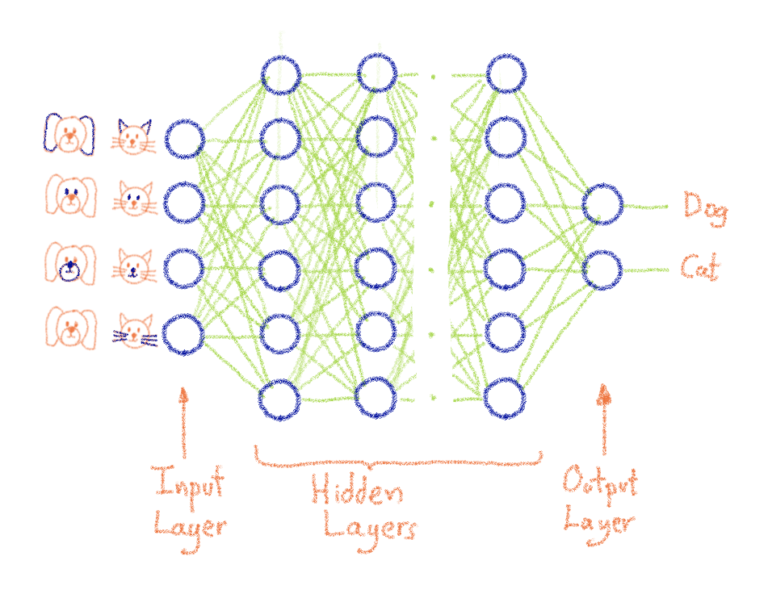
Как работает PCI-Express и почему вам это нужно? #GPU

Что такое PCI-Express?
Все, и я имею в виду все, должны обращать внимание, когда они проходят интенсивное обучение машинному обучению / глубокому обучению.
Как я объяснял в предыдущем сообщении блога, графические процессоры значительно ускорили эволюцию искусственного интеллекта.
Однако создать сервер на графических процессорах не так-то просто. А отсутствие соответствующей инфраструктуры может сказаться на времени обучения.
Если вы используете графические процессоры, вы должны знать, что есть 2 способа подключить их к материнской плате, чтобы позволить ей подключаться к другим компонентам (сети, ЦП, устройству хранения). Решение 1 — через PCI Express, а решение 2 — через SXM2 . Мы поговорим о SXM2 в будущем. Сегодня мы сосредоточимся на PCI Express . Это связано с тем, что он сильно зависит от выбора соседнего оборудования, такого как шина PCI или ЦП.

Дизайн SXM2 VS Дизайн PCI Express
Это основной элемент, который следует учитывать при разговоре о глубоком обучении, поскольку этап загрузки данных — это пустая трата времени вычислений, поэтому пропускная способность между компонентами и графическими процессорами является ключевым узким местом в большинстве контекстов обучения глубокому обучению.
Как работает PCI-Express и почему нужно заботиться о количестве линий PCIe? Что такое линии PCI-Express и есть ли связанные с этим ограничения ЦП?
Каждый GPU V100 использует 16 линий PCI-e. Что именно это означает?
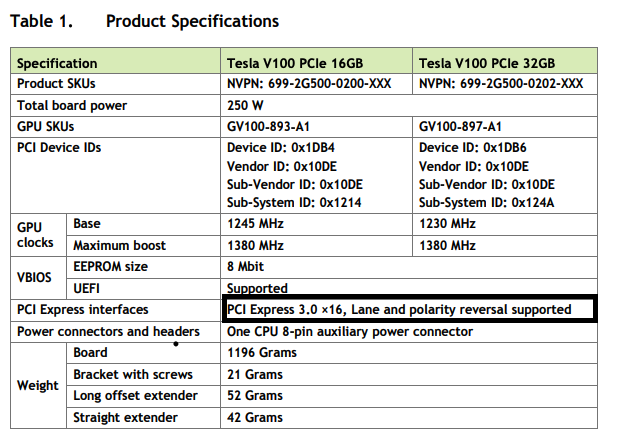
В «х16» означает, что PCIe имеет 16 выделенных полос. Итак… следующий вопрос: что такое полоса PCI Express?
Что такое линия PCI Express?
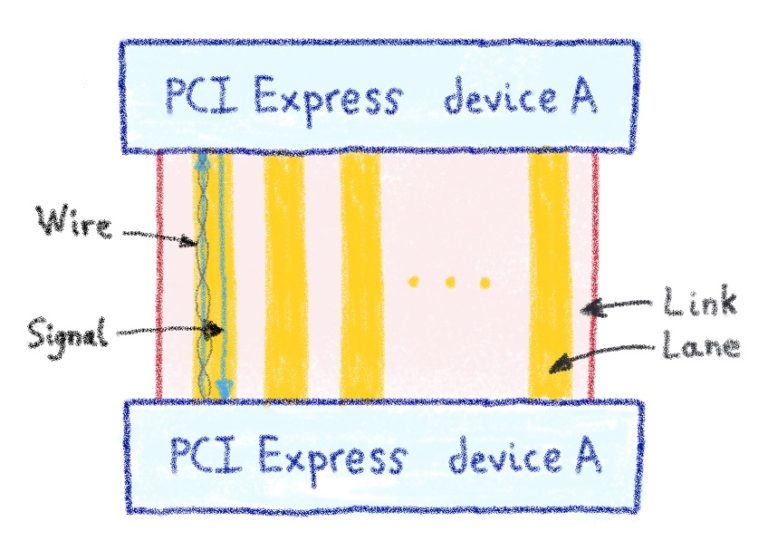
Дорожки PCIe используются для связи между устройствами PCIe или между PCIe и ЦП. Полоса состоит из двух проводов: один для входящей связи, а другой с удвоенной пропускной способностью трафика для исходящего.
Связь по дорожкам похожа на связь сетевого уровня 1 — все дело в максимально быстрой передаче битов по электрическим проводам! Однако метод, используемый для PCIe Link, немного отличается, поскольку устройство PCIe состоит из линий xN. В нашем предыдущем примере N = 16, но это может быть любая степень двойки от 1 до 16 (1/2/4/8/16).
Итак… если PCIe похож на сетевую архитектуру, это означает, что уровни PCIe существуют, не так ли?
Да! Вы правы, PCIe имеет 4 слоя:
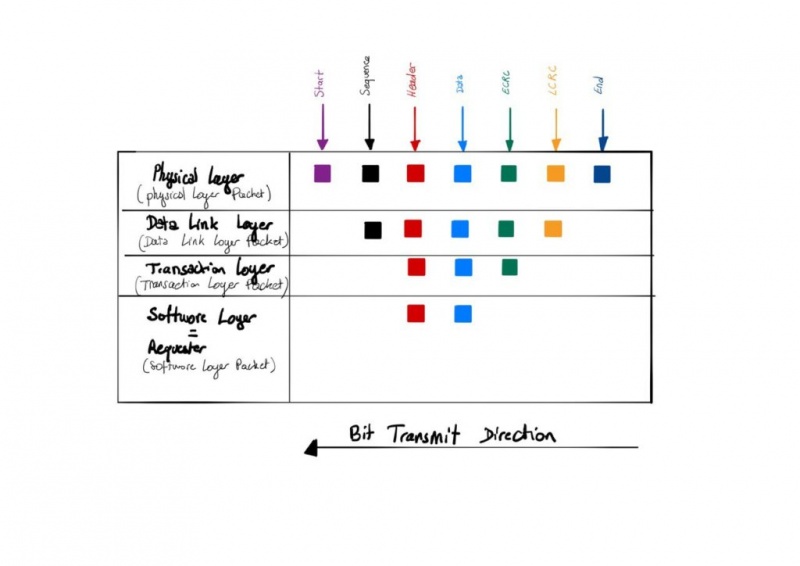
Физический уровень (также известный как уровень больших переговоров )
Физический уровень (PL) несет ответственность за ведение переговоров условия для получения исходных пакетов (PLP для пакетов физического уровня) , то есть ширина полосы частот , и с другим устройством.
Вы должны знать, что будет использоваться только наименьшее количество полос из двух устройств. Вот почему так важен выбор подходящего процессора. ЦП имеют ограниченное количество линий, которыми они могут управлять, поэтому наличие хорошего графического процессора с 16 линиями PCIe и наличие ЦП с 8 линиями шины PCIe будет так же эффективно, как выбросить половину ваших денег, потому что она не помещается в ваш кошелек.
Пакеты, полученные на физическом уровне (также известный как PHY) , поступают от других устройств PCIe или из системы (например, через память прямого доступа — DAM или от ЦП) и инкапсулируются в кадр.
Назначение Start-of-Frame — сказать: «Я отправляю вам данные, это начало», и для этого требуется всего 1 байт!
Слово « конец кадра» также составляет 1 байт, чтобы сказать «до свидания, я сделал это».
Этот уровень реализует декодирование 8b / 10b или 128b / 130b, которое мы объясним позже и в основном используется для восстановления тактовой частоты.
Пакет уровня канала передачи данных (он же давайте разберем этот беспорядок в правильном порядке )
Пакет уровня канала передачи данных (DLLP) начинается с порядкового номера пакета. Это действительно важно, поскольку в какой-то момент пакет может быть поврежден, поэтому может потребоваться однозначная идентификация для повторных попыток. Порядковый номер кодируется на 2 байта.
Layer Data Link Packet затем следуют уровне транзакций пакетов , а затем закрывается с МЦРК (Local Циклические Redundancy Check) и используется для проверки слоя транзакции пакета (значение фактического Payload) целостность.
Если LCRC подтвержден, то уровень звена данных отправляет сигнал ACK (ACKnowledge) на передатчик через физический уровень . В противном случае он отправляет сигнал NAK (Not AcKnowledge) на передатчик, который повторно отправит кадр, связанный с порядковым номером, для повторной попытки; эта часть обрабатывает буфер воспроизведения на стороне получателя .
Уровень транзакций
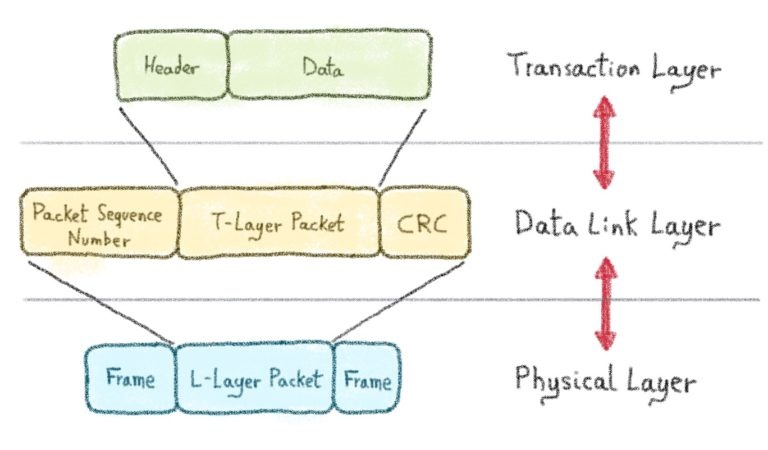
Уровень транзакции отвечает за управление фактической полезной нагрузкой (заголовок + данные), а также (необязательный) дайджест сообщения ECRC (сквозная циклическая проверка избыточности) . Этот пакет уровня транзакции поступает с уровня звена данных, где он декапсулирован .
При необходимости / запросе выполняется проверка целостности . Этот шаг будет проверять целостность бизнес - логику и не будет гарантировать , нет коррупции пакетов при передаче данных от Data Link Layer для транзакций уровня.
Заголовок описывает тип транзакции, например:
- Операция памяти
- Транзакция ввода-вывода
- Транзакция конфигурации
- или сообщение транзакции
Уровень приложения
Роль прикладного уровня — обрабатывать логику пользователя . Этот уровень отправляет заголовок и полезные данные на уровень транзакции . Магия происходит на этом уровне, где данные привязаны к разным аппаратным компонентам.
Как PCIe общается с остальным миром?
PCIe Link использует концепцию коммутации пакетов, используемую в сети в полнодуплексном режиме.
Устройство PCIe имеет внутренние часы для управления циклами передачи данных PCIe . Этот цикл передачи данных также организуется благодаря ссылочным часам. Последний отправляет сигнал через выделенную полосу (которая не является частью x1 / 2/4/8/16/32, упомянутой выше) . Эти часы помогут как принимающим, так и передающим устройствам синхронизироваться для передачи пакетов.
Каждая линия PCIe используется для отправки байтов параллельно с другими линиями . Синхронизация часов упоминалось выше , поможет приемник положить обратно эти байты в правильном порядке
У вас может быть порядок байтов, но есть ли у вас целостность данных на физическом уровне?
Для обеспечения целостности устройство PCIe использует кодировку 8b / 10b для PCIe поколений 1 и 2 или схему кодирования 128b / 130b для поколений 3 и 4.
Эти кодировки используются для предотвращения потери временных ориентиров, особенно при передаче последовательных одинаковых битов. Этот процесс называется « Восстановление часов ».
Эти 128 бит данных полезной нагрузки отправляются, и к ним добавляются 2 байта управления.
Быстрые примеры
Давайте упростим это на примере 8b / 10b: согласно IEEE 802.3, пункт 36, таблица 36–1a на основе спецификаций Ethernet здесь представляет собой кодировку таблицы 8b / 10b:
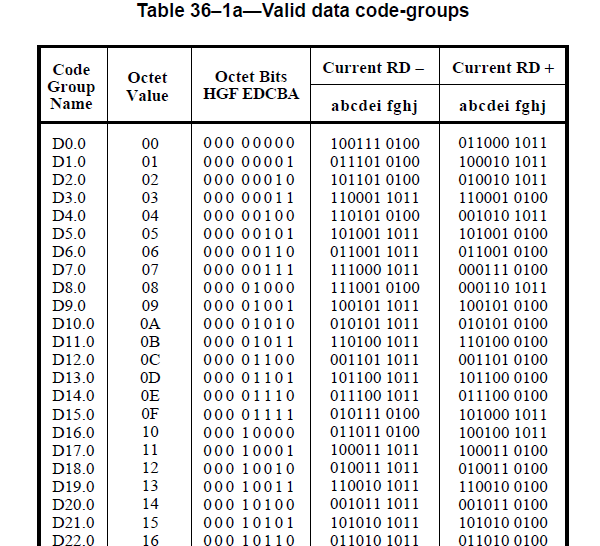
Итак, как получатель может различить всех, кто повторяет 0 (имя кодовой группы D0.0)?

Кодирование 8b / 10b состоит из кодировок 5b / 6b + 3b / 4b.
Следовательно, 00000 000 будет закодировано в 100111 0100, 5 первых битов исходных данных 00000 будут закодированы в 100111 с использованием кодирования 5b / 6b ( rd + ); то же самое касается второй группы из 3 бит исходных данных 000, закодированных в 0100 с использованием кодирования 3b / 4b ( rd- ).
Это могло бы быть также 5b / 6b кодирования й + и 3b / 4b кодирование RD- решений 00000 000 превращается в 011000 1011
Следовательно, исходные данные, которые были 8-битными, теперь являются 10-битными из-за управления битами (1 управляющий бит для 5b / 6b и 1 для 3b / 4b).
Но не волнуйтесь, я позже напишу в блоге сообщение, посвященное кодированию.
PCIe поколения 1 и 2 были разработаны с кодированием 8b / 10b, что означает, что фактические передаваемые данные составляли только 80% от общей нагрузки (поскольку 20% — 2 бита используются для синхронизации часов).
PCIe Gen3 и 4 были разработаны с 128b / 130b, что означает, что управляющие биты теперь составляют только 1,56% полезной нагрузки. Неплохо, не правда ли?
Давайте вместе рассчитаем пропускную способность PCIe
Вот таблица спецификаций версий PCIe
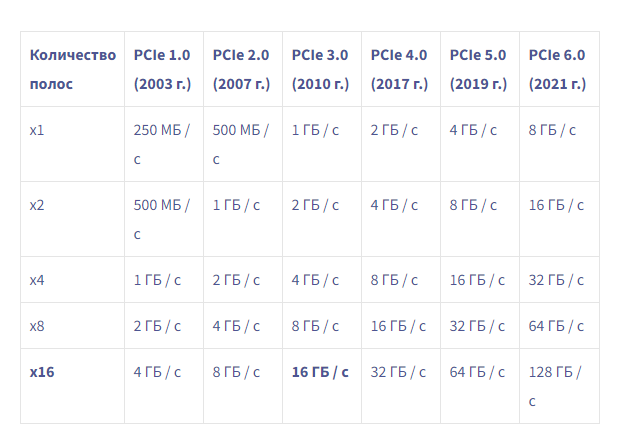
Консорциум PCI-SIG Теоретическая пропускная способность PCIe / Технические характеристики полосы / пути
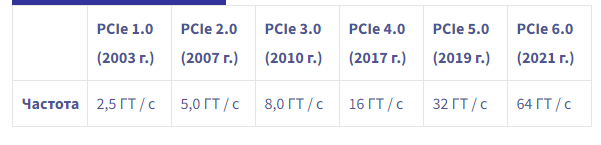
консорциум PCI-SIG PCIe теоретическая необработанная спецификация скорости передачи данных. Чтобы получить такие числа, давайте посмотрим на общую формулу пропускной способности:
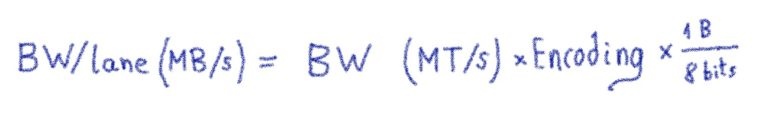
- BW означает пропускную способность
- MT / s: мегапереводы в секунду
- Кодирование может быть 4b / 5b /, 8b / 10b, 128b / 130b,…
Для PCIe v1.0:
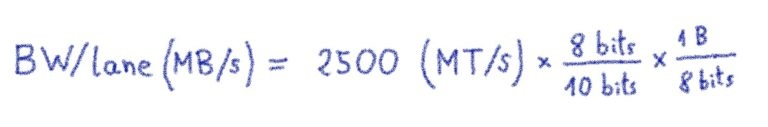
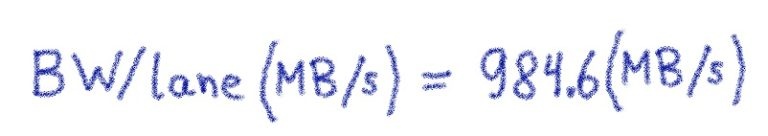
Таким образом, с 16 полосами для NVIDIA V100, подключенными к PCIe v3.0 , эффективная скорость передачи данных (пропускная способность данных) составляет почти 16 ГБ / с / путь ( фактическая пропускная способность составляет 15,75 ГБ / с / путь ).
Вы должны быть осторожны, чтобы не запутаться, поскольку общую пропускную способность также можно интерпретировать как двухстороннюю пропускную способность; в этом случае мы считаем, что общая пропускная способность x16 составляет около 32 ГБ / с.
Примечание: Еще один элементкоторый мы не рассматривал, что максимальные потребности теоретической пропускной способности будут снижены примерно1 Гбит / с для протоколов коррекции ошибок ( ЦЭР и МЦРК ), а также в заголовках ( Начальный тег, последовательность теги, заголовок ) иНакладные расходы на нижний колонтитул ( конечный тег) объяснялись ранее в этом сообщении в блоге.
В заключение
Мы видели, что PCI Express сильно изменился и основан на тех же концепциях, что и сеть. Чтобы извлечь максимум из устройств PCIe, необходимо понимать основы базовой инфраструктуры.
Неспособность выбрать правильную базовую материнскую плату, процессор или шину может привести к серьезному снижению производительности и снижению производительности графического процессора.
Подводить итоги:
Друзья не позволяют друзьям создавать собственные хосты на GPU