Selfheal at Webhosting - внешняя часть
Вступление
С почти 6000000 веб-сайтов, размещенных на более чем 15000 серверах, команда OVHcloud Webhosting SRE управляет множеством предупреждений в течение рабочего дня.
Наша инфраструктура постоянно растет, но для плавного масштабирования время, затрачиваемое на решение предупреждений, не должно увеличиваться пропорционально.
Поэтому нам нужны инструменты, которые нам помогут. В нашей команде мы называем это самоисцелением.
Что такое самоисцеление ?
Selfheal относится к автоматизации решения оповещения в производственных условиях. Автоматизированный процесс может исправить известные проблемы без вмешательства администратора.
Зачем нам это нужно?
Мы должны максимально ограничить время, которое мы тратим на устранение предупреждений. У нас есть не только время для запуска и обслуживания инфраструктуры, но и для того, чтобы оставаться в курсе последних событий.
При таком количестве серверов, которыми мы управляем, небольшая проблема может представлять собой десятки предупреждений.
Нам нужно работать эффективно, автоматизируя как можно больше производственных операций.
Оборудование
Для ежедневного обслуживания миллиардов HTTP-запросов требуется много ресурсов, поэтому мы часто используем физические серверы в наших центрах обработки данных.
Даже один физический сервер требует серьезной поддержки. Требуется много времени для диагностики, планирования простоев, запроса и управления вмешательством с группами центров обработки данных или даже для переустановки операционной системы в случае неисправности диска.
Мы не можем позволить себе тратить часы на повторяющиеся задачи, если их можно автоматизировать.
Программного обеспечения
Даже если программное обеспечение кажется предсказуемым, оно все равно будет терпеть неудачу. Это верно даже при управлении базовой инфраструктурой, содержащей миллионы строк неизвестного кода, предоставленного нашим клиентом.
Хотя мы стараемся иметь стабильный программный стек, мы не можем предсказать все поведение. Многие проблемы с программным обеспечением можно решить с помощью перезапуска или быстрого исправления, а многие из этих операций также можно автоматизировать.
Мы должны как можно меньше предупреждать дежурных администраторов, только когда это абсолютно необходимо.
Идея состоит в том, чтобы регистрировать каждое действие, выполненное самовосстановлением, для выявления ошибок или шаблонов ошибок, а затем работать над долгосрочными исправлениями.
Selfheal на веб — хостинг
В Webhosting мы разделяем selfheal на две части:
- Внешнее самовосстановление, которое обрабатывает проблемы с оборудованием или все, что не может быть решено самим хостом.
- Внутреннее самовосстановление, предназначенное для решения программных проблем в данной системе.
В этой статье мы обсудим внешнюю часть.
Внешнее самоисцеление
Контекст:
Как мы уже говорили ранее, внешняя часть нашего selfheal в основном предназначена для решения аппаратных проблем, которые не могут быть решены одним сервером.
Для этого мы создали небольшое приложение-микросервис, которое отслеживает и отслеживает события.
Мы могли выбрать существующий инструмент (например, StackStorm), но мы этого не сделали. Вот почему:
- Создание микросервисов в OVH действительно просто и быстро.
- Структурированные, подробные и простые журналы с уникальным идентификатором uuid для отслеживания каждой задачи самовосстановления в нашей внутренней системе журналов (что позволяет нам легко строить графики).
- Простая интеграция с нашими существующими инструментами и экосистемой
- Быстрое и простое развертывание во всех наших регионах
- Простой CI / CD (модульное тестирование и т. Д.)
- Пользовательские уведомления, например чат-бот
- Интеллект и история
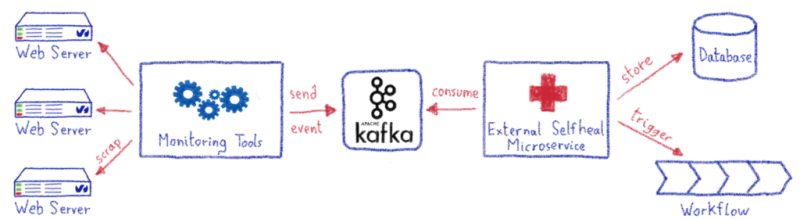
Как это устроено
Все начинается с нашего мониторинга, который отбрасывает пробы серверов и отправляет все предупреждения в теме Kafka.
Приложение использует события Kafka, а затем мгновенно реагирует на правильный рабочий процесс, в зависимости от проблемы.
Приложение отреагирует соответствующим рабочим процессом в зависимости от полученного предупреждения. Он делает это, выполняя правильный вызов API для наших различных служб и инструментов.
Все выполненные действия сохраняются. Это избавляет от необходимости выполнять одно и то же исправление несколько раз на данном сервере и выявлять сложные проблемы.
Конкретный пример замены неисправного диска
Одним из самых трудоемких предупреждений, которые нам пришлось решить, была замена неисправного жесткого диска, обнаруженного при проверке SMART.
Поскольку у нас нет состояния, многие наши серверы используют один диск без настройки рейда. Это также означает замену диска для переустановки хоста; но, надеюсь, это можно сделать с помощью одного вызова API.
Чтобы управлять этим предупреждением, администратор должен был выполнить следующие действия:
- Поставьте сервер на обслуживание, чтобы истощить запросы клиентов
- Создайте запрос центра обработки данных на замену жесткого диска
- Переустановите сервер
Весь этот процесс может занять до 3 часов и его сложно выполнить вручную (управление несколькими проблемами одновременно).
Первое, что мы сделали, — автоматизировали проверку зондом.
Затем мы решили автоматизировать все это с помощью простого рабочего процесса в нашем приложении с самовосстановлением, а затем организовать вызов API.
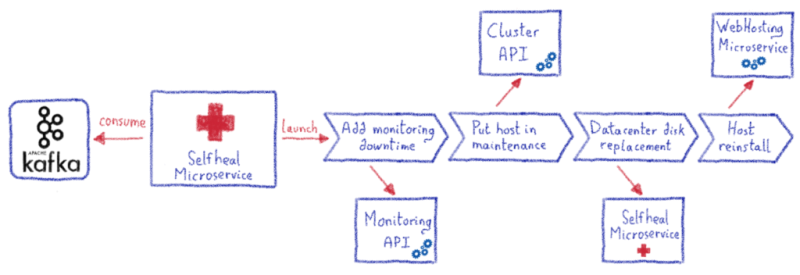
Благодаря этому процессу мы можем заменять диски каждый день без каких-либо ручных действий со стороны администратора.
Заключить
В прошлом месяце наш внешний инструмент самовосстановления запросил более 70 вмешательств в центры обработки данных для команд центров обработки данных, что представляет собой большую экономию времени.
Мы победили по реактивности. Больше нет задержки между обнаружением предупреждения и его обработкой.
Оповещения обрабатываются мгновенно при обнаружении системой мониторинга. Это помогает нам вести чистый список невыполненных работ по мониторингу и избегать «пакетных» решений по оповещениям, которые были сложными как для нас, так и для DC.
Теперь мы просто обрабатываем предупреждения, которые невозможно решить с помощью автоматизации, и сосредотачиваемся на критических случаях, когда взаимодействие администратора является ценным и необходимым.
0 комментариев