Абстрактно
Мне как исследователю необходимо проводить эксперименты, чтобы подтвердить свои гипотезы. Когда речь идет о компьютерных науках, хорошо известно, что специалисты-практики обычно проводят эксперименты в различных средах (на аппаратном уровне: x86 / arm /…, частота процессора, доступная память или на уровне программного обеспечения: операционная система, версии библиотек). Проблема с этими различными средами заключается в сложности точного воспроизведения эксперимента, как он был представлен в исследовательской статье.
В этом посте мы предлагаем способ проведения экспериментов, который можно воспроизвести с помощью Kubernetes-as-a-service, управляемой платформы для выполнения распределенных вычислений вместе с другими инструментами (Argo, MinIO), которые учитывают преимущества платформы.

Статья организована следующим образом: сначала мы вспомним контекст и проблему, с которой сталкивается исследователь, которому необходимо провести эксперименты. Затем мы объясняем, как решить проблему с Kubernetes и почему мы не выбрали другие решения (например, программное обеспечение HPC). Наконец, дадим несколько советов по улучшению настройки.
Вступление
Когда я начал свою докторскую диссертацию, я прочитал кучу статей, относящихся к той области, в которой я работаю, то есть к AutoML. Из этого исследования я понял, насколько важно хорошо проводить эксперименты, чтобы они были достоверными и проверяемыми. Я начал спрашивать своих коллег, как они проводят свои эксперименты, и у них был общий шаблон: разработайте свое решение, посмотрите на другие решения, связанные с той же проблемой, запустите каждое решение 30 раз, если оно стохастическое. с эквивалентными ресурсами и сравните свои результаты с другими решениями с помощью статистических тестов: Вилкоксона-Манна-Уитни при сравнении двух алгоритмов или теста Фридмана. Поскольку это не основная тема данной статьи, я не буду подробно останавливаться на статистических тестах.
Как опытный DevOps, у меня был один вопрос по автоматизации: как мне узнать, как воспроизвести эксперимент, особенно другого решения? Угадай ответ? Внимательно прочтите статью или найдите хранилище со всей информацией.
Либо вам повезло и исходный код доступен, либо в публикации указан псевдокод. В этом случае вам необходимо повторно реализовать решение, чтобы можно было его протестировать и сравнить. Даже если вам повезло и есть доступный исходный код, часто отсутствует вся среда (например, точная версия пакетов, сама версия python, версия JDK и т. Д.…). Отсутствие нужной информации влияет на производительность и может потенциально искажать эксперименты. Например, новые версии пакетов, языков и т. Д. Обычно имеют лучшую оптимизацию, которую может использовать ваша реализация. Иногда бывает сложно найти версии, которые использовались практикующими.
Другая проблема — сложность настройки кластера с помощью программного обеспечения HPC (например, Slurm, Torque). Действительно, для управления таким решением требуются технические знания: настройка сети, проверка того, что каждый узел имеет зависимости, необходимые для установленных запусков, проверка того, что узлы имеют одинаковые версии библиотек и т. Д. Эти технические шаги отнимают время у исследователей, таким образом отвлеките их от основной работы. Более того, чтобы извлечь результаты, исследователи обычно делают это вручную, они извлекают различные файлы (через FTP или NFS), а затем выполняют статистические тесты, которые сохраняют вручную. Следовательно, рабочий процесс проведения эксперимента относительно дорог и ненадежен.
С моей точки зрения, это поднимает одну
большую проблему: эксперимент не может быть воспроизведен в области компьютерных наук.
Решение
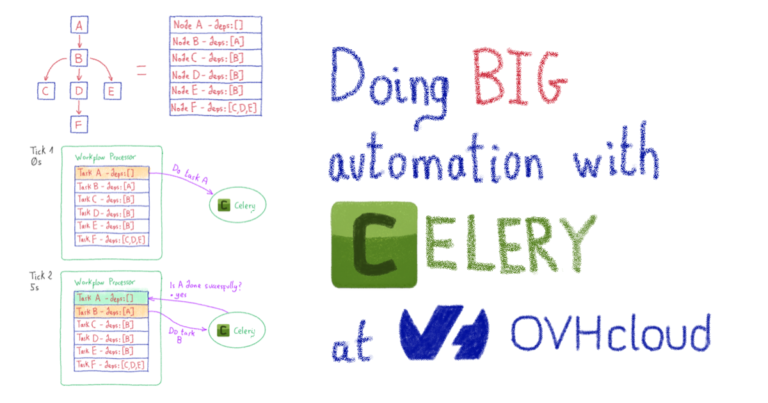
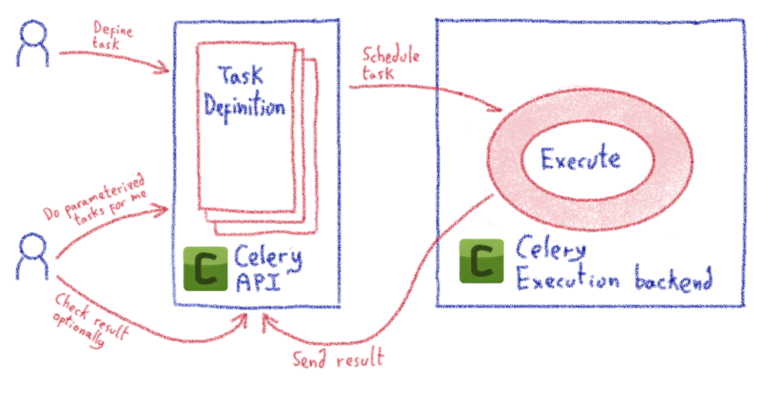
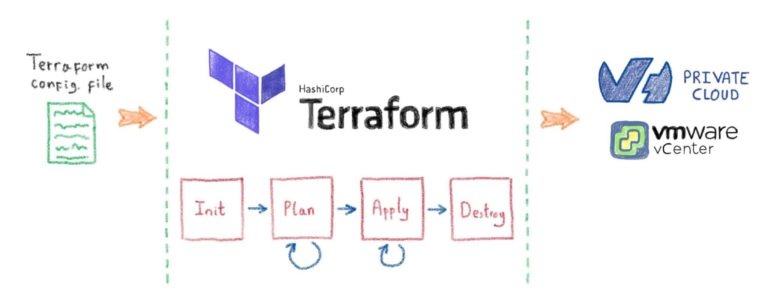
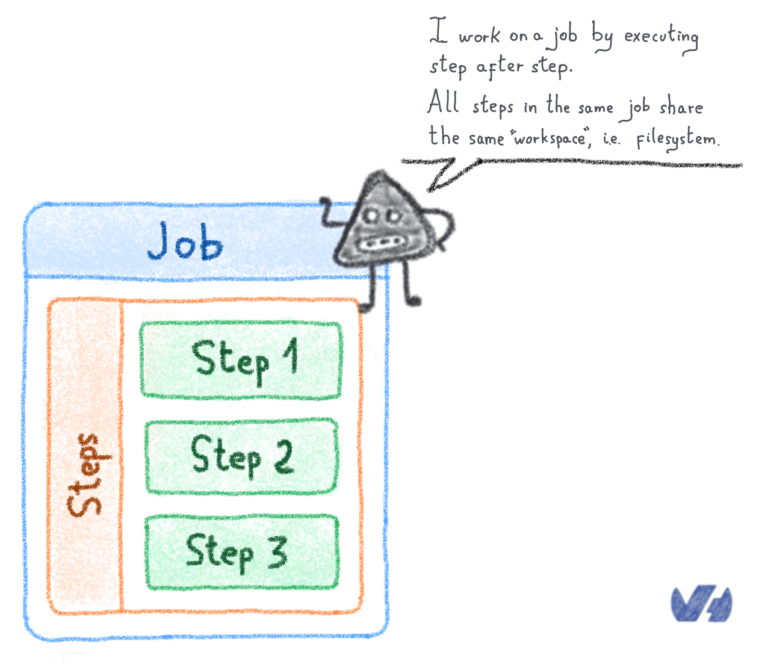
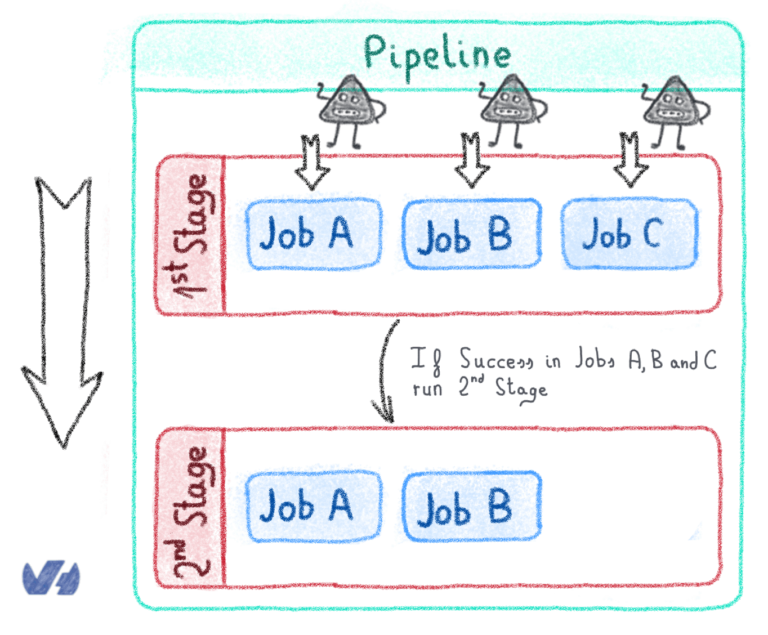
OVH предлагает Kubernetes-as-a-service, платформу управляемого кластера, где вам не нужно беспокоиться о том, как настроить кластер (добавить узел, настроить сеть и т. Д.), Поэтому я начал исследовать, как я мог бы аналогичным образом проводить эксперименты. к решениям для высокопроизводительных вычислений. Argo Workflows вышла из коробки. Этот инструмент позволяет вам определять рабочий процесс шагов, которые вы можете выполнять в своем кластере Kubernetes, когда каждый шаг заключен в контейнер, который в общих чертах называется образом. Контейнер позволяет запускать программу в определенной среде программного обеспечения (языковая версия, библиотеки, сторонние программы), дополнительно ограничивая ресурсы (время процессора, память), используемые программой.
Решение связано с нашей большой проблемой: убедитесь, что вы можете воспроизвести эксперимент, который эквивалентен запустить рабочий процесс, состоящий из этапов в соответствии с конкретной средой.
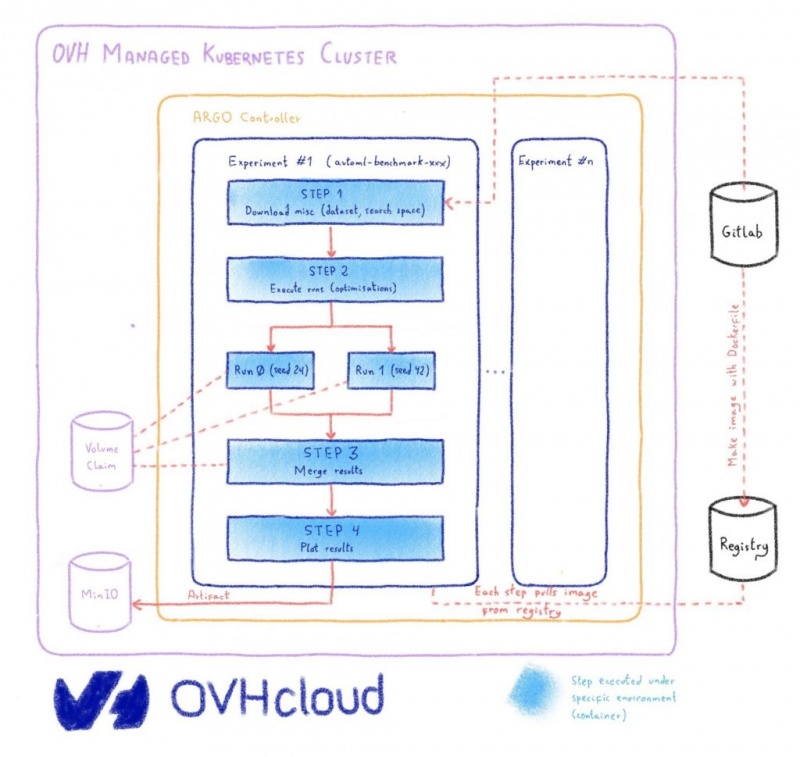
Пример использования: оценка решения AutoML
Вариант использования, который мы используем в нашем исследовании, будет связан с измерением сходимости байесовской оптимизации (SMAC) по проблеме AutoML.
Для этого варианта использования мы указали рабочий процесс Argo в следующем файле yaml
Настроить инфраструктуру
Сначала мы настроим кластер Kubernetes, во-вторых, мы установим службы в нашем кластере и, наконец, проведем эксперимент.
Кластер Kubernetes
Установка кластера Kubernetes с OVH — это детская игра. Подключитесь к панели управления OVH, перейдите к Public Cloud > Managed Kubernetes Service, затем Create a Kubernetes clusterследуйте инструкциям в зависимости от ваших потребностей.
- После создания кластера:
- Примите во внимание политику обновления изменений. Если вы исследователь и для выполнения вашего эксперимента требуется некоторое время, вам следует избегать обновления, которое отключило бы вашу инфраструктуру во время выполнения. Чтобы избежать такой ситуации, лучше выбрать «Минимальная недоступность» или «Не обновлять».
- Загрузите
kubeconfig
файл, он будет использоваться позже kubectl
для подключения к нашему кластеру. - Добавьте хотя бы один узел в свой кластер.
После установки вам понадобится kubectl — инструмент, позволяющий управлять кластером.Если все настроено правильно, должно получиться примерно следующее:
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node01 64m 3% 594Mi 11%
Установка Арго
Как мы упоминали ранее, Argo позволяет нам запускать рабочий процесс, состоящий из шагов. Этот учебник вдохновил нас на установку клиента и службы в кластере.Сначала скачиваем и устанавливаем Арго (клиент):
curl -sSL -o /usr/local/bin/argo https://github.com/argoproj/argo/releases/download/v2.3.0/argo-linux-amd64
chmod +x /usr/local/bin/argo
Настройте учетную запись службы:
kubectl create rolebinding default-admin --clusterrole=admin --serviceaccount=default:default
Затем с клиентом попробуйте простой рабочий процесс hello-world, чтобы убедиться, что стек работает (статус: успешно):
argo submit --watch https://raw.githubusercontent.com/argoproj/argo/master/examples/hello-world.yaml
Name: hello-world-2lx9d
Namespace: default
ServiceAccount: default
Status: Succeeded
Created: Tue Aug 13 16:51:32 +0200 (24 seconds ago)
Started: Tue Aug 13 16:51:32 +0200 (24 seconds ago)
Finished: Tue Aug 13 16:51:56 +0200 (now)
Duration: 24 seconds
STEP PODNAME DURATION MESSAGE
✔ hello-world-2lx9d hello-world-2lx9d 23s
Вы также можете получить доступ к панели управления пользовательского интерфейса через
localhost:8001:
kubectl port-forward -n argo service/argo-ui 8001:80
Настроить репозиторий артефактов (MinIO)
Артефакт — это термин, используемый Argo, он представляет собой архив, содержащий файлы, возвращаемые шагом. В нашем случае мы будем использовать эту функцию, чтобы возвращать окончательные результаты и делиться промежуточными результатами между шагами.Чтобы Artifact работал, нам нужно хранилище объектов. Если он у вас уже есть, вы можете пропустить часть установки, но все равно нужно его настроить.Как указано в руководстве, мы использовали MinIO, вот манифест для его установки ( minio-argo-artifact.install.yml):
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
# This name uniquely identifies the PVC. Will be used in deployment below.
name: minio-pv-claim
labels:
app: minio-storage-claim
spec:
# Read more about access modes here: https://kubernetes.io/docs/user-guide/persistent-volumes/#access-modes
accessModes:
- ReadWriteOnce
resources:
# This is the request for storage. Should be available in the cluster.
requests:
storage: 10
# Uncomment and add storageClass specific to your requirements below. Read more https://kubernetes.io/docs/concepts/storage/persistent-volumes/#class-1
#storageClassName:
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
# This name uniquely identifies the Deployment
name: minio-deployment
spec:
strategy:
type: Recreate
template:
metadata:
labels:
# Label is used as selector in the service.
app: minio
spec:
# Refer to the PVC created earlier
volumes:
- name: storage
persistentVolumeClaim:
# Name of the PVC created earlier
claimName: minio-pv-claim
containers:
- name: minio
# Pulls the default MinIO image from Docker Hub
image: minio/minio
args:
- server
- /storage
env:
# MinIO access key and secret key
- name: MINIO_ACCESS_KEY
value: "TemporaryAccessKey"
- name: MINIO_SECRET_KEY
value: "TemporarySecretKey"
ports:
- containerPort: 9000
# Mount the volume into the pod
volumeMounts:
- name: storage # must match the volume name, above
mountPath: "/storage"
---
apiVersion: v1
kind: Service
metadata:
name: minio-service
spec:
ports:
- port: 9000
targetPort: 9000
protocol: TCP
selector:
app: minio
- Примечание . Измените следующие пары «ключ-значение»:
kubectl create ns minio
kubectl apply -n minio -f minio-argo-artifact.install.yml
Примечание: в качестве альтернативы вы можете установить MinIO с Helm.Теперь нам нужно настроить Argo, чтобы использовать наше хранилище объектов MinIO:
kubectl edit cm -n argo workflow-controller-configmap
...
data:
config: |
artifactRepository:
s3:
bucket: my-bucket
endpoint: minio-service.minio:9000
insecure: true
# accessKeySecret and secretKeySecret are secret selectors.
# It references the k8s secret named 'argo-artifacts'
# which was created during the minio helm install. The keys,
# 'accesskey' and 'secretkey', inside that secret are where the
# actual minio credentials are stored.
accessKeySecret:
name: argo-artifacts
key: accesskey
secretKeySecret:
name: argo-artifacts
key: secretkey
Добавьте учетные данные:
kubectl create secret generic argo-artifacts --from-literal=accesskey="TemporaryAccessKey" --from-literal=secretkey="TemporarySecretKey"
Примечание. Используйте правильные учетные данные, указанные выше.Создайте ведро my-bucketс правами Read and writeподключившись к интерфейсу
localhost:9000:
kubectl port-forward -n minio service/minio-service 9000
Убедитесь, что Argo может использовать Artifact с хранилищем объектов:
argo submit --watch https://raw.githubusercontent.com/argoproj/argo/master/examples/artifact-passing.yaml
Name: artifact-passing-qzgxj
Namespace: default
ServiceAccount: default
Status: Succeeded
Created: Wed Aug 14 15:36:03 +0200 (13 seconds ago)
Started: Wed Aug 14 15:36:03 +0200 (13 seconds ago)
Finished: Wed Aug 14 15:36:16 +0200 (now)
Duration: 13 seconds
STEP PODNAME DURATION MESSAGE
✔ artifact-passing-qzgxj
├---✔ generate-artifact artifact-passing-qzgxj-4183565942 5s
└---✔ consume-artifact artifact-passing-qzgxj-3706021078 7s
Примечание: если вы застряли с сообщением ContainerCreating, есть большая вероятность, что Argo не сможет получить доступ к MinIO, например, из-за неверных учетных данных.
Установить частный реестр
Теперь, когда у нас есть способ запустить рабочий процесс, мы хотим, чтобы каждый шаг представлял конкретную программную среду (то есть изображение). Мы определили эту среду в Dockerfile.Поскольку каждый шаг может выполняться на разных узлах в нашем кластере, образ необходимо где-то хранить, в случае Docker нам требуется частный реестр.Получить приватный реестр можно разными способами:
В нашем случае мы использовали частный реестр OVH.
# First we clone the repository
git clone git@gitlab.com:automl/automl-smac-vanilla.git
cd automl-smac-vanilla
# We build the image locally
docker build -t asv-environment:latest .
# We push the image to our private registry
docker login REGISTRY_SERVER -u REGISTRY_USERNAME
docker tag asv-environment:latest REGISTRY_IMAGE_PATH:latest
docker push REGISTRY_IMAGE_PATH:latest
Разрешите нашему кластеру извлекать образы из реестра:
kubectl create secret docker-registry docker-credentials --docker-server=REGISTRY_SERVER --docker-username=REGISTRY_USERNAME --docker-password=REGISTRY_PWD
Попробуйте наш эксперимент на инфраструктуре
git clone git@gitlab.com:automl/automl-smac-vanilla.git
cd automl-smac-vanilla
argo submit --watch misc/workflow-argo -p image=REGISTRY_IMAGE_PATH:latest -p git_ref=master -p dataset=iris
Name: automl-benchmark-xlbbg
Namespace: default
ServiceAccount: default
Status: Succeeded
Created: Tue Aug 20 12:25:40 +0000 (13 minutes ago)
Started: Tue Aug 20 12:25:40 +0000 (13 minutes ago)
Finished: Tue Aug 20 12:39:29 +0000 (now)
Duration: 13 minutes 49 seconds
Parameters:
image: m1uuklj3.gra5.container-registry.ovh.net/automl/asv-environment:latest
dataset: iris
git_ref: master
cutoff_time: 300
number_of_evaluations: 100
train_size_ratio: 0.75
number_of_candidates_per_group: 10
STEP PODNAME DURATION MESSAGE
✔ automl-benchmark-xlbbg
├---✔ pre-run automl-benchmark-xlbbg-692822110 2m
├-·-✔ run(0:42) automl-benchmark-xlbbg-1485809288 11m
| └-✔ run(1:24) automl-benchmark-xlbbg-2740257143 9m
├---✔ merge automl-benchmark-xlbbg-232293281 9s
└---✔ plot automl-benchmark-xlbbg-1373531915 10s
Примечание :
Затем мы просто получаем результаты через веб-интерфейс пользователя MinIO
localhost:9000(вы также можете сделать это с помощью клиента ).
Результаты находятся в каталоге с тем же именем, что и имя рабочего процесса argo, в нашем примере это так my-bucket > automl-benchmark-xlbbg.
Ограничение нашего решения
Решение не может выполнять параллельные шаги на нескольких узлах. Это ограничение связано с тем, как мы объединяем наши результаты от параллельных шагов к шагу слияния. Мы используем volumeClaimTemplates, то есть монтируем том, и это невозможно сделать между разными узлами. Проблему можно решить двумя способами:
- Использование параллельных артефактов и их агрегирование, однако это постоянная проблема с Argo
- Непосредственно реализовать в коде вашего запуска способ сохранить результат в доступном хранилище (например, MinIO SDK )
Первый способ предпочтительнее, это означает, что вам не нужно изменять и настраивать код для конкретной файловой системы хранилища.
Советы по улучшению решения
Если вы хотите продолжить настройку, вам следует изучить следующие темы:
- Контроль доступа : чтобы ограничить пользователей в разных пространствах (по соображениям безопасности или для контроля ресурсов).
- Исследуя селектор Арго и селектор Kubernetes : в случае , если у вас есть кластер состоит из узлов , которые имеют различное оборудование , и что вам требуется эксперимент с использованием конкретного оборудования (например, конкретный процессор, графический процессор).
- Настройте распределенный MinIO : он гарантирует, что ваши данные будут реплицированы на несколько узлов и останутся доступными в случае отказа узла.
- Мониторинг вашего кластера .
Вывод
Не нуждаясь в глубоких технических знаниях, мы показали, что можем легко настроить сложный кластер для проведения исследовательских экспериментов и убедиться, что они могут быть воспроизведены.

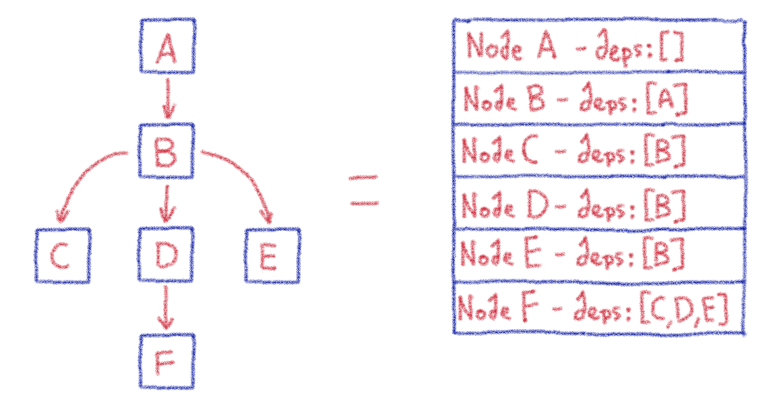
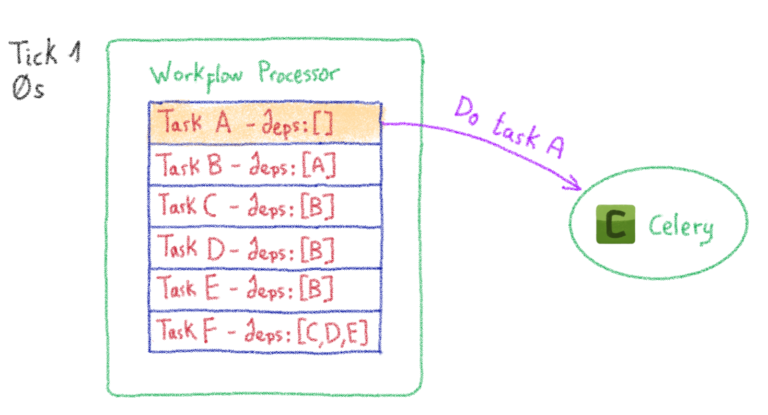
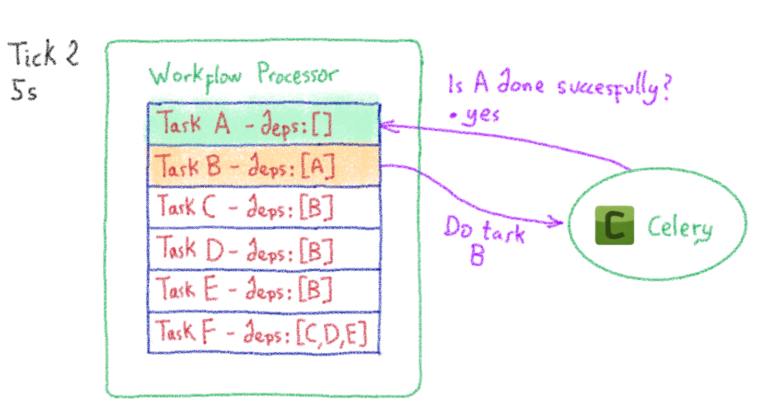






{kind=link}