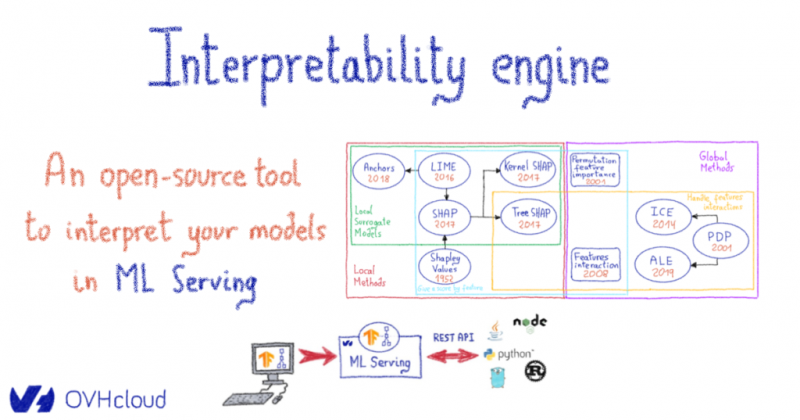
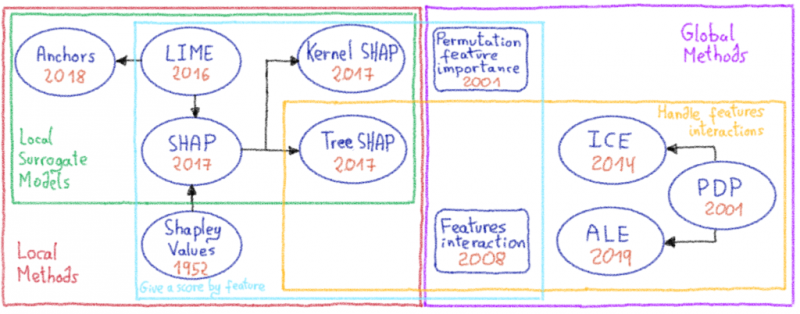
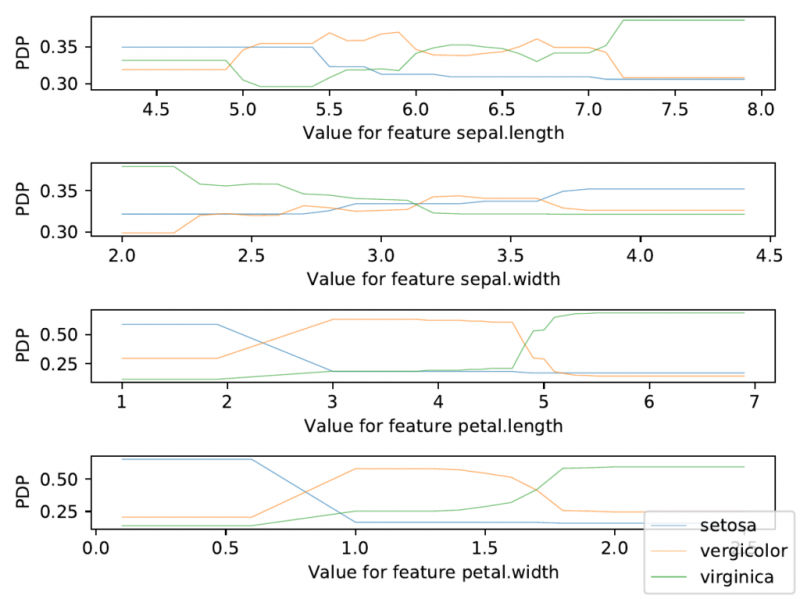
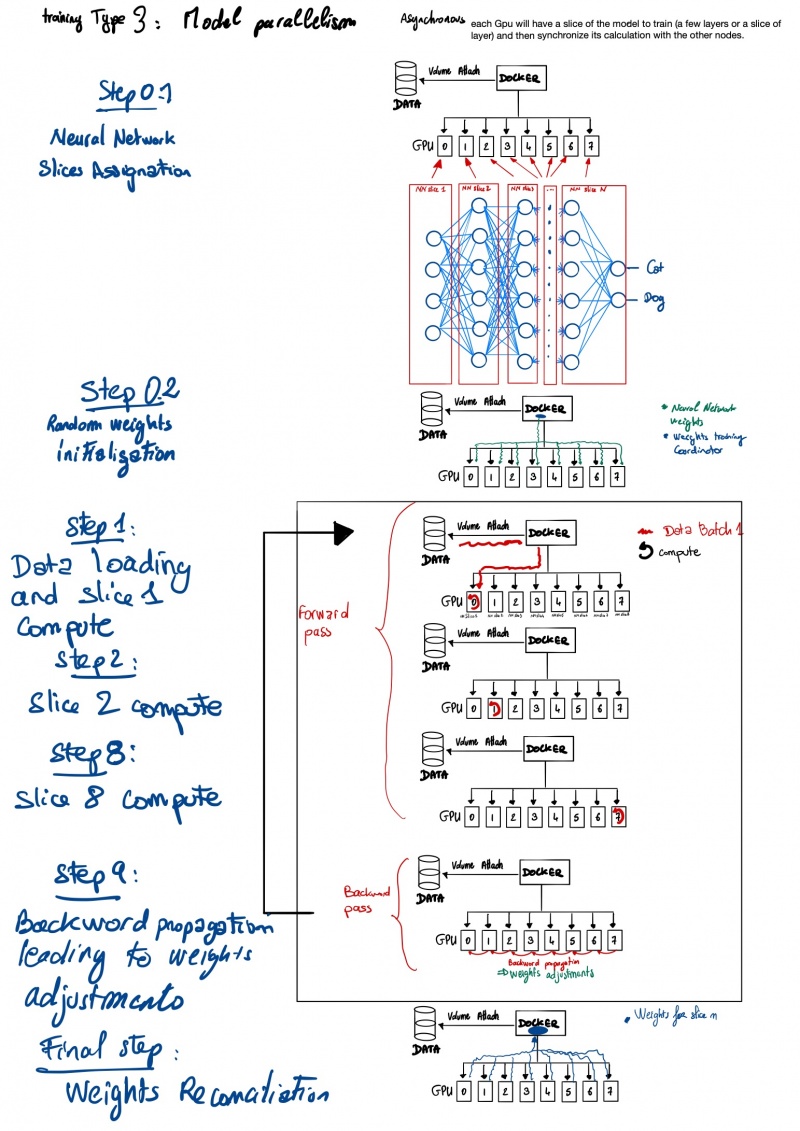
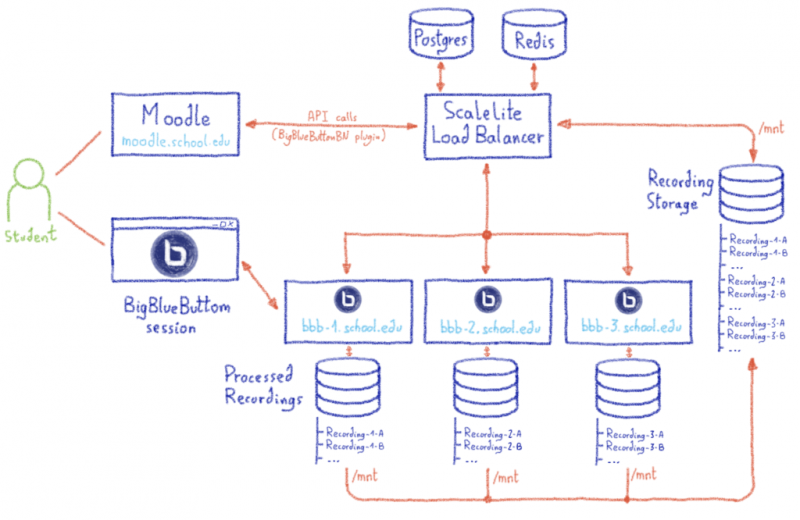
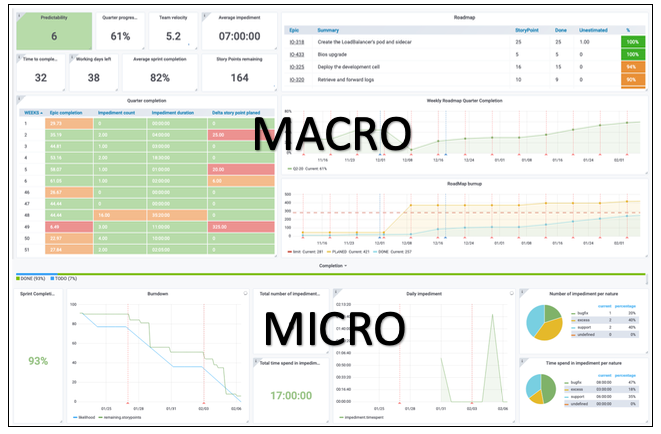
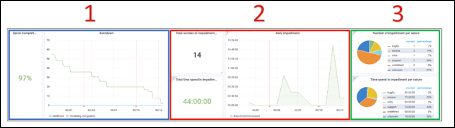
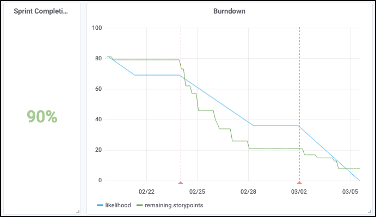
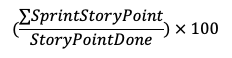Надежная цифровая экосистема. Он сейчас здесь! И мы вместе!
Драматический масштаб кризиса COVID-19, без сомнения, кардинально изменит наше видение мира. Неотложность ситуации радикально изменила наше социальное поведение и методы работы. Возникли региональные и международные проблемы.
Давайте рассмотрим страны, компании — целые сектора, например, сектор здравоохранения, которые сейчас так сильно пострадали. Каковы конкретные последствия таких концепций, как устойчивость, суверенитет и доверие?

Цифровой сектор никоим образом не избежал этих беспрецедентных вызовов, и для этого есть веские причины. Всего за несколько дней по всему миру произошли радикальные преобразования. Наша трудовая жизнь застыла и в то же время полностью изменилась. Хорошо это или плохо, но цифровые инструменты, несомненно, играют жизненно важную роль в этой вынужденной трансформации. Благодаря удаленной работе, удаленному обучению, системам оповещения, удаленному здравоохранению, покупкам в Интернете и многому другому, существует так много проблем и преобразований, которые могут быть внезапными.
День за днем мы обнаруживаем, что эта ускоренная цифровая трансформация имеет множество преимуществ, но также сопряжена с проблемами и даже рисками.
Джунгли цифровых решений настолько богаты и многочисленны, что линии доверия могут быть особенно трудными для чтения — особенно для общества, которое никогда раньше не нуждалось в таком количестве этих решений. Оживленная дискуссия о возможности отслеживания в инструментах отслеживания контактов, таких как TraceTogether в Сингапуре, демонстрирует, что граждане ставят под сомнение этичность этих цифровых инструментов. И они правы в этом.
Недавние скандалы по поводу неправомерного использования наших личных данных провайдерами социальных сетей показывают, что эти сценарии существуют не только в научно-фантастических шоу, таких как «Черное зеркало», — они уже стали реальностью.
В то время как многие страны Европы потеряли контроль над производством и поставкой оборудования, такого как маски и антибиотики, очевидно, что мир данных борется с теми же рисками зависимости.
В OVHcloud, как и наши клиенты и большинство других компаний, с которыми мы работаем, мы считаем, что возможность реализовать свой цифровой суверенитет является ключом к нашей свободе выбора. Это важно для сохранения контроля над нашим будущим, сохранения занятости и даже для сохранения нашего образа жизни. Это все проблемы надежного облака — облака, гарантирующего европейским странам защиту стратегических данных для их государств, компаний и граждан.
Мы твердо убеждены в том, что в Европе мы должны создать мощную экосистему игроков, разделяющих общие ценности и уважение к данным, обратимости, открытости и прозрачности.
Это убеждение разделяют многие владельцы бизнеса и службы на европейском континенте. Последние выступления Европейской комиссии демонстрируют, что это чувство разделяют, поэтому нам необходимо действовать.
Уже существуют различные инициативы; Я приведу три примера из тех, которые продвигают цифровой суверенитет:
Эти европейские решения существуют, они выдающиеся, и их изобретательность позволяет им конкурировать с более доминирующими игроками. Но солидарность между государственными органами, владельцами бизнеса и большими группами будет одним из ключей к успеху твердого цифрового суверенитета. Общественный спрос, спрос крупных европейских групп, сотрудничество между исследовательскими институтами и крупными учебными центрами со стартапами также являются ключевыми факторами для ускорения этой этической экосистемы.
Все поняли, что сейчас самое время действовать, а не просто выявлять проблемы. Октав клаб, основатель и председатель OVHcloud, всегда упорно трудился, чтобы защитить сильные ценности, и преуспел в создании европейского чемпиона компании — единственный европейский облачный плеер, который находится в пределах топ-10 во всем мире.
Чтобы нести ответственность, мы должны действовать.
Инвестиции в нашу надежную инфраструктуру: мы инвестируем в нашу собственную сеть из 30 центров обработки данных и в нашу собственную телекоммуникационную сеть с транзитом более 20 ТБ. Мы также инвестируем в два надежных центра обработки данных, расположенных во Франции, которые предназначены для европейских игроков с наиболее важными данными — наших государственных услуг, больниц и передовых отраслей. Наши центры обработки данных имеют самые высокие сертификаты с точки зрения безопасности (HDS, SecNumCloud в процессе, ISO / IEC 27001, 27017 и 27018, PCI DSS и т. Д.).
Инвестиции в ответственную и устойчивую модель: мы проектируем собственные центры обработки данных, строим наши серверы во Франции и предпочитаем короткие пути поставок. Эта модель гарантирует работу на севере Франции, а также обеспечивает отслеживаемость и возможность аудита нашего оборудования, а также повышает доступность.
Инвестиции в энергоэффективную модель: более 15 лет OVHcloud разрабатывает технологии водяного охлаждения для своих серверов, значительно сокращая затраты на строительство и эксплуатацию, а также резко ограничивая потребление энергии.
Инвестиции в инновации: мы убеждены, что инновации следует использовать для достижения целей доверия и уважения личных данных и данных компании. OVHcloud много инвестирует в исследования и разработки решений, особенно в проекты с открытым исходным кодом, а также работает с другими над созданием стандартов, гарантирующих совместимость облачных инфраструктур.
Но помимо инвестиций в наши собственные технологии, мы также должны создать экосистему игроков, которые разделяют одни и те же ценности и уважение к данным, обратимости, открытости и прозрачности.
Мы призываем издателей программного обеспечения и SaaS сотрудничать с нами и помочь с появлением новой инициативы: Open Trusted Cloud.

Эта программа преследует простую цель — создать экосистему решений SaaS и PaaS, размещенных в открытом обратимом облаке, гарантирующем физическое расположение данных.
OVHcloud гарантирует размещенные решения:
Таким образом, он предложит общую платформу конкурентоспособных решений, отмеченную ярлыком, который позволит каждому использовать лучшие программные решения в мире, при этом оставаясь защищенными надежной суверенной инфраструктурой.
Присоединяйтесь к нашей инициативе Open Trusted Cloud, и вместе мы докажем, что будущее может быть согласовано с нашими ценностями!
Давайте рассмотрим страны, компании — целые сектора, например, сектор здравоохранения, которые сейчас так сильно пострадали. Каковы конкретные последствия таких концепций, как устойчивость, суверенитет и доверие?
Цифровой сектор никоим образом не избежал этих беспрецедентных вызовов, и для этого есть веские причины. Всего за несколько дней по всему миру произошли радикальные преобразования. Наша трудовая жизнь застыла и в то же время полностью изменилась. Хорошо это или плохо, но цифровые инструменты, несомненно, играют жизненно важную роль в этой вынужденной трансформации. Благодаря удаленной работе, удаленному обучению, системам оповещения, удаленному здравоохранению, покупкам в Интернете и многому другому, существует так много проблем и преобразований, которые могут быть внезапными.
День за днем мы обнаруживаем, что эта ускоренная цифровая трансформация имеет множество преимуществ, но также сопряжена с проблемами и даже рисками.
Защищая нашу свободу выбора
Джунгли цифровых решений настолько богаты и многочисленны, что линии доверия могут быть особенно трудными для чтения — особенно для общества, которое никогда раньше не нуждалось в таком количестве этих решений. Оживленная дискуссия о возможности отслеживания в инструментах отслеживания контактов, таких как TraceTogether в Сингапуре, демонстрирует, что граждане ставят под сомнение этичность этих цифровых инструментов. И они правы в этом.
- Где хранятся наши медицинские данные, кто имеет к ним доступ и для чего они могут их использовать?
- Должны ли мы просто согласиться с тем, что несколько избранных игроков могут иногда полностью хранить свои основные правила в секрете?
Недавние скандалы по поводу неправомерного использования наших личных данных провайдерами социальных сетей показывают, что эти сценарии существуют не только в научно-фантастических шоу, таких как «Черное зеркало», — они уже стали реальностью.
В то время как многие страны Европы потеряли контроль над производством и поставкой оборудования, такого как маски и антибиотики, очевидно, что мир данных борется с теми же рисками зависимости.
Инициативы для надежной европейской цифровой экосистемы
В OVHcloud, как и наши клиенты и большинство других компаний, с которыми мы работаем, мы считаем, что возможность реализовать свой цифровой суверенитет является ключом к нашей свободе выбора. Это важно для сохранения контроля над нашим будущим, сохранения занятости и даже для сохранения нашего образа жизни. Это все проблемы надежного облака — облака, гарантирующего европейским странам защиту стратегических данных для их государств, компаний и граждан.
Мы твердо убеждены в том, что в Европе мы должны создать мощную экосистему игроков, разделяющих общие ценности и уважение к данным, обратимости, открытости и прозрачности.
Это убеждение разделяют многие владельцы бизнеса и службы на европейском континенте. Последние выступления Европейской комиссии демонстрируют, что это чувство разделяют, поэтому нам необходимо действовать.
Уже существуют различные инициативы; Я приведу три примера из тех, которые продвигают цифровой суверенитет:
- По всей Европе существует облачный проект Gaia-X — совместная инициатива государственных органов Германии и Франции, поддерживаемая их соответствующими экосистемами. Цель этого облачного проекта — определить оси влияния надежного европейского облака. Эта европейская экосистема, объединяющая интеграторов, производителей, игроков в телекоммуникационном секторе и организации, существует и объединена сильным набором ценностей.
- Во Франции существует Стратегический комитет промышленности, известный как Comité Stratégique de Filière (CSF). Он был инициирован Министерством финансов и промышленности, и такие игроки, как Atos, Oodrive, Outscale, OVHcloud, Scaleway и многие другие, подтвердили свою приверженность разработке надежных решений. Игроки интеграции, такие как CapGemini, GFI, Sopra и Thales, также много работали, чтобы предложить альтернативные, надежные суверенные решения.
- Что же касается владельцев бизнеса, то мы можем оценить успех призыва к действию от 9 апреля для улучшения цифрового суверенитета в Европе и во всем мире в будущем * (по инициативе Рафаэля Ришара (Неодиа), Паскаля Гаята (Лес Cas d'OR du Digital, Les Pionniers du Digital), Матье Хуг (Тилкаль) и Ален Гарнье (Jamespot)). Он был подписан более чем 100 владельцами бизнеса (включая меня и Октава от имени OVHcloud) и доказывает, насколько важно осознавать эти темы и насколько коллективное участие является ключевым элементом совместных действий.
Эти европейские решения существуют, они выдающиеся, и их изобретательность позволяет им конкурировать с более доминирующими игроками. Но солидарность между государственными органами, владельцами бизнеса и большими группами будет одним из ключей к успеху твердого цифрового суверенитета. Общественный спрос, спрос крупных европейских групп, сотрудничество между исследовательскими институтами и крупными учебными центрами со стартапами также являются ключевыми факторами для ускорения этой этической экосистемы.
Все поняли, что сейчас самое время действовать, а не просто выявлять проблемы. Октав клаб, основатель и председатель OVHcloud, всегда упорно трудился, чтобы защитить сильные ценности, и преуспел в создании европейского чемпиона компании — единственный европейский облачный плеер, который находится в пределах топ-10 во всем мире.
Чтобы нести ответственность, мы должны действовать.
Обязательство OVHcloud инвестировать и укреплять доверие в будущее
Инвестиции в нашу надежную инфраструктуру: мы инвестируем в нашу собственную сеть из 30 центров обработки данных и в нашу собственную телекоммуникационную сеть с транзитом более 20 ТБ. Мы также инвестируем в два надежных центра обработки данных, расположенных во Франции, которые предназначены для европейских игроков с наиболее важными данными — наших государственных услуг, больниц и передовых отраслей. Наши центры обработки данных имеют самые высокие сертификаты с точки зрения безопасности (HDS, SecNumCloud в процессе, ISO / IEC 27001, 27017 и 27018, PCI DSS и т. Д.).
Инвестиции в ответственную и устойчивую модель: мы проектируем собственные центры обработки данных, строим наши серверы во Франции и предпочитаем короткие пути поставок. Эта модель гарантирует работу на севере Франции, а также обеспечивает отслеживаемость и возможность аудита нашего оборудования, а также повышает доступность.
Инвестиции в энергоэффективную модель: более 15 лет OVHcloud разрабатывает технологии водяного охлаждения для своих серверов, значительно сокращая затраты на строительство и эксплуатацию, а также резко ограничивая потребление энергии.
Инвестиции в инновации: мы убеждены, что инновации следует использовать для достижения целей доверия и уважения личных данных и данных компании. OVHcloud много инвестирует в исследования и разработки решений, особенно в проекты с открытым исходным кодом, а также работает с другими над созданием стандартов, гарантирующих совместимость облачных инфраструктур.
Но помимо инвестиций в наши собственные технологии, мы также должны создать экосистему игроков, которые разделяют одни и те же ценности и уважение к данным, обратимости, открытости и прозрачности.
Open Trusted Cloud — каталог проверенных решений
Мы призываем издателей программного обеспечения и SaaS сотрудничать с нами и помочь с появлением новой инициативы: Open Trusted Cloud.
Эта программа преследует простую цель — создать экосистему решений SaaS и PaaS, размещенных в открытом обратимом облаке, гарантирующем физическое расположение данных.
OVHcloud гарантирует размещенные решения:
- Выбор места для хранения и обработки данных, обеспечивающий соблюдение местного европейского законодательства.
- Соблюдение европейского «кодекса поведения» CISPE по защите данных 1 .
- Соблюдение «Кодекса поведения» по обратимости данных при содействии Европейской комиссии (SWIPO IaaS 2 )
- При необходимости, соответствие требованиям для хостинга медицинских данных (сертификация HDS) и хостинга финансовых данных (соответствие SOC / ACPR / EBA и сертификация PCI-DSS) во Франции и в некоторых европейских странах.
- И в некоторых случаях, если на решения ссылаются правильные организации, C2-хостинг для государственных услуг во Франции.
Таким образом, он предложит общую платформу конкурентоспособных решений, отмеченную ярлыком, который позволит каждому использовать лучшие программные решения в мире, при этом оставаясь защищенными надежной суверенной инфраструктурой.
Присоединяйтесь к нашей инициативе Open Trusted Cloud, и вместе мы докажем, что будущее может быть согласовано с нашими ценностями!