Путешествие в чудесную страну машинного обучения, или «Меня ограбили?» (Часть 1)
Два года назад я купил квартиру. Мне потребовался год, чтобы получить правильное представление о рынке недвижимости: совершить несколько визитов, пару раз разочароваться и, наконец, найти квартиру своей мечты (и которую я считал оцененной, соответствующей рынку).

Но как именно я пришел к этой предполагаемой «подходящей цене»? Ну, я видел много объявлений о большом количестве квартир. Я обнаружил, что некоторые объекты недвижимости были желательными и, следовательно, востребованными (с балконом, хорошим видом, безопасным районом и т. квартира.
Другими словами, я узнал из опыта , и это знание позволило мне построить ментальную модель , сколько квартира должна стоить в зависимости от его характеристик.

Но, как и любой другой человек, я подвержен ошибкам и поэтому постоянно задаю себе один и тот же вопрос: «Меня ограбили?». Что ж, оглядываясь назад на процесс, который привел меня к этому, становится очевидным, что есть способ следовать тому же процессу, но с большим количеством данных, меньшими предвзятостями и, надеюсь, в лучшее время: машинное обучение.
В этой серии сообщений в блоге я собираюсь изучить, как машинное обучение могло помочь мне оценить стоимость купленной мной квартиры; какие инструменты вам понадобятся для этого, как вы будете действовать и с какими трудностями вы можете столкнуться. Теперь, прежде чем мы окунемся в эту чудесную страну, сделаем небольшое заявление об отказе от ответственности: путешествие, которое мы собираемся пройти вместе, служит иллюстрацией того, как работает машинное обучение и почему оно, по сути, не является магией.
Вы не закончите это путешествие с помощью алгоритма, который сможет с максимальной точностью оценить любую квартиру. Вы не будете следующим магнатом недвижимости (если бы все было так просто, я бы продавал курсы о том, как стать миллионером на Facebook, за 20 евро). Надеюсь, однако, если я выполнил свою работу правильно, вы поймете, почему машинное обучение проще, чем вы думаете, но не так просто, как может показаться.

Помеченные данные
В этом примере для прогнозирования стоимости обмена собственности мы ищем данные, которые содержат характеристики домов и квартир, а также цену, по которой они были проданы (цена является меткой). К счастью, несколько лет назад французское правительство решило создать платформу открытых данных, обеспечивающую доступ к десяткам наборов данных, связанных с администрацией, таких как общедоступная база данных о наркотиках, концентрация атмосферных загрязнителей в реальном времени и многие другие. К счастью для нас, они включили набор данных, содержащий транзакции с недвижимостью!
Что ж, вот наш набор данных. Если вы просмотрите веб-страницу, вы увидите, что существует множество вкладов сообщества, которые обогащают данные, делая их пригодными для макроанализа. Для наших целей мы можем использовать набор данных, предоставленный Etalab, общественной организацией, ответственной за поддержку платформы открытых данных.
Программного обеспечения
Здесь все становится немного сложнее. Если бы я был одаренным специалистом по данным, я мог бы просто положиться на среду, такую как TensorFlow, PyTorch или ScikitLearn, чтобы загрузить свои данные и выяснить, какой алгоритм лучше всего подходит для обучения модели. Отсюда я мог определить оптимальные параметры обучения и затем тренировать их. К сожалению, я не одаренный аналитик данных. Но, к моему несчастью, мне все же повезло: есть инструменты, обычно сгруппированные под названием «AI Studios», которые разработаны именно для этой цели, но не требуют никаких навыков. В этом примере мы будем использовать Dataiku, одну из самых известных и эффективных AI Studios:
Инфраструктура
Очевидно, что программное обеспечение должно работать на компьютере. Я мог бы попробовать установить Dataiku на свой компьютер, но, поскольку мы находимся в блоге OVHCloud, кажется целесообразным развернуть его в облаке! Как оказалось, вы можете легко развернуть виртуальную машину с предварительно установленным Dataiku в нашем публичном облаке (вы также можете сделать это в публичном облаке некоторых наших конкурентов) с бесплатной лицензией сообщества. С помощью инструмента Dataiku я смогу загрузить набор данных, обучить модель и развернуть ее. Легко, правда?
Работа с вашим набором данных
После того, как вы установили свою виртуальную машину, Dataiku автоматически запускает веб-сервер, доступный через порт 11000. Чтобы получить к нему доступ, просто зайдите в свой браузер и введите. http://<your-VM-IP-address>:11000.После этого появится экран приветствия, предлагающий вам зарегистрироваться для получения бесплатной лицензии сообщества. Как только все это будет сделано, создайте свой первый проект и следуйте инструкциям по импорту вашего первого набора данных (вам просто нужно перетащить несколько файлов) и сохранить его.
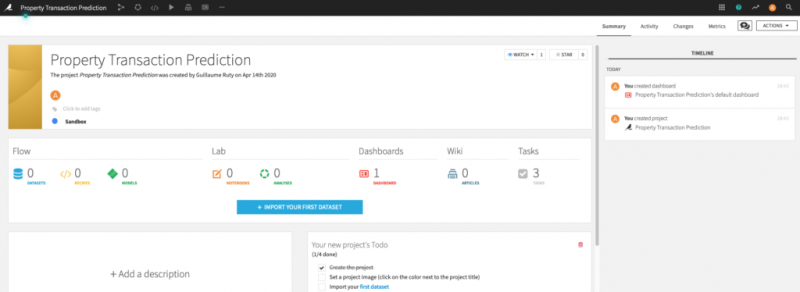
Как только это будет сделано, перейдите к представлению «Поток» вашего проекта. Вы должны увидеть там свой набор данных. Выберите его, и вы увидите широкий спектр возможных действий.
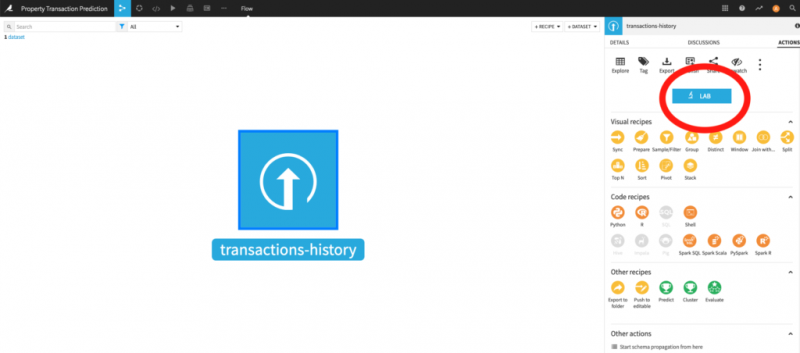
А теперь перейдем к делу и обучим модель. Для этого перейдите к действию «Лаборатория» и выберите «Быстрая модель», затем «Прогнозирование» с «valeur_fonciere» в качестве целевой переменной (поскольку мы пытаемся предсказать цену).
Поскольку мы не являемся экспертами, давайте попробуем автоматическое машинное обучение, предложенное Dataiku, с интерпретируемой моделью и обучим его. Dataiku должен автоматически обучать две модели, дерево решений и регрессию, причем одна из них имеет лучшую оценку, чем другая (выбранная метрика по умолчанию — это оценка R2, одна из множества метрик, которые можно использовать для оценки производительности модели).. Щелкните по этой модели, и вы сможете ее развернуть. Теперь вы можете использовать эту модель в любом наборе данных по той же схеме.
Теперь, когда модель обучена, давайте попробуем ее и посмотрим, предсказывает ли она правильную цену на квартиру, которую я купил! По вполне очевидным причинам я не буду сообщать вам свой адрес, цену моей квартиры или другую подобную личную информацию. Поэтому до конца поста я буду делать вид, что купил свою квартиру за 100 евро (мне повезло!), И нормализовать все остальные цены таким же образом.
Как я упоминал выше, чтобы запросить модель, нам нужно создать новый набор данных, состоящий из данных, которые мы хотим протестировать. В моем случае мне просто нужно было создать новый файл csv из заголовка (вы должны сохранить его в файле, чтобы Dataiku его понял) и строку, которая относится к фактической транзакции, которую я совершил (легко, поскольку это уже было сделано).
Если бы я хотел сделать это для собственности, которую собирался купить, мне пришлось бы собрать как можно больше информации, чтобы наилучшим образом выполнить критерии в схеме (адрес, площадь, почтовый индекс, географические координаты и т. Д.) И построить эту линию. себя. На этом этапе я также могу создать набор данных из нескольких строк, чтобы запросить модель сразу по нескольким случаям.
Как только этот новый набор данных будет построен, просто загрузите его, как в первый раз, и вернитесь в представление потока. Там должен появиться ваш новый набор данных. Щелкните модель справа от потока, а затем действие «Оценка». Выберите образец набора данных, используйте параметры по умолчанию и запустите задание. Теперь у вас должен появиться новый набор данных в вашем потоке. Если вы изучите этот набор данных, вы увидите, что в конце есть новый столбец, содержащий прогнозы!
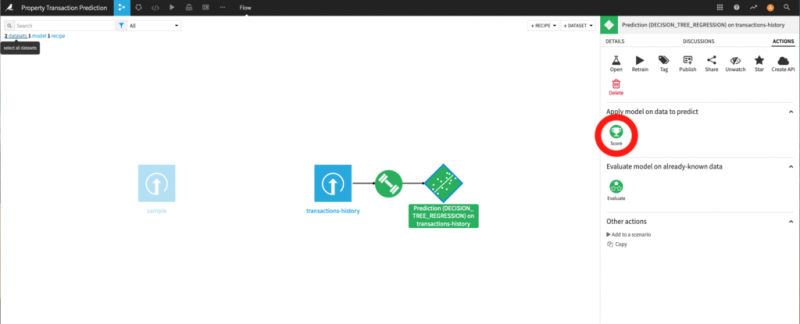
В моем случае для моей квартиры за 100 евро прогнозируемая цена составляет 105 евро. Это может означать две вещи:
Или…
Давайте попробуем другие транзакции, которые произошли на той же улице и в том же году. Что ж, на этот раз результат не впечатляет: очевидно, каждая квартира, купленная на моей улице в 2018 году, стоит ровно 105 евро, независимо от их размера и характеристик. Если бы я знал это, я бы, наверное, купил квартиру побольше! Казалось бы, наша модель не так умна, как мы изначально думали, и нам еще есть над чем поработать…
В этом посте мы изучили, где может пригодиться машинное обучение, какие данные будут полезны, какое программное обеспечение нам необходимо для его использования, а также рассмотрели инфраструктуру, необходимую для запуска программного обеспечения. Мы обнаружили, что каждый может попробовать машинное обучение — это не волшебство, — но мы также обнаружили, что нам придется немного усерднее работать, чтобы добиться результатов. В самом деле, бросаясь в чудесное путешествие, как мы, мы не уделили время более внимательному изучению самих данных и тому, как упростить использование модели, — и не посмотрели на то, что модель фактически наблюдала при прогнозировании цена. Если бы это было так, мы бы поняли, что это действительно бессмысленно. Другими словами, мы недостаточно квалифицировали нашу проблему. Но пусть это не умаляет нашего энтузиазма в нашем путешествии, поскольку это всего лишь небольшая неудача!
В следующем посте мы продолжим наше путешествие и поймем, почему модель, которую мы обучили, в конечном итоге оказалась бесполезной: мы более точно посмотрим на данные, которые есть в нашем распоряжении, и найдем несколько способов сделать ее более подходящей для машинного обучения. алгоритмы — следуя простым рекомендациям здравого смысла. Надеюсь, что с более точными данными мы сможем значительно улучшить нашу модель.
Но как именно я пришел к этой предполагаемой «подходящей цене»? Ну, я видел много объявлений о большом количестве квартир. Я обнаружил, что некоторые объекты недвижимости были желательными и, следовательно, востребованными (с балконом, хорошим видом, безопасным районом и т. квартира.
Другими словами, я узнал из опыта , и это знание позволило мне построить ментальную модель , сколько квартира должна стоить в зависимости от его характеристик.
Но, как и любой другой человек, я подвержен ошибкам и поэтому постоянно задаю себе один и тот же вопрос: «Меня ограбили?». Что ж, оглядываясь назад на процесс, который привел меня к этому, становится очевидным, что есть способ следовать тому же процессу, но с большим количеством данных, меньшими предвзятостями и, надеюсь, в лучшее время: машинное обучение.
В этой серии сообщений в блоге я собираюсь изучить, как машинное обучение могло помочь мне оценить стоимость купленной мной квартиры; какие инструменты вам понадобятся для этого, как вы будете действовать и с какими трудностями вы можете столкнуться. Теперь, прежде чем мы окунемся в эту чудесную страну, сделаем небольшое заявление об отказе от ответственности: путешествие, которое мы собираемся пройти вместе, служит иллюстрацией того, как работает машинное обучение и почему оно, по сути, не является магией.
Вы не закончите это путешествие с помощью алгоритма, который сможет с максимальной точностью оценить любую квартиру. Вы не будете следующим магнатом недвижимости (если бы все было так просто, я бы продавал курсы о том, как стать миллионером на Facebook, за 20 евро). Надеюсь, однако, если я выполнил свою работу правильно, вы поймете, почему машинное обучение проще, чем вы думаете, но не так просто, как может показаться.
Что вам нужно, чтобы построить модель с помощью машинного обучения?
Помеченные данные
В этом примере для прогнозирования стоимости обмена собственности мы ищем данные, которые содержат характеристики домов и квартир, а также цену, по которой они были проданы (цена является меткой). К счастью, несколько лет назад французское правительство решило создать платформу открытых данных, обеспечивающую доступ к десяткам наборов данных, связанных с администрацией, таких как общедоступная база данных о наркотиках, концентрация атмосферных загрязнителей в реальном времени и многие другие. К счастью для нас, они включили набор данных, содержащий транзакции с недвижимостью!
Что ж, вот наш набор данных. Если вы просмотрите веб-страницу, вы увидите, что существует множество вкладов сообщества, которые обогащают данные, делая их пригодными для макроанализа. Для наших целей мы можем использовать набор данных, предоставленный Etalab, общественной организацией, ответственной за поддержку платформы открытых данных.
Программного обеспечения
Здесь все становится немного сложнее. Если бы я был одаренным специалистом по данным, я мог бы просто положиться на среду, такую как TensorFlow, PyTorch или ScikitLearn, чтобы загрузить свои данные и выяснить, какой алгоритм лучше всего подходит для обучения модели. Отсюда я мог определить оптимальные параметры обучения и затем тренировать их. К сожалению, я не одаренный аналитик данных. Но, к моему несчастью, мне все же повезло: есть инструменты, обычно сгруппированные под названием «AI Studios», которые разработаны именно для этой цели, но не требуют никаких навыков. В этом примере мы будем использовать Dataiku, одну из самых известных и эффективных AI Studios:
Инфраструктура
Очевидно, что программное обеспечение должно работать на компьютере. Я мог бы попробовать установить Dataiku на свой компьютер, но, поскольку мы находимся в блоге OVHCloud, кажется целесообразным развернуть его в облаке! Как оказалось, вы можете легко развернуть виртуальную машину с предварительно установленным Dataiku в нашем публичном облаке (вы также можете сделать это в публичном облаке некоторых наших конкурентов) с бесплатной лицензией сообщества. С помощью инструмента Dataiku я смогу загрузить набор данных, обучить модель и развернуть ее. Легко, правда?
Работа с вашим набором данных
После того, как вы установили свою виртуальную машину, Dataiku автоматически запускает веб-сервер, доступный через порт 11000. Чтобы получить к нему доступ, просто зайдите в свой браузер и введите. http://<your-VM-IP-address>:11000.После этого появится экран приветствия, предлагающий вам зарегистрироваться для получения бесплатной лицензии сообщества. Как только все это будет сделано, создайте свой первый проект и следуйте инструкциям по импорту вашего первого набора данных (вам просто нужно перетащить несколько файлов) и сохранить его.
Как только это будет сделано, перейдите к представлению «Поток» вашего проекта. Вы должны увидеть там свой набор данных. Выберите его, и вы увидите широкий спектр возможных действий.
А теперь перейдем к делу и обучим модель. Для этого перейдите к действию «Лаборатория» и выберите «Быстрая модель», затем «Прогнозирование» с «valeur_fonciere» в качестве целевой переменной (поскольку мы пытаемся предсказать цену).
Поскольку мы не являемся экспертами, давайте попробуем автоматическое машинное обучение, предложенное Dataiku, с интерпретируемой моделью и обучим его. Dataiku должен автоматически обучать две модели, дерево решений и регрессию, причем одна из них имеет лучшую оценку, чем другая (выбранная метрика по умолчанию — это оценка R2, одна из множества метрик, которые можно использовать для оценки производительности модели).. Щелкните по этой модели, и вы сможете ее развернуть. Теперь вы можете использовать эту модель в любом наборе данных по той же схеме.
Теперь, когда модель обучена, давайте попробуем ее и посмотрим, предсказывает ли она правильную цену на квартиру, которую я купил! По вполне очевидным причинам я не буду сообщать вам свой адрес, цену моей квартиры или другую подобную личную информацию. Поэтому до конца поста я буду делать вид, что купил свою квартиру за 100 евро (мне повезло!), И нормализовать все остальные цены таким же образом.
Как я упоминал выше, чтобы запросить модель, нам нужно создать новый набор данных, состоящий из данных, которые мы хотим протестировать. В моем случае мне просто нужно было создать новый файл csv из заголовка (вы должны сохранить его в файле, чтобы Dataiku его понял) и строку, которая относится к фактической транзакции, которую я совершил (легко, поскольку это уже было сделано).
Если бы я хотел сделать это для собственности, которую собирался купить, мне пришлось бы собрать как можно больше информации, чтобы наилучшим образом выполнить критерии в схеме (адрес, площадь, почтовый индекс, географические координаты и т. Д.) И построить эту линию. себя. На этом этапе я также могу создать набор данных из нескольких строк, чтобы запросить модель сразу по нескольким случаям.
Как только этот новый набор данных будет построен, просто загрузите его, как в первый раз, и вернитесь в представление потока. Там должен появиться ваш новый набор данных. Щелкните модель справа от потока, а затем действие «Оценка». Выберите образец набора данных, используйте параметры по умолчанию и запустите задание. Теперь у вас должен появиться новый набор данных в вашем потоке. Если вы изучите этот набор данных, вы увидите, что в конце есть новый столбец, содержащий прогнозы!
В моем случае для моей квартиры за 100 евро прогнозируемая цена составляет 105 евро. Это может означать две вещи:
- Модель, которую мы обучили, довольно хороша, а недвижимость была хорошей сделкой!
Или…
- Модель сделала удачную догадку.
Давайте попробуем другие транзакции, которые произошли на той же улице и в том же году. Что ж, на этот раз результат не впечатляет: очевидно, каждая квартира, купленная на моей улице в 2018 году, стоит ровно 105 евро, независимо от их размера и характеристик. Если бы я знал это, я бы, наверное, купил квартиру побольше! Казалось бы, наша модель не так умна, как мы изначально думали, и нам еще есть над чем поработать…
В этом посте мы изучили, где может пригодиться машинное обучение, какие данные будут полезны, какое программное обеспечение нам необходимо для его использования, а также рассмотрели инфраструктуру, необходимую для запуска программного обеспечения. Мы обнаружили, что каждый может попробовать машинное обучение — это не волшебство, — но мы также обнаружили, что нам придется немного усерднее работать, чтобы добиться результатов. В самом деле, бросаясь в чудесное путешествие, как мы, мы не уделили время более внимательному изучению самих данных и тому, как упростить использование модели, — и не посмотрели на то, что модель фактически наблюдала при прогнозировании цена. Если бы это было так, мы бы поняли, что это действительно бессмысленно. Другими словами, мы недостаточно квалифицировали нашу проблему. Но пусть это не умаляет нашего энтузиазма в нашем путешествии, поскольку это всего лишь небольшая неудача!
В следующем посте мы продолжим наше путешествие и поймем, почему модель, которую мы обучили, в конечном итоге оказалась бесполезной: мы более точно посмотрим на данные, которые есть в нашем распоряжении, и найдем несколько способов сделать ее более подходящей для машинного обучения. алгоритмы — следуя простым рекомендациям здравого смысла. Надеюсь, что с более точными данными мы сможем значительно улучшить нашу модель.
0 комментариев