OVHcloud Web Statistics: новый интерфейс статистики для вашего веб-сайта, размещенного в OVHcloud
Если вы когда-либо управляли или редактировали веб-сайт, у вас наверняка будет опыт отслеживания просмотров страниц и статистики посещений.
Если это так, то эта статья для вас! Будьте готовы вступить в 2020 год с совершенно новым интерфейсом!
На рынке есть несколько решений, которые помогут вам анализировать посещения вашего веб-сайта.
Существуют два метода, которые помогут вам собрать эту информацию:
В 2004 году, чтобы обеспечить безопасность ваших данных, мы решили использовать локальное решение под названием Urchin… но пришло время меняться!
Почему?

Ежедневно мы вычисляем статистику по нескольким миллионам сайтов. Это особое требование, и существует несколько решений для его удовлетворения.
Что это за потребности:
Долгое время мы пытались избежать эффекта «придумано не здесь», потому что восстановление статистического инструмента — не наша основная работа. Поэтому мы перепробовали множество решений на рынке. Открытый исходный код или нет. Бесплатно или с лицензией. И мы не нашли решения, способного масштабировать наше количество журналов и вычислять статистику для всех веб-сайтов, которые мы размещаем!
Итак, мы решили разработать альтернативное решение и предложили его по умолчанию для всех: OVHcloud Web Statistics (или OWStats).
Новый пользовательский интерфейс для быстрой визуализации наиболее актуальной статистики
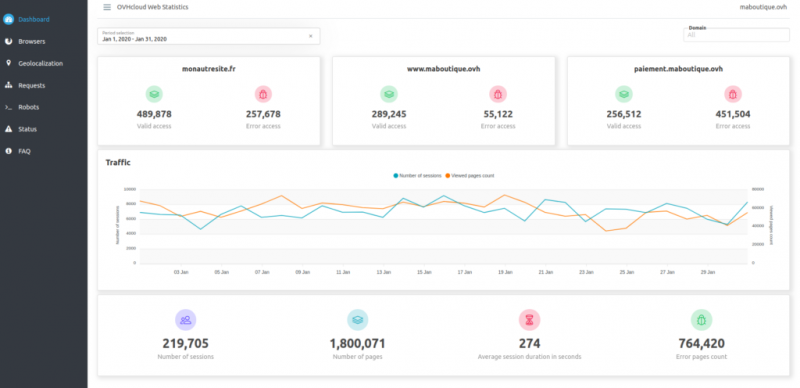
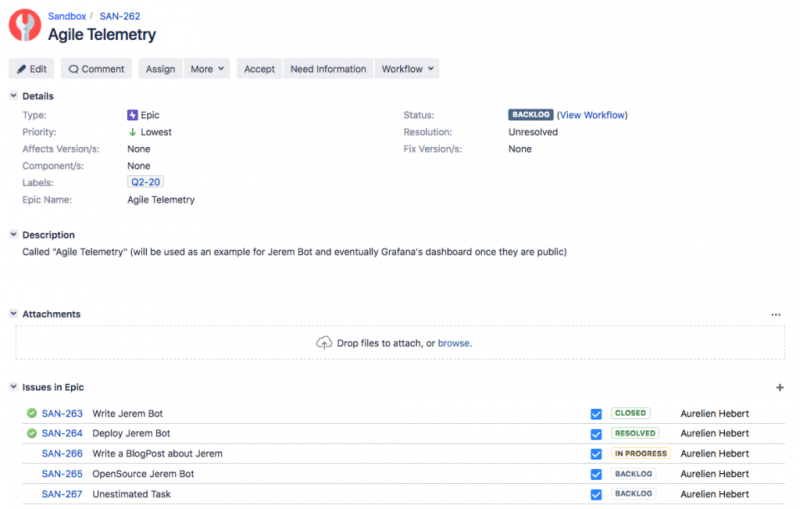
Вы можете найти несколько разделов:
Ну конечно бы! Здесь у вас есть:
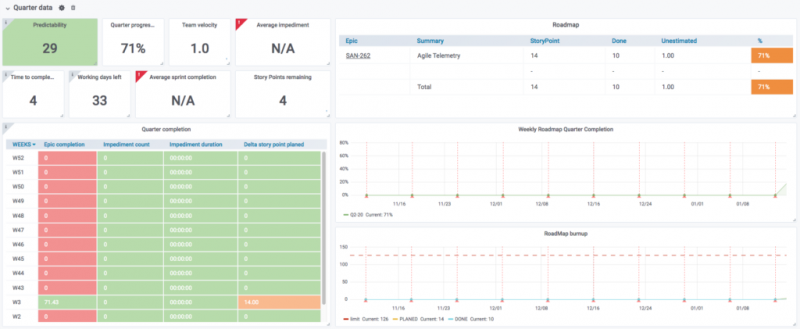
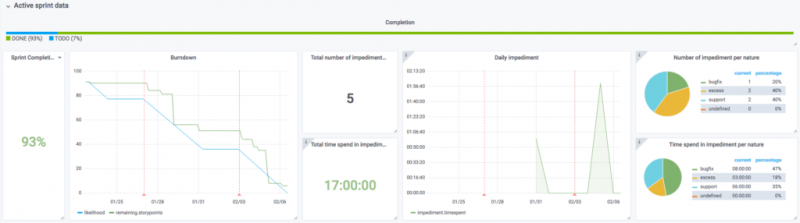
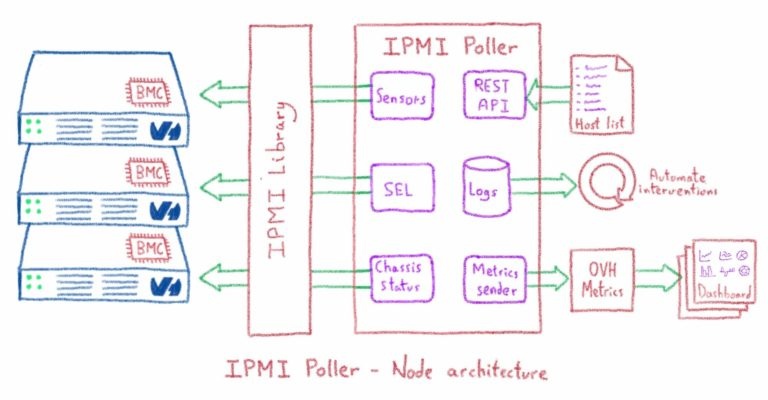
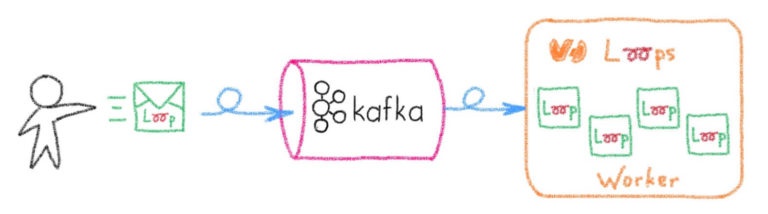
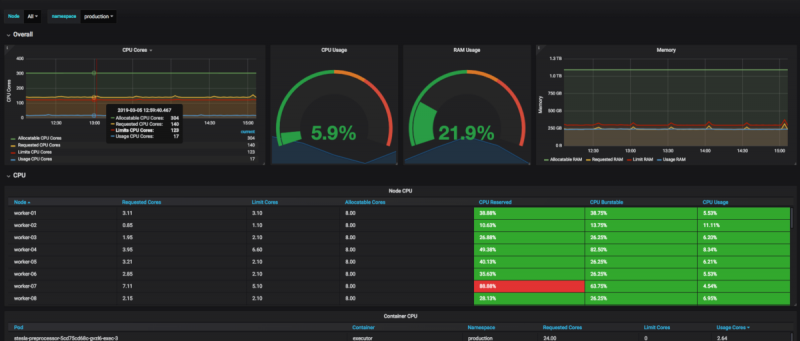
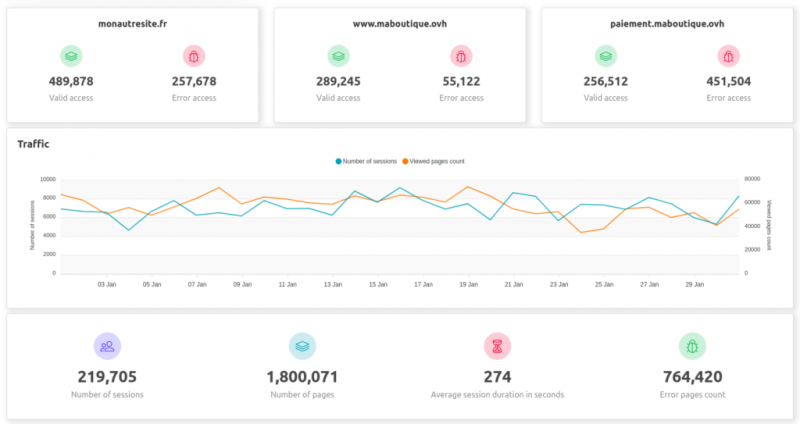
Панель управления:
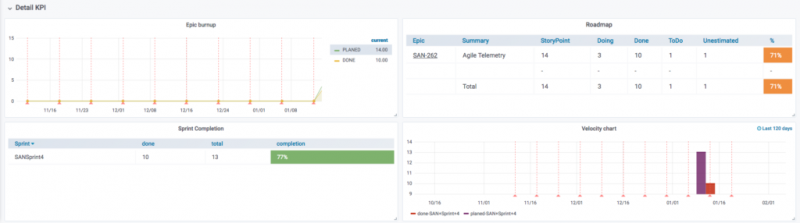
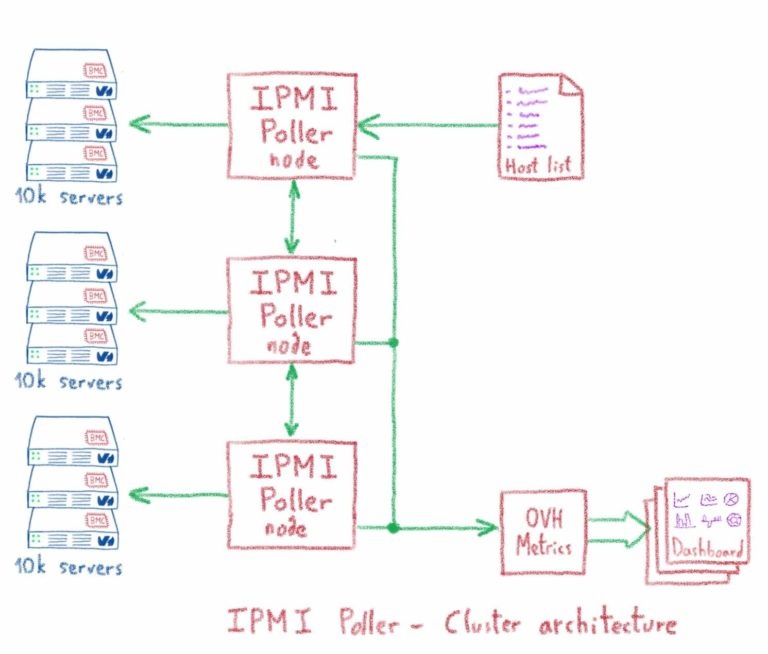
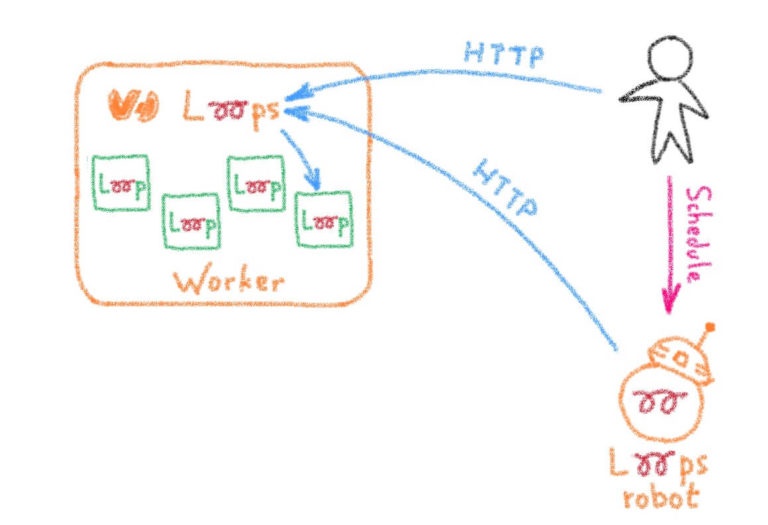
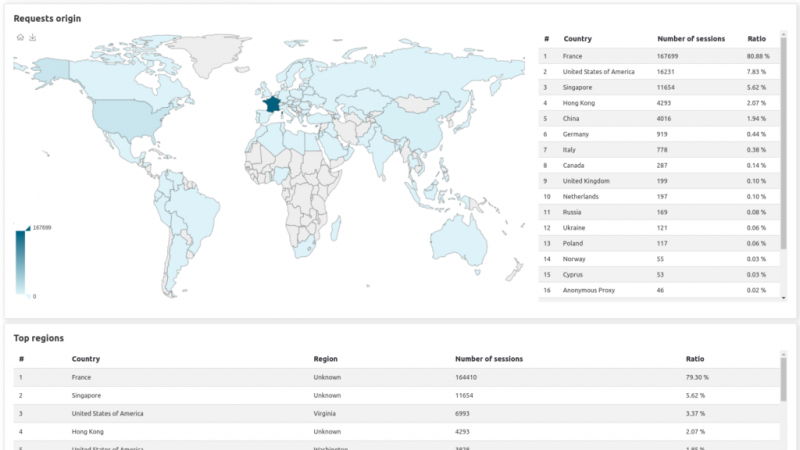
Страница геолокации:
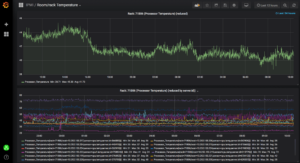
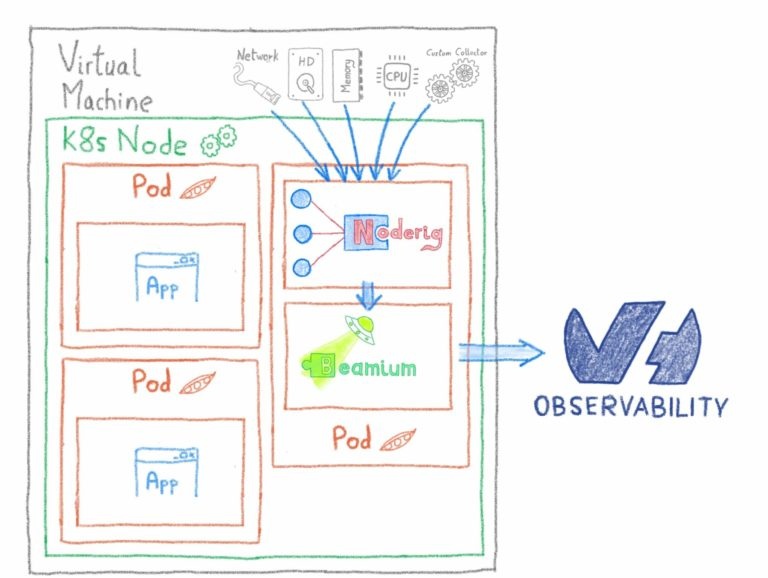
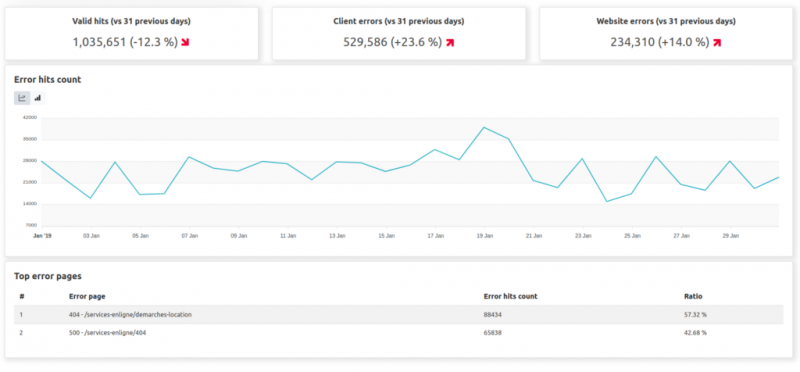
И страницы статуса:
Благодаря этому новому инструменту мы можем вычислять вашу статистику до 8 раз быстрее.
Мы также вычисляем 2,5 ТБ логов в день!
Этот пост является предварительным просмотром нашей входящей службы веб-статистики OVH. Мы вернемся к вам с дополнительными сообщениями о технических деталях по мере приближения даты выпуска!
Если это так, то эта статья для вас! Будьте готовы вступить в 2020 год с совершенно новым интерфейсом!
Немного истории
На рынке есть несколько решений, которые помогут вам анализировать посещения вашего веб-сайта.
Существуют два метода, которые помогут вам собрать эту информацию:
- Вставьте код на свой веб-сайт, чтобы отслеживать ваши посещения, и отправьте эти результаты третьей стороне, чтобы они были обработаны.
- Сохраняйте контроль над своими данными: анализируйте собственные необработанные журналы для вычисления соответствующих показателей
В 2004 году, чтобы обеспечить безопасность ваших данных, мы решили использовать локальное решение под названием Urchin… но пришло время меняться!
Почему?
- Urchin был куплен Google, и программное обеспечение больше не выпускается. Таким образом, с 2012 года он не развивался.
- Urchin основан на Flash Player. Поддержка Flash Player прекращена, и в 2020 году он будет остановлен компанией Adobe. Поддержки для него больше не будет.
- Это не лучший опыт.
- Urchin не позволяет пользователям визуализировать статистику субдоменов. (пример: app.mydomain.com)
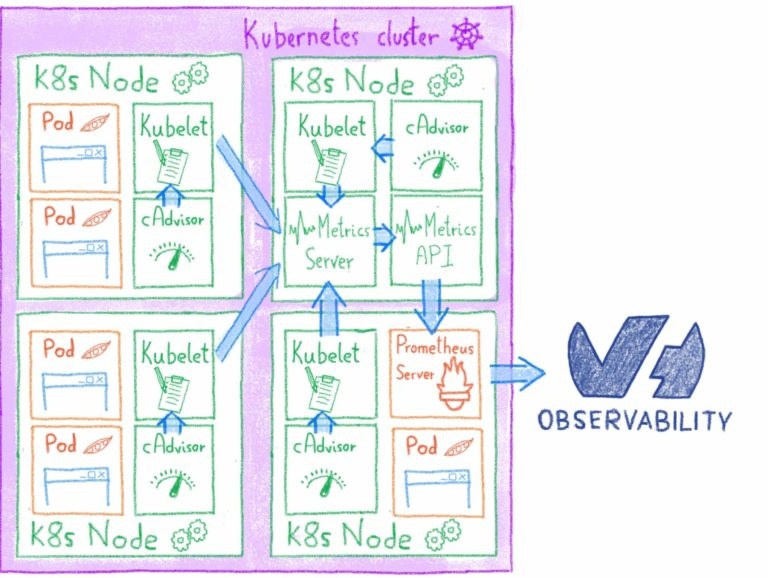
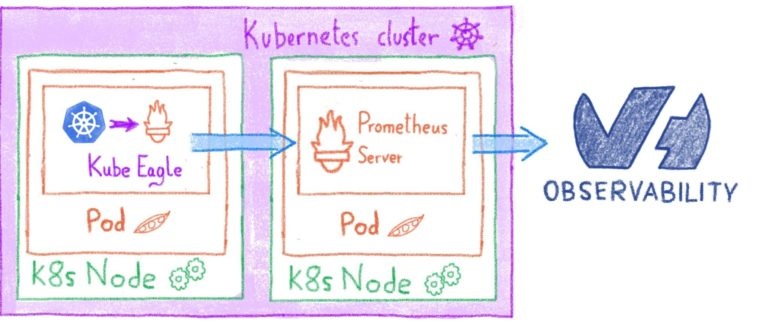
Как мы предоставляем статистику вашего сайта?
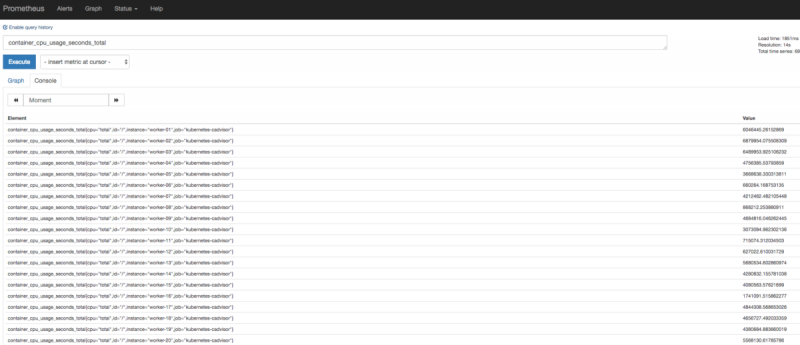
Ежедневно мы вычисляем статистику по нескольким миллионам сайтов. Это особое требование, и существует несколько решений для его удовлетворения.
Что это за потребности:
- Возможность максимально быстро вычислить статистику всех веб-сайтов.
- Сводные данные для отображения анонимных данных.
- Не встраивайте код / трекер на свой сайт
- Иметь простой в использовании интерфейс, соответствующий сегодняшним стандартам
- Дайте вам возможность видеть на уровне поддоменов вашу статистику
- Перенесите предыдущую статистику из Urchin, чтобы не потерять ее
Долгое время мы пытались избежать эффекта «придумано не здесь», потому что восстановление статистического инструмента — не наша основная работа. Поэтому мы перепробовали множество решений на рынке. Открытый исходный код или нет. Бесплатно или с лицензией. И мы не нашли решения, способного масштабировать наше количество журналов и вычислять статистику для всех веб-сайтов, которые мы размещаем!
Итак, мы решили разработать альтернативное решение и предложили его по умолчанию для всех: OVHcloud Web Statistics (или OWStats).
Так что нового?
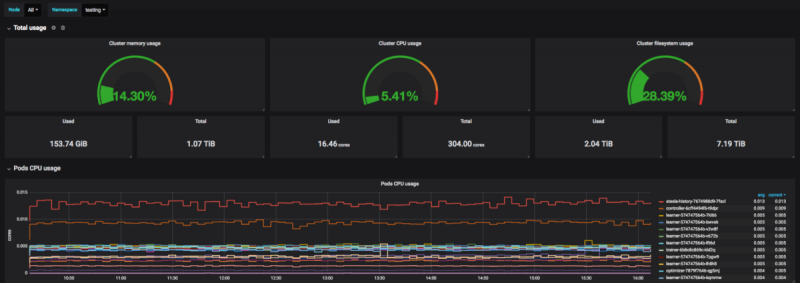
Новый пользовательский интерфейс для быстрой визуализации наиболее актуальной статистики
Вы можете найти несколько разделов:
- Панель управления : сводка действий в вашем домене с помощью панели управления.
- Браузеры : дополнительная техническая информация о различных браузерах и платформах, используемых для посещения вашего домена.
- Геолокация : какая страна / регион посещает ваш домен (данные анонимны, поэтому это только общий обзор).
- Запросы : Обзор самых просматриваемых страниц
- Роботы : Анализ ботов, посещающих ваш домен
- Статус : эволюция кода статуса и страницы с ошибками, которые следует изучить.
Было бы проще, если бы мы показали несколько картинок, не так ли?
Ну конечно бы! Здесь у вас есть:
Панель управления:
Страница геолокации:
И страницы статуса:
Некоторые цифры
Благодаря этому новому инструменту мы можем вычислять вашу статистику до 8 раз быстрее.
Мы также вычисляем 2,5 ТБ логов в день!
Хотите больше информации?
Этот пост является предварительным просмотром нашей входящей службы веб-статистики OVH. Мы вернемся к вам с дополнительными сообщениями о технических деталях по мере приближения даты выпуска!