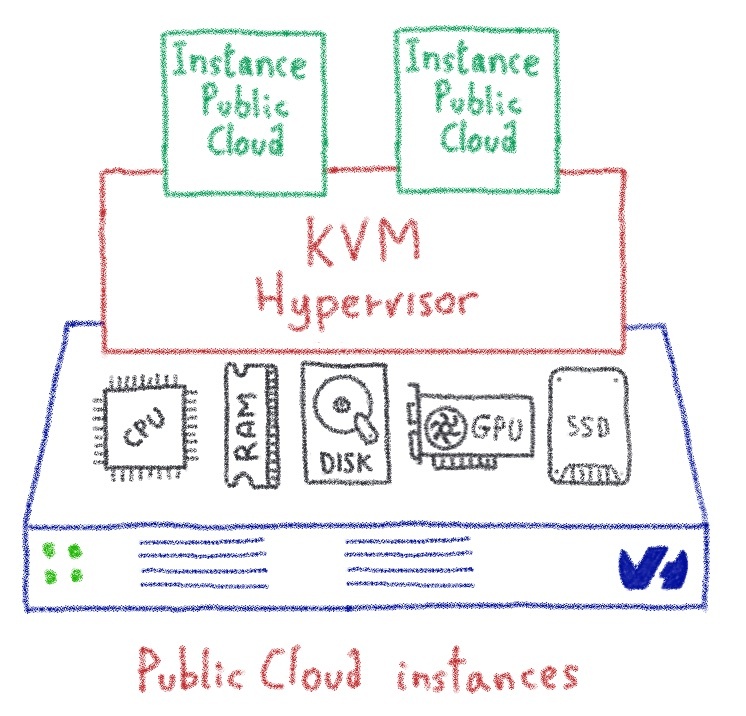
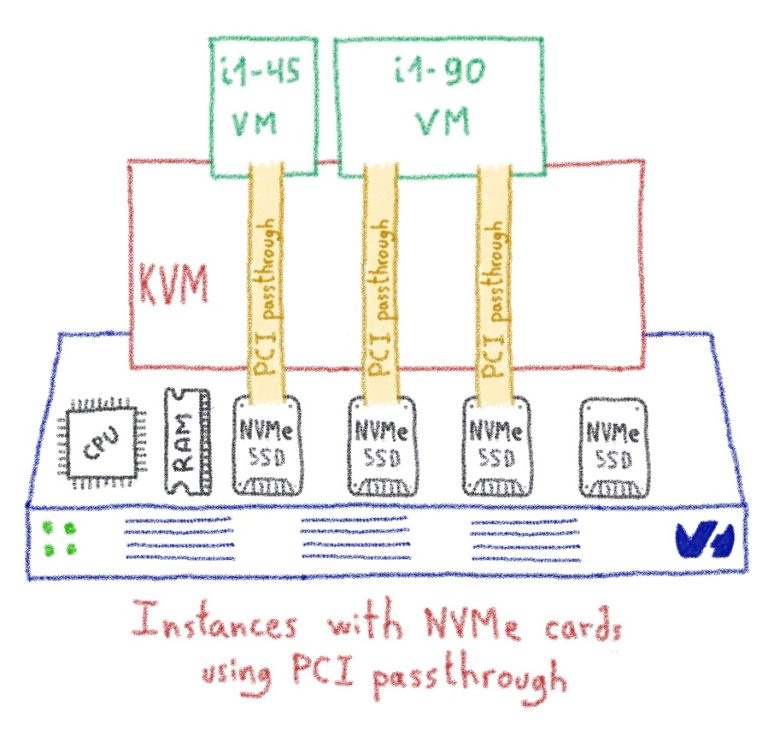
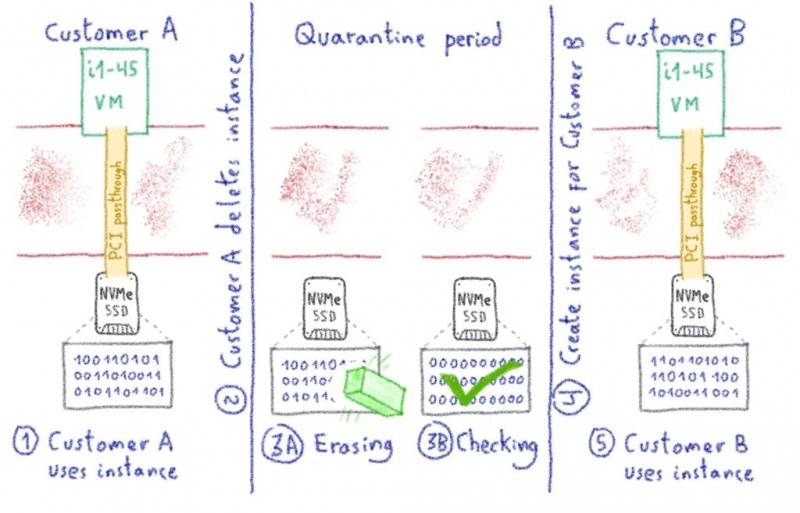
Водяное охлаждение: от инноваций к революционным изменениям - Часть II
В нашем предыдущем посте мы говорили о том, как наша технология водоблоков развивалась с 2003 по 2014 год. Сегодня мы продолжим эту тему, исследуя эту технологию после 2015 года. Мы сосредоточимся на текущем поколении водоблоков и дадим вам краткий обзор доработки впереди.
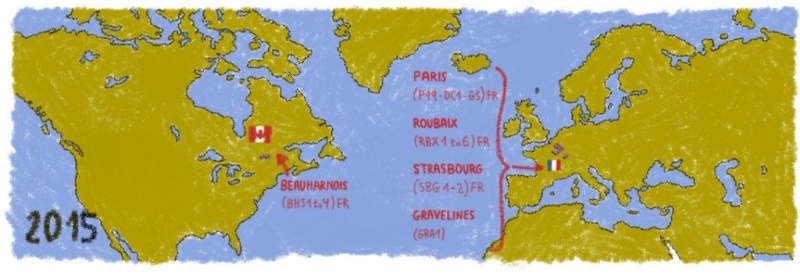
В 2015 году приблизился, наша ключевой целью заключалась в разработке водных блоков с производительностью оптимального по 120W и температурой воды 30 ° С .
Чтобы упростить процесс и снизить затраты, мы заменили металлическую крышку на АБС-пластик.
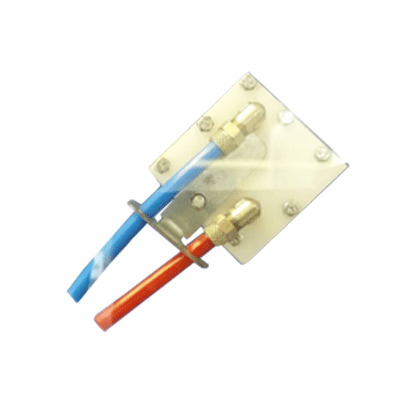
Использование пластиковых крышек позволило также построить прототипы без металлической арматуры для входных и выходных труб. Вместо фитингов трубы приклеили непосредственно к крышке водоблока.

Как и в предыдущих итерациях, мы также производили водоблоки меньшего форм-фактора. Например, вот вам водоблок GPU:

Использование пластиковых крышек для водоблоков также открыло двери для нового процесса прототипирования, включая 3D-печать. Мы начали экспериментировать с 3D-печатными водоблоками из АБС-пластика, тестируя различные типы крышек.
Варианты обложек, напечатанных на 3D-принтере:

Впервые в истории OVHcloud мы использовали расширенное моделирование CFD (вычислительная гидродинамика). Это позволило нам оптимизировать теплогидравлику пластин с медным основанием и дополнительно улучшить характеристики водоблока.

Именно в это время мы впервые использовали четырехуровневые покрытия, добавив избыточность и повысив надежность.

Мы всегда ищем стандартизованные подходы, применимые к различным географическим зонам и потребностям местных клиентов. Наряду с международной экспансией мы придерживались экологически безопасного подхода, поддерживая очень низкие уровни ODP ( потенциал разрушения озонового слоя ) и GWP ( потенциал глобального потепления ) в наших центрах обработки данных.
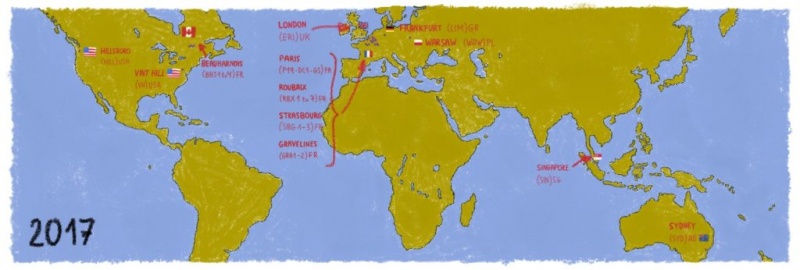
К 2017 году мы были в состоянии использовать водные блоки с оптимальной производительностью от 200Вт и температурой воды 30 ° C , и все было полностью разработано и изготовлено внутри на OVHcloud .
После крышек из АБС-пластика пришло время протестировать другие пластики, включая полиамиды.
Два примера водоблоков: один для стандартных процессоров, другой для графических процессоров, с белыми полиамидными крышками:


Водоблок для процессоров высокой плотности с черной крышкой из полиамидного пластика:

Эксперименты с полиамидным пластиком также позволили нам быстро спроектировать и протестировать различные прототипы для улучшения поддержки ЦП и снижения стоимости.

В OVHcloud у нас есть полный контроль от исследований и разработок до развертывания центра обработки данных. Мы можем постоянно внедрять инновации в короткие циклы, что значительно сокращает время между прототипированием и крупномасштабным развертыванием.
В результате мы сейчас более чем когда-либо способны выпускать новые продукты на рынок быстрее и по оптимальной цене. Многие из наших серверов доставляются за 120 секунд со 100% непрерывностью обслуживания, повышенной доступностью и оптимизированной производительностью инфраструктуры.
За последние два года мы начали работать с новой технологией, используя сваренные лазерной сваркой металлические опорные плиты и крышки. С помощью этой технологии мы можем избежать использования винтов и клея и минимизировать риск утечки.

На этих водоблоках трубопроводы полностью выполнены из медных сварных труб.

Как обычно, мы также производим водоблоки для определенных форм-факторов, таких как графические процессоры или процессоры высокой плотности.


В OVHcloud мы продолжаем выявлять, переносить и адаптировать то, что работает где-то еще, чтобы мы могли внедрять инновации и создавать собственные решения. Мы будем следовать циклам сбоев, чтобы повысить эффективность и сократить расходы, всегда стремясь создать добавленную стоимость для наших клиентов.
Мы работаем над водоблоками следующего поколения tier-4, используя нашу запатентованную технологию. Наши водоблоки 4-го уровня больше не являются прототипами, они готовы к производству, и мы активно работаем над моделированием и тестами для повышения производительности.

Мы стремимся к водоблокам мощностью 400 Вт с температурой воды 30 ° C и полностью резервным водоснабжением.

В OVHcloud мы гордимся своими научно-исследовательскими лабораториями. Они полностью привержены продвижению наших конкурентных преимуществ в отношении оборудования, программного обеспечения и наших проверенных на заказ методов проверки и тестирования серверов под нагрузкой. В наших лабораториях мы разрабатываем и тестируем решения для охлаждения, новые прототипы серверов и инновационные варианты хранения.

В будущих публикациях мы расскажем о других аспектах нашего процесса промышленных инноваций и посмотрим, какие выгоды получают наши клиенты от постоянного повышения надежности обслуживания и повышения ценовой эффективности.
2015 г.
В 2015 году приблизился, наша ключевой целью заключалась в разработке водных блоков с производительностью оптимального по 120W и температурой воды 30 ° С .
Чтобы упростить процесс и снизить затраты, мы заменили металлическую крышку на АБС-пластик.
Использование пластиковых крышек позволило также построить прототипы без металлической арматуры для входных и выходных труб. Вместо фитингов трубы приклеили непосредственно к крышке водоблока.
Как и в предыдущих итерациях, мы также производили водоблоки меньшего форм-фактора. Например, вот вам водоблок GPU:
3D-печать водяных блоков
Использование пластиковых крышек для водоблоков также открыло двери для нового процесса прототипирования, включая 3D-печать. Мы начали экспериментировать с 3D-печатными водоблоками из АБС-пластика, тестируя различные типы крышек.
Варианты обложек, напечатанных на 3D-принтере:
CFD моделирование
Впервые в истории OVHcloud мы использовали расширенное моделирование CFD (вычислительная гидродинамика). Это позволило нам оптимизировать теплогидравлику пластин с медным основанием и дополнительно улучшить характеристики водоблока.
Резервирование
Именно в это время мы впервые использовали четырехуровневые покрытия, добавив избыточность и повысив надежность.
2017 г.
Мы всегда ищем стандартизованные подходы, применимые к различным географическим зонам и потребностям местных клиентов. Наряду с международной экспансией мы придерживались экологически безопасного подхода, поддерживая очень низкие уровни ODP ( потенциал разрушения озонового слоя ) и GWP ( потенциал глобального потепления ) в наших центрах обработки данных.
К 2017 году мы были в состоянии использовать водные блоки с оптимальной производительностью от 200Вт и температурой воды 30 ° C , и все было полностью разработано и изготовлено внутри на OVHcloud .
После крышек из АБС-пластика пришло время протестировать другие пластики, включая полиамиды.
Два примера водоблоков: один для стандартных процессоров, другой для графических процессоров, с белыми полиамидными крышками:
Водоблок для процессоров высокой плотности с черной крышкой из полиамидного пластика:
Эксперименты с полиамидным пластиком также позволили нам быстро спроектировать и протестировать различные прототипы для улучшения поддержки ЦП и снижения стоимости.
2018-2019
В OVHcloud у нас есть полный контроль от исследований и разработок до развертывания центра обработки данных. Мы можем постоянно внедрять инновации в короткие циклы, что значительно сокращает время между прототипированием и крупномасштабным развертыванием.
В результате мы сейчас более чем когда-либо способны выпускать новые продукты на рынок быстрее и по оптимальной цене. Многие из наших серверов доставляются за 120 секунд со 100% непрерывностью обслуживания, повышенной доступностью и оптимизированной производительностью инфраструктуры.
За последние два года мы начали работать с новой технологией, используя сваренные лазерной сваркой металлические опорные плиты и крышки. С помощью этой технологии мы можем избежать использования винтов и клея и минимизировать риск утечки.
На этих водоблоках трубопроводы полностью выполнены из медных сварных труб.
Как обычно, мы также производим водоблоки для определенных форм-факторов, таких как графические процессоры или процессоры высокой плотности.
2020-…
В OVHcloud мы продолжаем выявлять, переносить и адаптировать то, что работает где-то еще, чтобы мы могли внедрять инновации и создавать собственные решения. Мы будем следовать циклам сбоев, чтобы повысить эффективность и сократить расходы, всегда стремясь создать добавленную стоимость для наших клиентов.
Мы работаем над водоблоками следующего поколения tier-4, используя нашу запатентованную технологию. Наши водоблоки 4-го уровня больше не являются прототипами, они готовы к производству, и мы активно работаем над моделированием и тестами для повышения производительности.
Мы стремимся к водоблокам мощностью 400 Вт с температурой воды 30 ° C и полностью резервным водоснабжением.
А кроме водоблоков?
В OVHcloud мы гордимся своими научно-исследовательскими лабораториями. Они полностью привержены продвижению наших конкурентных преимуществ в отношении оборудования, программного обеспечения и наших проверенных на заказ методов проверки и тестирования серверов под нагрузкой. В наших лабораториях мы разрабатываем и тестируем решения для охлаждения, новые прототипы серверов и инновационные варианты хранения.
В будущих публикациях мы расскажем о других аспектах нашего процесса промышленных инноваций и посмотрим, какие выгоды получают наши клиенты от постоянного повышения надежности обслуживания и повышения ценовой эффективности.