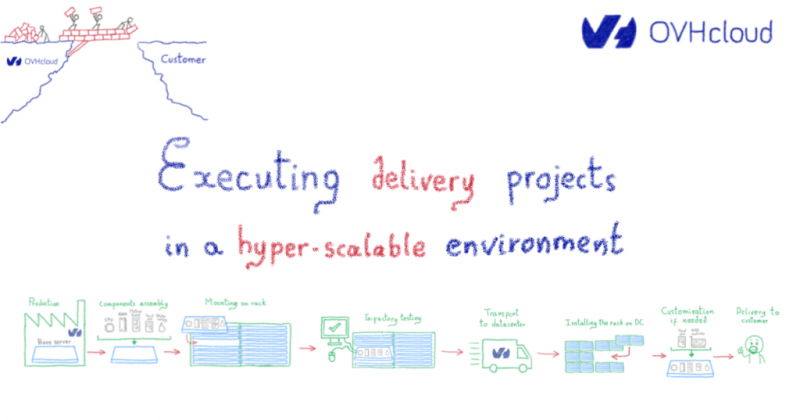
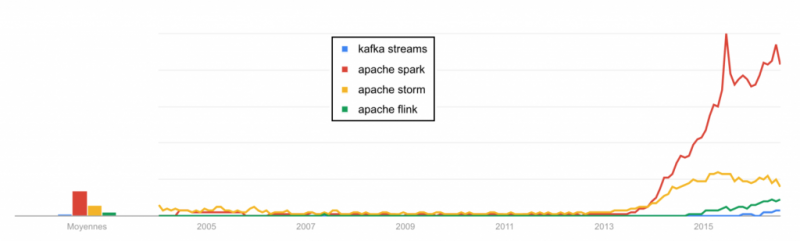
Почему вы все еще управляете кластерами обработки данных?
Кластерные вычисления используются для распределения вычислительной нагрузки между группой компьютеров. Таким образом достигается более высокий уровень производительности и масштабируемости.
Apache Spark — это среда распределенных кластерных вычислений с открытым исходным кодом, которая намного быстрее предыдущей (Hadoop MapReduce). Это благодаря таким функциям, как обработка в памяти и ленивая оценка. Apache Spark — самый популярный инструмент в этой категории.

Механизм аналитики — это ведущая платформа для крупномасштабного SQL, пакетной обработки, потоковой обработки и машинного обучения. Для кодирования в Spark у вас есть возможность использовать разные языки программирования; включая Java, Scala, Python, R и SQL. Его можно запускать локально на одной машине или на кластере компьютеров для распределения задач.
Используя Apache Spark, вы можете обрабатывать свои данные на локальном компьютере или можете создать кластер для отправки любого количества заданий обработки.
Вы можете создать свой кластер с физическими компьютерами в локальной среде, с виртуальными машинами в хостинговой компании или с любым поставщиком облачных услуг. Имея собственный кластер, у вас будет возможность отправлять задания Spark в любое время.
Если вы обрабатываете огромный объем данных и ожидаете получить результаты в разумные сроки, вашего локального компьютера будет недостаточно. Вам нужен кластер компьютеров для разделения данных и обработки рабочих нагрузок — несколько компьютеров работают параллельно, чтобы ускорить выполнение задачи.
Однако создание и управление собственным кластером компьютеров — непростая задача. Вы столкнетесь с несколькими проблемами:
Создание кластера Apache Spark — сложная задача.
Во-первых, вам нужно создать кластер компьютеров и установить операционную систему, инструменты разработки (Python, Java, Scala) и т. Д.
Во-вторых, вам нужно выбрать версию Apache Spark и установить необходимые узлы (мастер и рабочие).
Наконец, вам необходимо соединить все эти узлы вместе, чтобы завершить работу над кластером Apache Spark.
В целом создание и настройка нового кластера Apache Spark может занять несколько часов.
Но если у вас есть собственный кластер, ваша работа еще далека от завершения. Ваш кластер работает хорошо? Каждый ли узел здоров?
Вот вторая проблема: справиться с болью управления кластером!
Вам нужно будет проверить состояние всех ваших узлов вручную или, желательно, установить инструменты мониторинга, которые сообщают о любых проблемах, с которыми могут столкнуться узлы.
Достаточно ли на узлах дискового пространства для новых задач? Одна из ключевых проблем, с которыми сталкиваются кластеры Apache Spark, заключается в том, что некоторые задачи записывают большой объем данных в локальное дисковое пространство узлов, не удаляя их. Дисковое пространство — распространенная проблема, и, как вы, возможно, знаете, нехватка дискового пространства исключает возможность выполнения большего количества задач.
Вам нужно запускать несколько заданий Spark одновременно? Иногда одно задание занимает все ресурсы ЦП и ОЗУ в вашем кластере и не позволяет другим заданиям запускаться и выполняться одновременно.
Это лишь некоторые из проблем, с которыми вы столкнетесь при работе с собственными кластерами.
Теперь о третьем испытании! Что может быть даже важнее, чем бесперебойная работа кластера?
Как вы уже догадались: безопасность. В конце концов, Apache Spark — это инструмент для обработки данных. И данные очень чувствительны.
Где в вашем кластере безопасность имеет наибольшее значение?
А как насчет связи между узлами? Связаны ли они с безопасным (и быстрым) соединением? У кого есть доступ к серверам вашего кластера?
Если вы создали свой кластер в облаке и работаете с конфиденциальными данными, вам необходимо решить эти проблемы путем защиты каждого узла и шифрования связи между ними.
Вот ваша четвертая задача: управление ожиданиями пользователей вашего кластера. В некоторых случаях это может быть менее сложной задачей, но не во всех.
Вы мало что можете сделать, чтобы изменить ожидания пользователей кластера, но вот типичный пример, который поможет вам подготовиться:
Ваши пользователи любят тестировать свои коды с разными версиями Apache Spark? Или им нужна последняя функция из последней ночной версии Spark?
Когда вы создаете кластер Apache Spark, вы должны выбрать одну версию Spark. Весь ваш кластер будет связан с ним, и это в одиночку. Это означает, что несколько версий не могут сосуществовать в одном кластере.
Итак, вам придется либо изменить версию Spark для всего кластера, либо создать еще один отдельный кластер. И, конечно же, если вы решите это сделать, вам нужно создать в кластере время простоя для внесения изменений.
И последний вызов: масштабирование!
Как получить максимальную выгоду от ресурсов кластера, за которые вы платите? Вы платите за свой кластер, но чувствуете, что используете его неэффективно? Ваш кластер слишком велик для ваших пользователей? Он работает, но в праздничные дни там нет рабочих мест?
Когда у вас есть обрабатывающий кластер — особенно если у вас много ценных ресурсов в кластере, за которые вы платите, — у вас всегда будет одна серьезная проблема: используется ли ваш кластер как можно более эффективно. Бывают случаи, когда некоторые ресурсы в вашем кластере простаивают, или когда вы выполняете только небольшие задания, которые не требуют количества ресурсов в вашем кластере. Масштабирование станет серьезной проблемой.
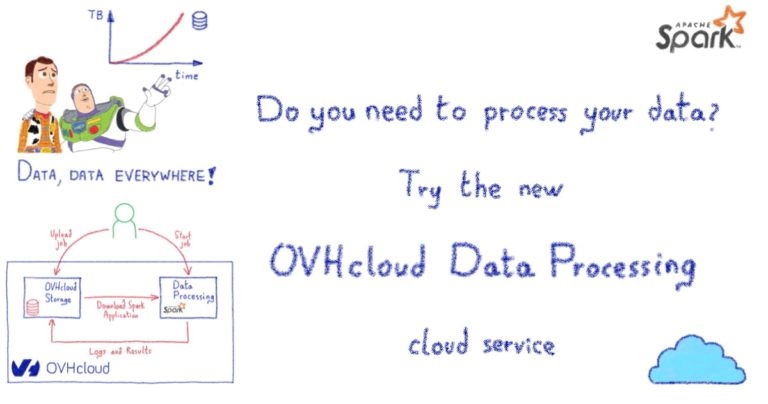
В OVHcloud мы создали новую службу данных под названием OVHcloud Data Processing (ODP) для решения всех проблем управления кластером, упомянутых выше.
Предположим, у вас есть некоторые данные для обработки, но у вас нет желания, времени, бюджета или навыков для решения этих проблем. Возможно, вы не хотите или не можете просить помощи у коллег или консультантов для создания кластера и управления им. Как вы все еще можете использовать Apache Spark? Здесь на помощь приходит служба ODP!
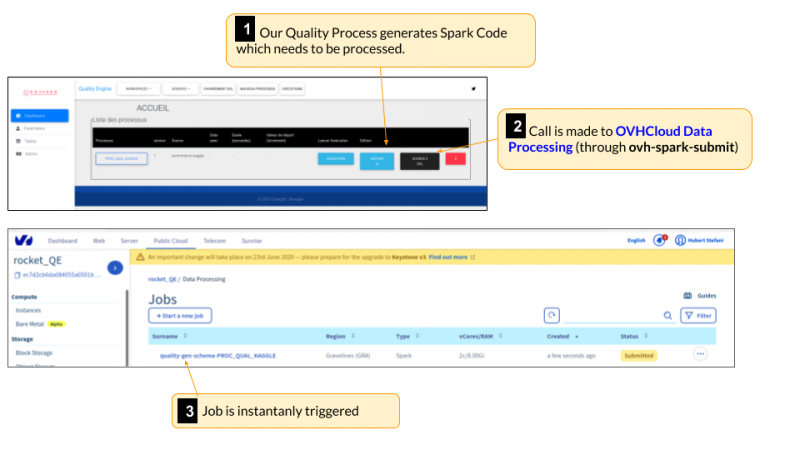
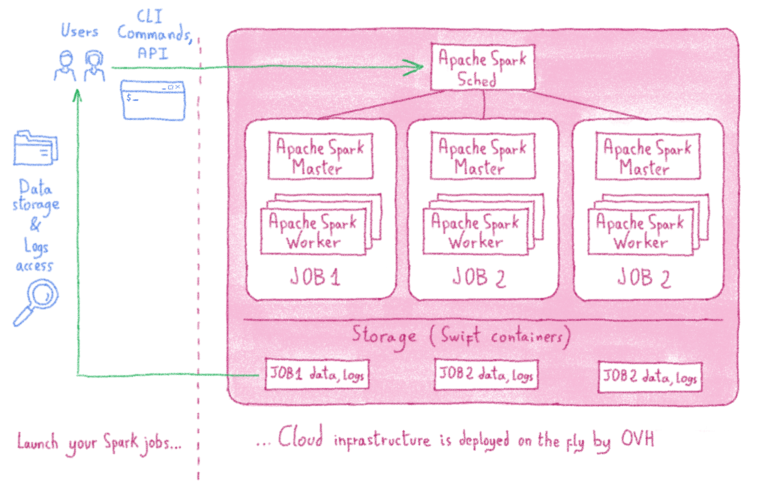
Используя ODP, вам нужно написать свой код Apache Spark, а все остальное сделает ODP. Он создаст одноразовый выделенный кластер Apache Spark в облаке для каждого задания всего за несколько секунд, а затем удалит весь кластер после завершения задания. Вы платите только за запрошенные ресурсы и только на время вычисления. Нет необходимости оплачивать часы работы облачных серверов, пока вы заняты установкой, настройкой кластера или даже отладкой и обновлением версии движка.
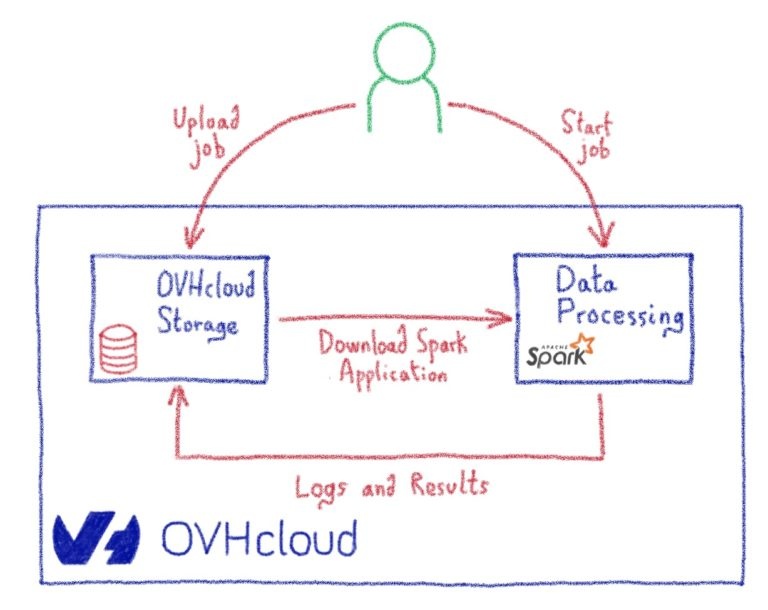
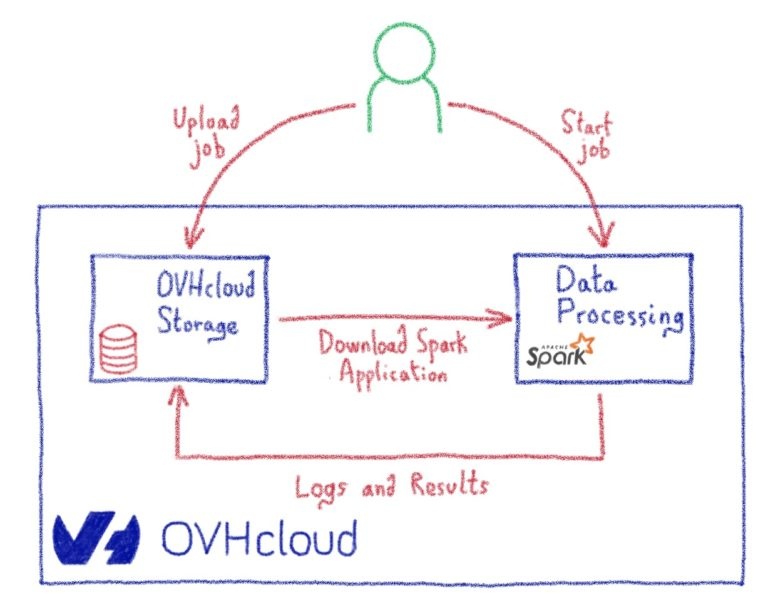
Когда вы отправляете свою работу, ODP создаст искровой кластер apache, посвященный этой работе, всего за несколько секунд. Этот кластер будет иметь количество ЦП и ОЗУ, а также количество рабочих, указанных в форме отправки задания. Все необходимое программное обеспечение будет установлено автоматически. Вам не нужно вообще беспокоиться о кластере, о том, как его установить, настроить или защитить. ODP сделает все это за вас.
Когда вы отправляете свою работу, управление и мониторинг кластера настраиваются и обрабатываются ODP. Все механизмы и инструменты ведения журналов и мониторинга будут установлены автоматически. У вас будет панель управления Grafana для мониторинга различных параметров и ресурсов вашей работы, а также у вас будет доступ к официальной панели инструментов Apache Spark.
Вам не нужно беспокоиться об очистке локального диска каждого узла, потому что каждое задание будет начинаться со свежих ресурсов. Следовательно, одно задание не может отложить другое задание, поскольку каждое задание имеет новые выделенные ресурсы.
ODP также позаботится о безопасности и конфиденциальности вашего кластера. Во-первых, все коммуникации между узлами Spark зашифрованы. Во-вторых, ни один из узлов вашей работы не доступен извне. ODP позволяет открывать только ограниченные порты для вашего кластера, так что вы по-прежнему можете загружать или передавать свои данные.
Когда дело доходит до использования нескольких версий Spark в одном кластере, ODP предлагает решение. Поскольку каждое задание обладает собственными выделенными ресурсами, каждое задание может использовать любую версию, которая в настоящее время поддерживается службой, независимо от любого другого задания, выполняющегося в то же время. При отправке задания Apache Spark через ODP вы сначала выбираете версию Apache Spark, которую хотите использовать. Когда сообщество Apache Spark выпустит новую версию, она скоро станет доступной в ODP, и вы также сможете отправить другое задание с новой версией Spark. Это означает, что вам больше не нужно постоянно обновлять версию Spark для всего кластера.
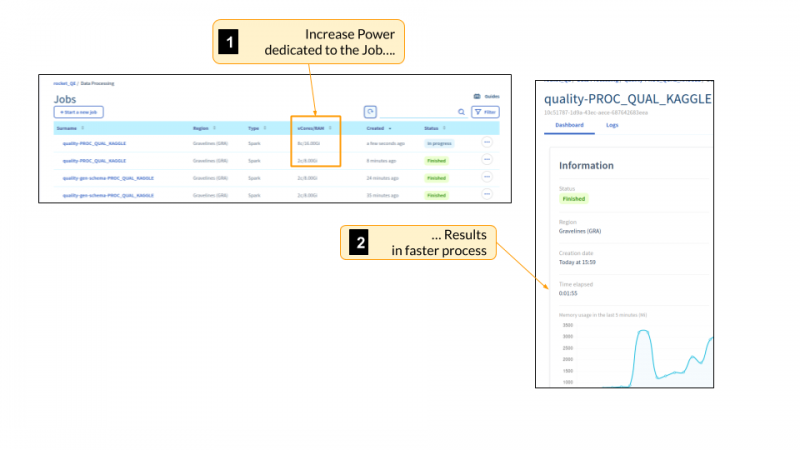
Каждый раз, когда вы отправляете задание, вам нужно будет точно определить, сколько ресурсов и рабочих вы хотите использовать для этого задания. Как было сказано ранее, каждое задание имеет свои собственные выделенные ресурсы, поэтому вы сможете выполнять небольшие задания вместе с гораздо более крупными. Такая гибкость означает, что вам никогда не придется беспокоиться о простаивающем кластере. Вы платите за ресурсы, которые используете, когда вы их используете.
Если вы хотите попробовать ODP, вы можете проверить: www.ovhcloud.com/en/public-cloud/data-processing/ или вы можете легко создать учетную запись на www.ovhcloud.com и выбрать « обработка данных »в разделе публичного облака. Также можно задать вопросы непосредственно от команды разработчиков в общедоступном канале Gitter ODP gitter.im/ovh/data-processing.
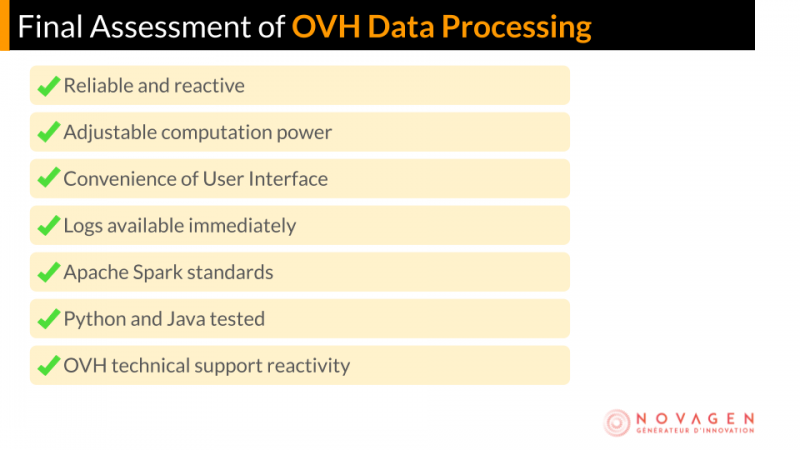
С ODP проблемы, связанные с запуском кластера Apache Spark, устраняются или упрощаются (мы по-прежнему мало что можем поделать с ожиданиями пользователей!). Вам не нужно беспокоиться о нехватке ресурсов, необходимых для обработки ваших данных, или необходимо создать, установить и управлять собственным кластером.
Сосредоточьтесь на своем алгоритме обработки, а остальное сделает ODP.
Apache Spark — это среда распределенных кластерных вычислений с открытым исходным кодом, которая намного быстрее предыдущей (Hadoop MapReduce). Это благодаря таким функциям, как обработка в памяти и ленивая оценка. Apache Spark — самый популярный инструмент в этой категории.
Механизм аналитики — это ведущая платформа для крупномасштабного SQL, пакетной обработки, потоковой обработки и машинного обучения. Для кодирования в Spark у вас есть возможность использовать разные языки программирования; включая Java, Scala, Python, R и SQL. Его можно запускать локально на одной машине или на кластере компьютеров для распределения задач.
Используя Apache Spark, вы можете обрабатывать свои данные на локальном компьютере или можете создать кластер для отправки любого количества заданий обработки.
Вы можете создать свой кластер с физическими компьютерами в локальной среде, с виртуальными машинами в хостинговой компании или с любым поставщиком облачных услуг. Имея собственный кластер, у вас будет возможность отправлять задания Spark в любое время.
Проблемы управления кластером
Если вы обрабатываете огромный объем данных и ожидаете получить результаты в разумные сроки, вашего локального компьютера будет недостаточно. Вам нужен кластер компьютеров для разделения данных и обработки рабочих нагрузок — несколько компьютеров работают параллельно, чтобы ускорить выполнение задачи.
Однако создание и управление собственным кластером компьютеров — непростая задача. Вы столкнетесь с несколькими проблемами:
Создание кластера
Создание кластера Apache Spark — сложная задача.
Во-первых, вам нужно создать кластер компьютеров и установить операционную систему, инструменты разработки (Python, Java, Scala) и т. Д.
Во-вторых, вам нужно выбрать версию Apache Spark и установить необходимые узлы (мастер и рабочие).
Наконец, вам необходимо соединить все эти узлы вместе, чтобы завершить работу над кластером Apache Spark.
В целом создание и настройка нового кластера Apache Spark может занять несколько часов.
Управление кластером
Но если у вас есть собственный кластер, ваша работа еще далека от завершения. Ваш кластер работает хорошо? Каждый ли узел здоров?
Вот вторая проблема: справиться с болью управления кластером!
Вам нужно будет проверить состояние всех ваших узлов вручную или, желательно, установить инструменты мониторинга, которые сообщают о любых проблемах, с которыми могут столкнуться узлы.
Достаточно ли на узлах дискового пространства для новых задач? Одна из ключевых проблем, с которыми сталкиваются кластеры Apache Spark, заключается в том, что некоторые задачи записывают большой объем данных в локальное дисковое пространство узлов, не удаляя их. Дисковое пространство — распространенная проблема, и, как вы, возможно, знаете, нехватка дискового пространства исключает возможность выполнения большего количества задач.
Вам нужно запускать несколько заданий Spark одновременно? Иногда одно задание занимает все ресурсы ЦП и ОЗУ в вашем кластере и не позволяет другим заданиям запускаться и выполняться одновременно.
Это лишь некоторые из проблем, с которыми вы столкнетесь при работе с собственными кластерами.
Безопасность кластера
Теперь о третьем испытании! Что может быть даже важнее, чем бесперебойная работа кластера?
Как вы уже догадались: безопасность. В конце концов, Apache Spark — это инструмент для обработки данных. И данные очень чувствительны.
Где в вашем кластере безопасность имеет наибольшее значение?
А как насчет связи между узлами? Связаны ли они с безопасным (и быстрым) соединением? У кого есть доступ к серверам вашего кластера?
Если вы создали свой кластер в облаке и работаете с конфиденциальными данными, вам необходимо решить эти проблемы путем защиты каждого узла и шифрования связи между ними.
Версия Spark
Вот ваша четвертая задача: управление ожиданиями пользователей вашего кластера. В некоторых случаях это может быть менее сложной задачей, но не во всех.
Вы мало что можете сделать, чтобы изменить ожидания пользователей кластера, но вот типичный пример, который поможет вам подготовиться:
Ваши пользователи любят тестировать свои коды с разными версиями Apache Spark? Или им нужна последняя функция из последней ночной версии Spark?
Когда вы создаете кластер Apache Spark, вы должны выбрать одну версию Spark. Весь ваш кластер будет связан с ним, и это в одиночку. Это означает, что несколько версий не могут сосуществовать в одном кластере.
Итак, вам придется либо изменить версию Spark для всего кластера, либо создать еще один отдельный кластер. И, конечно же, если вы решите это сделать, вам нужно создать в кластере время простоя для внесения изменений.
Эффективность кластера
И последний вызов: масштабирование!
Как получить максимальную выгоду от ресурсов кластера, за которые вы платите? Вы платите за свой кластер, но чувствуете, что используете его неэффективно? Ваш кластер слишком велик для ваших пользователей? Он работает, но в праздничные дни там нет рабочих мест?
Когда у вас есть обрабатывающий кластер — особенно если у вас много ценных ресурсов в кластере, за которые вы платите, — у вас всегда будет одна серьезная проблема: используется ли ваш кластер как можно более эффективно. Бывают случаи, когда некоторые ресурсы в вашем кластере простаивают, или когда вы выполняете только небольшие задания, которые не требуют количества ресурсов в вашем кластере. Масштабирование станет серьезной проблемой.
Решение OVHcloud для обработки данных (ODP)
В OVHcloud мы создали новую службу данных под названием OVHcloud Data Processing (ODP) для решения всех проблем управления кластером, упомянутых выше.
Предположим, у вас есть некоторые данные для обработки, но у вас нет желания, времени, бюджета или навыков для решения этих проблем. Возможно, вы не хотите или не можете просить помощи у коллег или консультантов для создания кластера и управления им. Как вы все еще можете использовать Apache Spark? Здесь на помощь приходит служба ODP!
Используя ODP, вам нужно написать свой код Apache Spark, а все остальное сделает ODP. Он создаст одноразовый выделенный кластер Apache Spark в облаке для каждого задания всего за несколько секунд, а затем удалит весь кластер после завершения задания. Вы платите только за запрошенные ресурсы и только на время вычисления. Нет необходимости оплачивать часы работы облачных серверов, пока вы заняты установкой, настройкой кластера или даже отладкой и обновлением версии движка.
Создание кластера ODP
Когда вы отправляете свою работу, ODP создаст искровой кластер apache, посвященный этой работе, всего за несколько секунд. Этот кластер будет иметь количество ЦП и ОЗУ, а также количество рабочих, указанных в форме отправки задания. Все необходимое программное обеспечение будет установлено автоматически. Вам не нужно вообще беспокоиться о кластере, о том, как его установить, настроить или защитить. ODP сделает все это за вас.
Управление кластером ODP
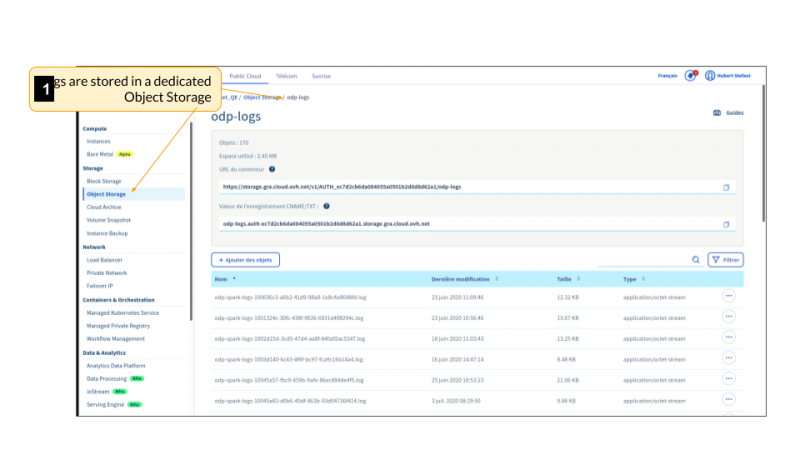
Когда вы отправляете свою работу, управление и мониторинг кластера настраиваются и обрабатываются ODP. Все механизмы и инструменты ведения журналов и мониторинга будут установлены автоматически. У вас будет панель управления Grafana для мониторинга различных параметров и ресурсов вашей работы, а также у вас будет доступ к официальной панели инструментов Apache Spark.
Вам не нужно беспокоиться об очистке локального диска каждого узла, потому что каждое задание будет начинаться со свежих ресурсов. Следовательно, одно задание не может отложить другое задание, поскольку каждое задание имеет новые выделенные ресурсы.
Безопасность кластера ODP
ODP также позаботится о безопасности и конфиденциальности вашего кластера. Во-первых, все коммуникации между узлами Spark зашифрованы. Во-вторых, ни один из узлов вашей работы не доступен извне. ODP позволяет открывать только ограниченные порты для вашего кластера, так что вы по-прежнему можете загружать или передавать свои данные.
Версия ODP Cluster Spark
Когда дело доходит до использования нескольких версий Spark в одном кластере, ODP предлагает решение. Поскольку каждое задание обладает собственными выделенными ресурсами, каждое задание может использовать любую версию, которая в настоящее время поддерживается службой, независимо от любого другого задания, выполняющегося в то же время. При отправке задания Apache Spark через ODP вы сначала выбираете версию Apache Spark, которую хотите использовать. Когда сообщество Apache Spark выпустит новую версию, она скоро станет доступной в ODP, и вы также сможете отправить другое задание с новой версией Spark. Это означает, что вам больше не нужно постоянно обновлять версию Spark для всего кластера.
Эффективность кластера ODP
Каждый раз, когда вы отправляете задание, вам нужно будет точно определить, сколько ресурсов и рабочих вы хотите использовать для этого задания. Как было сказано ранее, каждое задание имеет свои собственные выделенные ресурсы, поэтому вы сможете выполнять небольшие задания вместе с гораздо более крупными. Такая гибкость означает, что вам никогда не придется беспокоиться о простаивающем кластере. Вы платите за ресурсы, которые используете, когда вы их используете.
Как начать?
Если вы хотите попробовать ODP, вы можете проверить: www.ovhcloud.com/en/public-cloud/data-processing/ или вы можете легко создать учетную запись на www.ovhcloud.com и выбрать « обработка данных »в разделе публичного облака. Также можно задать вопросы непосредственно от команды разработчиков в общедоступном канале Gitter ODP gitter.im/ovh/data-processing.
Вывод
С ODP проблемы, связанные с запуском кластера Apache Spark, устраняются или упрощаются (мы по-прежнему мало что можем поделать с ожиданиями пользователей!). Вам не нужно беспокоиться о нехватке ресурсов, необходимых для обработки ваших данных, или необходимо создать, установить и управлять собственным кластером.
Сосредоточьтесь на своем алгоритме обработки, а остальное сделает ODP.