Распределенное обучение в контексте глубокого обучения

Ранее в блоге OVHcloud…
В предыдущих сообщениях блога мы обсуждали высокоуровневый подход к глубокому обучению, а также то, что подразумевается под «обучением» по отношению к глубокому обучению.

После статьи у меня появилось много вопросов в моем твиттере, особенно относительно того, как на самом деле работают графические процессоры.
Поэтому я решил написать статью о том, как работают графические процессоры:
Во время нашего процесса исследований и разработок аппаратных средств и моделей искусственного интеллекта возник вопрос о распределенном обучении (быстро). Но прежде чем углубленно изучать распределенное обучение, я предлагаю вам прочитать следующую статью, чтобы понять, как на самом деле работает обучение с глубоким обучением:
Как обсуждалось ранее, обучение нейронных сетей зависит от:
- Входные данные
- Архитектура нейронной сети, состоящая из «слоев»
- Вес
- Скорость обучения (шаг, используемый для настройки весов нейронной сети)
Зачем нам нужно распределенное обучение
Глубокое обучение в основном используется для изучения шаблонов неструктурированных данных. Неструктурированные данные — например, текстовый корпус, изображение, видео или звук — могут представлять огромный объем данных для обучения.
Обучение такой библиотеки может занять несколько дней или даже недель из-за размера данных и / или размера сети.
Можно рассмотреть несколько подходов к распределенному обучению.
Различные подходы к распределенному обучению
Когда дело доходит до глубокого обучения, существует две основные категории распределенного обучения, и обе они основаны на парадигме «разделяй и властвуй».
Первая категория называется «Распределенный параллелизм данных», в которой данные разделяются между несколькими графическими процессорами.
Вторая категория называется «Параллелизм моделей», где модель глубокого обучения разделена на несколько графических процессоров .
Однако параллелизм распределенных данных является наиболее распространенным подходом, поскольку он подходит практически для любой проблемы . Второй подход имеет серьезные технические ограничения в отношении разделения модели. Разделение модели — это высокотехнологичный подход, поскольку вам необходимо знать пространство, используемое каждой частью сети в DRAM графического процессора. После того, как у вас есть использование DRAM для каждого фрагмента, вам необходимо обеспечить выполнение вычислений путем жесткого кодирования размещения слоев нейронной сети на желаемом графическом процессоре . Этот подход делает его связанным с оборудованием , поскольку DRAM может отличаться от одного графического процессора к другому, в то время как параллелизм распределенных данных просто требуеткорректировка размера данных (обычно размер пакета), что относительно просто .
Модель распределенного параллелизма данных имеет два варианта, каждый из которых имеет свои преимущества и недостатки. Первый вариант позволяет тренировать модель с синхронной регулировкой веса. То есть каждый пакет обучения в каждом графическом процессоре будет возвращать поправки, которые необходимо внести в модель для ее обучения. И что ему придется подождать, пока все рабочие завершат свою задачу, чтобы получить новый набор весов, чтобы он мог распознать это в следующем тренировочном пакете.
А второй вариант позволяет работать асинхронно . Это означает, что каждая партия каждого графического процессора будет сообщать нейронной сети об исправлениях, которые необходимо внести. Координатор веса будет посылать новый набор весов W ез ждет других графических процессоров до конца подготовки их собственной партии.
3 шпаргалки для лучшего понимания распределенного глубокого обучения
В этой шпаргалке предположим, что вы используете докер с прикрепленным томом.
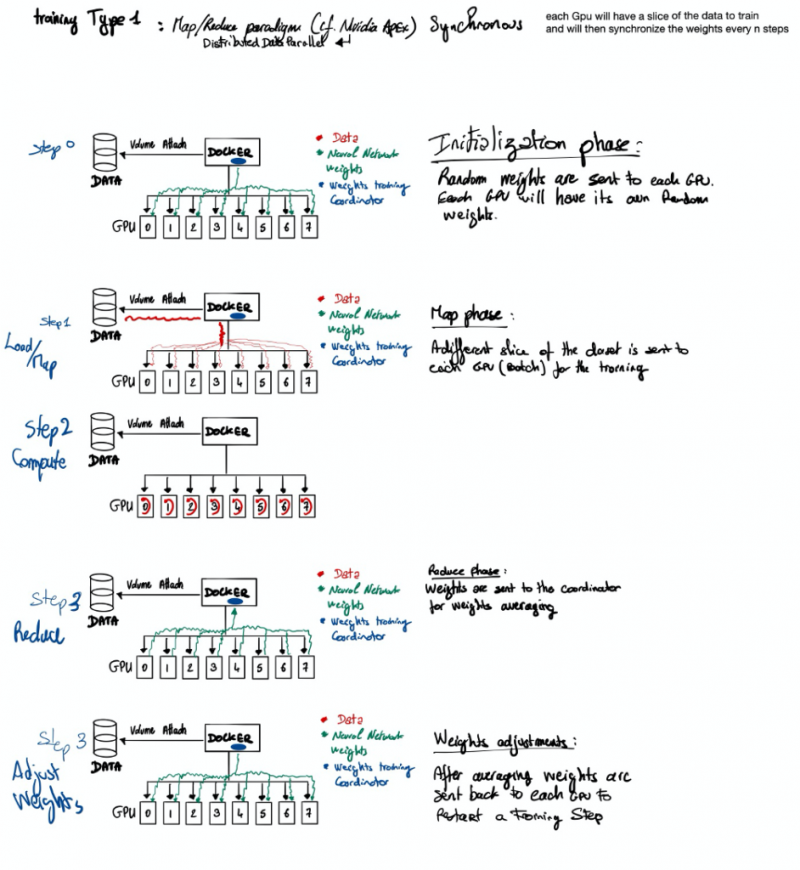
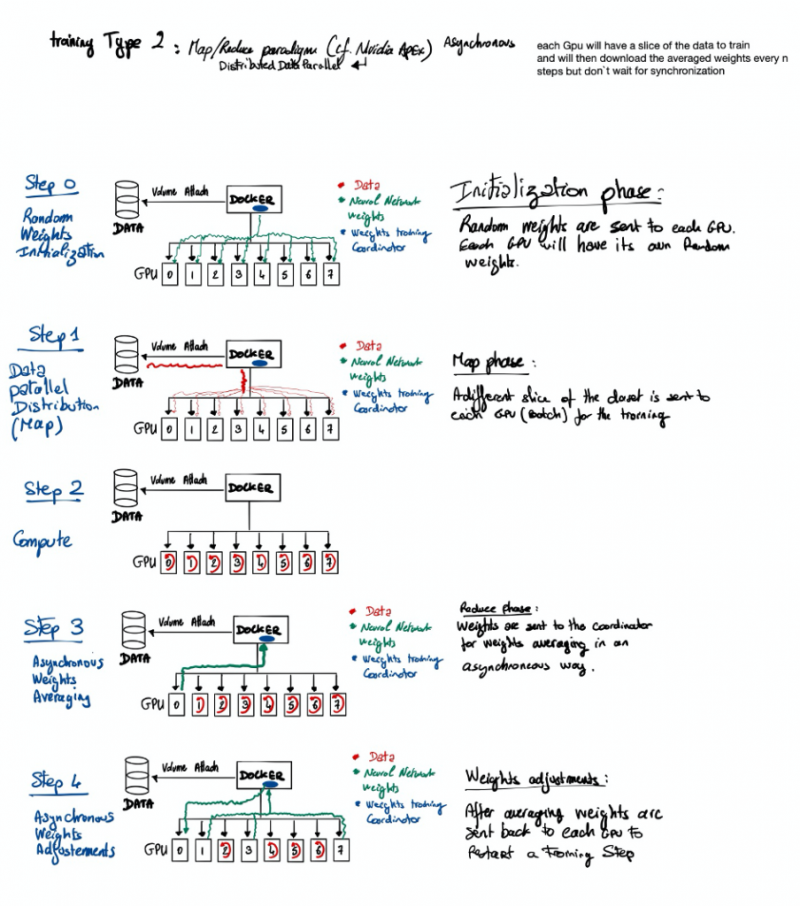
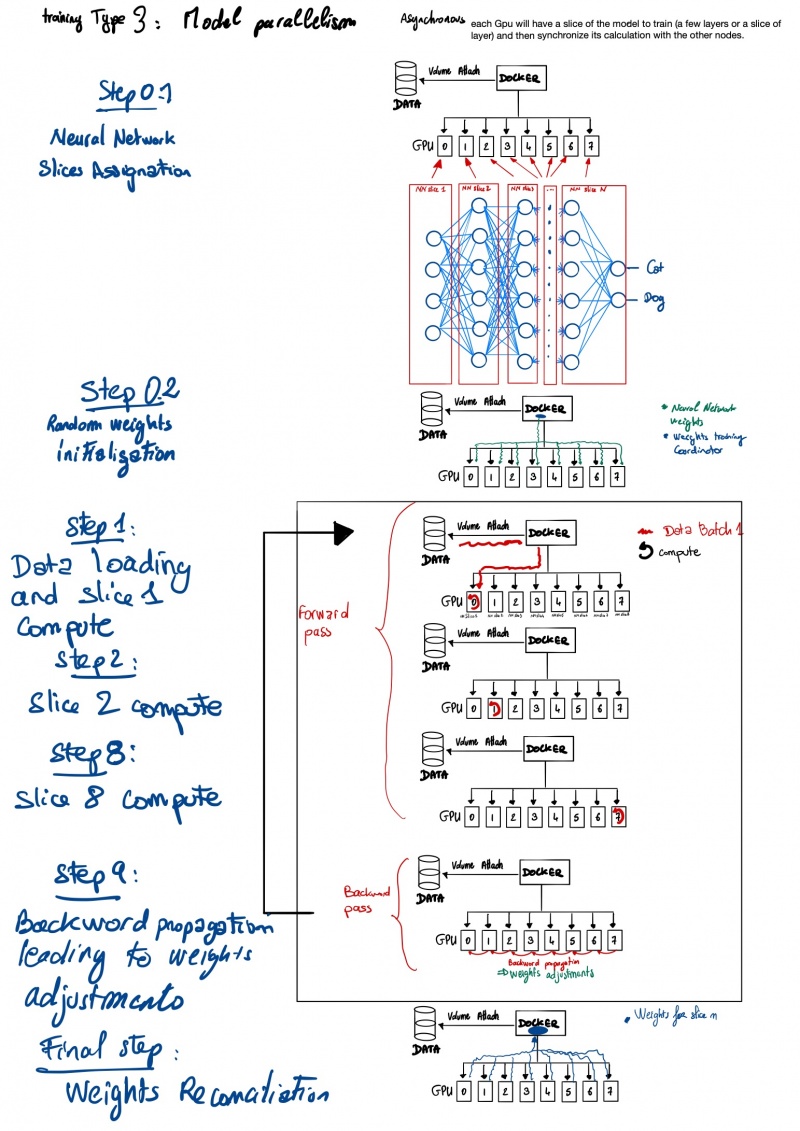

Теперь вам нужно выбрать стратегию распределенного обучения (с умом).
Дополнительная литература
Хотя мы многое рассмотрели в этом сообщении в блоге, мы почти не рассмотрели все аспекты распределенного обучения Deep Learning, включая предыдущую работу, историю и связанную с ней математику.
Я настоятельно рекомендую вам прочитать замечательную статью « Параллельное и распределенное глубокое обучение » Вишаха Хегде и Шимы Усмани (обе из Стэнфордского университета).
А также статью « Демистификация параллельного и распределенного глубокого обучения: углубленный анализ параллелизма», написанную Талом Бен-Нун и Торстеном Хефлером ETH Zurich, Switzerland. Я предлагаю вам начать с перехода к разделу 6.3 .
0 комментариев