Циклы: обеспечение непрерывных запросов с помощью Observability FaaS
Все мы знакомы с этим небольшим фрагментом кода, который добавляет разумную ценность вашему бизнес-подразделению. Он может материализоваться в виде сценария, программы, строки кода… и будет создавать отчет, новые показатели, ключевые показатели эффективности или создавать новые составные данные. Этот код предназначен для периодического запуска, чтобы соответствовать требованиям к актуальной информации.
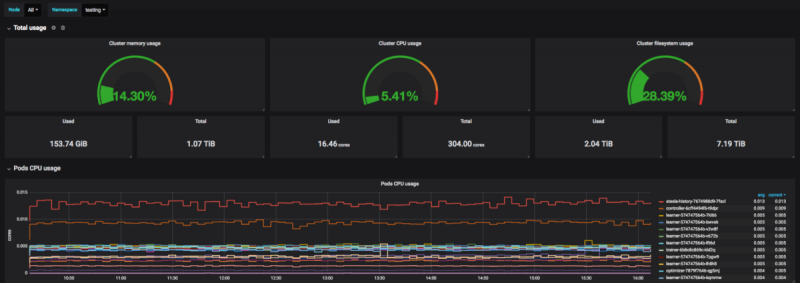
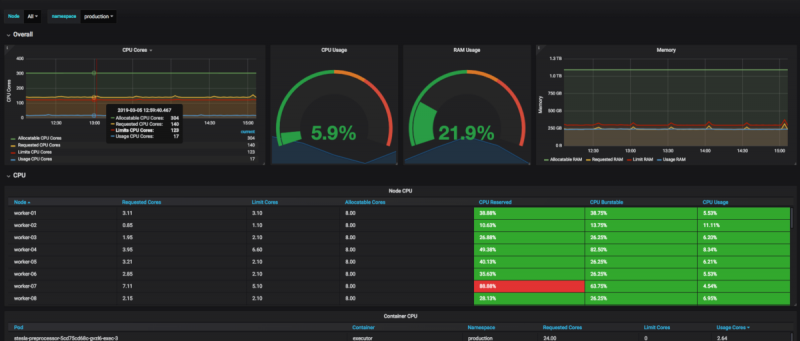
В команде Observability мы встречаем эти фрагменты как запросы в базе данных временных рядов (TSDB), чтобы выражать непрерывные запросы, которые отвечают за автоматизацию различных вариантов использования, таких как: удаление, сведение или любая бизнес-логика, которая должна манипулировать данными временных рядов.
Мы уже представили TSL в предыдущем сообщении блога , в котором было продемонстрировано, как наши клиенты используют доступные протоколы OVH Metrics, такие как Graphite, OpenTSDB, PromQL и WarpScript ™, но когда дело доходит до манипулирования или даже создания новых данных , у вас нет много вариантов, хотя вы можете использовать WarpScript ™ или TSL в качестве языка сценариев вместо языка запросов.
В большинстве случаев эта бизнес-логика требует создания приложения, что требует больше времени, чем выражение логики в виде запроса, нацеленного на TSDB. Создание кода базового приложения — это первый шаг, за которым следует CI / CD (или любой процесс доставки) и настройка его мониторинга. Однако управление сотнями таких небольших приложений приведет к увеличению органических затрат из-за необходимости поддерживать их вместе с базовой инфраструктурой.
Мы хотели, чтобы эти ценные задачи не ложились на головы нескольких разработчиков, которым в таком случае пришлось бы нести ответственность за владение данными и вычислительные ресурсы , поэтому мы задавались вопросом, как мы можем автоматизировать вещи, не полагаясь на команду в настройке вычислять задания каждый раз, когда кому-то что-то нужно.
Нам нужно было решение, которое сфокусировалось бы на бизнес-логике без необходимости запускать все приложение. Таким образом, кому-то, кто хочет создать файл JSON с ежедневным отчетом (например), нужно будет только выразить соответствующий запрос.
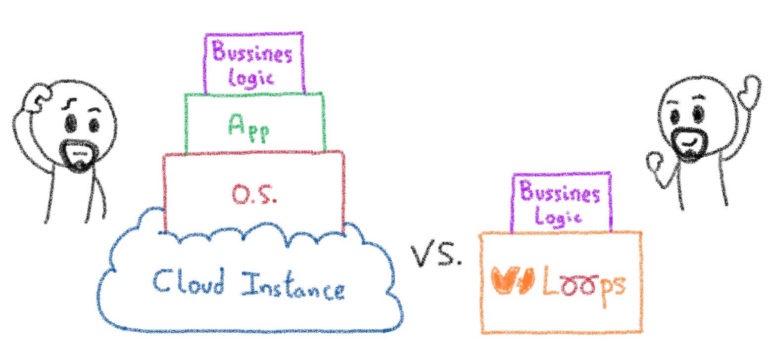
Вы не должны FaaS!
Планирование работы — старая привычная рутина. Будь то задания bash cron, раннеры или специализированные планировщики, когда дело доходит до упаковки фрагмента кода и его периодического запуска, для этого есть название: FaaS.
FaaS был создан с простой целью: сократить время разработки. Мы могли бы найти реализацию с открытым исходным кодом для оценки (например, OpenFaas ), но большинство из них полагалось на управляемый стек контейнеров. Наличие одного контейнера на запрос было бы очень дорогостоящим, плюс разогрев контейнера для выполнения функции, а затем его замораживание было бы очень контрпродуктивным.
Это потребовало бы большего планирования и автоматизации, чем мы хотели для нашей конечной цели, привело бы к неоптимальной производительности и ввело бы новое требование для управления емкостью кластера. Также существует время сборки, необходимое для развертывания новой функции в контейнере, которое, следовательно, не является бесплатным.
#def <Циклы>
Именно тогда мы решили создать «Loops»: платформу приложений, на которой вы можете отправить код, который хотите запустить. Вот и все. Цель состоит в том, чтобы продвинуть функцию (буквально!), А не модуль, как это делают все текущие решения FaaS:
function dailyReport(event) {
return Promise.resolve('Today, everything is fine !')
}Затем вы можете выполнить его вручную, используя HTTP-вызов или планировщик, подобный Cron.
Оба эти аспекта необходимы, поскольку у вас может быть (например) ежемесячный отчет, но в один прекрасный день потребуется дополнительный, через 15 дней после последнего отчета. Циклы упростят создание нового отчета вручную в дополнение к ежемесячному.
Когда мы начали создавать Loops, были некоторые необходимые ограничения:
- Эта платформа должна легко масштабироваться , чтобы поддерживать производственную нагрузку OVH.
- Он должен быть высокодоступным
- Он должен быть независимым от языка , потому что некоторые из нас предпочитают Python, а другие JavaScript.
- Это должно быть надежно
- Часть планирования не должна коррелировать с частью выполнения ( культура μService )
- Он должен быть безопасным и изолированным, чтобы любой мог размещать непонятный код на платформе.
Реализация петель
Мы решили построить нашу первую версию на V8 . Мы выбрали JavaScript в качестве первого языка, потому что его легко изучить, а асинхронными потоками данных легко управлять с помощью Promises. Кроме того, он очень хорошо сочетается с FaaS, поскольку функции Javascript очень выразительны. Мы построили его на основе нового модуля виртуальной машины NodeJS , который позволяет выполнять код в выделенном контексте V8 .
Контекст V8 похож на объект (JSON), изолированный от вашего исполнения. В контексте вы можете найти собственные функции и объекты. Однако, если вы создадите новый контекст V8, вы увидите, что некоторые переменные или функции изначально недоступны (например, setTimeout (), setInterval () или Buffer ). Если вы хотите их использовать, вам придется внедрить их в свой новый контекст. Последнее, что нужно помнить, это то, что когда у вас есть новый контекст, вы можете легко выполнить сценарий JavaScript в строковой форме.
Контексты выполняют самую важную часть нашего первоначального списка требований: изоляцию . Каждый контекст V8 изолирован, поэтому он не может взаимодействовать с другим контекстом. Это означает, что глобальная переменная, определенная в одном контексте, недоступна в другом. Вам придется построить между ними мост, если вы хотите, чтобы это было так.
Мы не хотели выполнять скрипты с eval () , поскольку вызов этой функции позволяет выполнять JS-код в основном общем контексте с вызывающим его кодом. Затем вы можете получить доступ к тем же объектам, константам, переменным и т. Д. Эта проблема безопасности стала нарушением условий сделки для новой платформы.
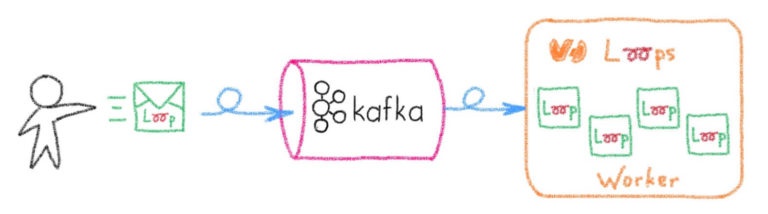
Теперь мы знаем, как выполнять наши скрипты, давайте реализуем для них некоторое управление. Чтобы не иметь состояния , каждый экземпляр рабочего цикла Loops (то есть движок JavaScript, способный запускать код в контексте виртуальной машины) должен иметь последнюю версию каждого цикла (цикл — это сценарий, который нужно выполнить). Это означает, что когда пользователь отправляет новый цикл, мы должны синхронизировать его с каждым рабочим циклом. Эта модель хорошо согласуется с парадигмой pub / sub, и, поскольку мы уже используем Kafka в качестве инфраструктуры pub / sub, оставалось лишь создать специальную тему и использовать ее у рабочих. В этом случае публикация включает API, в который пользователь отправляет свои циклы, которые создают событие Kafka, содержащее тело функции. Поскольку у каждого воркера есть своя группа потребителей Kafka, все они получают одинаковые сообщения.
Рабочие подписываются на обновления Loops как потребители Kafka и поддерживают хранилище Loop, которое представляет собой встроенный ключ (хэш Loop) / значение (текущая версия функции). В части API хэши цикла используются в качестве параметров URL для определения того, какой цикл выполнять. После вызова цикл извлекается из карты, затем вводится в контекст V8 , выполняется и отбрасывается. Этот механизм перезагрузки горячего кода гарантирует, что каждый цикл может быть выполнен для каждого рабочего. Мы также можем использовать возможности наших балансировщиков нагрузки для распределения нагрузки на рабочих. Эта простая модель распределения позволяет избежать сложного планирования и упрощает обслуживание всей инфраструктуры.
Для защиты от перезагрузки мы используем очень удобную функцию сжатия журналов Kafka . Сжатие журнала позволяет Kafka сохранять последнюю версию каждого сообщения с ключом. Когда пользователь создает новый цикл, ему будет присвоен уникальный идентификатор, который используется в качестве ключа сообщения Kafka. Когда пользователь обновляет цикл, это новое сообщение будет перенаправлено всем потребителям, но поскольку ключ уже существует, Kafka сохранит только последнюю версию. Когда рабочий перезапускается, он будет использовать все сообщения для восстановления своего внутреннего KV, поэтому будет восстановлено предыдущее состояние. Кафка здесь используется как постоянное хранилище .
Время выполнения циклов
Даже если базовый движок может запускать собственный Javascript, как указано выше, мы хотели, чтобы он выполнял более идиоматические запросы временных рядов, такие как TSL или WarpScript ™ . Для этого мы создали абстракцию Loops Runtime, которая оборачивает не только Javascript, но также запросы TSL и WarpScript ™ в код Javascript. Пользователи должны объявить цикл с его средой выполнения, после чего остается лишь вопрос работы оберток. Например, выполнение цикла WarpScript ™ включает в себя использование простого сценария WarpScript ™ и его отправку посредством HTTP-вызова запроса узла.
Обратная связь по петлям
Безопасное выполнение кода — это начало, но когда дело доходит до выполнения произвольного кода, также полезно получить некоторую обратную связь о состоянии выполнения . Удачно это было или нет? В функции есть ошибка? Если цикл находится в состоянии сбоя, пользователь должен быть немедленно уведомлен.
Это приводит нас к одному особому условию: скрипты пользователя должны уметь определять, все ли в порядке или нет. В базовом движке JavaScript есть два способа сделать это : обратные вызовы и обещания.
Мы выбрали Promises, который предлагает лучшее асинхронное управление. Каждый цикл возвращает обещание в конце скрипта. Отклоненное обещание приведет к статусу ошибки HTTP 500, а решенное — к статусу HTTP 200.
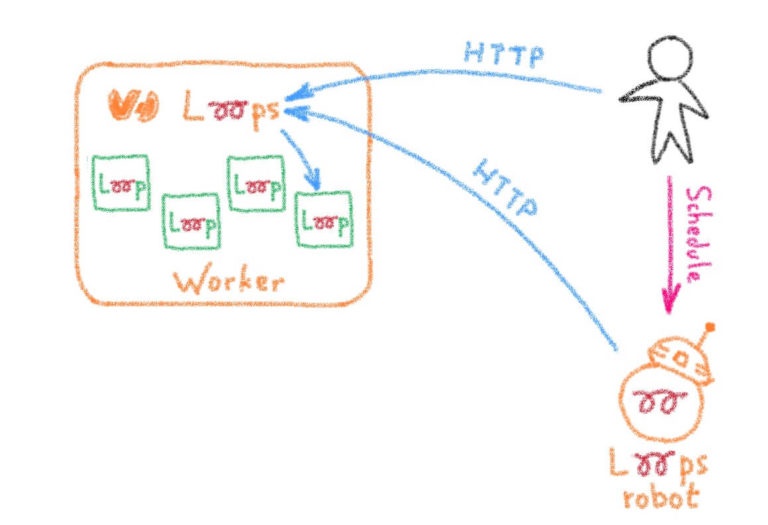
Планирование циклов
При публикации Loops вы можете объявить несколько триггеров аналогично Cron. Каждый триггер будет выполнять HTTP-вызов вашего цикла с дополнительными параметрами.
На основе этой семантики для создания нескольких отчетов мы можем зарегистрировать одну функцию, которая будет планироваться в разных контекстах, определяемых различными параметрами (регион, скорость и т. Д.). См. Пример ниже:
functions:
warp_apps_by_cells:
handler: apps-by-cells.mc2
runtime: ws
timeout: 30
environment:
events:
- agra:
rate: R/2018-01-01T00:00:00Z/PT5M/ET1M
params:
cell: ovh-a-gra
- abhs:
rate: R/2018-01-01T00:00:00Z/PT5M/ET1M
params:
cell: ovh-a-bhsПланирование основано на Metronome, который представляет собой планировщик событий с открытым исходным кодом, с особым упором на планирование, а не на выполнение. Это идеально подходит для циклов, поскольку циклы обрабатывают выполнение, а метроном управляет вызовами выполнения.
Петли трубопроводов
В проекте Loops может быть несколько циклов. Одним из распространенных вариантов использования наших клиентов было использование Loops в качестве платформы данных в режиме потока данных. Поток данных — это способ описания конвейера этапов выполнения. В контексте Loops есть глобальный объект Loop, который позволяет сценарию выполнять другой цикл с этим именем. Затем вы можете связать выполнение цикла, которое будет действовать как пошаговые функции.
Болевые точки: масштабирование приложения NodeJS
Рабочие циклов — это приложения NodeJS. Большинство разработчиков NodeJS знают, что NodeJS использует однопоточный цикл обработки событий . Если вы не позаботитесь о потоковой модели своего приложения nodeJS, вы, скорее всего, пострадаете из-за недостаточной производительности, поскольку будет использоваться только один поток хоста.
NodeJS также имеет доступный модуль кластера , который позволяет приложению использовать несколько потоков. Вот почему в воркере Loops мы начинаем с потока N-1 для обработки вызовов API, где N — общее количество доступных потоков, в результате чего один остается выделенным для главного потока.
Главный поток отвечает за использование тем Kafka и поддержание хранилища Loops , а рабочий поток запускает сервер API. Для каждого запрошенного выполнения цикла он запрашивает у мастера содержимое скрипта и выполняет его в выделенном потоке.
При такой настройке на каждом сервере запускается одно приложение NodeJS с одним потребителем Kafka, что позволяет очень легко масштабировать инфраструктуру, просто добавляя дополнительные серверы или облачные экземпляры.
Вывод
В этом посте мы предварительно ознакомились с Loops, масштабируемой, ориентированной на метрики FaaS с встроенной поддержкой JavaScript и расширенной поддержкой WarpScript ™ и TSL .
У нас еще есть несколько вещей, которые нужно улучшить, например импорт зависимостей в стиле ES5 и предварительный просмотр показателей для проектов циклов наших клиентов. Мы также планируем добавить больше сред выполнения , особенно WASM , что позволит использовать многие другие языки, которые могут быть ориентированы на него, например Go, Rust или Python , в соответствии с предпочтениями большинства разработчиков.
Платформа Loops была частью требования по созданию высокоуровневых функций вокруг продуктов OVH Observability. Это первый шаг к предложению более автоматизированных сервисов, таких как накопление метрик , конвейеры агрегации или экстракторы журналов в метрики .
Этот инструмент был создан как часть набора продуктов Observability с учетом более высокого уровня абстракции, но вам также может потребоваться прямой доступ к API, чтобы реализовать собственную автоматизированную логику для ваших показателей. Вас заинтересует такая функция? Посетите наш канал Gitter, чтобы обсудить это с нами!