Обработка предупреждений OVH с помощью Apache Flink
OVH в значительной степени полагается на метрики для эффективного мониторинга всего своего стека. Независимо от того, являются ли они низкоуровневыми или ориентированными на бизнес , они позволяют командам получить представление о том, как наши службы работают на повседневной основе. Необходимость хранить миллионы точек данных в секунду привела к необходимости создать специальную команду для создания продукта, способного справиться с этой нагрузкой: Metrics Data Platform . Опираясь на Apache Hbase , Apache Kafka и Warp 10 , нам удалось создать полностью распределенную платформу, которая обрабатывает все наши показатели… и ваши!
После создания платформы для работы со всеми этими метриками нашей следующей задачей было создать одну из самых необходимых функций для метрик: оповещение.

OMNI наше кодовое название полностью распределенной , как-код , предупреждая систему , которую мы разработали на вершине Метрики. Он разделен на компоненты:
Исполнитель запроса помещает результаты запроса в Kafka, готовые к обработке! Теперь нам нужно выполнить все задачи, которые выполняет система оповещения:
Чтобы справиться с этим, мы посмотрели на проекты с открытым исходным кодом, такие как Prometheus AlertManager, LinkedIn Iris, и обнаружили скрытую правду:
Мы приняли это и решили использовать Apache Flink для создания Beacon . В следующем разделе мы собираемся описать архитектуру Beacon, а также то, как мы ее построили и эксплуатировали.
Если вам нужна дополнительная информация об Apache Flink, мы предлагаем прочитать вводную статью на официальном сайте: Что такое Apache Flink?
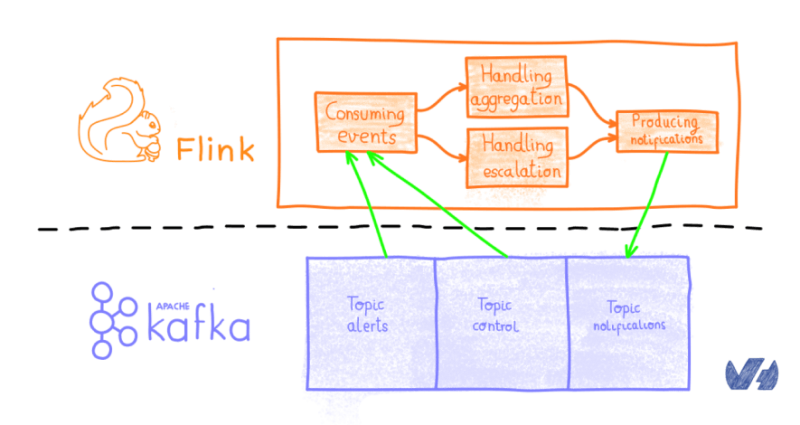
По сути, Beacon читает события от Кафки . Все представлено в виде сообщения , от предупреждений до правил агрегирования, отложенных заказов и так далее. Трубопровод разделен на две ветви:
Тогда все объединяется , чтобы произвести на уведомление , что собирается быть вперед к нужному человеку. Уведомляющее сообщение помещается в Kafka, которое будет использоваться другим компонентом, называемым beacon-notifier.
Если вы новичок в потоковой архитектуре, я рекомендую прочитать модель программирования потока данных из официальной документации Flink.
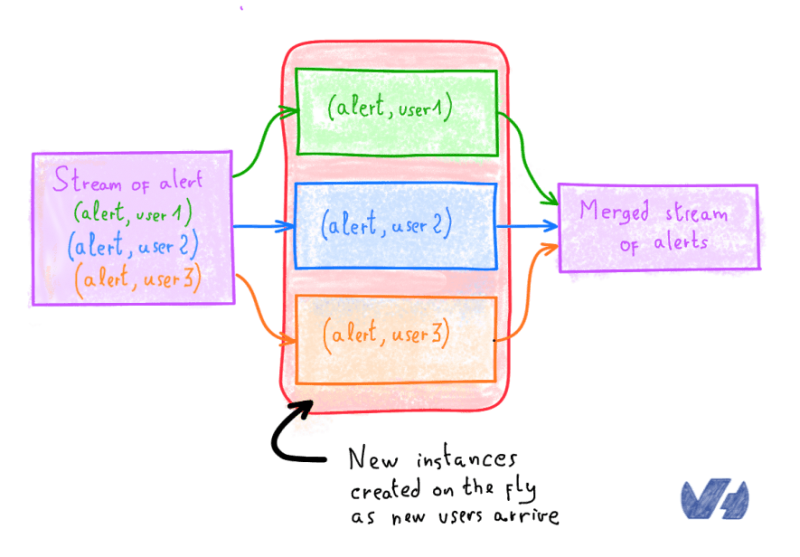
Все объединяется в поток данных, разделяется (с ключом в Flink API) пользователями. Вот пример:
Каждый из этого класса содержит менее 120 строк кода, потому что Flink справляется со всеми трудностями . Большая часть конвейера состоит только из классических преобразований, таких как Map, FlatMap, Reduce , включая их версии Rich и Keyed . У нас есть несколько функций процессов , которые очень удобны для разработки, например, таймера эскалации.
Поскольку количество классов росло, нам нужно было протестировать наш конвейер. Поскольку он подключен только к Kafka, мы обернули потребителя и производителя, чтобы создать то, что мы называем сценарием: серию интеграционных тестов, запускающих разные сценарии.
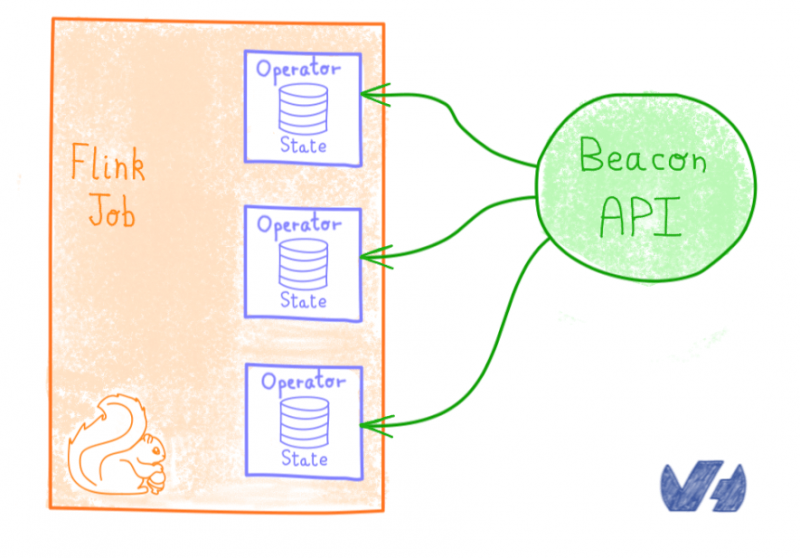
Убийственная особенность Apache Flink — это возможность запрашивать внутреннее состояниеоператора . Даже если это бета-функция, она позволяет нам узнать текущее состояние различных частей работы:
Благодаря этому мы легко разработали API для состояния запроса, который поддерживает наше представление предупреждений в Metrics Studio, наше кодовое имя для веб-интерфейса платформы данных метрик.
Мы развернули последнюю версию Flink ( 1.7.1 на момент написания) непосредственно на голых металлических серверах с выделенным кластером Zookeeper с использованием Ansible. Работа с Flink стала для нас действительно приятным сюрпризом, с понятной документацией и настройкой , а также впечатляющей устойчивостью . Мы можем перезагрузить весь кластер Flink, и задание перезапускается в его последнем сохраненном состоянии , как будто ничего не произошло.
Мы используем RockDB в качестве государственного сервера, поддерживаемого хранилищем OpenStack Swift, предоставляемым OVH Public Cloud.
Для мониторинга мы полагаемся на Prometheus Exporter с Beamium, чтобы получить возможность наблюдать за состоянием здоровья рабочих.
Если вы привыкли работать с программным обеспечением, связанным с потоковой передачей, вы, возможно, поняли, что мы не использовали никаких ракетостроений или уловок. Возможно, мы полагаемся на базовые функции потоковой передачи, предлагаемые Apache Flink, но они позволили нам с легкостью решить многие проблемы бизнеса и масштабируемости.

Таким образом, мы настоятельно рекомендуем всем разработчикам взглянуть на Apache Flink. Я рекомендую вам пройти обучение Apache Flink , написанное Data Artisans. Более того, сообщество приложило немало усилий, чтобы легко развернуть Apache Flink в Kubernetes, поэтому вы можете легко попробовать Flink с помощью нашего управляемого Kubernetes!
На следующей неделе мы вернемся к Kubernetes, поскольку мы расскажем, как мы работаем с ETCD в нашей службе OVH Managed Kubernetes .
После создания платформы для работы со всеми этими метриками нашей следующей задачей было создать одну из самых необходимых функций для метрик: оповещение.
Встречайте OMNI, наш уровень оповещения
OMNI наше кодовое название полностью распределенной , как-код , предупреждая систему , которую мы разработали на вершине Метрики. Он разделен на компоненты:
- Часть управления , которая берет определения ваших предупреждений, определенных в репозитории Git, и представляет их как непрерывные запросы,
- Исполнитель запросов, распределяющий ваши запросы по расписанию.
Исполнитель запроса помещает результаты запроса в Kafka, готовые к обработке! Теперь нам нужно выполнить все задачи, которые выполняет система оповещения:
- Обработка дедупликации и группировки предупреждений, чтобы избежать усталости от предупреждений.
- Обработка шагов эскалации , подтверждения или откладывания .
- Уведомить конечного пользователя по разным каналам : SMS, почта, Push-уведомления и т. Д.
Чтобы справиться с этим, мы посмотрели на проекты с открытым исходным кодом, такие как Prometheus AlertManager, LinkedIn Iris, и обнаружили скрытую правду:
Обработка предупреждений как потоков данных,
передача от оператора к другому.
Мы приняли это и решили использовать Apache Flink для создания Beacon . В следующем разделе мы собираемся описать архитектуру Beacon, а также то, как мы ее построили и эксплуатировали.
Если вам нужна дополнительная информация об Apache Flink, мы предлагаем прочитать вводную статью на официальном сайте: Что такое Apache Flink?
Архитектура маяка
По сути, Beacon читает события от Кафки . Все представлено в виде сообщения , от предупреждений до правил агрегирования, отложенных заказов и так далее. Трубопровод разделен на две ветви:
- Тот, который выполняет агрегирование и запускает уведомления на основе правил клиента.
- Тот, который обрабатывает шаги эскалации .
Тогда все объединяется , чтобы произвести на уведомление , что собирается быть вперед к нужному человеку. Уведомляющее сообщение помещается в Kafka, которое будет использоваться другим компонентом, называемым beacon-notifier.
Если вы новичок в потоковой архитектуре, я рекомендую прочитать модель программирования потока данных из официальной документации Flink.
Все объединяется в поток данных, разделяется (с ключом в Flink API) пользователями. Вот пример:
final DataStream<Tuple4<PlanIdentifier, Alert, Plan, Operation>> alertStream =
// Partitioning Stream per AlertIdentifier
cleanedAlertsStream.keyBy(0)
// Applying a Map Operation which is setting since when an alert is triggered
.map(new SetSinceOnSelector())
.name("setting-since-on-selector").uid("setting-since-on-selector")
// Partitioning again Stream per AlertIdentifier
.keyBy(0)
// Applying another Map Operation which is setting State and Trend
.map(new SetStateAndTrend())
.name("setting-state").uid("setting-state");- SetSinceOnSelector , который устанавливается с момента срабатывания предупреждения
- SetStateAndTrend , который устанавливает состояние (ПРОДОЛЖЕНИЕ, ВОССТАНОВЛЕНИЕ или ОК) и тренд (есть ли у нас более или менее метрики в ошибках).
Каждый из этого класса содержит менее 120 строк кода, потому что Flink справляется со всеми трудностями . Большая часть конвейера состоит только из классических преобразований, таких как Map, FlatMap, Reduce , включая их версии Rich и Keyed . У нас есть несколько функций процессов , которые очень удобны для разработки, например, таймера эскалации.
Интеграционные тесты
Поскольку количество классов росло, нам нужно было протестировать наш конвейер. Поскольку он подключен только к Kafka, мы обернули потребителя и производителя, чтобы создать то, что мы называем сценарием: серию интеграционных тестов, запускающих разные сценарии.
Запрашиваемое состояние
Убийственная особенность Apache Flink — это возможность запрашивать внутреннее состояниеоператора . Даже если это бета-функция, она позволяет нам узнать текущее состояние различных частей работы:
- на каких этапах эскалации мы находимся
- это он прилег или извед -ed
- Какое оповещение продолжается
- и так далее.
Благодаря этому мы легко разработали API для состояния запроса, который поддерживает наше представление предупреждений в Metrics Studio, наше кодовое имя для веб-интерфейса платформы данных метрик.
Развертывание Apache Flink
Мы развернули последнюю версию Flink ( 1.7.1 на момент написания) непосредственно на голых металлических серверах с выделенным кластером Zookeeper с использованием Ansible. Работа с Flink стала для нас действительно приятным сюрпризом, с понятной документацией и настройкой , а также впечатляющей устойчивостью . Мы можем перезагрузить весь кластер Flink, и задание перезапускается в его последнем сохраненном состоянии , как будто ничего не произошло.
Мы используем RockDB в качестве государственного сервера, поддерживаемого хранилищем OpenStack Swift, предоставляемым OVH Public Cloud.
Для мониторинга мы полагаемся на Prometheus Exporter с Beamium, чтобы получить возможность наблюдать за состоянием здоровья рабочих.
Одним словом, мы любим Apache Flink!
Если вы привыкли работать с программным обеспечением, связанным с потоковой передачей, вы, возможно, поняли, что мы не использовали никаких ракетостроений или уловок. Возможно, мы полагаемся на базовые функции потоковой передачи, предлагаемые Apache Flink, но они позволили нам с легкостью решить многие проблемы бизнеса и масштабируемости.
Таким образом, мы настоятельно рекомендуем всем разработчикам взглянуть на Apache Flink. Я рекомендую вам пройти обучение Apache Flink , написанное Data Artisans. Более того, сообщество приложило немало усилий, чтобы легко развернуть Apache Flink в Kubernetes, поэтому вы можете легко попробовать Flink с помощью нашего управляемого Kubernetes!
Что дальше?
На следующей неделе мы вернемся к Kubernetes, поскольку мы расскажем, как мы работаем с ETCD в нашей службе OVH Managed Kubernetes .
0 комментариев