Механизм интерпретации: инструмент с открытым исходным кодом для интерпретации ваших моделей в ML Serving
Контекст
Искусственный интеллект теперь является частью нашей повседневной жизни, и услуги, которые он предоставляет, продолжают процветать во многих отраслях. В OVHCloud мы недавно запустили обслуживание машинного обучения; сервис для развертывания моделей машинного обучения, готовых к использованию в производстве.
Скорее всего, вы читали статьи о методах машинного обучения (ML) или даже использовали модели машинного обучения — возможно, это заставило вас усомниться в их использовании в производственных системах. В самом деле, даже если модель дает интересные результаты, результаты могут показаться практикам неясными. Не всегда очевидно, почему модель приняла решение, особенно когда есть много функций с различными значениями и метками. Для неопытных пользователей предсказание будет казаться волшебным. В ответ на это новая область исследований, известная как интерпретируемость, направлена на демистификацию моделей черного ящика. Исследование интерпретирует объяснения прогнозов, что, в свою очередь, дает пользователям уверенность в результатах. Таким же образом подтверждается использование моделей в производстве.
Чтобы преодолеть эту проблему, мы вместе с Университетом Лилля и Центрального Лилля инициировали проект, заключающийся в разработке современных методов интерпретируемости, не зависящих от моделей.
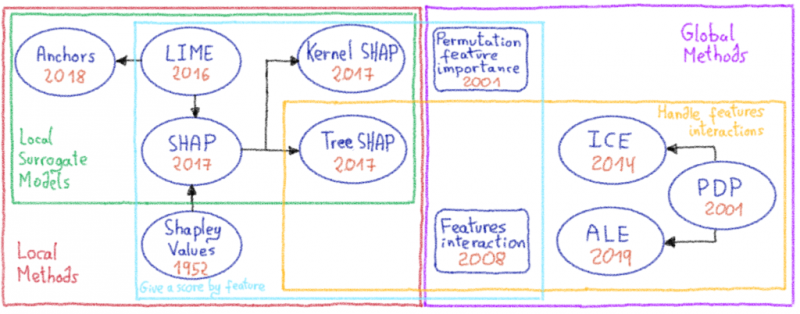
Классификация метода изображена на рисунке выше. Во-первых, мы отделяем локальные методы от глобальных. Локальные методы объясняют один прогноз, сделанный моделью, в то время как глобальные методы исследуют поведение всех функций для набора образцов. Во-вторых, мы различаем способ представления результатов методами (например, ранжирование важности признаков, график прогнозирования воздействия для значений признаков, дерево правил и т. Д.…).
В механизме интерпретируемости мы начали сосредотачиваться на локальном методе PDP, который эффективен в вычислительном отношении и прост для понимания.
Механизм интерпретации
Использовать механизм интерпретируемости довольно просто. Чтобы установить инструмент, вы можете ввести его pip install interpretability-engine, а затем использовать его через интерфейс командной строки.
На этом этапе мы предполагаем, что у вас уже есть развернутая модель с токеном, URL-адресом развертывания и образцами. Затем вы можете попытаться объяснить свою модель с помощью следующей команды:
interpretability-engine --token XXX --deployment-url https://localhost:8080 --samples-path my_dataset.csv --features 0 1 2 --method 'pdp'Примечание: 0 1 2 — это указатели характеристик
Вы также можете получить образцы, хранящиеся в хранилище объектов, с помощью swift, см .: interpretability-engine --help.
Пример в наборе данных iris
Теперь давайте попробуем конкретный пример на наборе данных радужной оболочки глаза. Мы обучили модель с помощью scikit, экспортируем ее в формат ONNX и развертываем на ML Serving, см. Документацию.
Затем мы использовали весь набор данных радужной оболочки в качестве образца, что позволило нам получить максимум информации о модели.
Примеры выглядят так (формат csv):
4.7,3.2,1.3,.2
4.6,3.1,1.5,.2
5,3.6,1.4,.2
5.4,3.9,1.7,.4
...Примечания :
- Каждая строка — это экземпляр, а каждый столбец — это функция.
- Первый столбец соответствует
, второй -sepal.length
, третий -sepal.width
и последний -petal.length
.petal.width - Порядок функции должен соответствовать порядку функции в экспортированном формате, см. Ограничения, подробно описанные ниже.
Затем запускаем следующую команду:
interpretability-engine --token xxx --deployment-url https://xxxx.c1.gra.serving.ai.ovh.net/iris/ --samples-path iris.csv --features 0 1 2 3 --feature-names "sepal.length" "sepal.width" "petal.length" "petal.width" --label-names "setosa" "vergicolor" "virginica"И получаем следующий рисунок:
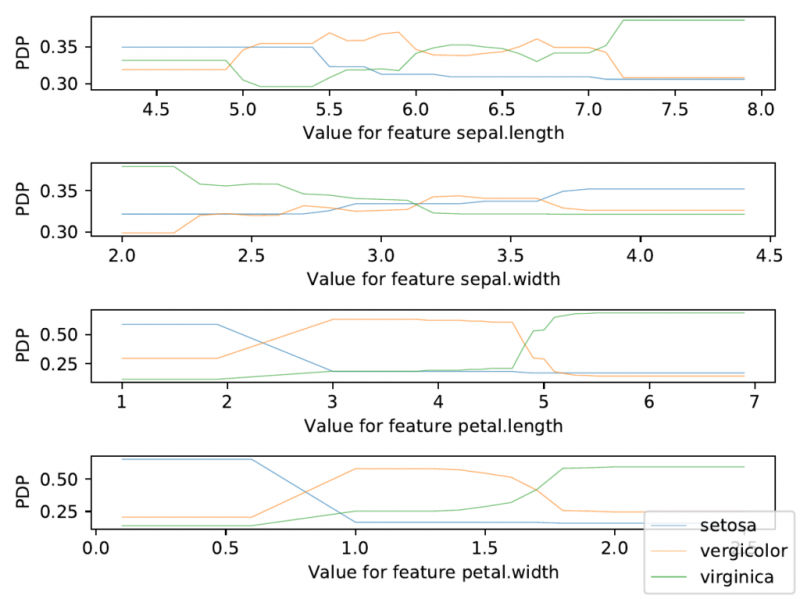
Ось PDP соответствует среднему значению воздействия на модель. В этом примере это их вероятность для каждой метки. Например, чем больше длина чашелистика, тем выше вероятность, что это будет вид «вергиника».
Примечание: если вы хотите сохранить результат, используйте опцию--output-file you-result-filename.pdf
Ограничения и будущая работа
Interpretability Engine — это первый шаг к объяснению модели, но текущая реализация включает ограничения.
Среди них — отсутствие методов. На данный момент доступен только один глобальный метод (PDP). Мы планируем добавить дополнительные методы, более эффективные с точки зрения вычислений, такие как ALE. Мы также планируем добавить локальные методы с целью объяснения одного прогноза. Самый эффективный с точки зрения вычислений — LIME. Другие методы, такие как [Anchors] () или [SHAP] (), звучат многообещающе, но пока остаются дорогими.
Другое ограничение связано с именами функций, которые зависят от того, как вы экспортировали свою модель. Модель, обученная в scikit и экспортированная в формат ONNX, будет иметь только один вход с формой, соответствующей количеству функций. Следовательно, функции не имеют имен и основаны на их индексах. Чтобы решить эту проблему, мы позволяем пользователю сопоставлять указатель функций с именами с помощью этой опции --feature-names. Таким образом, когда объяснение экспортируется, его легче читать. Аналогичная проблема существует с этикетками, в этом случае вы можете использовать эту опцию --label-names.
Мы не пробовали использовать метод PDP на более сложных примерах (изображения, видео, песни). Мы рассматривали данные только в табличном представлении, и нам нужен механизм для обработки других случаев.
На данный момент экспортированные результаты доступны для чтения, когда есть некоторые функции, но остается вопрос, как представить сотни функций с помощью методов PDP?
Открытый источник
Открытый исходный код является частью культуры OVHCloud, поэтому мы сделали инструмент доступным на Github. Если у вас есть какие-либо мысли по поводу улучшений, не стесняйтесь сообщить нам об этом через PR.
0 комментариев