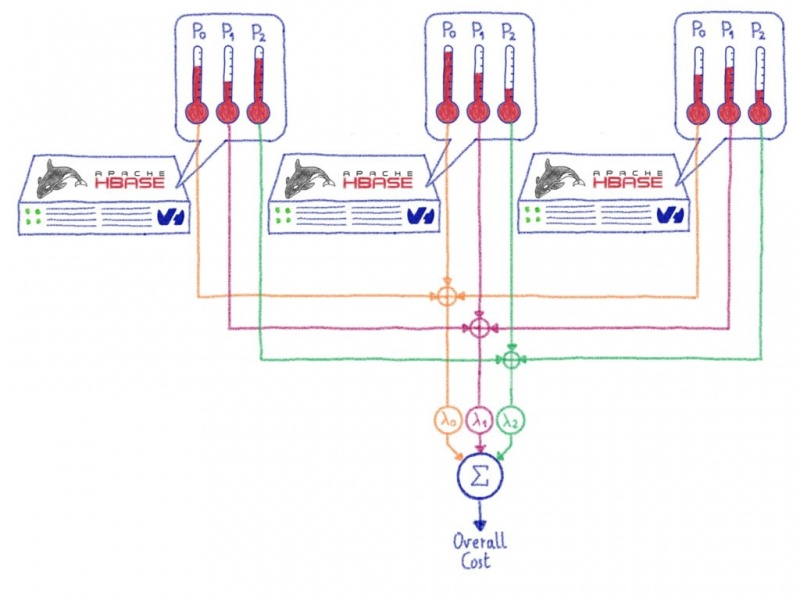
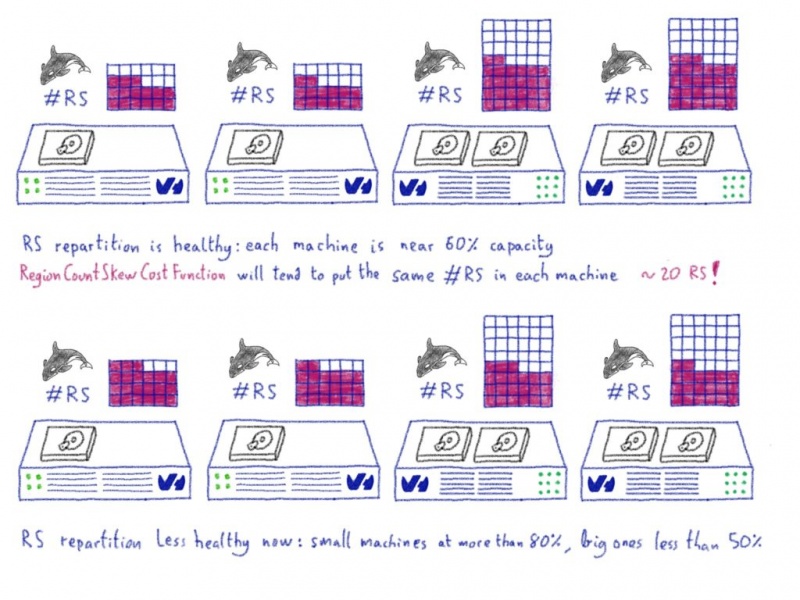
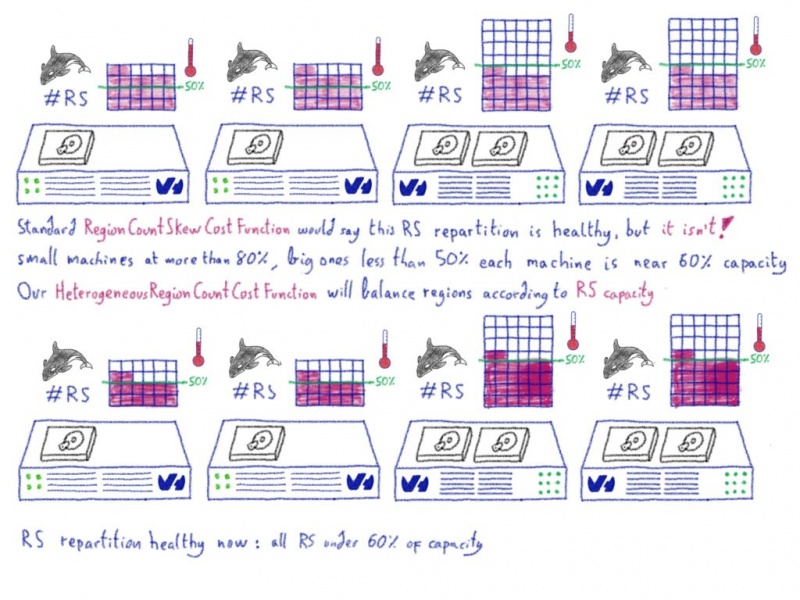
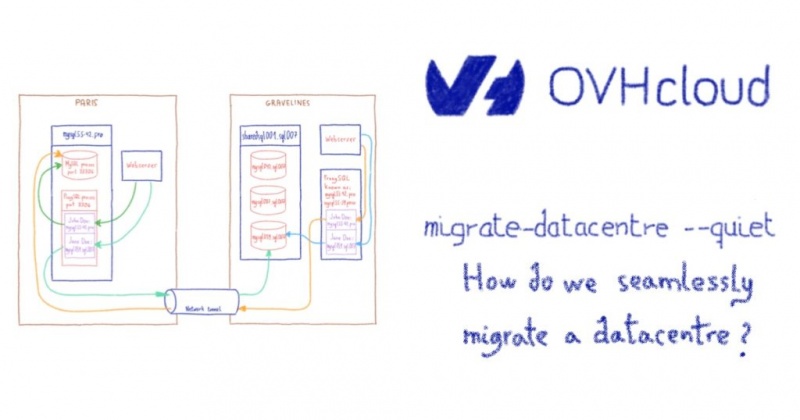
Еще один день в жизни ProxySQL: делиться заботой
Этот пост — еще одна часть нашего списка коротких постов, в которых описываются конкретные случаи, с которыми сталкивался OVHcloud как при подготовке к миграции, так и во время нее. Здесь мы рассказываем историю о том, как иногда небольшое неожиданное поведение может привести к исправлению ошибки в программном обеспечении, используемом миллионами людей по всему миру.
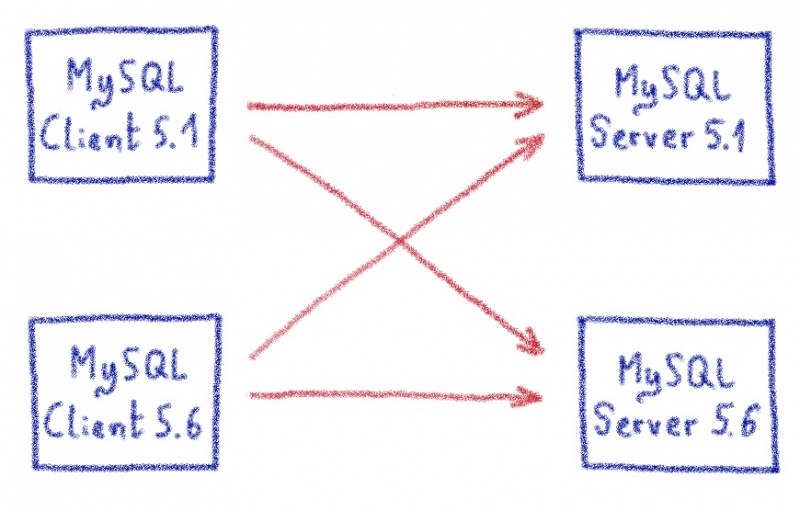
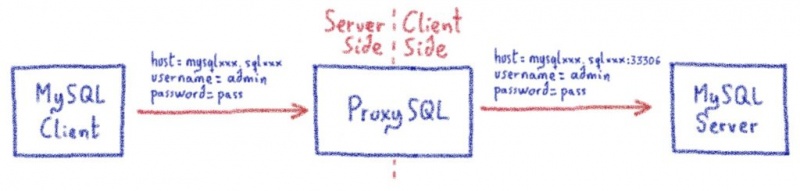
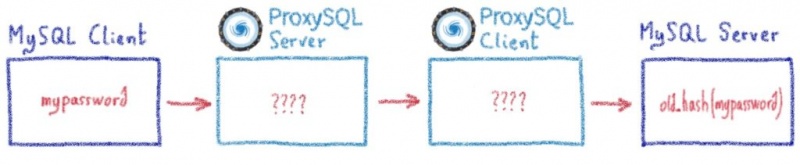
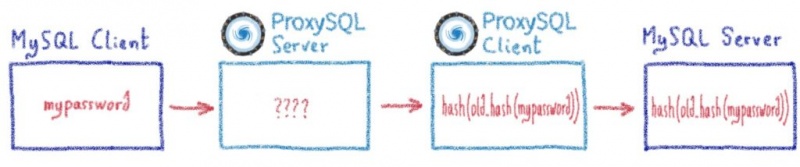
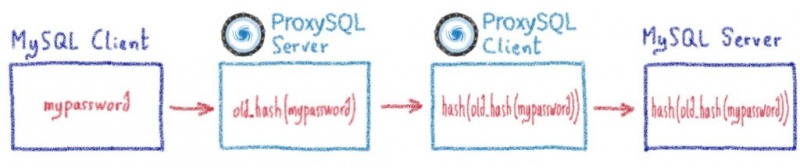
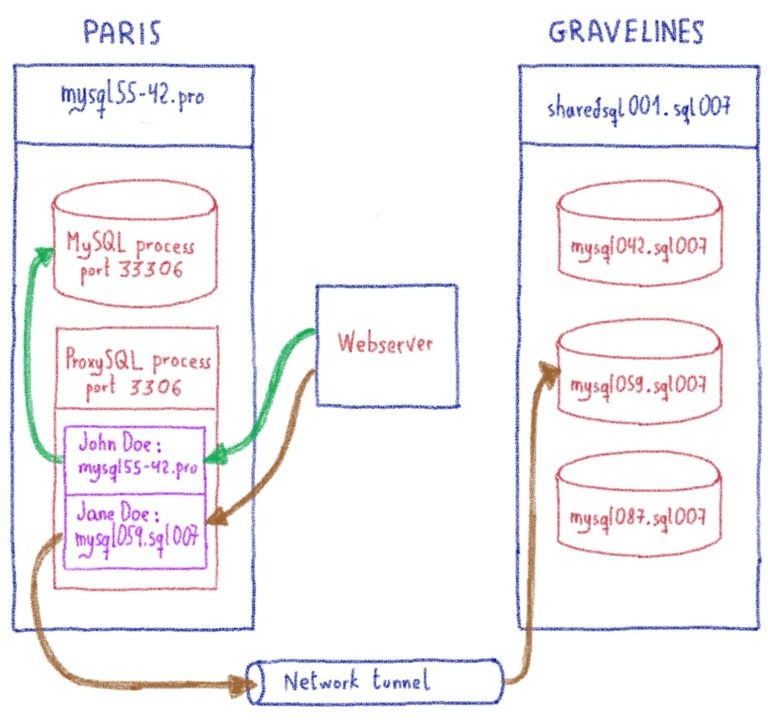
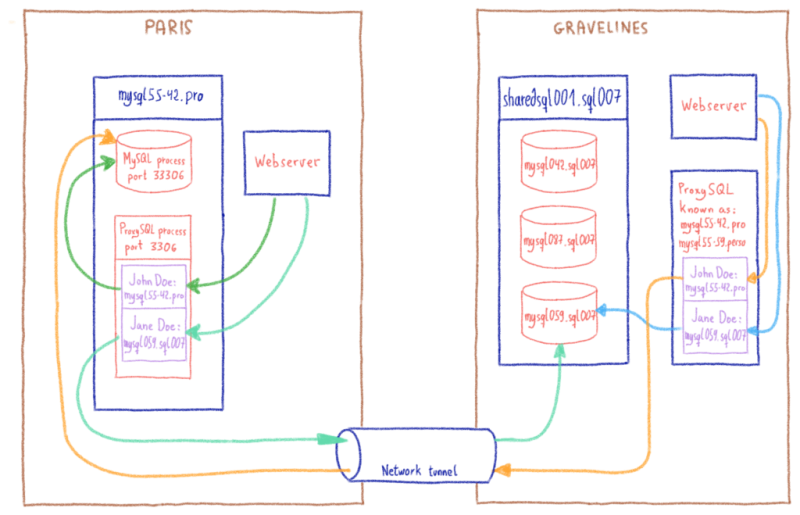
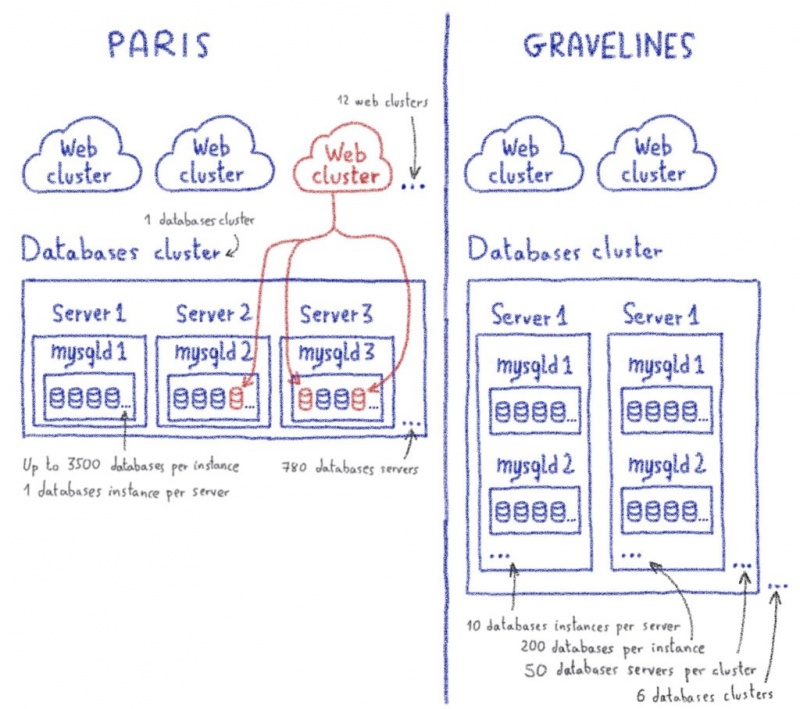
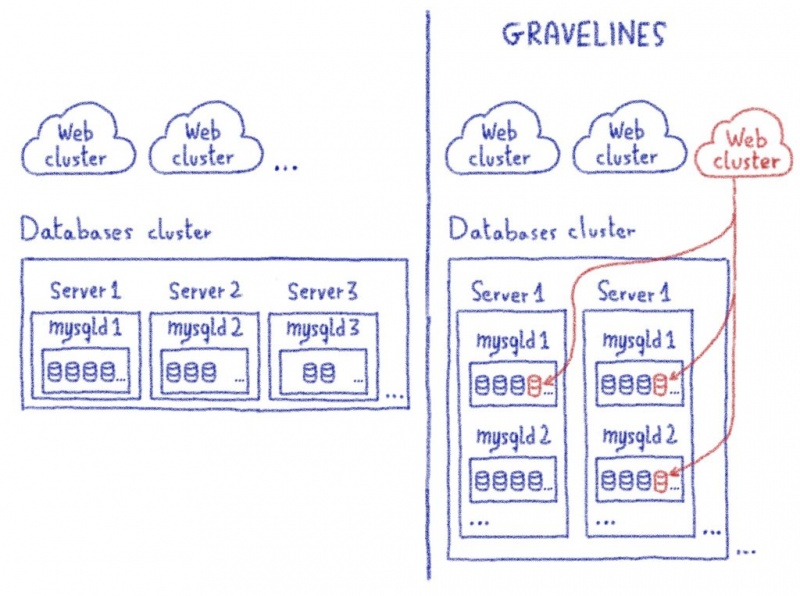
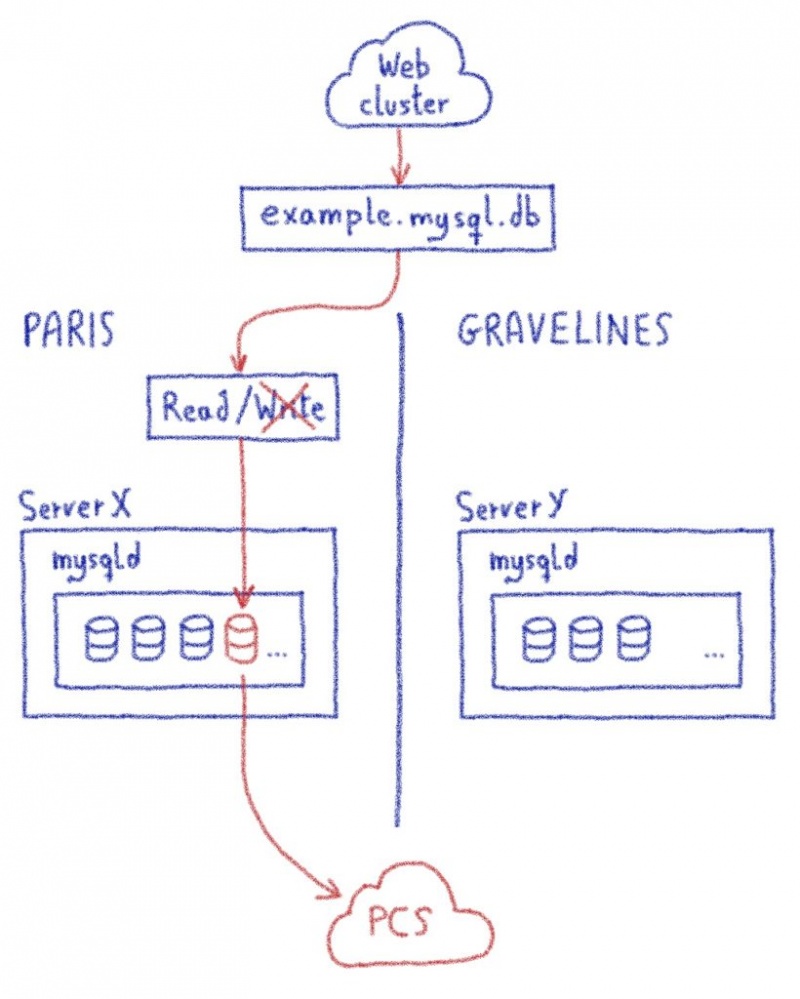
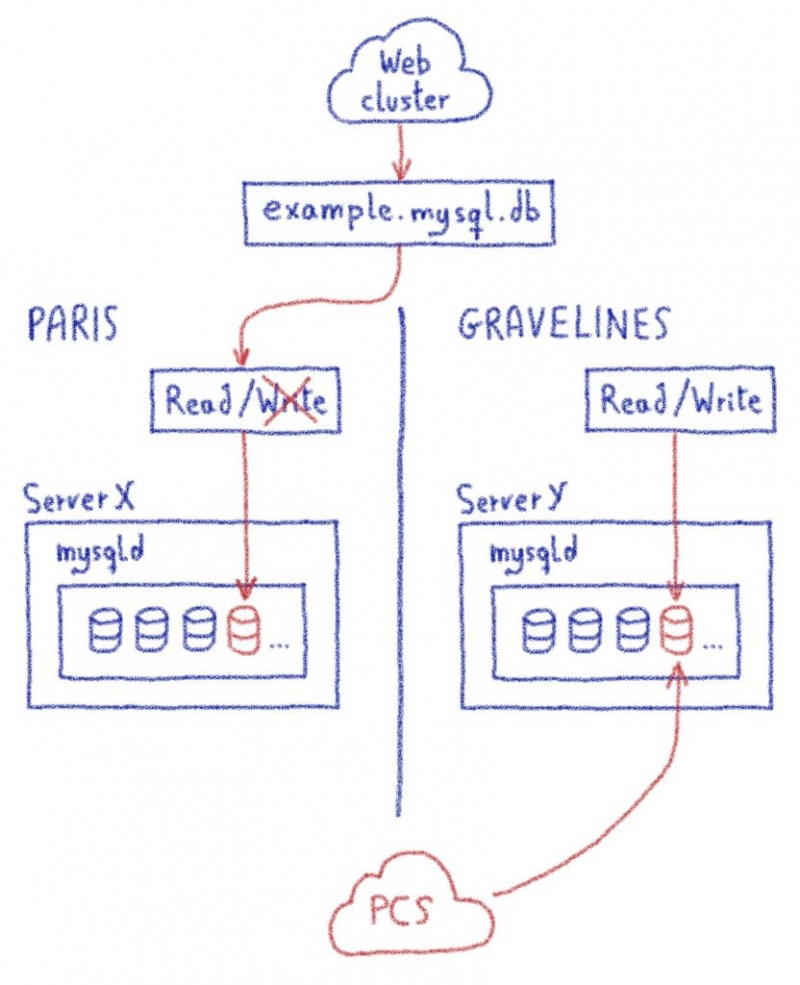
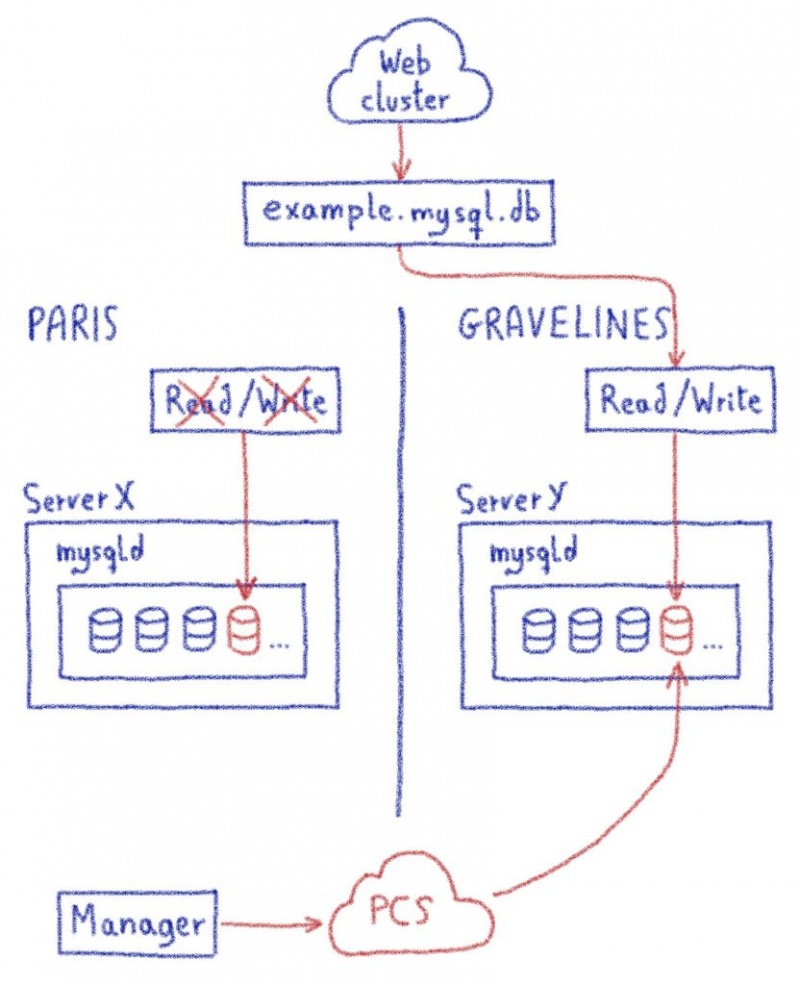
В этом посте я объяснил, как нам пришлось продвинуть proxySQL за его пределы.
Жюльен объяснил здесь, насколько сложно перехватить часть программы и заставить ее работать для очень специфического случая использования. Один настолько специфический, что мы просто не могли продвинуть его вверх по течению, поскольку мы нарушали некоторые предположения в базовом коде (что-то вроде «смотри, мы не используем это, может быть, мы можем отклонить его, чтобы он соответствовал нашему использованию»).
Но иногда, копаясь все глубже и глубже в строках кода, расширяя границы программ с открытым исходным кодом все дальше и дальше, мы обнаруживаем ошибки.
Вот два реальных случая, когда у нас было неожиданное поведение ProxySQL, в результате чего появился патч для MariaDB / MySQL.
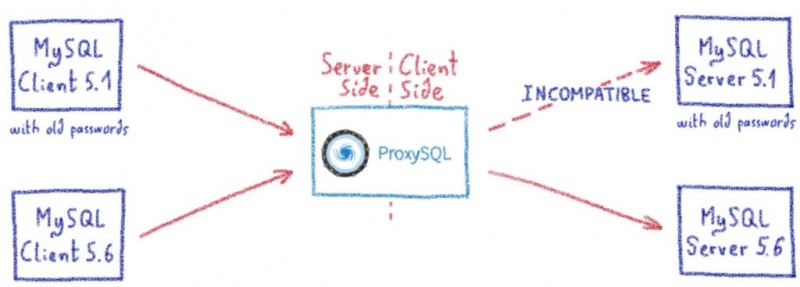
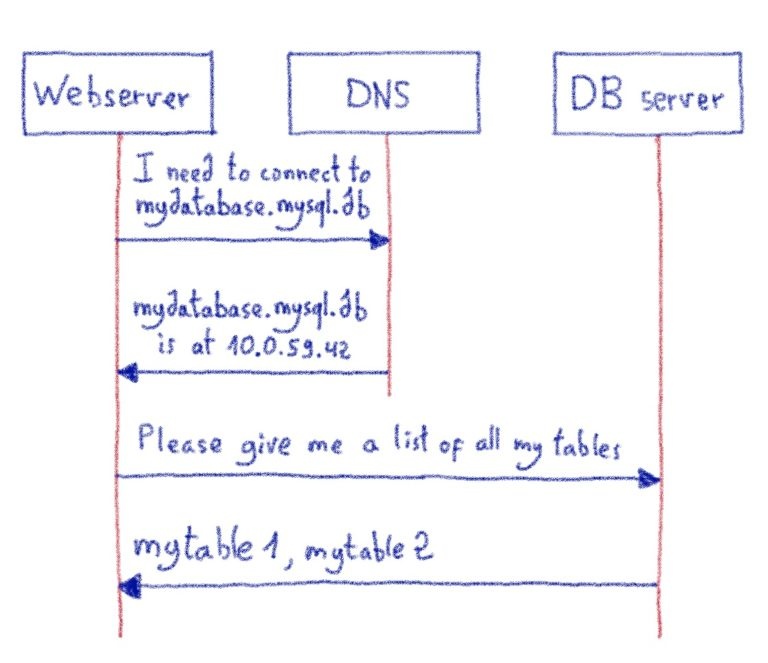
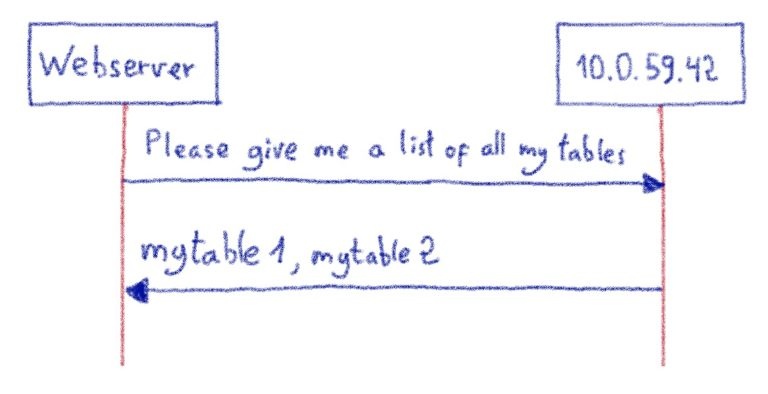
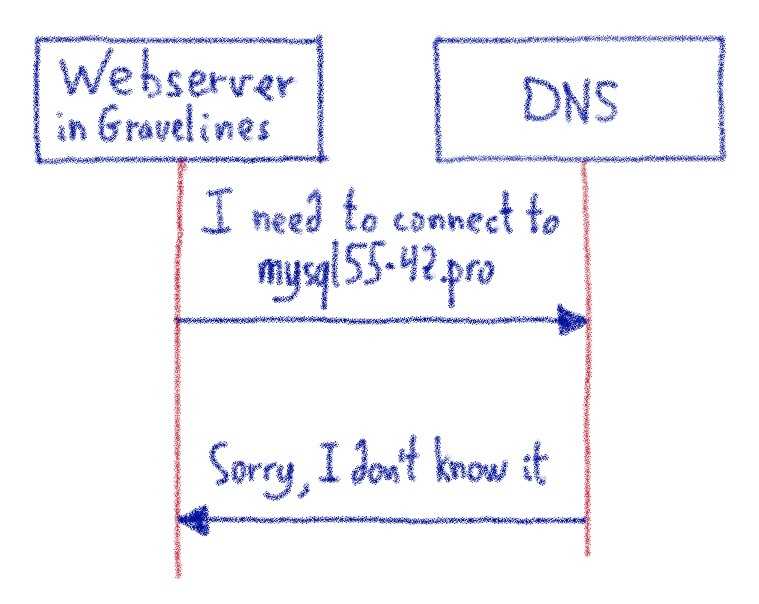
Когда мы впервые начали использовать ProxySQL, у нас было неожиданное поведение. ProxySQL раньше зависал. Ни предупреждения, ни предвестника. Зависание означает, что ProxySQL не может обрабатывать ваши запросы, в результате чего ваши веб-сайты становятся недоступными.
Системные администраторы знают, что в случае сомнений проверяйте журналы. Вот что мы сделали и заметили вот это:
Это явно ошибка, возвращенная сервером MySQL. Поскольку эта строка журнала была создана на ProxySQL, это означает, что ошибка произошла между нашим ProxySQL и сервером MySQL.
Жюльен много работал — он прочитал тонны журналов, отследил множество PID и отследил проблему вплоть до ИСПОЛЬЗОВАНИЯ триггерного случая, выполнив эту команду:
Сопоставление — это своего рода набор правил для сравнения строк. Он может определять, например, при сортировке по алфавиту, если Aидет раньше a, éследует ли рассматривать как eили нет, или где œдолжно быть в алфавите.
Вы можете узнать больше об этом в Базе знаний MariaDB.
Отправив сообщение об обнаруженной нами проблеме в системе отслеживания ошибок ProxySQL и предложив исправление, автор ProxySQL взглянул и подтвердил ошибку.
При написании ProxySQL Рене Канна делал то же, что и все разработчики, — следовал документации коннектора MariaDB. И ошибка была отсюда:
(https://bugs.mysql.com/bug.php?172id=93692)
Итак, из-за зависания нашей инфраструктуры мы сообщили об ошибке создателю проекта, который затем отследил ее до ошибки в коннекторе MariaDB, проследил ее до родительского MySQL и исправил в восходящем направлении. Ошибка была закрыта в начале 2020 года.
Тем временем мы работали с г-ном Канна, чтобы найти обходной путь (в основном, заставляя имя сортировки указывать в коде ProxySQL).
Во время написания этой статьи я вспомнил еще один забавный баг. Я решил проверить статус этой ошибки и заметил, что мы никогда о ней не сообщали. Моя ошибка исправлена.
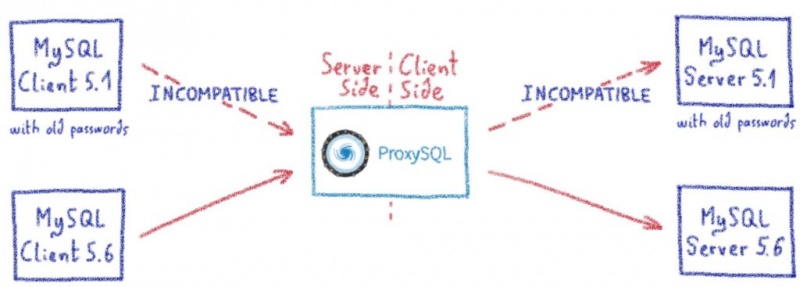
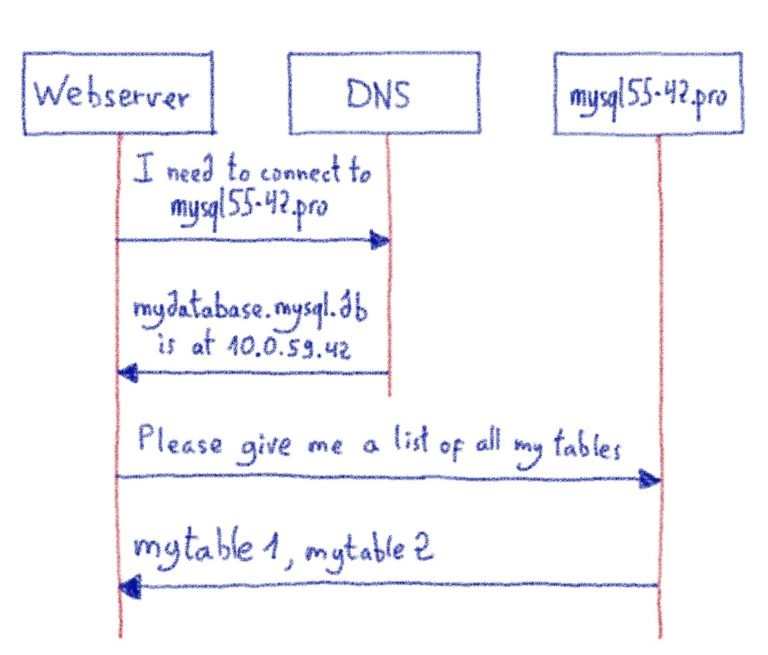
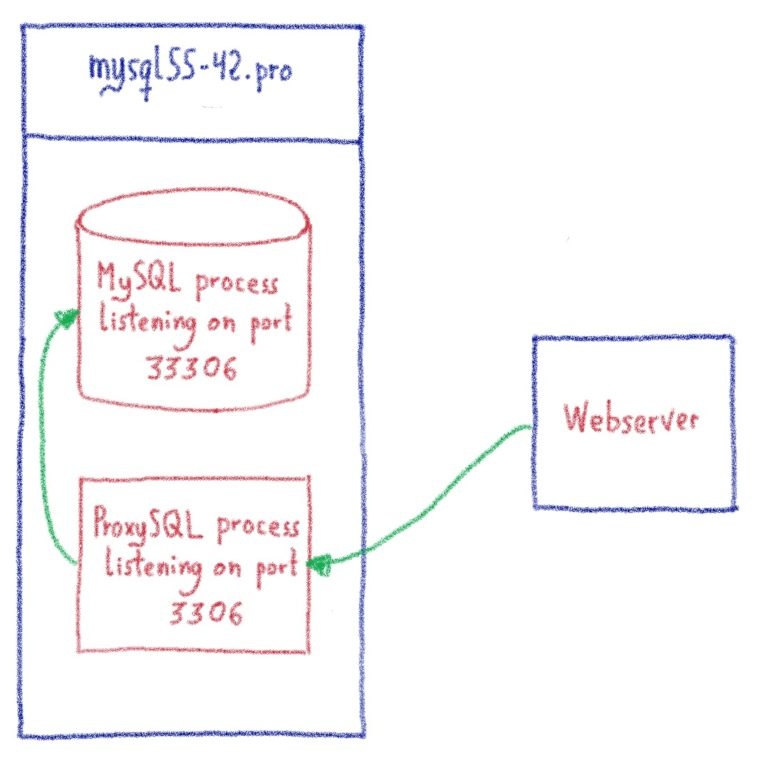
При использовании некоторых реальных, но экзотических кодировок на ProxySQL (нам также нравятся сложные сценарии, поэтому мы стараемся тестировать их как можно больше), у нас была ошибка ProxySQL, в которой говорилось, что мы использовали неправильную кодировку.
Конечно, в первую очередь мы проверили, что мы используем настоящую и допустимую кодировку и соответствующее сопоставление. Мы дважды и трижды проверили, что нам разрешено использовать dec8_swedish_ci.
Мы решили взглянуть на исходный код коннектора.
Если вам интересно, вы можете взглянуть на более старые версии кода libmariadb / my_charset.c, начиная со строки 541. Вы заметите, что dec8_swedish_ci нигде не найти. Но если вы присмотритесь, вы заметите dec8_swedisch_ci. Дорогие друзья из Швеции, опечатка была сделана не только вами.
При устранении проблемы с экзотическими кодировками мы применили специальный патч к нашей собственной сборке ProxySQL. Сгоряча, мы отложили сообщение об ошибке.
Мы разделили репозиторий GitHub mariadb-corporation / mariadb-connector-c , исправили несколько опечаток и предложили запрос на перенос, который затем был объединен в середине февраля.
Все склонны к опечаткам и ошибкам. С некоторыми мы столкнулись, они были исправлены и портированы для всех.
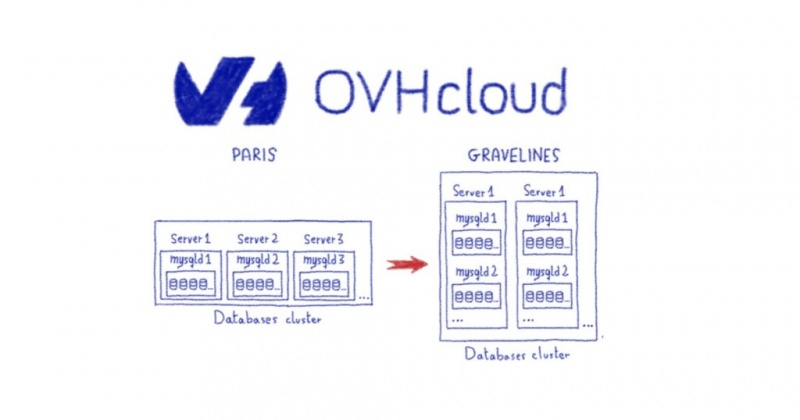
Как ведущий поставщик веб-хостинга в Европе, мы сталкиваемся с законом действительно больших чисел ( en.wikipedia.org/wiki/Law_of_truly_large_numbers ). TL; DR: произойдет каждое событие с ненулевой вероятностью.
У нас размещено более 1,3 миллиона веб-сайтов. Предположим, что 0,0001% наших клиентов могут вызвать одну конкретную ошибку — у нас есть по крайней мере 1 клиент, который ее вызовет. Вопрос не в том, если, а в том, когда нам придется с этим бороться и как это сделать.
Хотите знать, как мы заметили, что попали в Закон действительно больших чисел? Следите за обновлениями, ведь мы скоро напишем об этом.
OVHCloud любит открытый исходный код и любит делиться. Это не первый раз, когда мы вносим свой вклад в мир открытого исходного кода, и определенно не последний.
В этом посте я объяснил, как нам пришлось продвинуть proxySQL за его пределы.
Жюльен объяснил здесь, насколько сложно перехватить часть программы и заставить ее работать для очень специфического случая использования. Один настолько специфический, что мы просто не могли продвинуть его вверх по течению, поскольку мы нарушали некоторые предположения в базовом коде (что-то вроде «смотри, мы не используем это, может быть, мы можем отклонить его, чтобы он соответствовал нашему использованию»).
Но иногда, копаясь все глубже и глубже в строках кода, расширяя границы программ с открытым исходным кодом все дальше и дальше, мы обнаруживаем ошибки.
Вот два реальных случая, когда у нас было неожиданное поведение ProxySQL, в результате чего появился патч для MariaDB / MySQL.
1. Важность цитирования
Неожиданное поведение
Когда мы впервые начали использовать ProxySQL, у нас было неожиданное поведение. ProxySQL раньше зависал. Ни предупреждения, ни предвестника. Зависание означает, что ProxySQL не может обрабатывать ваши запросы, в результате чего ваши веб-сайты становятся недоступными.
Копать
Системные администраторы знают, что в случае сомнений проверяйте журналы. Вот что мы сделали и заметили вот это:
[ОШИБКА] Обнаружено разорванное соединение во время SET NAMES на 192.168.59.272, 3306: 2019, Невозможно инициализировать набор символов (null) (путь: compiled_in)ОШИБКА 1064 (42000): у вас есть ошибка в синтаксисе SQL; проверьте руководство, которое соответствует вашей версии сервера MySQL, чтобы найти правильный синтаксис для использования рядом с «двоичным» в строке 1Это явно ошибка, возвращенная сервером MySQL. Поскольку эта строка журнала была создана на ProxySQL, это означает, что ошибка произошла между нашим ProxySQL и сервером MySQL.
В поисках золота
Жюльен много работал — он прочитал тонны журналов, отследил множество PID и отследил проблему вплоть до ИСПОЛЬЗОВАНИЯ триггерного случая, выполнив эту команду:
set names binary COLLATE binary;Сопоставление — это своего рода набор правил для сравнения строк. Он может определять, например, при сортировке по алфавиту, если Aидет раньше a, éследует ли рассматривать как eили нет, или где œдолжно быть в алфавите.
Вы можете узнать больше об этом в Базе знаний MariaDB.
Исправление
Отправив сообщение об обнаруженной нами проблеме в системе отслеживания ошибок ProxySQL и предложив исправление, автор ProxySQL взглянул и подтвердил ошибку.
При написании ProxySQL Рене Канна делал то же, что и все разработчики, — следовал документации коннектора MariaDB. И ошибка была отсюда:
According to the documentation on SET NAMES syntax (https://dev.mysql.com/doc/refman/5.7/en/set-names.html) :
charset_name and collation_name may be quoted or unquoted
This doesn't seem true for "SET NAMES binary COLLATE binary" , that requires the collation name to be quoted.(https://bugs.mysql.com/bug.php?172id=93692)
Эффект бабочки
Итак, из-за зависания нашей инфраструктуры мы сообщили об ошибке создателю проекта, который затем отследил ее до ошибки в коннекторе MariaDB, проследил ее до родительского MySQL и исправил в восходящем направлении. Ошибка была закрыта в начале 2020 года.
Тем временем мы работали с г-ном Канна, чтобы найти обходной путь (в основном, заставляя имя сортировки указывать в коде ProxySQL).
2. Когда провода перекрещиваются
Во время написания этой статьи я вспомнил еще один забавный баг. Я решил проверить статус этой ошибки и заметил, что мы никогда о ней не сообщали. Моя ошибка исправлена.
Неожиданное поведение
При использовании некоторых реальных, но экзотических кодировок на ProxySQL (нам также нравятся сложные сценарии, поэтому мы стараемся тестировать их как можно больше), у нас была ошибка ProxySQL, в которой говорилось, что мы использовали неправильную кодировку.
MySQL_Session.cpp:2964:handler(): [WARNING] Error during query on (42,192.168.59.272,3306): 1267, Illegal mix of collations (utf8_general_ci,IMPLICIT) and (dec8_swedish_ci,COERCIBLE) for operation '='Копать
Конечно, в первую очередь мы проверили, что мы используем настоящую и допустимую кодировку и соответствующее сопоставление. Мы дважды и трижды проверили, что нам разрешено использовать dec8_swedish_ci.
Мы решили взглянуть на исходный код коннектора.
В поисках золота
Если вам интересно, вы можете взглянуть на более старые версии кода libmariadb / my_charset.c, начиная со строки 541. Вы заметите, что dec8_swedish_ci нигде не найти. Но если вы присмотритесь, вы заметите dec8_swedisch_ci. Дорогие друзья из Швеции, опечатка была сделана не только вами.
Исправление
При устранении проблемы с экзотическими кодировками мы применили специальный патч к нашей собственной сборке ProxySQL. Сгоряча, мы отложили сообщение об ошибке.
Мы разделили репозиторий GitHub mariadb-corporation / mariadb-connector-c , исправили несколько опечаток и предложили запрос на перенос, который затем был объединен в середине февраля.
Эффект бабочки
Все склонны к опечаткам и ошибкам. С некоторыми мы столкнулись, они были исправлены и портированы для всех.
Вывод
Как ведущий поставщик веб-хостинга в Европе, мы сталкиваемся с законом действительно больших чисел ( en.wikipedia.org/wiki/Law_of_truly_large_numbers ). TL; DR: произойдет каждое событие с ненулевой вероятностью.
У нас размещено более 1,3 миллиона веб-сайтов. Предположим, что 0,0001% наших клиентов могут вызвать одну конкретную ошибку — у нас есть по крайней мере 1 клиент, который ее вызовет. Вопрос не в том, если, а в том, когда нам придется с этим бороться и как это сделать.
Хотите знать, как мы заметили, что попали в Закон действительно больших чисел? Следите за обновлениями, ведь мы скоро напишем об этом.
Поделиться заботой
OVHCloud любит открытый исходный код и любит делиться. Это не первый раз, когда мы вносим свой вклад в мир открытого исходного кода, и определенно не последний.