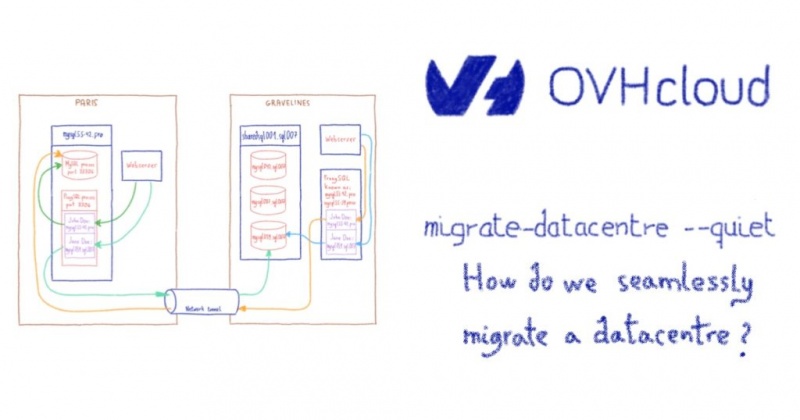
В предыдущих статьях мы видели, каковы операционные и технические ограничения проекта миграции нашего центра обработки данных в Париже.
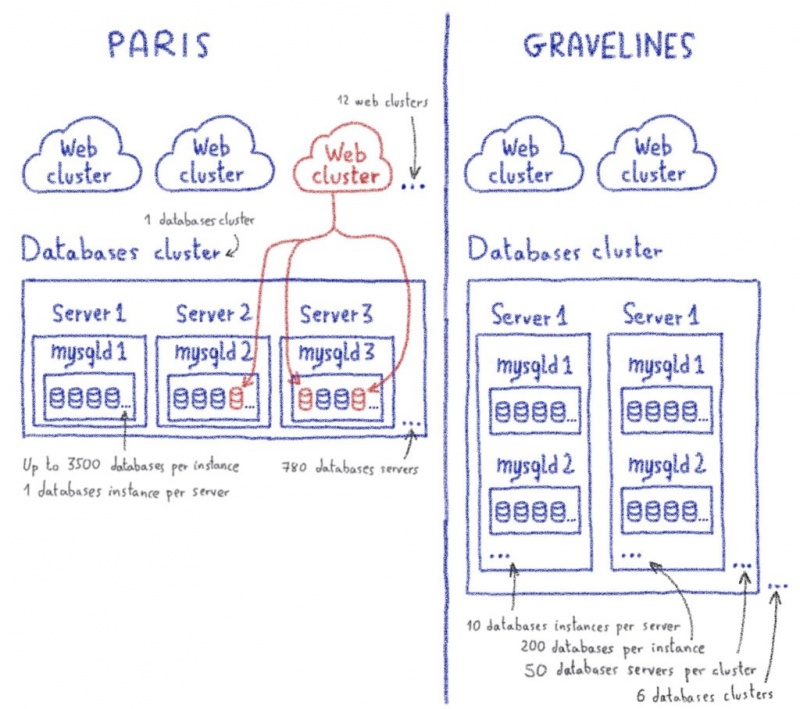
Если вы не выполнили все наши технические ограничения, я предлагаю вам перечитать статью, в которой представлена инфраструктура нашего веб-хостинга. Мы построили наши сценарии миграции, серьезно отнеслись к этим ограничениям.
Чтобы преодолеть этот рискованный проект, мы рассмотрели несколько сценариев, каждый со своим набором операционных трудностей и рисков. Давайте посмотрим, какие проекты миграции мы изучали, а затем мы объясним, как мы выбрали лучший.
Сценарии
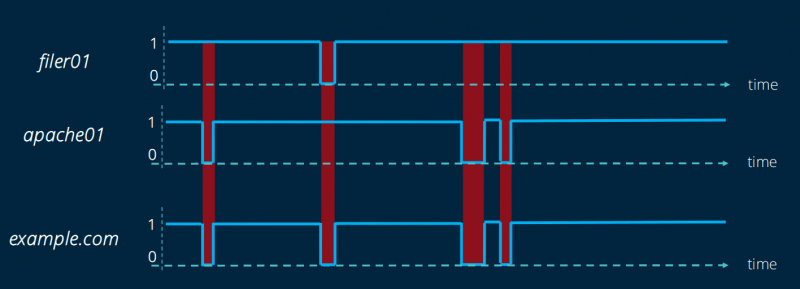
Нашей главной заботой во всех сценариях миграции было избежать проблемы разделения мозга. Эта проблема возникает, когда система одновременно получает данные, записанные как в источнике миграции, так и в месте назначения.
Возьмем пример: мигрируемый сайт электронной коммерции доступен в источнике и месте назначения одновременно. Если клиент этого сайта размещает заказ, и эта информация поступает в инфраструктуру назначения, и что, когда он оплачивает свой заказ, запрос поступает в исходную инфраструктуру, веб-сайт не может установить связь между платежом и заказом. Это то, что мы называем разделенным мозгом.
Чтобы решить эту проблему, необходимо согласовать две базы данных, что возможно только при управлении моделью данных и, следовательно, в целом исходным кодом сайта.
Как веб-хостинг, у нас нет доступа к исходному коду наших клиентов. В нашем масштабе мы даже представить себе не можем, что нам придется решать проблемы, с которыми мы столкнемся. Таким образом, мы не можем рассматривать любой сценарий с расщепленным мозгом.
Самостоятельный перенос сайтов
Наша первая идея заключалась в том, чтобы переносить веб-сайты независимо друг от друга. Это также решение, которое мы рекомендуем клиентам, желающим быстро воспользоваться преимуществами Gravelines, прежде чем приступить к глобальной миграции.
Вот что обычно приходилось делать нашим клиентам:
- Определите все базы данных, используемые в их исходном коде
- Настройте целевую учетную запись
- Поместите сайт на обслуживание в центр обработки данных в Париже, чтобы избежать раздвоения мозгов
- Перенести все данные: файлы исходного кода, а также базы данных
- Настройте новые учетные данные базы данных в исходном коде сайта.
- Убедитесь, что сайт работает как задумано
- Измените свою зону DNS, чтобы перенаправить свой веб-сайт на новый IP-адрес нового кластера Gravelines.
- Повторно откройте сайт и дождитесь окончания задержки распространения DNS.
Мы рассмотрели возможность индустриализации этой техники, чтобы сделать это от имени клиента. Но мы столкнулись с несколькими техническими проблемами:
- Надежная идентификация всех используемых баз данных сложна. Можно искать все имена баз данных в исходном коде наших клиентов, но это очень долгая операция, надежная только в том случае, если исходный код не изменяется в течение этого времени. Это также требует работы со многими особыми случаями: двоичные файлы, выполняемые в CGI, обфускация исходного кода или даже хранение имени баз данных в… базе данных. Этот метод не позволяет нам рассчитывать на 100% надежность нашей миграции.
- Перенос файлов можно выполнить двумя способами:
- В файловом режиме сценарий миграции проходит по дереву файлов и копирует их по одному.
- В блочном режиме сценарий миграции берет данные с жесткого диска и побитно передает их на целевой жесткий диск без учета древовидной структуры.
Оба метода позволяют надежно копировать данные, но предполагаемый вариант использования сильно отличается.
В блочном режиме вы можете скопировать только весь диск или раздел. Если в одном разделе находятся данные с нескольких веб-сайтов, только файловый режим позволяет переносить данные веб-сайта индивидуально.
Перемещение данных в файловом режиме происходит очень медленно, если количество файлов для просмотра важно, как это имеет место во многих фреймворках PHP, выполняющих кэширование. Таким образом, у нас был риск, что мы не сможем перенести некоторые сайты.
- Изменение исходного кода — опасная операция, которую мы не позволяем делать, потому что это может сильно повлиять на веб-сайт. Кроме того, это требует исчерпывающего определения всех видов использования баз данных…
- Некоторые наши клиенты не размещают свою зону DNS дома. После этого мы не сможем изменить IP-адрес их веб-сайта без их вмешательства, что требует от нас сохранения этого IP-адреса, если мы хотим достичь хорошего уровня надежности для миграции.
Поэтому мы отклонили этот сценарий. Несмотря на то, что они функционируют для подавляющего большинства веб-сайтов, небольшой процент затронутых сайтов на самом деле представляет собой большое количество веб-сайтов. Надо было их ремонтировать вручную, и наша команда все время проводила бы там.
IP через грузовые автомобили
Интернет основан на IP-протоколе для адресации машин в сети. Это не зависит от физического материала, на котором происходит обмен сообщениями, можно использовать многие: оптические каналы, электрические, беспроводные; даже странствующих голубей, как это описано в юмористическом стандарте, установленном 1 апреля 1990 года!
Эта первоапрельская шутка нас вдохновила, хотя мы не знатоки голубей. В самом деле, даже если задержка (продолжительность путешествия для сообщения из точки A в точку B) важна, пропускная способность (количество отправленной информации / время в пути) потенциально огромна: USB-ключ содержит много данных! При некоторых больших передачах физическое перемещение данных — разумный способ увеличить пропускную способность передачи.
Поэтому мы подумали о варианте просто перенести инфраструктуру из Парижа в Gravelines. У этого есть преимущества:
- Не влияет на веб-сайты. Нам просто нужно снова включить инфраструктуру в другом центре обработки данных и перенаправить туда трафик;
- Это позволяет очень быстро опустошить дата-центр.
Но это также создает некоторые проблемы:
- Как сократить время нарезки сайтов между остановкой машин в Париже, их загрузкой, транспортировкой, разгрузкой и повторным зажиганием? Время отключения будет порядка нескольких дней.
- Что делать в случае аварии в дороге? Падение сервера, ДТП…
- Как убедиться, что данные не изменятся во время транспортировки из-за вибрации грузовика?
- Как интегрировать эту инфраструктуру, не соблюдая стандарты индустриализации, действующие в Gravelines?
Ни один из этих пунктов не был блокирующим, но они ставили интересные задачи. Поэтому мы сохранили этот сценарий, хотя и не в качестве нашего первого выбора из-за физических рисков и длительного периода недоступности веб-сайтов во время работы.
Масштабируемые миграции
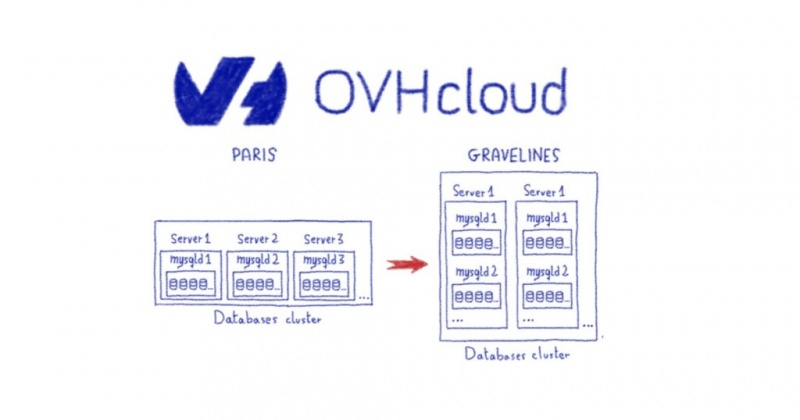
Не имея возможности перенести весь центр обработки данных сразу или веб-сайты по отдельности, мы изучаем, как переносить активы нашей инфраструктуры по мере продвижения.
Поэтому мы сделали шаг назад и посмотрели на уровни детализации нашей инфраструктуры, то есть на элементы, которые связывают веб-сайты друг с другом и предотвращают переход от сайта к сайту:
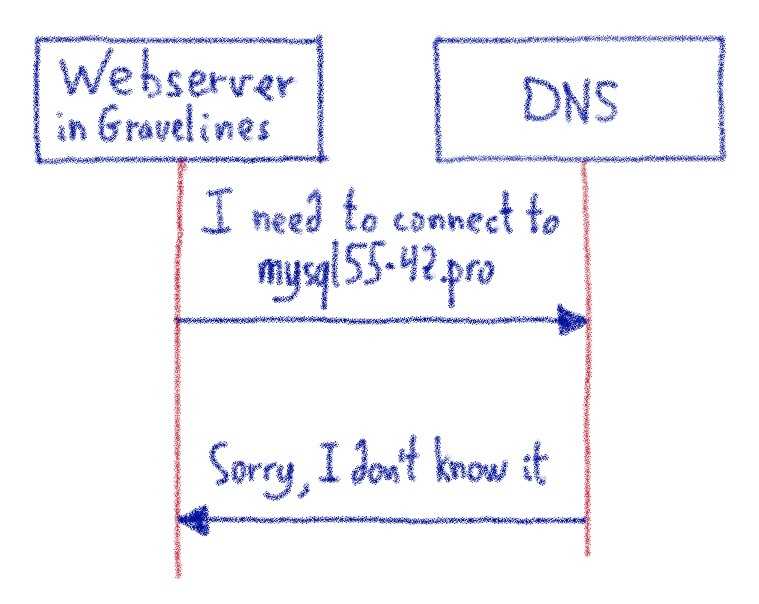
- IP-адреса: мы не контролировали все зоны DNS, мы считали, что IP-адреса сайтов наших клиентов не могут быть изменены. Это означает, что мы должны перенести сразу все веб-сайты, использующие один и тот же IP-адрес.
- Filerz : миграция в файл данных режима на filerz не является возможным из - за большое количество файлов, мы должны выполнить миграцию в блочной режиме и тем самым перенести все клиент в том же filerz одновременно.
- Базы данных: все базы данных на одном веб-сайте должны быть перенесены одновременно, чтобы сайт продолжал работать, а идентификаторы баз данных не должны изменяться. Эти базы данных потенциально могут использоваться двумя разными местоположениями, включая разные кластеры; эти приспособления должны быть перенесены одновременно.
Если мы рассмотрим все эти предположения, необходимо сделать один вывод: чтобы их уважать, мы должны перенести все сайты сразу из-за взаимозависимостей.
Мы были в блокирующей позиции. Чтобы двигаться вперед, необходимо было пересмотреть каждый постулат и рассмотреть решения для преодоления этих проблем.
Устранение зависимостей от баз данных
Одно из самых сложных ограничений — это надежная миграция баз данных вместе с веб-сайтами.
Можем ли мы представить себе 95% надежную миграцию с учетом только баз данных, предоставленных с хостингом (то есть, не считая нетипичных случаев, которые обнаруживаются только путем анализа исходного кода веб-сайтов)?
На бумаге это не сработает, так как это повлияет на нетипичные веб-сайты, поскольку базы данных больше не будут доступны.
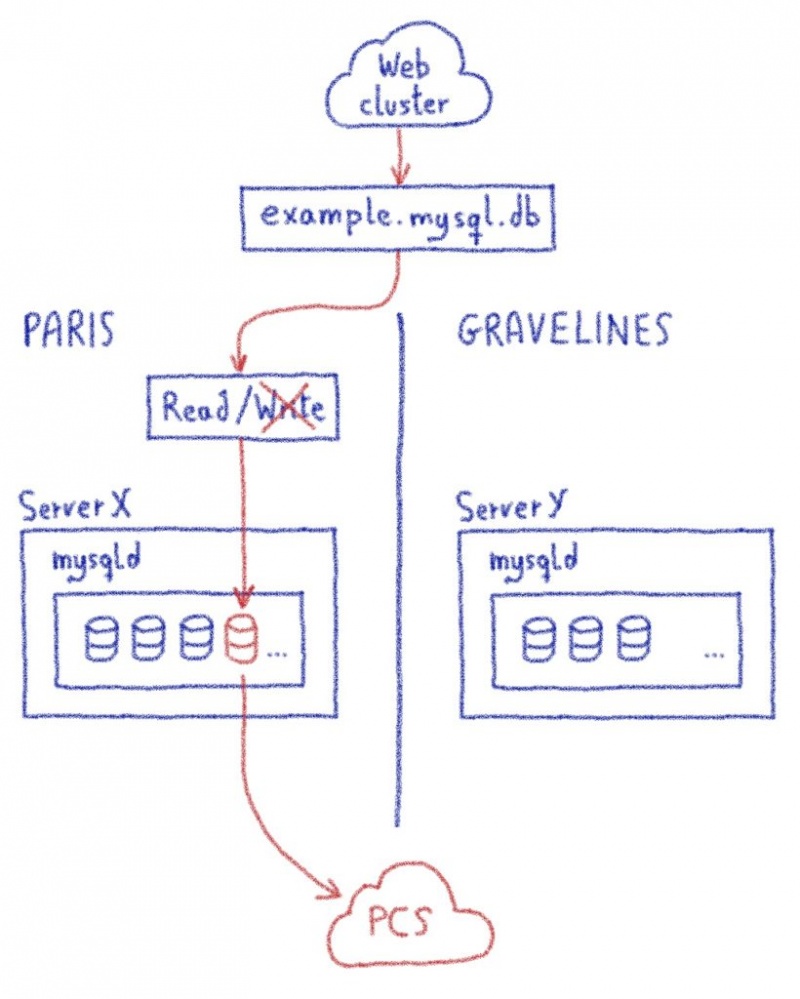
Таким образом, нам нужно было поиграть с доступностью базы данных: если нам удастся сохранить доступную базу данных, даже если она не будет перенесена, мы можем удалить это ограничение, и нетипичные случаи продолжат работать.
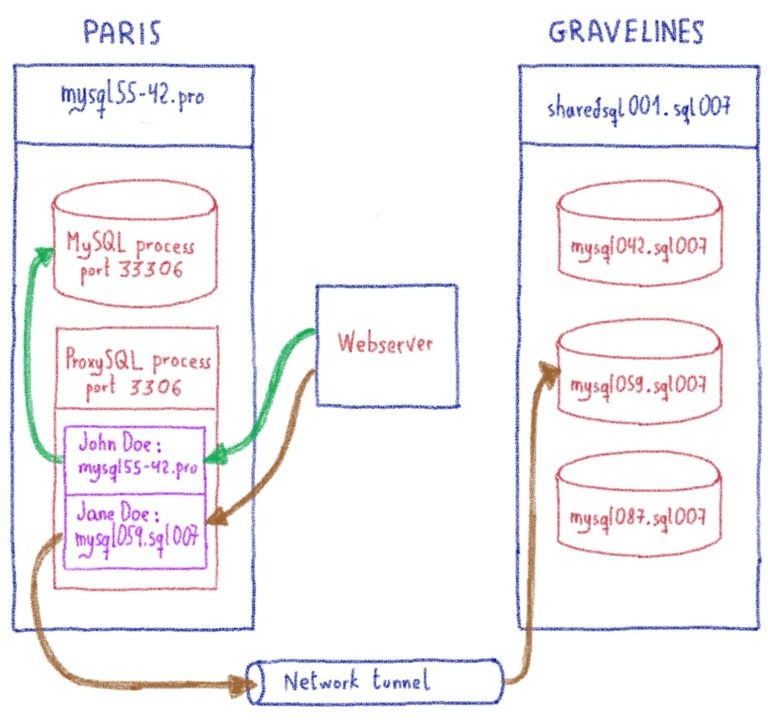
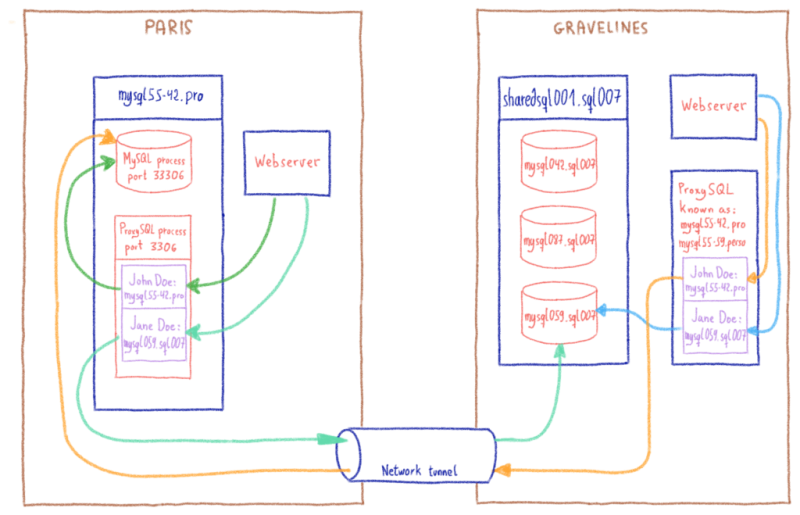
Это технически возможно, если мы откроем сетевой туннель между нашим центром обработки данных в Gravelines и этим центром в Париже. С помощью этого туннеля веб-сайт, использующий базу данных, на которую нет ссылок на его хостинге, продолжит работу, получая данные в Париже.
Это не идеальное решение: добавление сетевого туннеля означает добавление задержки 10 мс. И на некоторых CMS, выполняющих десятки SQL-запросов последовательно, эта задержка быстро заметна. Но, ограничив этот эффект только базами данных без ссылок, мы могли бы упростить это сильное ограничение. Все сайты продолжат работу. Некоторые сайты могут работать медленно, но для наших обычных случаев веб-хостинга последствия минимальны.
Обход зависимости IP-адреса
За одним IP-адресом скрывается несколько сотен тысяч веб-сайтов. Поэтому миграция всех файлов и баз данных потребует очень важного времени завершения работы.
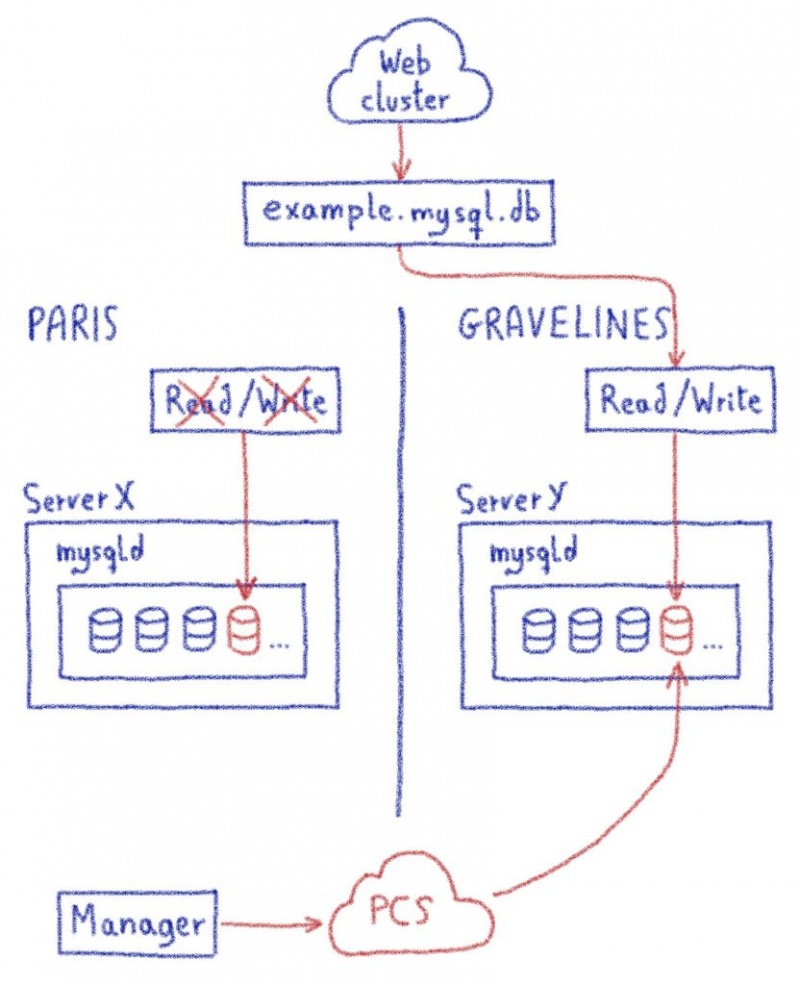
Однако вопрос можно задать по-другому: IP-адрес обслуживает несколько сайтов, как мы можем распределить входящий трафик с этого IP-адреса в правильный центр обработки данных, на котором размещен нужный веб-сайт? Это проблема балансировки нагрузки, и у нас уже есть балансировщик нагрузки, который адаптируется в соответствии с запрошенным веб-сайтом: предсказатель.
В предикторе можно определить, где веб-сайт действительно должен перенаправлять трафик. Самым простым решением было бы добавление нового предиктора перед нашей инфраструктурой, но объединение балансировок нагрузки в цепочку — не лучшая идея: это делает путь к веб-сайту более сложным и добавляет новый критический элемент в инфраструктуру.
И наконец, ничто не мешает нам использовать балансировку нагрузки Paris или Gravelines для выполнения этого перенаправления трафика.
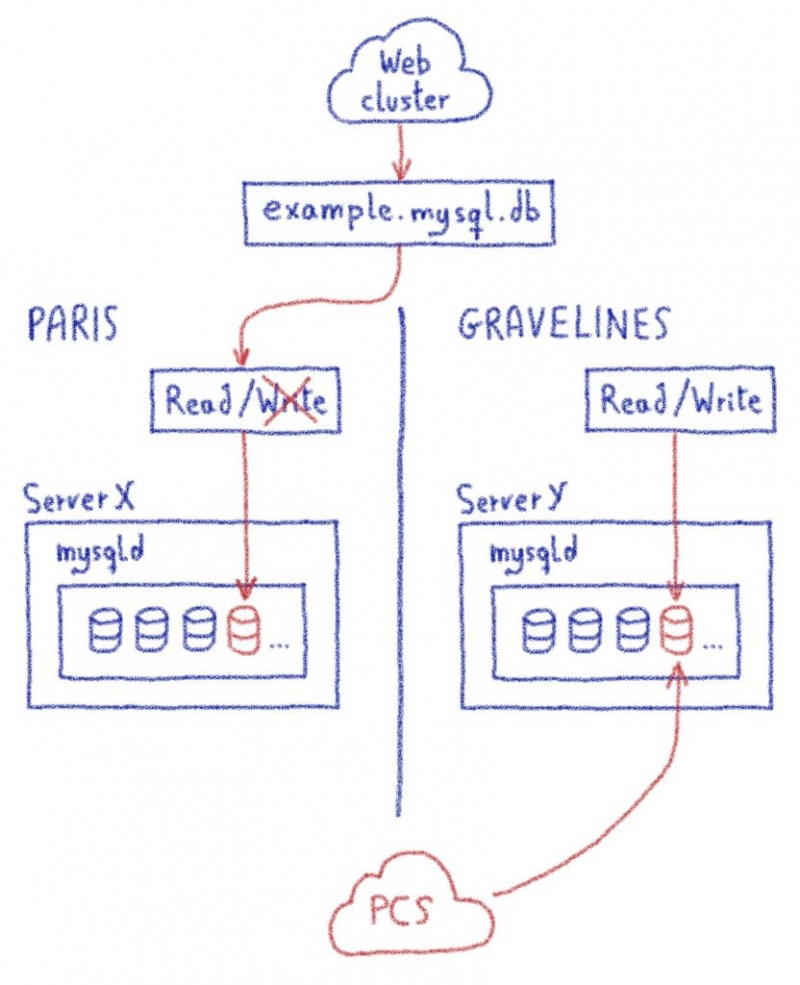
Мы выбрали предиктор наших новых кластеров Gravelines. Мы добавили список веб-сайтов и их статус: перенесены или нет. Таким образом, для перенесенных сайтов трафик распределяется локально. В противном случае трафик перенаправляется на балансировщик нагрузки кластера в Париже.
Мы знали, как переносить IP-адрес между нашими центрами обработки данных. Таким образом, можно подготовить эти новые предикторы, а затем прозрачным образом перенести IP-адреса всего кластера, не вызывая прерывания работы клиента.
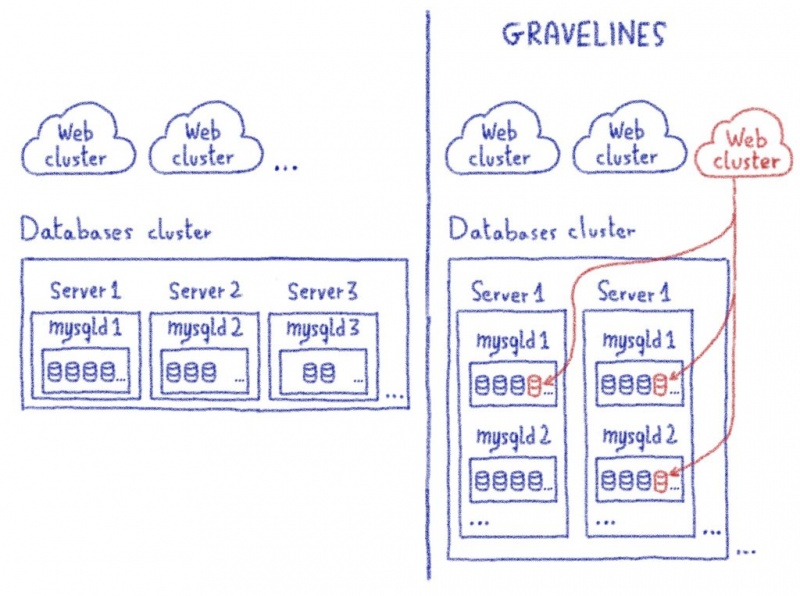
IP-адреса больше не были точкой блокировки. Снижая это ограничение, мы теперь можем переносить клиентов filerz by filerz. Можем ли мы сделать еще лучше?
Перенести filerz как блок
Чтобы добиться большего, нам потребуется декоррелировать клиентов каждого filerz. Как мы могли это сделать?
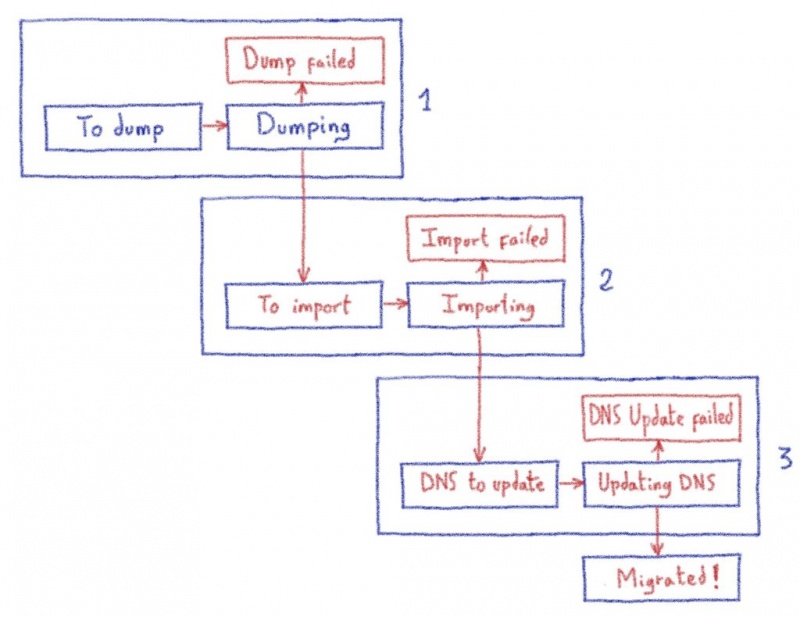
Перенос всего filerz требует времени. Нам нужно переместить несколько ТБ данных по нашей сети, это может занять десятки часов. Чтобы избежать расщепления мозгов, нам нужно избегать записи в источнике во время копирования.
Но наша команда хранилищ знает, как справиться с таким типичным для них делом. Они начинают с создания первой копии всех данных, не закрывая исходную службу. Как только эта первая копия сделана, последним копиям нужно только синхронизировать различия, записанные с момента создания первой. После нескольких последовательных копий время копирования очень короткое.
В этот момент можно отключить службу на несколько часов ночью, чтобы выполнить миграцию ( filerz и связанные базы данных), не рискуя разделить мозг.
Теперь у нас есть все элементы для реализации нового сценария миграции!
Давай, сделаем это еще раз.
Наш финальный сценарий
После прочтения предыдущих разделов вы, вероятно, уже имеете хорошее представление о том, как мы переносим кластеры. Вот основные шаги:
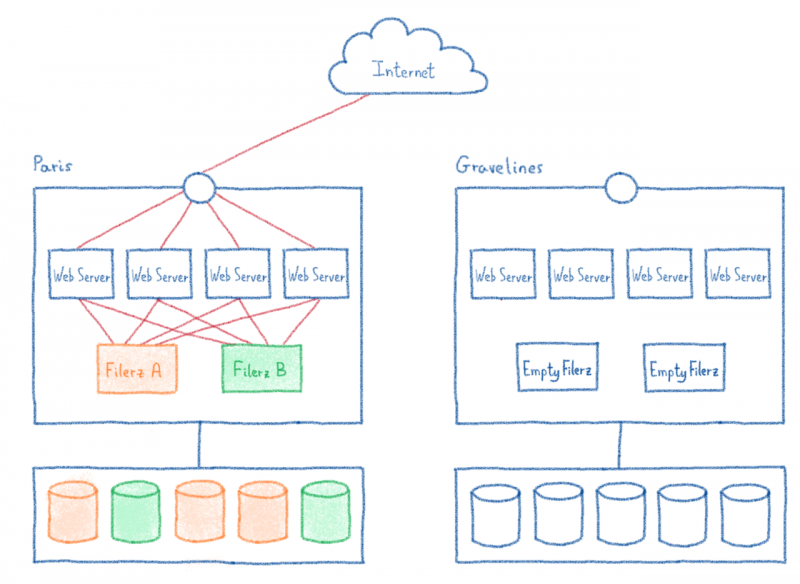
1 / Строительство нового кластера в Gravelines, соответствующего стандартам этого нового центра обработки данных, но включающего столько же файлов и баз данных, сколько и предыдущий.
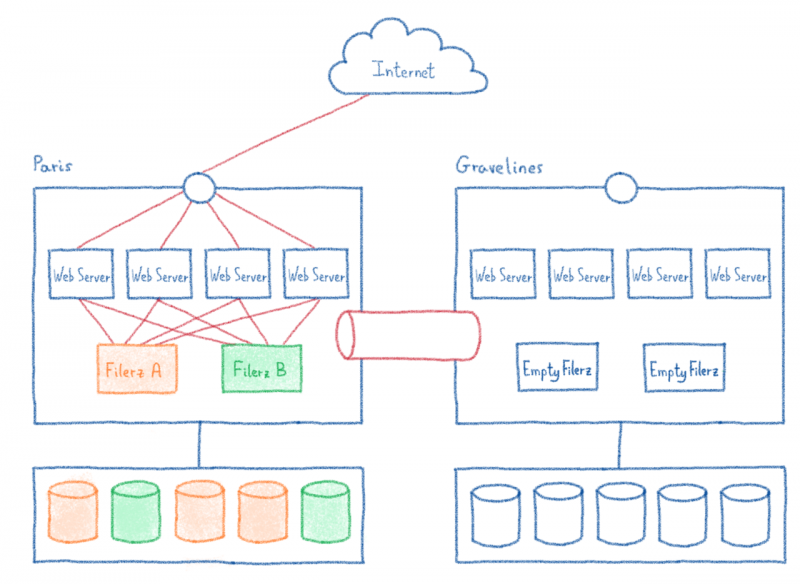
 2 / Построение сетевого соединения между новым и старым центром обработки данных.
2 / Построение сетевого соединения между новым и старым центром обработки данных.
 3 / Миграция IP-трафика на новый кластер с перенаправлением в Париж для немигрированных сайтов.
3 / Миграция IP-трафика на новый кластер с перенаправлением в Париж для немигрированных сайтов.
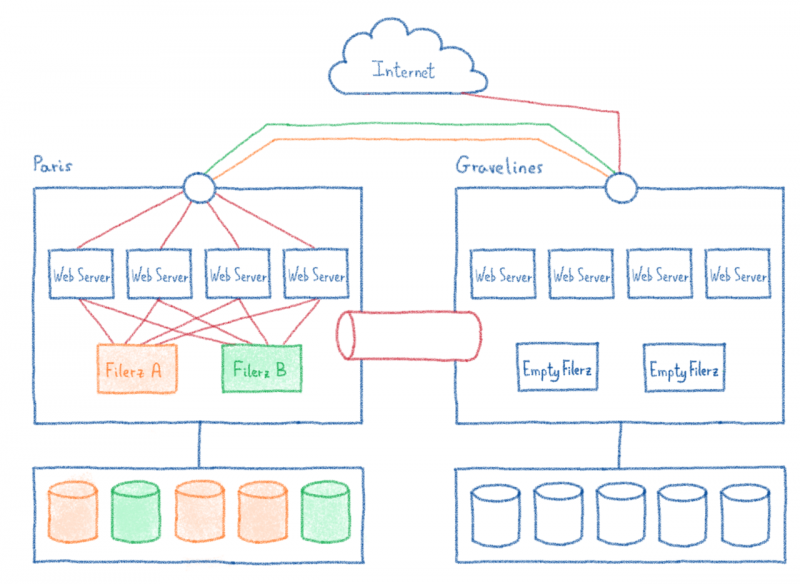 4 / Копирование данных без взлома сайтов.
4 / Копирование данных без взлома сайтов.
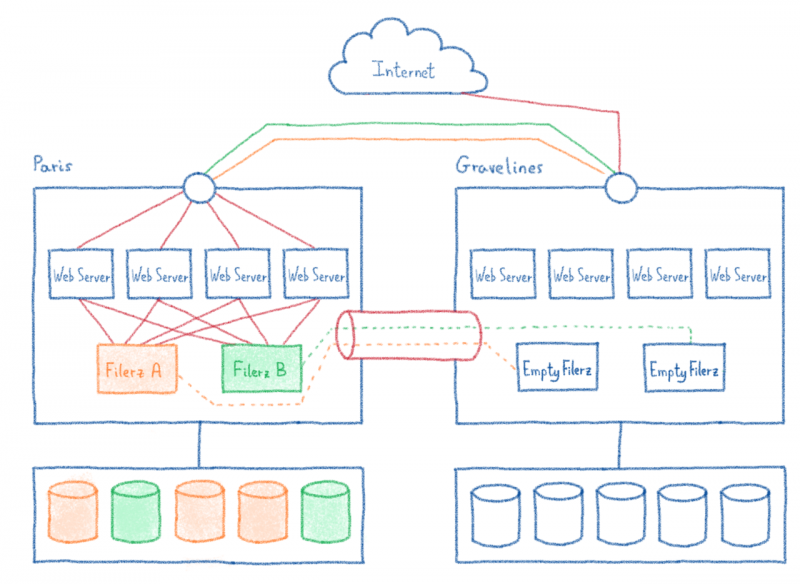 5 / Ночью: отключение сайтов первого filerz, перенос его данных и связанных баз данных.
5 / Ночью: отключение сайтов первого filerz, перенос его данных и связанных баз данных.
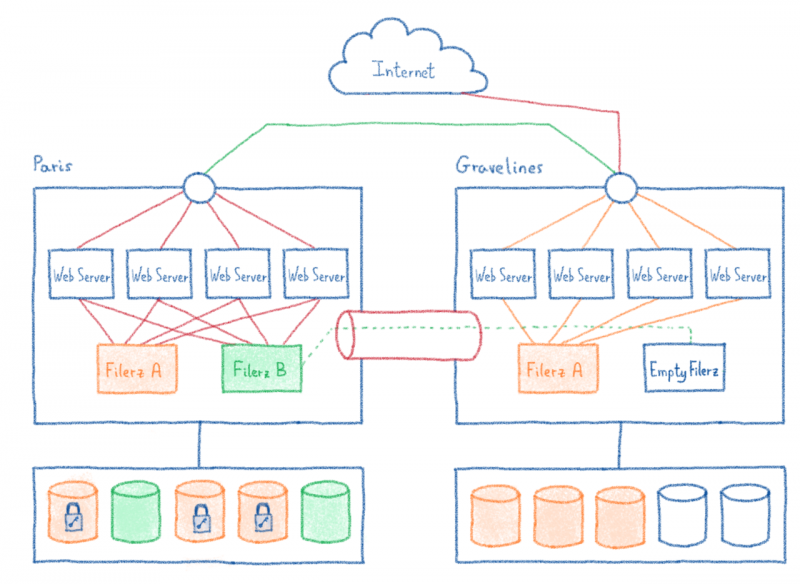 6 / Ночью: отключение сайтов, миграция второго filerz и связанных баз данных.
6 / Ночью: отключение сайтов, миграция второго filerz и связанных баз данных.
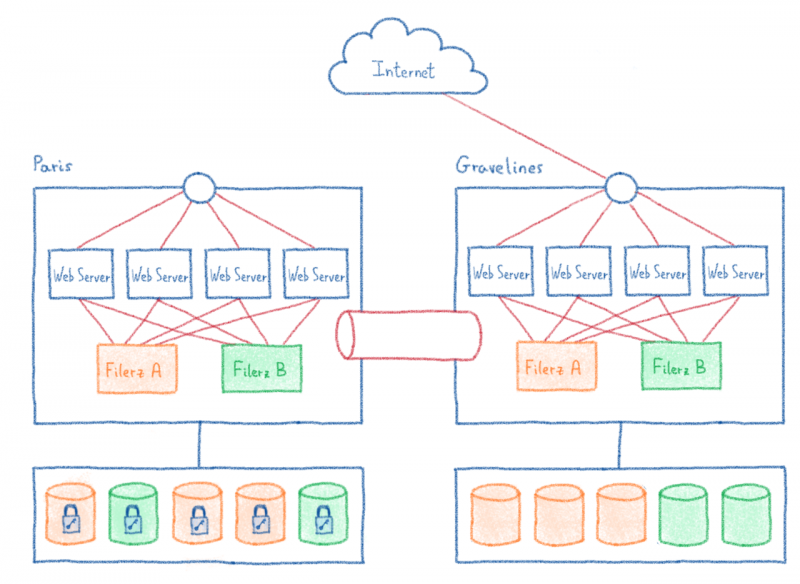 7 / Закрытие исходного кластера.
7 / Закрытие исходного кластера.
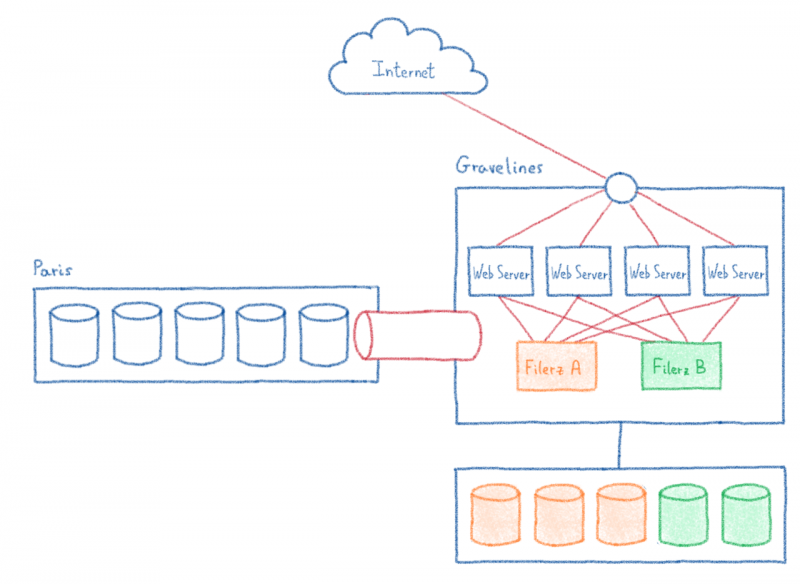
Даже после миграции всех файлов кластера сетевое соединение с центром обработки данных в Париже необходимо поддерживать до тех пор, пока не будут перенесены все базы данных, в самом конце миграции. Таким образом, эта связь должна быть долговечной и отслеживаться в течение нескольких месяцев.
Этот сценарий был проверен в июле 2018 года. Чтобы он заработал, нам потребовалось 5 месяцев адаптации наших систем, а также несколько холостых повторений на тестовом кластере, специально развернутом для проверки того, что все работает должным образом. На бумаге сценарий выглядел красиво, но нам приходилось решать множество проблем на каждом этапе процесса (мы более подробно рассмотрим технические детали в будущих сообщениях в блоге).
Каждый шаг в этом сценарии предполагал десятки синхронизированных операций между разными командами. Мы должны были организовать очень точное отслеживание наших операций, чтобы все прошло без сучка и задоринки (мы также поговорим об этом в другом посте).
Теперь вы знаете наш процесс миграции. Эта статья, хотя и длинная, необходима для понимания архитектурных решений и сюрпризов, с которыми мы столкнулись во время миграции.
В будущих публикациях мы сосредоточимся на конкретных моментах нашей миграции и технических проблемах, с которыми мы столкнулись.
До скорой встречи для дальнейших приключений!