ML Serving: облачный инструмент для развертывания машинного обучения
Сегодня мы рады объявить о выпуске нового продукта Public Cloud . Чтобы ускорить и упростить ваши проекты машинного обучения, мы вводим ML Serving .
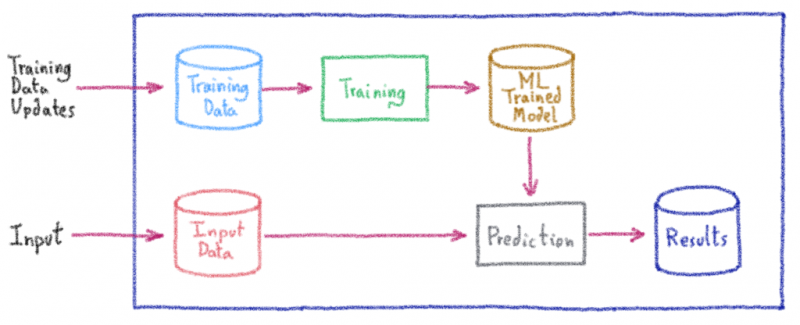
В OVHcloud мы используем несколько моделей машинного обучения, которые помогают принимать решения; начиная от борьбы с мошенничеством и заканчивая улучшением обслуживания нашей инфраструктуры. В недавнем сообщении в блоге мы представили платформу машинного обучения, которая ускоряет создание прототипов. Одна из ключевых особенностей платформы — возможность напрямую предоставлять прототипы через надежный веб-API .
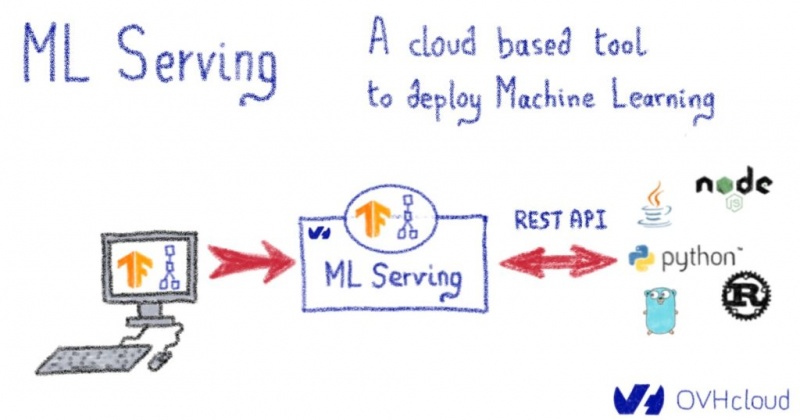
Однако для конкретных случаев использования — или для изучения современных компонентов машинного обучения — практики не могут ограничиться использованием только этой платформы. Таким образом, перед этими проектами стоит одна из основных проблем машинного обучения : переход от стадии прототипа к реальной системе производственного уровня , которая является надежной и доступной для бизнес-приложений. Чтобы восполнить этот пробел , мы разработали ML Serving — инструмент для управления процессом индустриализации.
Используя преимущества стандартных форматов с открытым исходным кодом, таких как Tensorflow SavedModel, ML Serving позволяет пользователям легко развертывать свои модели, используя при этом важные функции, включая инструментарий, масштабируемость и управление версиями моделей . В этой статье мы познакомим вас с основными компонентами и функциями инструмента.
Служба ML была разработана для удовлетворения следующих требований:
Для достижения этих целей мы основали наш дизайн на микросервисной архитектуре, опирающейся на инфраструктуру Kubernetes. Проект разделен на два основных компонента:
Компонент Serving Runtime является автономным и нацелен на упрощение использования и доступа. Таким образом, его две основные задачи — загрузить модели и раскрыть их.
Мы обнаружили, что самый простой способ раскрыть модель — использовать HTTP API. Затем он легко интегрируется в любое бизнес-приложение. Среда выполнения обслуживания предоставляет API, ограниченный тем, что важно — конечную точку для описания модели и другую для ее оценки.
Входные данные API по умолчанию отформатированы как тензоры JSON. Ниже приведен пример входной полезной нагрузки для набора данных Титаника при оценке шансов на выживание двух пассажиров:
Тензоры используются для универсальной адресации всех обслуживающих моделей. Однако представление может быть трудным для понимания и в некоторых случаях может быть упрощено. В случае вывода только для одного пассажира JSON выглядит так:
ML Serving также поддерживает распространенные форматы изображений, такие как JPG и PNG.
Теперь, когда мы определили API, нам нужно загрузить модели и оценить их. Модели загружаются на основе стандартов сериализации, из которых поддерживаются следующие:
Выделенный модуль, заключенный в общий интерфейс, поддерживает каждый из этих форматов. Если возникнут или потребуются дополнительные форматы, их можно будет легко добавить как новые модули. Полагаясь исключительно на стандартные форматы, система обеспечивает обратимость. Это означает, что специалисты по машинному обучению могут использовать их на различных языках и в библиотеках вне среды выполнения.
Среду выполнения обслуживания можно запускать непосредственно из экспортированных файлов модели или из более гибкой точки входа — манифеста. Манифест — это описание последовательности нескольких моделей или оценщиков. Используя манифест, пользователи могут описать последовательность оценщиков, выходные данные которой могут быть переданы непосредственно последующим оценщикам. Другими словами, специалисты-практики могут объединить их в уникальное развертывание модели.
Обычный вариант использования такой комбинации включает в себя предварительную обработку данных на основе пользовательских оценщиков перед подачей фактической модели или разметку предложений перед оценкой некоторой нейронной сети.
Эта часть все еще является экспериментальной и оказалась сложной с точки зрения простоты использования и обратимости. Тем не менее, это окажется важным в некоторых случаях использования, например, при токенизации предложений перед оценкой модели на основе BERT.
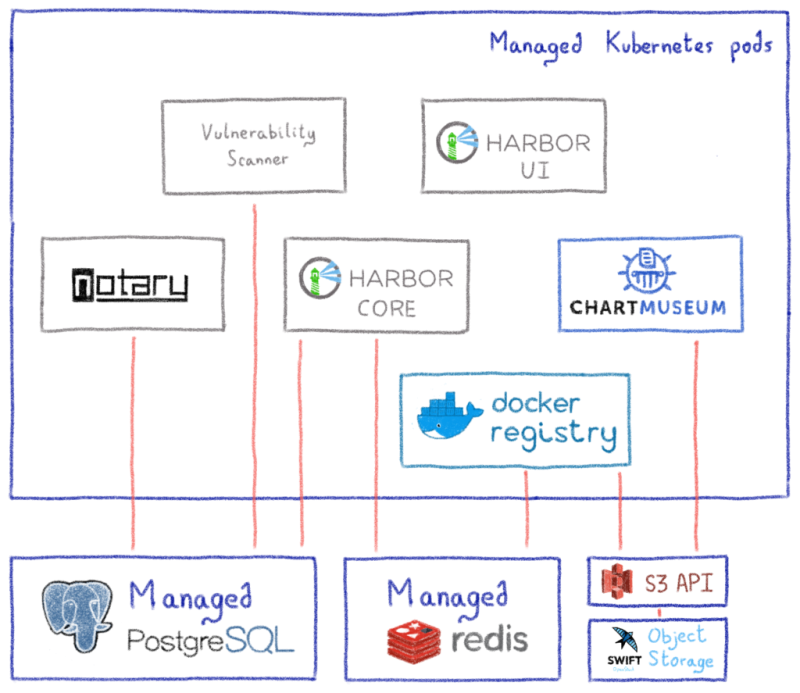
Компонент Serving Hub направлен на удовлетворение всех требований производственного уровня: управление версиями, безопасность, развертывание и высокая доступность.
Его основные задачи — это упаковка Serving Runtime с экспортированными моделями в образ Docker, а затем их развертывание в кластере Kubernetes. В глобальном масштабе компонент во многом полагается на свои функции Kubernetes. Например, для концентратора не требуется база данных, поскольку вся информация о моделях и развертываниях хранится в виде настраиваемых ресурсов Kubernetes.
Центр обслуживания предоставляет два API — API аутентификации, который защищает доступ к модели и управление ею с помощью токенов JWT, и второй, предназначенный для самого управления моделью.
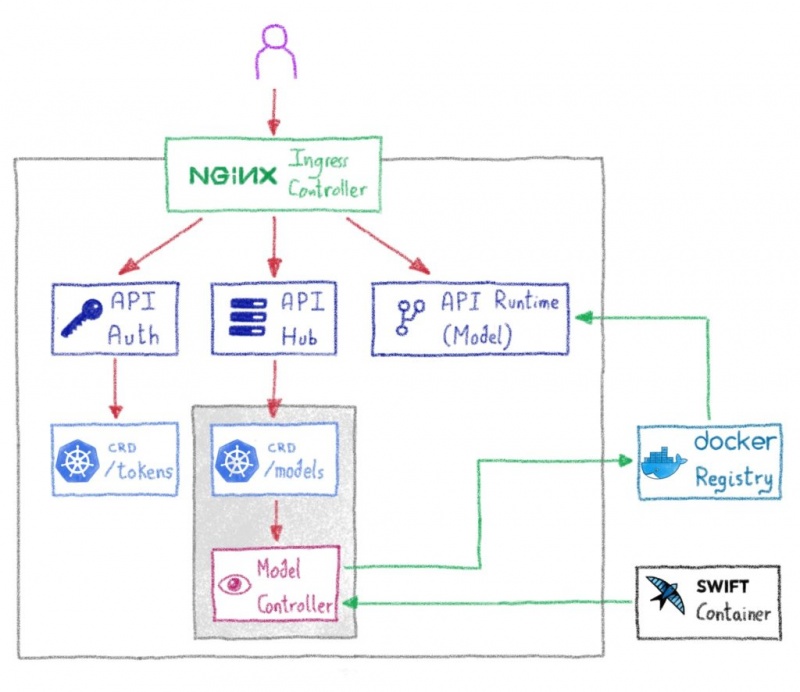
При использовании API управления моделями развертывание модели так же просто, как предоставление имени и пути к файлам модели в серверной части хранилища. Затем Serving Hub запускает рабочий процесс для создания образа Docker, который упаковывает файл с экземпляром Serving Runtime перед его отправкой в реестр. Образ является автономным, и его можно просто запустить с помощью Docker.
Центр обслуживания обеспечивает управление версиями посредством добавления тегов к изображениям моделей; он также обрабатывает развертывание с использованием встроенных возможностей Kubernetes; настраивает всю модельную аппаратуру; и обеспечивает автоматическое масштабирование модели. Всякий раз, когда модель перегружается, создается новый экземпляр — это извлекает образ из реестра, чтобы помочь выдержать новую рабочую нагрузку. Как только рабочая нагрузка уменьшается, дополнительные экземпляры удаляются, а потребляемые ресурсы адаптируются к реальной рабочей нагрузке.
Хотя некоторые модели могут быть специфичными только для бизнеса, другие могут использоваться совместно. В этой степени Serving Hub также управляет списком предварительно созданных моделей для удовлетворения общих сценариев использования.
В настоящее время в OVHCloud доступны две модели: анализ тональности для английского языка и еще одна для французского языка. Оба основаны на знаменитой архитектуре BERT (и ее французского аналога CamemBERT), поддерживаемой Hugging Face, и тонко настроены для анализа настроений с использованием Stanford Sentiment Treebank (1).
Другие модели со временем расширят текущий список предустановленных изображений, поэтому, пожалуйста, свяжитесь с нами, если вы считаете, что конкретная задача будет полезным дополнением (например, некоторые из моделей, доступных на OVHcloud AI MarketPlace ).
ML Serving в настоящее время предоставляет основные функции для любой производственной системы. Кроме того, однако, системы машинного обучения имеют свои особенности и дополнительные функции, которые отслеживают глобальное состояние и производительность любых будущих моделей.
В настоящий момент мы разрабатываем функцию, которая может отслеживать потенциальное смещение концепций в моделях. Раннее обнаружение концепции дрейфа потенциально позволяет превентивно переобучить или усовершенствовать производственную модель, что снижает риск принятия решений, основанных на неверных прогнозах.
Еще одна важная особенность постановки — интерпретируемость. Хотя обычно это требует больших вычислительных затрат, интерпретируемость может иметь решающее значение; либо для целей отладки (например, для понимания того, почему модель так плохо себя ведет на определенных образцах), либо с точки зрения бизнеса. В самом деле, не всегда желательно слепо доверять алгоритму, не осознавая его ограничений или процесса принятия решения.
Обслуживание машинного обучения доступно как продукт OVHcloud в интерфейсе управления публичным облаком. Приходите и развертывайте свои модели или опробуйте наши предустановленные модели и не забудьте поделиться с нами своими отзывами на OVHcloud AI Gitter.
В OVHcloud мы используем несколько моделей машинного обучения, которые помогают принимать решения; начиная от борьбы с мошенничеством и заканчивая улучшением обслуживания нашей инфраструктуры. В недавнем сообщении в блоге мы представили платформу машинного обучения, которая ускоряет создание прототипов. Одна из ключевых особенностей платформы — возможность напрямую предоставлять прототипы через надежный веб-API .
Однако для конкретных случаев использования — или для изучения современных компонентов машинного обучения — практики не могут ограничиться использованием только этой платформы. Таким образом, перед этими проектами стоит одна из основных проблем машинного обучения : переход от стадии прототипа к реальной системе производственного уровня , которая является надежной и доступной для бизнес-приложений. Чтобы восполнить этот пробел , мы разработали ML Serving — инструмент для управления процессом индустриализации.
Используя преимущества стандартных форматов с открытым исходным кодом, таких как Tensorflow SavedModel, ML Serving позволяет пользователям легко развертывать свои модели, используя при этом важные функции, включая инструментарий, масштабируемость и управление версиями моделей . В этой статье мы познакомим вас с основными компонентами и функциями инструмента.
Дизайн обслуживания ML
Служба ML была разработана для удовлетворения следующих требований:
- Легкость использования
- Управление версиями модели
- Стратегии развертывания
- Простота доступа
- Высокая доступность
- Обратимость
- Безопасность
Для достижения этих целей мы основали наш дизайн на микросервисной архитектуре, опирающейся на инфраструктуру Kubernetes. Проект разделен на два основных компонента:
- Среда выполнения обслуживания: обрабатывает фактический вывод модели.
- Центр обслуживания: обеспечивает оркестровку модели и управление
Время выполнения обслуживания
Компонент Serving Runtime является автономным и нацелен на упрощение использования и доступа. Таким образом, его две основные задачи — загрузить модели и раскрыть их.
Простота доступа
Мы обнаружили, что самый простой способ раскрыть модель — использовать HTTP API. Затем он легко интегрируется в любое бизнес-приложение. Среда выполнения обслуживания предоставляет API, ограниченный тем, что важно — конечную точку для описания модели и другую для ее оценки.
Входные данные API по умолчанию отформатированы как тензоры JSON. Ниже приведен пример входной полезной нагрузки для набора данных Титаника при оценке шансов на выживание двух пассажиров:
{
"fare" : [ [ 7 ], [ 9 ] ],
"sex" : [ [ "male" ], [ "female" ] ],
"embarked" : [ [ "Q"], ["S" ] ],
"pclass" : [ [ "3" ], [ "2" ] ],
"age" : [ [ 27 ], [ 38 ] ]
}Тензоры используются для универсальной адресации всех обслуживающих моделей. Однако представление может быть трудным для понимания и в некоторых случаях может быть упрощено. В случае вывода только для одного пассажира JSON выглядит так:
{
"fare" : 7,
"sex" : "male",
"embarked" : "Q",
"pclass" :"3",
"age" : 27
}ML Serving также поддерживает распространенные форматы изображений, такие как JPG и PNG.
Легкость использования
Теперь, когда мы определили API, нам нужно загрузить модели и оценить их. Модели загружаются на основе стандартов сериализации, из которых поддерживаются следующие:
- Tensorflow SavedModel
- HDF5
- ONNX
- PMML
Выделенный модуль, заключенный в общий интерфейс, поддерживает каждый из этих форматов. Если возникнут или потребуются дополнительные форматы, их можно будет легко добавить как новые модули. Полагаясь исключительно на стандартные форматы, система обеспечивает обратимость. Это означает, что специалисты по машинному обучению могут использовать их на различных языках и в библиотеках вне среды выполнения.
Гибкость
Среду выполнения обслуживания можно запускать непосредственно из экспортированных файлов модели или из более гибкой точки входа — манифеста. Манифест — это описание последовательности нескольких моделей или оценщиков. Используя манифест, пользователи могут описать последовательность оценщиков, выходные данные которой могут быть переданы непосредственно последующим оценщикам. Другими словами, специалисты-практики могут объединить их в уникальное развертывание модели.
Обычный вариант использования такой комбинации включает в себя предварительную обработку данных на основе пользовательских оценщиков перед подачей фактической модели или разметку предложений перед оценкой некоторой нейронной сети.
Эта часть все еще является экспериментальной и оказалась сложной с точки зрения простоты использования и обратимости. Тем не менее, это окажется важным в некоторых случаях использования, например, при токенизации предложений перед оценкой модели на основе BERT.
Центр обслуживания
Компонент Serving Hub направлен на удовлетворение всех требований производственного уровня: управление версиями, безопасность, развертывание и высокая доступность.
Его основные задачи — это упаковка Serving Runtime с экспортированными моделями в образ Docker, а затем их развертывание в кластере Kubernetes. В глобальном масштабе компонент во многом полагается на свои функции Kubernetes. Например, для концентратора не требуется база данных, поскольку вся информация о моделях и развертываниях хранится в виде настраиваемых ресурсов Kubernetes.
Центр обслуживания предоставляет два API — API аутентификации, который защищает доступ к модели и управление ею с помощью токенов JWT, и второй, предназначенный для самого управления моделью.
При использовании API управления моделями развертывание модели так же просто, как предоставление имени и пути к файлам модели в серверной части хранилища. Затем Serving Hub запускает рабочий процесс для создания образа Docker, который упаковывает файл с экземпляром Serving Runtime перед его отправкой в реестр. Образ является автономным, и его можно просто запустить с помощью Docker.
Центр обслуживания обеспечивает управление версиями посредством добавления тегов к изображениям моделей; он также обрабатывает развертывание с использованием встроенных возможностей Kubernetes; настраивает всю модельную аппаратуру; и обеспечивает автоматическое масштабирование модели. Всякий раз, когда модель перегружается, создается новый экземпляр — это извлекает образ из реестра, чтобы помочь выдержать новую рабочую нагрузку. Как только рабочая нагрузка уменьшается, дополнительные экземпляры удаляются, а потребляемые ресурсы адаптируются к реальной рабочей нагрузке.
Предустановленные изображения
Хотя некоторые модели могут быть специфичными только для бизнеса, другие могут использоваться совместно. В этой степени Serving Hub также управляет списком предварительно созданных моделей для удовлетворения общих сценариев использования.
В настоящее время в OVHCloud доступны две модели: анализ тональности для английского языка и еще одна для французского языка. Оба основаны на знаменитой архитектуре BERT (и ее французского аналога CamemBERT), поддерживаемой Hugging Face, и тонко настроены для анализа настроений с использованием Stanford Sentiment Treebank (1).
Другие модели со временем расширят текущий список предустановленных изображений, поэтому, пожалуйста, свяжитесь с нами, если вы считаете, что конкретная задача будет полезным дополнением (например, некоторые из моделей, доступных на OVHcloud AI MarketPlace ).
Следующие шаги
ML Serving в настоящее время предоставляет основные функции для любой производственной системы. Кроме того, однако, системы машинного обучения имеют свои особенности и дополнительные функции, которые отслеживают глобальное состояние и производительность любых будущих моделей.
В настоящий момент мы разрабатываем функцию, которая может отслеживать потенциальное смещение концепций в моделях. Раннее обнаружение концепции дрейфа потенциально позволяет превентивно переобучить или усовершенствовать производственную модель, что снижает риск принятия решений, основанных на неверных прогнозах.
Еще одна важная особенность постановки — интерпретируемость. Хотя обычно это требует больших вычислительных затрат, интерпретируемость может иметь решающее значение; либо для целей отладки (например, для понимания того, почему модель так плохо себя ведет на определенных образцах), либо с точки зрения бизнеса. В самом деле, не всегда желательно слепо доверять алгоритму, не осознавая его ограничений или процесса принятия решения.
Обслуживание OVHcloud ML:
Обслуживание машинного обучения доступно как продукт OVHcloud в интерфейсе управления публичным облаком. Приходите и развертывайте свои модели или опробуйте наши предустановленные модели и не забудьте поделиться с нами своими отзывами на OVHcloud AI Gitter.