Семейство Open Source Metrics приветствует Catalyst и Erlenmeyer
В OVHcloud Metrics мы любим открытый исходный код! Наша цель — предоставить всем нашим пользователям полноценный опыт . Мы полагаемся на базу данных временных рядов Warp10, которая позволяет нам создавать инструменты с открытым исходным кодом для наших пользователей. Давайте взглянем на некоторые из них в этом блоге.
Наша инфраструктура основана на базе данных временных рядов с открытым исходным кодом: Warp10 . Эта база данных включает две версии: автономную и распределенную . Распределенный полагается на распределенные инструменты, такие как Apache Kafka, Apache Hadoop и Apache HBase .
Неудивительно, что наша команда вносит свой вклад в платформу Warp10 . Из-за наших уникальных требований мы даже вносим свой вклад в базовую базу данных с открытым исходным кодом HBase !
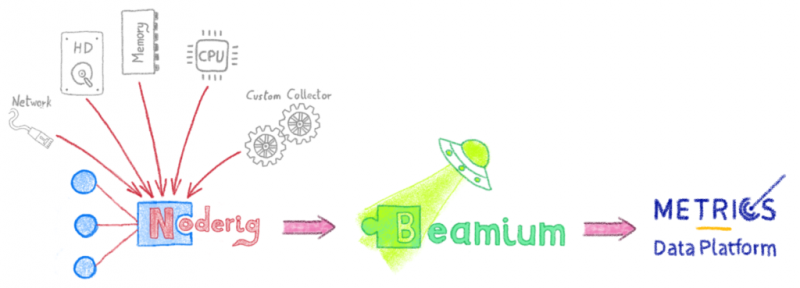
Собственно говоря, мы были первыми, кто застрял в процессе приема ! Мы часто создаем адаптированные инструменты для сбора и отправки данных мониторинга на Warp10 — так появился noderig . Noderig является адаптированным инструментом , который способен собрать в простое ядро метрик с любого сервера или любой виртуальной машины . Также можно безопасно отправлять метрики на бэкэнд. Beamium , инструмент Rust, может передавать метрики Noderig одному или нескольким бэкэндам Warp 10 .
Что, если я хочу собирать собственные специальные показатели ? Во-первых, вам нужно будет разоблачить их по «модели Прометея». Beamium затем может подручных приложений на основе их файл конфигурации и вперед все данные в сконфигурированной Деформация 10 бэкэндом (ов)!
Если вы хотите отслеживать определенные приложения с помощью агента Influx Telegraf (чтобы предоставить необходимые вам метрики), мы также предоставили соединитель Warp10 Telegraf , который был недавно объединен!
Пока это выглядит великолепно, но что, если я обычно нажимаю метрики Graphite, Prometheus, Influx или OpenTSDB ; как я могу просто перейти на Warp10 ? Наш ответ - Catalyst : прокси-уровень, который может анализировать метрики в связанных форматах и преобразовывать их в родной для Warp10.
Catalyst — это HTTP-прокси Go, используемый для анализа нескольких записей в базе данных TimeSeries с открытым исходным кодом. На данный момент он поддерживает несколько операций записи в базу данных TimeSeries с открытым исходным кодом; такие как OpenTSDB, PromQL, Prometheus-remote_write, Influx и Graphite. Catalyst запускает HTTP-сервер, который прослушивает определенный путь ; начиная с имени временного ряда протокола, а затем с собственного запроса . Например, чтобы собрать данные о притоке, вы просто отправляете запрос на адрес

Сбор данных — важный первый шаг, но мы также рассмотрели, как существующие протоколы мониторинга запросов могут быть использованы поверх Warp10. Это привело нас к внедрению TSL. TSL подробно обсуждался во время встречи по временным рядам в Париже, а также в этом сообщении в блоге.
Теперь давайте возьмем пользователя, который использует Telegraf и отправляет данные в Warp10 с помощью Catalyst. Они захотят использовать встроенную панель управления Influx Grafana, но как? А как насчет пользователей, которые автоматизируют запросы с помощью протокола запросов OpenTSDB? Нашим ответом было разработать прокси: Эрленмейер
Erlenmeyer — это HTTP-прокси Go, который позволяет пользователям запрашивать Warp 10 на основепротокола запросовс открытым исходным кодом . На данный момент он поддерживает несколько форматов TimeSeries с открытым исходным кодом; такие как PromQL, удаленное чтение Prometheus, InfluxQL, OpenTSDB или Graphite. Эрленмейер запускает HTTP-сервер, который прослушивает определенный путь ; начиная с имени временного ряда протокола, а затем с собственного запроса . Например, чтобы выполнить запрос promQL, пользователь отправляет запрос в

Сначала Erlenmeyer и Catalyst представили быструю реализацию собственных протоколов, призванную помочь внутренним группам выполнять миграцию, при этом используя знакомый инструмент . Теперь мы интегрировали множество встроенных функций каждого протокола и чувствуем, что они готовы к совместному использованию. Это время , чтобы сделать их доступными для Warp10 сообщества , поэтому мы можем получить обратную связь и продолжать работать в поддержке протоколов с открытым исходным кодом. Вы можете найти нас в игровой комнате OVHcloud Metrics !
Другим пользователям Warp10 может потребоваться нереализованный протокол. Они смогут использовать Erlenmeyer и Catalyst для поддержки их на собственном сервере Warp10.
Добро пожаловать, Erlenmeyer и Catalyst — Metrics Open Source проекты!
Инструмент для хранения
Наша инфраструктура основана на базе данных временных рядов с открытым исходным кодом: Warp10 . Эта база данных включает две версии: автономную и распределенную . Распределенный полагается на распределенные инструменты, такие как Apache Kafka, Apache Hadoop и Apache HBase .
Неудивительно, что наша команда вносит свой вклад в платформу Warp10 . Из-за наших уникальных требований мы даже вносим свой вклад в базовую базу данных с открытым исходным кодом HBase !
Прием данных метрик
Собственно говоря, мы были первыми, кто застрял в процессе приема ! Мы часто создаем адаптированные инструменты для сбора и отправки данных мониторинга на Warp10 — так появился noderig . Noderig является адаптированным инструментом , который способен собрать в простое ядро метрик с любого сервера или любой виртуальной машины . Также можно безопасно отправлять метрики на бэкэнд. Beamium , инструмент Rust, может передавать метрики Noderig одному или нескольким бэкэндам Warp 10 .
Что, если я хочу собирать собственные специальные показатели ? Во-первых, вам нужно будет разоблачить их по «модели Прометея». Beamium затем может подручных приложений на основе их файл конфигурации и вперед все данные в сконфигурированной Деформация 10 бэкэндом (ов)!
Если вы хотите отслеживать определенные приложения с помощью агента Influx Telegraf (чтобы предоставить необходимые вам метрики), мы также предоставили соединитель Warp10 Telegraf , который был недавно объединен!
Пока это выглядит великолепно, но что, если я обычно нажимаю метрики Graphite, Prometheus, Influx или OpenTSDB ; как я могу просто перейти на Warp10 ? Наш ответ - Catalyst : прокси-уровень, который может анализировать метрики в связанных форматах и преобразовывать их в родной для Warp10.
Катализатор
Catalyst — это HTTP-прокси Go, используемый для анализа нескольких записей в базе данных TimeSeries с открытым исходным кодом. На данный момент он поддерживает несколько операций записи в базу данных TimeSeries с открытым исходным кодом; такие как OpenTSDB, PromQL, Prometheus-remote_write, Influx и Graphite. Catalyst запускает HTTP-сервер, который прослушивает определенный путь ; начиная с имени временного ряда протокола, а затем с собственного запроса . Например, чтобы собрать данные о притоке, вы просто отправляете запрос на адрес
influxdb/writeinfluxЗапросы метрик
Сбор данных — важный первый шаг, но мы также рассмотрели, как существующие протоколы мониторинга запросов могут быть использованы поверх Warp10. Это привело нас к внедрению TSL. TSL подробно обсуждался во время встречи по временным рядам в Париже, а также в этом сообщении в блоге.
Теперь давайте возьмем пользователя, который использует Telegraf и отправляет данные в Warp10 с помощью Catalyst. Они захотят использовать встроенную панель управления Influx Grafana, но как? А как насчет пользователей, которые автоматизируют запросы с помощью протокола запросов OpenTSDB? Нашим ответом было разработать прокси: Эрленмейер
Эрленмейер
Erlenmeyer — это HTTP-прокси Go, который позволяет пользователям запрашивать Warp 10 на основепротокола запросовс открытым исходным кодом . На данный момент он поддерживает несколько форматов TimeSeries с открытым исходным кодом; такие как PromQL, удаленное чтение Prometheus, InfluxQL, OpenTSDB или Graphite. Эрленмейер запускает HTTP-сервер, который прослушивает определенный путь ; начиная с имени временного ряда протокола, а затем с собственного запроса . Например, чтобы выполнить запрос promQL, пользователь отправляет запрос в
prometheus/api/v0/querypromQLПродолжение следует
Сначала Erlenmeyer и Catalyst представили быструю реализацию собственных протоколов, призванную помочь внутренним группам выполнять миграцию, при этом используя знакомый инструмент . Теперь мы интегрировали множество встроенных функций каждого протокола и чувствуем, что они готовы к совместному использованию. Это время , чтобы сделать их доступными для Warp10 сообщества , поэтому мы можем получить обратную связь и продолжать работать в поддержке протоколов с открытым исходным кодом. Вы можете найти нас в игровой комнате OVHcloud Metrics !
Другим пользователям Warp10 может потребоваться нереализованный протокол. Они смогут использовать Erlenmeyer и Catalyst для поддержки их на собственном сервере Warp10.
Добро пожаловать, Erlenmeyer и Catalyst — Metrics Open Source проекты!