Рекомендации по мониторингу наблюдаемости OVH
В команде OVH Observability (ранее Metrics) мы собираем, обрабатываем и анализируем большую часть данных мониторинга OVH. Он представляет около 500 миллионов уникальных показателей, перемещая точки данных с постоянной скоростью 5 миллионов в секунду.
Эти данные можно классифицировать двумя способами: мониторинг хоста или приложения. Мониторинг хоста в основном основан на аппаратных счетчиках (ЦП, память, сеть, диск…), тогда как мониторинг приложений основан на сервисе и его масштабируемости (запросы, обработка, бизнес-логика…).
Мы предоставляем эту услугу для внутренних команд, которые пользуются тем же опытом, что и наши клиенты. По сути, наша служба Observability — это SaaS с уровнем совместимости (поддерживающим InfluxDB, OpenTSDB, Warp10, Prometheus и Graphite), который позволяет ему интегрироваться с большинством существующих решений. Таким образом, команде, которая привыкла к определенному инструменту или уже развернула решение для мониторинга, не нужно будет тратить много времени или усилий при переходе на полностью управляемую и масштабируемую службу: они просто выбирают токен, используют правильный конечная точка, и все готово. Кроме того, наш уровень совместимости предлагает выбор: вы можете отправить свои данные с помощью OpenTSDB, а затем запросить их в PromQL или WarpScript. Подобное комбинирование протоколов приводит к уникальной совместимости с открытым исходным кодом, которая обеспечивает большую ценность.
Опираясь на этот опыт, мы коллективно опробовали большинство инструментов сбора данных, но всегда приходили к одному и тому же выводу: мы наблюдали утечку показателей. Каждый инструмент ориентирован на очистку каждого доступного бита данных, что отлично, если вы зависим от графиков, но может оказаться контрпродуктивным с операционной точки зрения, если вам нужно контролировать тысячи хостов. Хотя их можно отфильтровать, командам все равно необходимо понимать весь набор показателей, чтобы знать, что нужно фильтровать.
В OVH мы используем наборы показателей, вырезанные лазером. У каждого хоста есть определенный шаблон (веб-сервер, база данных, автоматизация…), который экспортирует заданное количество показателей, которые можно использовать для диагностики работоспособности и мониторинга производительности приложений.
Такое детализированное управление приводит к большему пониманию для операционных команд, поскольку они знают, что доступно, и могут постепенно добавлять метрики для управления своими собственными услугами.
Наши требования были довольно простыми:
— Масштабируемость : мониторинг одного узла так же, как мы наблюдаем за тысячами
— Laser-Cut : собирать только релевантные метрики
— Надежность : мы хотим, чтобы метрики были доступны даже в наихудших условиях
— Просто : Несколько компонентов plug-and-play вместо сложных
— Эффективность : мы верим в беспроблемный сбор показателей
Beamium обрабатывает два аспекта процесса мониторинга: данные приложения слом и показатели пересылки.
Данные приложения собираются в хорошо известном и широко используемом формате Prometheus. Мы выбрали Prometheus, поскольку в то время сообщество быстро росло, и для него было доступно множество инструментальных библиотек. В Beamium есть две ключевые концепции: источники и приемники.
Источники, из которых Beamium будет извлекать данные, — это просто конечные точки HTTP Prometheus. Это означает, что это так же просто, как предоставить конечную точку HTTP и, в конечном итоге, добавить несколько параметров. Эти данные будут направляться в приемники, что позволяет нам фильтровать их во время процесса маршрутизации между источником и приемником. Приемники — это конечные точки Warp 10 ®, куда мы можем отправлять данные.
После очистки метрики сначала сохраняются на диске, а затем направляются в приемник. Механизм переключения диска при отказе (DFO) позволяет выполнять восстановление после сбоя в сети или удаленно. Таким образом, локально мы сохраняем логику вытягивания Prometheus, но децентрализованно, и мы обращаем ее вспять, чтобы протолкнуть для подачи на платформу, которая имеет много преимуществ:
У нас много разных клиентов, некоторые из которых используют хранилище временных рядов для продукта Observability для управления потреблением продукта или транзакционными изменениями при лицензировании. Эти варианты использования не могут быть обработаны с помощью экземпляров Prometheus, которые лучше подходят для мониторинга на основе метрик.
В ходе бесед с некоторыми из наших клиентов мы пришли к выводу, что существующие инструменты нуждаются в определенном уровне знаний, чтобы их можно было использовать в больших масштабах. Например, команда с кластером из 20 тыс. Узлов с Scollector в итоге получит более 10 миллионов метрик только для узлов… Фактически, в зависимости от конфигурации оборудования, Scollector будет генерировать от 350 до 1000 метрик из одного узла.
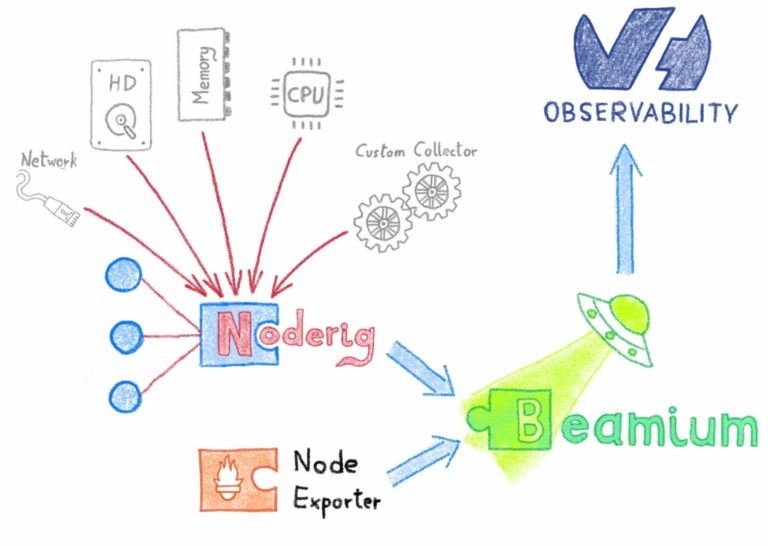
Это причина создания Noderig. Мы хотели, чтобы он был таким же простым в использовании, как экспортер узлов от Prometheus, но с более детализированным производством метрик по умолчанию.
Noderig собирает метрики ОС (ЦП, память, диск и сеть), используя семантику простого уровня. Это позволяет собирать нужное количество метрик для любого типа хоста, что особенно подходит для контейнерных сред.
Мы сделали его совместимым с пользовательскими сборщиками Scollector, чтобы упростить процесс миграции и обеспечить расширяемость. Внешние сборщики — это простые исполняемые файлы, которые действуют как поставщики данных, собираемых Noderig, как и любые другие показатели.
Собранные метрики доступны через простую конечную точку отдыха, что позволяет вам видеть свои метрики в режиме реального времени и легко интегрировать их с Beamium.
Beamium и Noderig широко используются в OVH и поддерживают мониторинг очень больших инфраструктур. На момент написания мы собираем и храним сотни миллионов показателей с помощью этих инструментов. Так что они определенно работают!
Фактически, в настоящее время мы работаем над выпуском 2.0, который будет доработкой, включающей автообнаружение и горячую перезагрузку.
Эти данные можно классифицировать двумя способами: мониторинг хоста или приложения. Мониторинг хоста в основном основан на аппаратных счетчиках (ЦП, память, сеть, диск…), тогда как мониторинг приложений основан на сервисе и его масштабируемости (запросы, обработка, бизнес-логика…).
Мы предоставляем эту услугу для внутренних команд, которые пользуются тем же опытом, что и наши клиенты. По сути, наша служба Observability — это SaaS с уровнем совместимости (поддерживающим InfluxDB, OpenTSDB, Warp10, Prometheus и Graphite), который позволяет ему интегрироваться с большинством существующих решений. Таким образом, команде, которая привыкла к определенному инструменту или уже развернула решение для мониторинга, не нужно будет тратить много времени или усилий при переходе на полностью управляемую и масштабируемую службу: они просто выбирают токен, используют правильный конечная точка, и все готово. Кроме того, наш уровень совместимости предлагает выбор: вы можете отправить свои данные с помощью OpenTSDB, а затем запросить их в PromQL или WarpScript. Подобное комбинирование протоколов приводит к уникальной совместимости с открытым исходным кодом, которая обеспечивает большую ценность.
Scollector, Snap, Telegraf, Graphite, Collectd…
Опираясь на этот опыт, мы коллективно опробовали большинство инструментов сбора данных, но всегда приходили к одному и тому же выводу: мы наблюдали утечку показателей. Каждый инструмент ориентирован на очистку каждого доступного бита данных, что отлично, если вы зависим от графиков, но может оказаться контрпродуктивным с операционной точки зрения, если вам нужно контролировать тысячи хостов. Хотя их можно отфильтровать, командам все равно необходимо понимать весь набор показателей, чтобы знать, что нужно фильтровать.
В OVH мы используем наборы показателей, вырезанные лазером. У каждого хоста есть определенный шаблон (веб-сервер, база данных, автоматизация…), который экспортирует заданное количество показателей, которые можно использовать для диагностики работоспособности и мониторинга производительности приложений.
Такое детализированное управление приводит к большему пониманию для операционных команд, поскольку они знают, что доступно, и могут постепенно добавлять метрики для управления своими собственными услугами.
Beamium & Noderig — Идеальная посадка
Наши требования были довольно простыми:
— Масштабируемость : мониторинг одного узла так же, как мы наблюдаем за тысячами
— Laser-Cut : собирать только релевантные метрики
— Надежность : мы хотим, чтобы метрики были доступны даже в наихудших условиях
— Просто : Несколько компонентов plug-and-play вместо сложных
— Эффективность : мы верим в беспроблемный сбор показателей
Первым решением был Beamium
Beamium обрабатывает два аспекта процесса мониторинга: данные приложения слом и показатели пересылки.
Данные приложения собираются в хорошо известном и широко используемом формате Prometheus. Мы выбрали Prometheus, поскольку в то время сообщество быстро росло, и для него было доступно множество инструментальных библиотек. В Beamium есть две ключевые концепции: источники и приемники.
Источники, из которых Beamium будет извлекать данные, — это просто конечные точки HTTP Prometheus. Это означает, что это так же просто, как предоставить конечную точку HTTP и, в конечном итоге, добавить несколько параметров. Эти данные будут направляться в приемники, что позволяет нам фильтровать их во время процесса маршрутизации между источником и приемником. Приемники — это конечные точки Warp 10 ®, куда мы можем отправлять данные.
После очистки метрики сначала сохраняются на диске, а затем направляются в приемник. Механизм переключения диска при отказе (DFO) позволяет выполнять восстановление после сбоя в сети или удаленно. Таким образом, локально мы сохраняем логику вытягивания Prometheus, но децентрализованно, и мы обращаем ее вспять, чтобы протолкнуть для подачи на платформу, которая имеет много преимуществ:
- поддержка транзакционной логики на платформе метрик
- восстановление после разделения сети или недоступности платформы
- двойная запись с согласованностью данных (поскольку в противном случае нет гарантии, что два экземпляра Prometheus будут очищать одни и те же данные с одной и той же меткой времени)
У нас много разных клиентов, некоторые из которых используют хранилище временных рядов для продукта Observability для управления потреблением продукта или транзакционными изменениями при лицензировании. Эти варианты использования не могут быть обработаны с помощью экземпляров Prometheus, которые лучше подходят для мониторинга на основе метрик.
Второй был Noderig
В ходе бесед с некоторыми из наших клиентов мы пришли к выводу, что существующие инструменты нуждаются в определенном уровне знаний, чтобы их можно было использовать в больших масштабах. Например, команда с кластером из 20 тыс. Узлов с Scollector в итоге получит более 10 миллионов метрик только для узлов… Фактически, в зависимости от конфигурации оборудования, Scollector будет генерировать от 350 до 1000 метрик из одного узла.
Это причина создания Noderig. Мы хотели, чтобы он был таким же простым в использовании, как экспортер узлов от Prometheus, но с более детализированным производством метрик по умолчанию.
Noderig собирает метрики ОС (ЦП, память, диск и сеть), используя семантику простого уровня. Это позволяет собирать нужное количество метрик для любого типа хоста, что особенно подходит для контейнерных сред.
Мы сделали его совместимым с пользовательскими сборщиками Scollector, чтобы упростить процесс миграции и обеспечить расширяемость. Внешние сборщики — это простые исполняемые файлы, которые действуют как поставщики данных, собираемых Noderig, как и любые другие показатели.
Собранные метрики доступны через простую конечную точку отдыха, что позволяет вам видеть свои метрики в режиме реального времени и легко интегрировать их с Beamium.
Это работает?
Beamium и Noderig широко используются в OVH и поддерживают мониторинг очень больших инфраструктур. На момент написания мы собираем и храним сотни миллионов показателей с помощью этих инструментов. Так что они определенно работают!
Фактически, в настоящее время мы работаем над выпуском 2.0, который будет доработкой, включающей автообнаружение и горячую перезагрузку.
0 комментариев