Работа с небольшими файлами с помощью OpenStack Swift (часть 1)
OpenStack Swift — это распределенная система хранения, которую легко масштабировать по горизонтали с использованием стандартных серверов и дисков.
Мы используем его в OVHcloud для внутренних нужд и в качестве услуги для наших клиентов.

По дизайну он довольно прост в использовании, но вам все равно нужно думать о своей рабочей нагрузке при проектировании кластера Swift. В этом посте я объясню, как данные хранятся в кластере Swift и почему маленькие объекты вызывают беспокойство.
Узлы, отвечающие за хранение данных в кластере Swift, являются «объектными серверами». Чтобы выбрать серверы объектов, которые будут содержать определенный объект, Swift полагается на согласованное хеширование:
На практике, когда объект загружен, контрольная сумма MD5 будет вычисляться на основе имени объекта. Из этой контрольной суммы будет извлечено некоторое количество битов, что даст нам номер «раздела».
Номер раздела позволяет вам посмотреть на «кольцо», чтобы увидеть, на каком сервере и диске должен храниться этот конкретный объект. «Кольцо» — это соответствие между номером раздела и серверами объектов, которые должны хранить объекты, принадлежащие этому разделу.
Давайте посмотрим на пример. В этом случае мы будем использовать только 2 бита из контрольной суммы md5 (слишком мало, но рисовать гораздо проще! Всего 4 раздела)
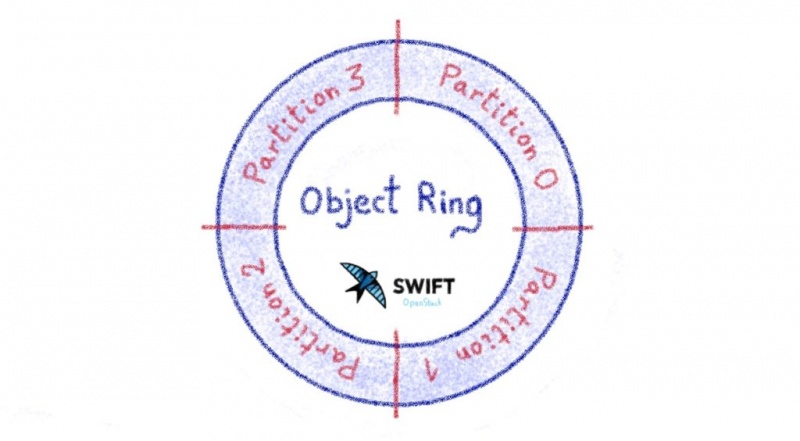
При загрузке файла, от его имени и других элементов, мы получаем контрольную сумму md5, 72acded3acd45e4c8b6ed680854b8ab1. Если мы возьмем 2 старших бита, мы получим раздел 1.
Из кольца объектов мы получаем список серверов, на которых должны храниться копии объекта.
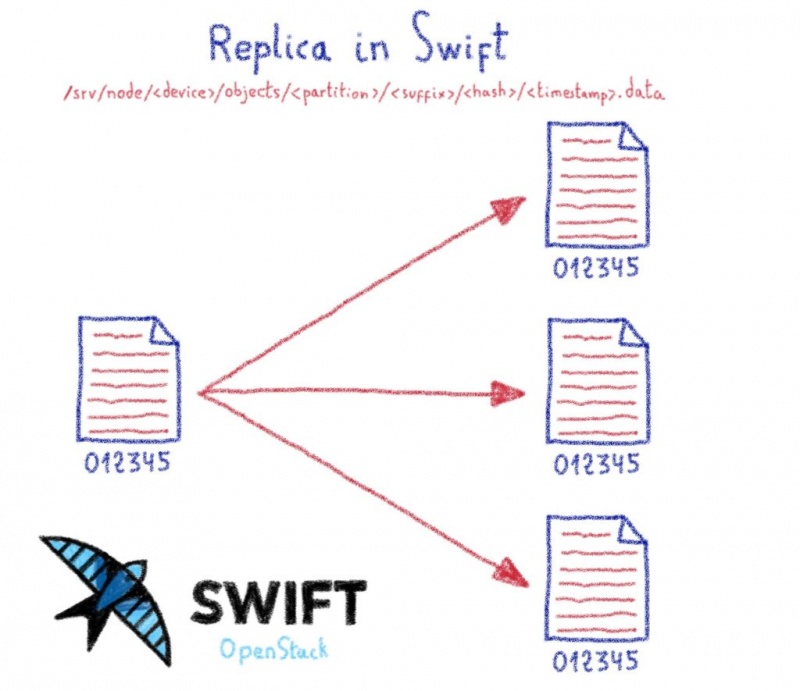
При рекомендованной настройке Swift вы сохраните три идентичные копии объекта. Для одной загрузки мы создаем три реальных файла на трех разных серверах.
Мы только что видели, как наиболее распространенная политика Swift — хранить идентичные копии объекта.
Это может быть немного дорого для некоторых случаев использования, и Swift также поддерживает политики «стирания кодирования».
Давайте сравним их сейчас.
«Политика реплик», которую мы только что описали. Вы можете выбрать, сколько копий объектов вы хотите сохранить.
Тип политики «кодирование стирания»
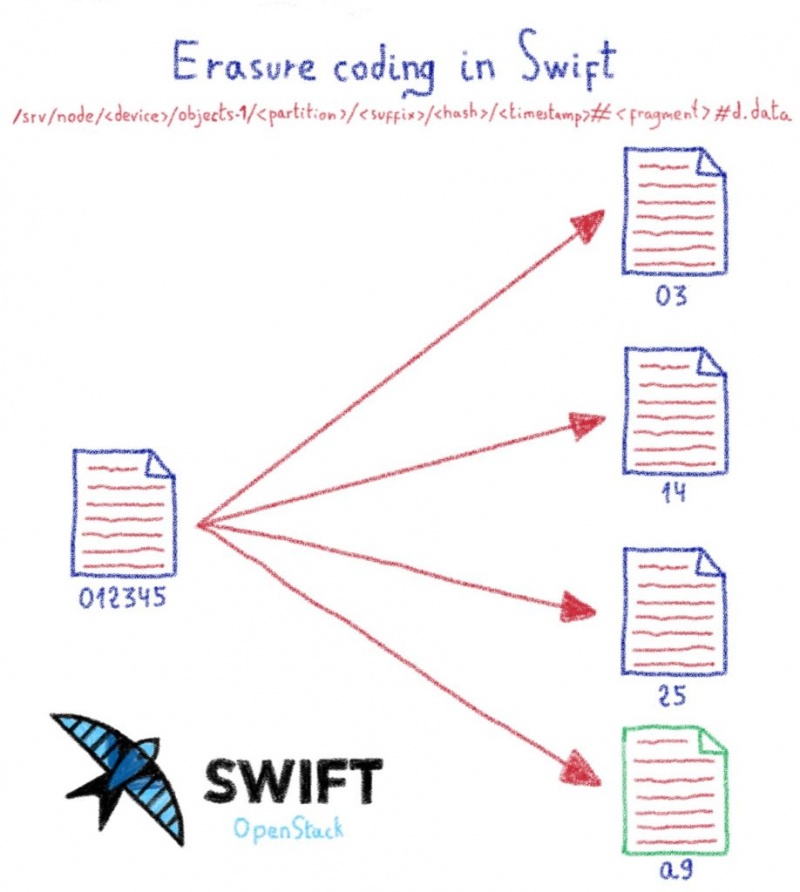
Объект разбивается на фрагменты с добавлением лишних частей, чтобы можно было реконструировать объект, если диск, содержащий фрагмент, выйдет из строя.
В OVHcloud мы используем политику 12 + 3 (12 частей от объекта и 3 вычисляемых части)
Этот режим более экономичен, чем репликация, но он также создает больше файлов в инфраструктуре. В нашей конфигурации мы должны создать 15 файлов в инфраструктуре, а не 3 файла со стандартной политикой «репликации».
В кластерах, где у нас есть комбинация политики кодирования стирания и среднего размера объекта 32 КБ, мы получим более 70 миллионов файлов * на диск *.
На сервере с 36 дисками это 2,5 миллиарда файлов.
Кластеру Swift необходимо регулярно перечислять эти файлы, чтобы:
Обычно список файлов на жестком диске выполняется довольно быстро, благодаря кешу каталогов Linux. Однако на некоторых кластерах мы заметили, что время для вывода списка файлов увеличивалось, и большая часть емкости ввода-вывода жесткого диска использовалась для чтения содержимого каталога: было слишком много файлов, и система не могла кэшировать содержимое каталога. Потеря большого количества операций ввода-вывода для этого означала, что время отклика кластера становилось все медленнее, а задачи восстановления (восстановление фрагментов, потерянных из-за сбоев диска) отставали.
В следующем посте мы увидим, как мы это решили.
Мы используем его в OVHcloud для внутренних нужд и в качестве услуги для наших клиентов.
По дизайну он довольно прост в использовании, но вам все равно нужно думать о своей рабочей нагрузке при проектировании кластера Swift. В этом посте я объясню, как данные хранятся в кластере Swift и почему маленькие объекты вызывают беспокойство.
Как Swift хранит файлы?
Узлы, отвечающие за хранение данных в кластере Swift, являются «объектными серверами». Чтобы выбрать серверы объектов, которые будут содержать определенный объект, Swift полагается на согласованное хеширование:
На практике, когда объект загружен, контрольная сумма MD5 будет вычисляться на основе имени объекта. Из этой контрольной суммы будет извлечено некоторое количество битов, что даст нам номер «раздела».
Номер раздела позволяет вам посмотреть на «кольцо», чтобы увидеть, на каком сервере и диске должен храниться этот конкретный объект. «Кольцо» — это соответствие между номером раздела и серверами объектов, которые должны хранить объекты, принадлежащие этому разделу.
Давайте посмотрим на пример. В этом случае мы будем использовать только 2 бита из контрольной суммы md5 (слишком мало, но рисовать гораздо проще! Всего 4 раздела)
При загрузке файла, от его имени и других элементов, мы получаем контрольную сумму md5, 72acded3acd45e4c8b6ed680854b8ab1. Если мы возьмем 2 старших бита, мы получим раздел 1.
Из кольца объектов мы получаем список серверов, на которых должны храниться копии объекта.
При рекомендованной настройке Swift вы сохраните три идентичные копии объекта. Для одной загрузки мы создаем три реальных файла на трех разных серверах.
Политика Swift
Мы только что видели, как наиболее распространенная политика Swift — хранить идентичные копии объекта.
Это может быть немного дорого для некоторых случаев использования, и Swift также поддерживает политики «стирания кодирования».
Давайте сравним их сейчас.
«Политика реплик», которую мы только что описали. Вы можете выбрать, сколько копий объектов вы хотите сохранить.
Тип политики «кодирование стирания»
Объект разбивается на фрагменты с добавлением лишних частей, чтобы можно было реконструировать объект, если диск, содержащий фрагмент, выйдет из строя.
В OVHcloud мы используем политику 12 + 3 (12 частей от объекта и 3 вычисляемых части)
Этот режим более экономичен, чем репликация, но он также создает больше файлов в инфраструктуре. В нашей конфигурации мы должны создать 15 файлов в инфраструктуре, а не 3 файла со стандартной политикой «репликации».
Почему это проблема?
В кластерах, где у нас есть комбинация политики кодирования стирания и среднего размера объекта 32 КБ, мы получим более 70 миллионов файлов * на диск *.
На сервере с 36 дисками это 2,5 миллиарда файлов.
Кластеру Swift необходимо регулярно перечислять эти файлы, чтобы:
- Подавать объект покупателям
- Обнаружение битовой гнили
- Реконструировать объект, если фрагмент был потерян из-за сбоя диска
Обычно список файлов на жестком диске выполняется довольно быстро, благодаря кешу каталогов Linux. Однако на некоторых кластерах мы заметили, что время для вывода списка файлов увеличивалось, и большая часть емкости ввода-вывода жесткого диска использовалась для чтения содержимого каталога: было слишком много файлов, и система не могла кэшировать содержимое каталога. Потеря большого количества операций ввода-вывода для этого означала, что время отклика кластера становилось все медленнее, а задачи восстановления (восстановление фрагментов, потерянных из-за сбоев диска) отставали.
В следующем посте мы увидим, как мы это решили.
0 комментариев