Тестирование промышленных систем хранения с помощью размещенного частного облака от OVHcloud
Бенчмаркинг — это очень обсуждаемая тема в компьютерной индустрии из-за бесчисленного множества методов и подходов. Однако в этом блоге не будут перечислены все эти подходы, а вместо этого будет предоставлено представление о том, как мы проводим сравнительный анализ различных видов хранилищ, доступных в наших решениях для размещенного частного облака.
Прежде чем обсуждать это более подробно, мы должны понять, почему мы вообще проводим бенчмаркинг. Причина номер один в том, что нам необходимо оценить влияние на наших клиентов, прежде чем запускать что-либо в производство. Это может быть что угодно, от новой платформы хранения, новой модели диска, исправления ядра до обновления прошивки и любого количества вариантов использования.
По мере того, как мы продолжаем улучшать нашу инфраструктуру хранения и внедрять новые технологии хранения, мы регулярно совершенствуем наши методологии и инструменты тестирования. С тысячами ссылок на оборудование и равным количеством конфигураций количество тестов, которые нам нужно достичь, является экспоненциальным. Вот почему так важно индустриализировать процесс.
Стремясь повысить прозрачность, мы решили проводить тесты с точки зрения конечного пользователя. Это означает, что всю оркестровку, которую мы описываем в этом сообщении блога, может выполнить любой из наших клиентов размещенного частного облака.
FIO, vdbench, I / O Meter, (dd!) — это лишь некоторые из широко используемых и проверенных инструментов для тестирования хранилища. Они дают вам обзор чистой производительности для данного типа хранилища. Но что, если вы хотите протестировать всю инфраструктуру от начала до конца? Это может включать 1, 10, 100, 1000 виртуальных машин или более, с несколькими настройками диска / рейда, несколькими размерами дисков, несколькими размерами блоков. И все это с различными типичными рабочими нагрузками, состоящими из определенного процента операций чтения / записи, последовательных или случайных, и выполняемых таким количеством потоков. Вам также нужно будет использовать рабочие нагрузки, соответствующие вашим производственным рабочим нагрузкам. На самом деле комбинации бесконечны.
Имея все это в виду, для нашей первой итерации мы начали использовать HCIbench для автоматизации наших тестов.

HCibench ( flings.vmware.com/hcibench ) — это бесплатный инструмент автоматизации тестов с открытым исходным кодом. Он определяет себя как «Тест гиперконвергентной инфраструктуры». По сути, это оболочка для автоматизации популярных и проверенных инструментов тестирования производительности с открытым исходным кодом: Vdbench и Fio, упрощающая автоматизацию тестирования в кластере HCI. HCIBench стремится упростить и ускорить тестирование производительности клиентских POC последовательным и контролируемым образом. Этот инструмент полностью автоматизирует сквозной процесс развертывания тестовых виртуальных машин, координации выполнения рабочих нагрузок, агрегирования результатов тестирования, анализа производительности и сбора необходимых данных для устранения неполадок.
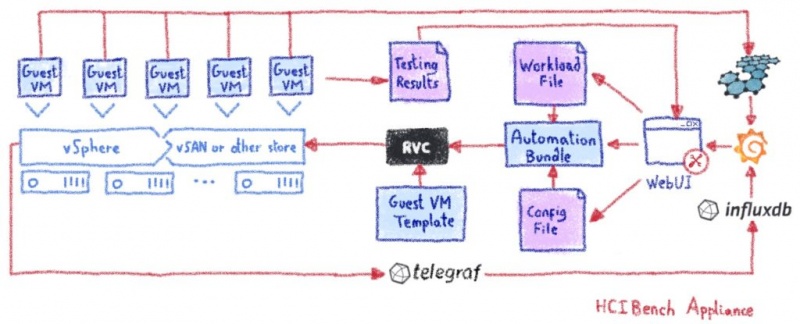
HCIbench так же просто установить, как развернуть OVA (Open Virtual Appliance) в вашей инфраструктуре VMware:
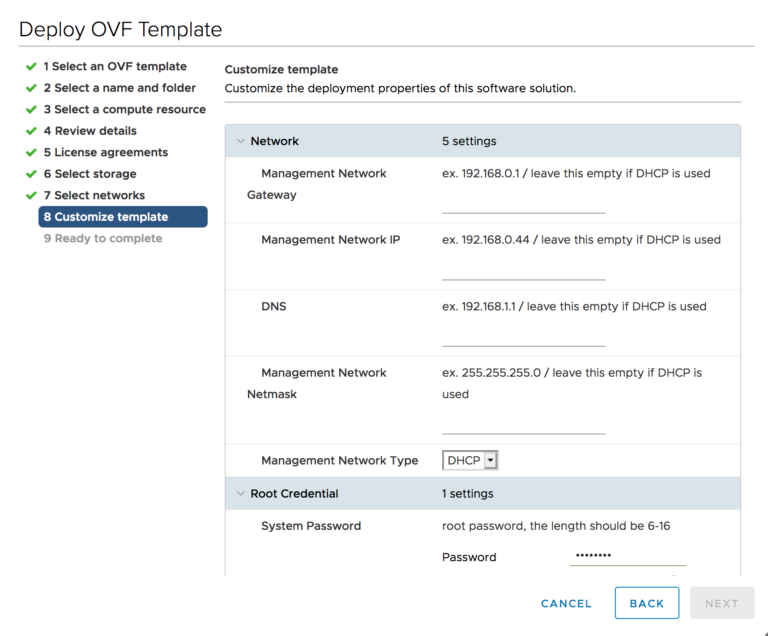
После настройки HCIbench просто укажите в браузере адрес https: // IP: 8483, и вы готовы приступить к тестированию:
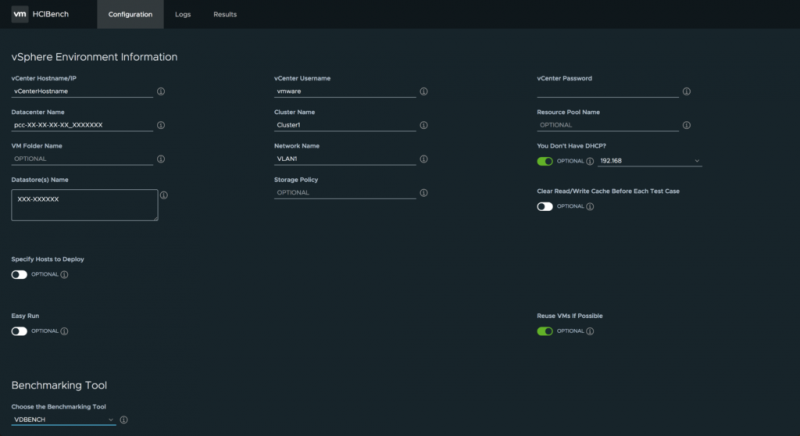
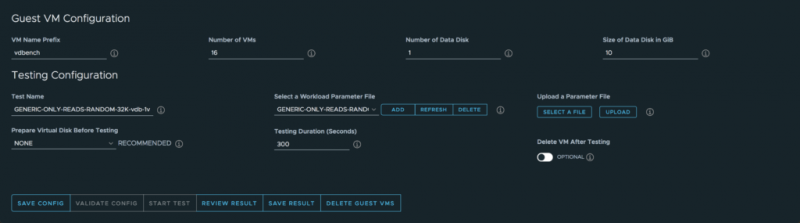
После того, как вы ввели свои учетные данные vCenter и некоторую дополнительную информацию (центр обработки данных, кластер, сеть, хранилище данных и т. Д.), Вы сможете установить настройки гостевых виртуальных машин:
Затем HCIbench возьмет на себя все операции по развертыванию / утилизации виртуальных машин и выполнит ваш тест. Результаты доступны в различных формах, от интерфейсов Grafana до файлов Excel или просто текстовых файлов для дальнейшего внешнего анализа…
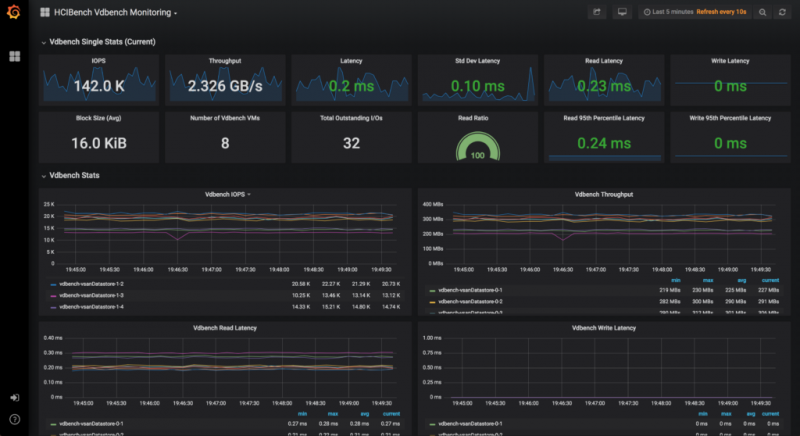
Файлы параметров рабочей нагрузки (здесь используются vdbench) лежат в основе всех операций тестирования. Они описывают модель ввода-вывода, которую вы хотите использовать для данной конечной точки хранилища. Доступны проценты чтения / записи, случайные / последовательные, размер блока, потоки и многие другие параметры.
Мы выбрали 3 разных подхода для оценки наших платформ хранения: общие рабочие нагрузки, рабочие нагрузки приложений и производственные рабочие нагрузки.
Под «общими» рабочими нагрузками мы понимаем все рабочие нагрузки, которые выглядят как «ТОЛЬКО СЛУЧАЙНОЕ ЧТЕНИЕ» или «ТОЛЬКО ПОСЛЕДОВАТЕЛЬНЫЕ ЗАПИСИ». Они позволяют нам проверить, как тип хранилища реагирует на линейные случаи и как он работает с «крайними» случаями.

Пример «универсального» файла параметров рабочей нагрузки vdbench
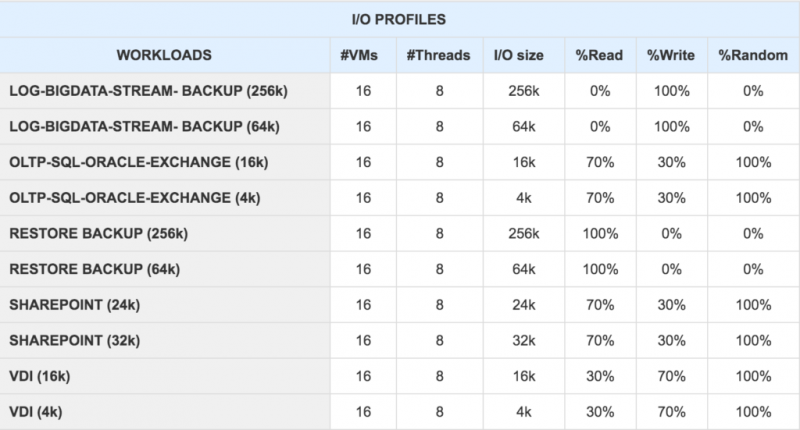
Под «прикладными» рабочими нагрузками мы понимаем рабочие нагрузки, которые соответствуют типичным производственным сценариям использования, таким как «РАБОЧАЯ ЗАГРУЗКА БАЗЫ ДАННЫХ», «РАБОЧАЯ ЗАГРУЗКА VDI», «РЕЗЕРВНАЯ РАБОЧАЯ ЗАГРУЗКА» и т. Д. отлично.
Пример файла параметров рабочей нагрузки vdbench «Приложение»
Наконец, еще один подход, над которым мы работаем, — это возможность «записывать» производственную рабочую нагрузку и «воспроизводить» ее на другой конечной точке хранилища, чтобы оценить, как целевое хранилище работает с вашей производственной рабочей нагрузкой, без необходимости запускать на нем реальное производство. Хитрость здесь в том, чтобы использовать сочетание 3 инструментов: blktrace, btrecord и btreplay, чтобы отслеживать и отслеживать вызовы ввода-вывода низкого уровня и иметь возможность воспроизвести эти следы на другой платформе хранения.
В следующих статьях блога мы поделимся с вами этой функцией, следите за обновлениями!

Как мы видели, за несколько щелчков мышью мы можем определить и запустить тестовый сценарий для конкретной рабочей нагрузки. Развертывание и повторное использование тестовых виртуальных машин полностью автоматизировано. Что, если в следующий раз мы захотим повторить несколько сценариев? Например, в рамках общей проверки новой платформы хранения? На этом этапе мы начали использовать Rundeck ( www.rundeck.com), бесплатный планировщик автоматизации Runbook с открытым исходным кодом, перед HCIbench. Идея состоит в том, чтобы иметь возможность создавать полные коллекции сценариев тестов.
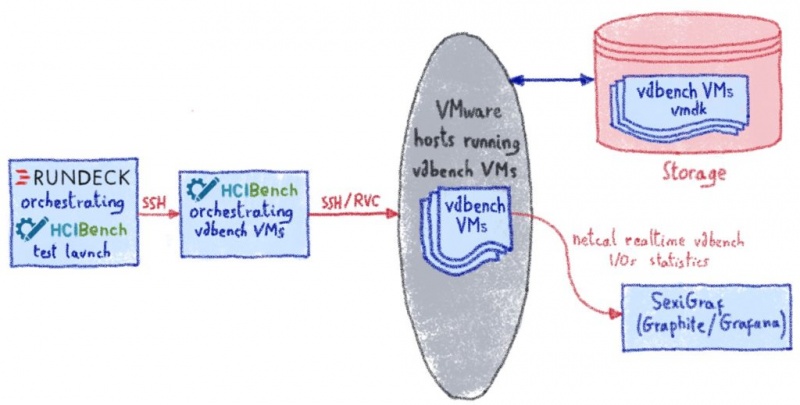
Первым шагом было понять, как HCIbench работает под капотом, чтобы мы могли управлять им через планировщик Rundeck. HCIbench разработан для использования через веб-интерфейс, но все его механизмы выполняются с помощью чистых и отдельных скриптов, таких как start / stop / kill. Все настройки тестов хранятся в чистом плоском файле конфигурации, который легко преобразовать в шаблон…

Задание rundeck состоит из последовательности шагов, которые будут выполняться для определенного списка узлов. В нашем контексте узлы — это виртуальные машины, на которых работает HCIbench.
То, что мы называем стендовым «корневым заданием», — это задание rundeck, которое является основной точкой входа в стенд. Его общая роль заключается в том, чтобы вызывать другие рабочие места и запускать один конкретный стенд.
Опции (параметры) этого задания — это все элементы из шаблона конфигурации HCIbench (см. Выше).
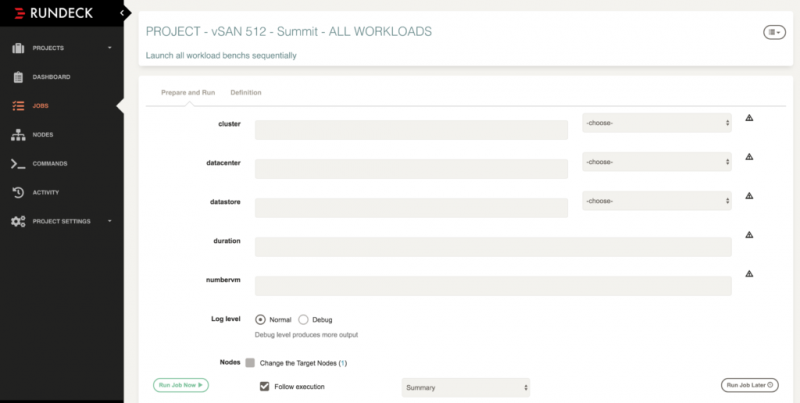
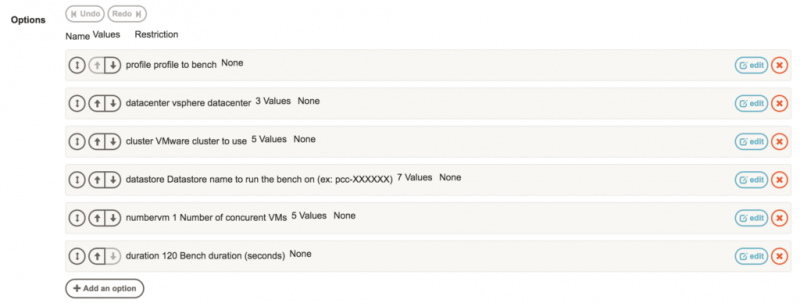
Рабочий процесс для этого задания следующий:
— Параметры задания синтаксического анализа
— Подключение SSH к виртуальной машине HCIbench
- Заполнение шаблона конфигурации соответствующими параметрами задания
— Запуск HCIbench
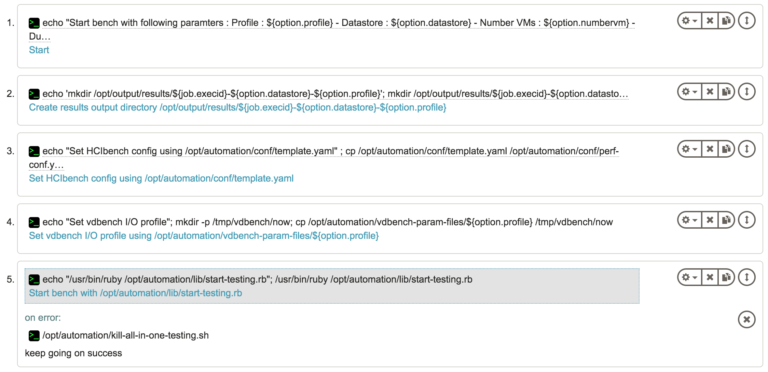
Во-вторых, у нас есть «скамейки запасные». С помощью rundeck API мы создали задания для каждой рабочей нагрузки, чтобы иметь возможность запускать стенды индивидуально или в группе по мере необходимости. Каждое из этих «стендовых заданий» вызывает описанное выше «корневое задание» с соответствующими параметрами стендового анализа.
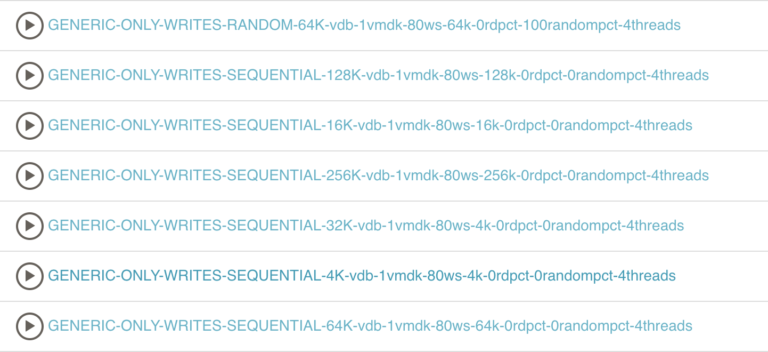
Наконец-то у нас есть «Супер вакансии». Это коллекции заданий, их рабочие процессы — это серии вызовов стендовых заданий. Мы используем механизм каскадных опций для передачи опций через задания. В приведенном ниже примере мы тестируем кластер vSAN через полную панель моделей ввода-вывода.
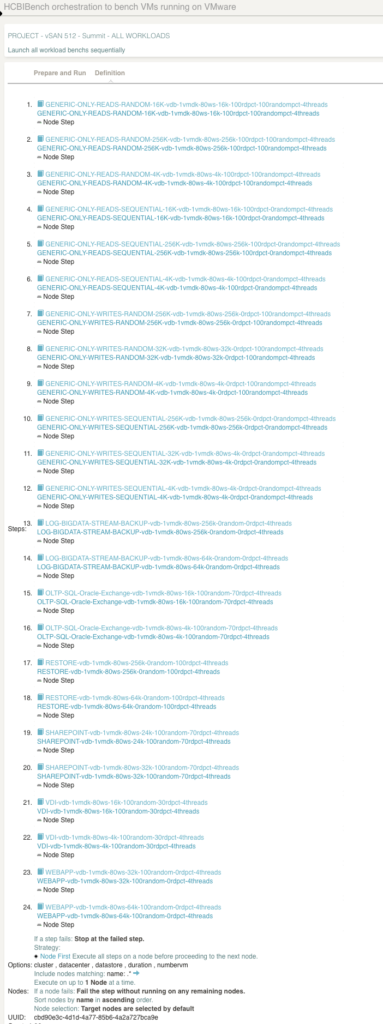
Еще одна интересная особенность использования Rundeck в качестве планировщика HCIbench — это возможность хранить все журналы с виртуальных машин HCIbench и время каждого теста в одном месте. Таким образом, можно легко просматривать и искать по всем нашим тестам или ориентироваться на конкретное поведение, показанное на графике.
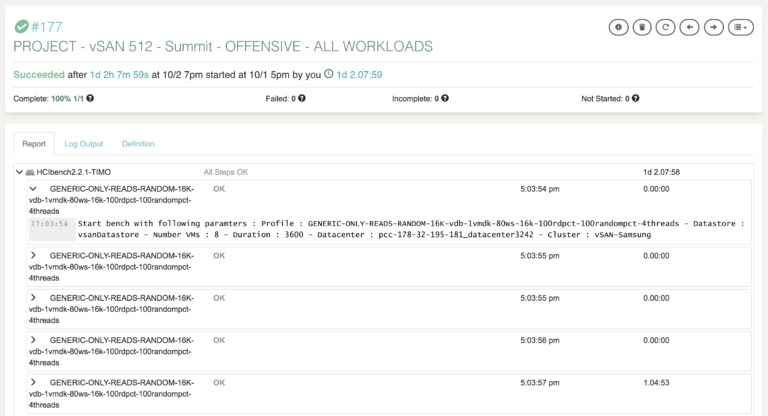
Интеграция vSAN в наш продукт Hosted Private Cloud была типичным эталонным проектом, в котором нам нужно было не только проверить, как вся платформа работает в каждой области, но и уточнить дизайн самой платформы. С одной стороны, мы оценили дизайн оборудования с несколькими ссылками на диски, а с другой стороны, мы улучшили дизайн программного обеспечения, оценив различные группы дисков vSAN и конфигурации кеша.

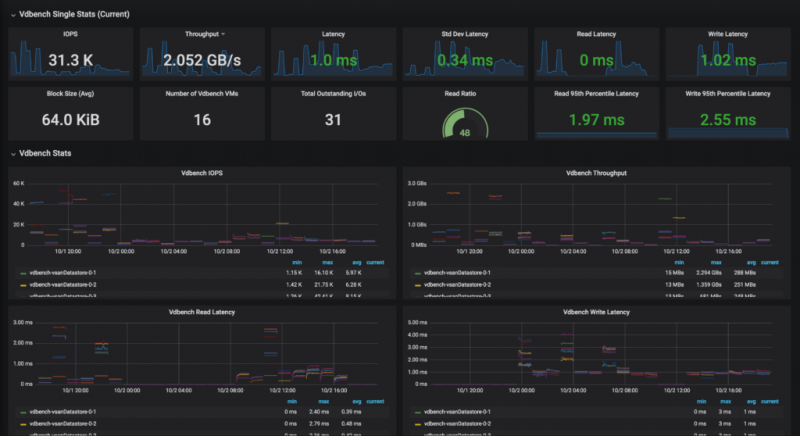
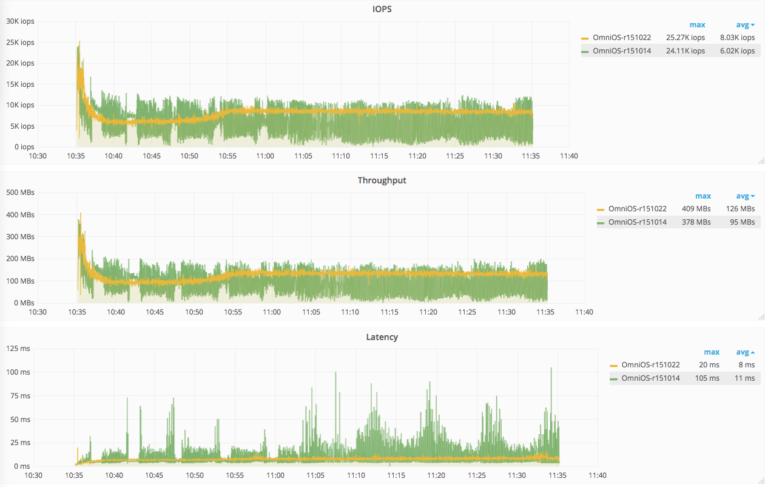
Еще один интересный случай использования — это оценка влияния нового ядра на массивы хранения на базе OmniOS ( www.omniosce.org). OmniOS — это бесплатная операционная система с открытым исходным кодом, основанная на OpenSolaris, которая объединяет некоторые замечательные технологии, такие как ZFS, DTrace, Crossbow, SMF, Bhyve, KVM и поддержку зон Linux. Этот случай показывает не только немного лучшие характеристики, но и значительное улучшение обработки операций ввода-вывода.
Действительно, среди множества различных тестов новое ядро (r151022) показывает гораздо более стабильные и линейные операции ввода-вывода. Этот стенд также подтверждает несколько исправлений ZFS / NFS, которые были включены в это ядро, которые устраняют проблемы с задержкой во время отправки / получения снимка ZFS.
Индустриализация наших тестов позволила нам отслеживать производительность нашего хранилища. Прежде всего, поскольку мы создавали их для наших пользователей, мы согласны с тем, что получат наши клиенты. Кроме того, тесты дают нам представление об устранении проблем с хранением, которые очень специфичны и / или видны только с виртуальных машин. Мы планируем расширить это, чтобы мы могли проверить, как работает вычислительная сторона (CPU / RAM /…). Наконец, теперь мы сосредоточены на функции записи / воспроизведения рабочей нагрузки, позволяющей нашим пользователям прогнозировать, как их производственная рабочая нагрузка будет работать на платформах «XYZ», без необходимости фактически запускать на ней свою производственную среду. Мы подробно расскажем об этом в следующих статьях блога, следите за обновлениями!
Прежде чем обсуждать это более подробно, мы должны понять, почему мы вообще проводим бенчмаркинг. Причина номер один в том, что нам необходимо оценить влияние на наших клиентов, прежде чем запускать что-либо в производство. Это может быть что угодно, от новой платформы хранения, новой модели диска, исправления ядра до обновления прошивки и любого количества вариантов использования.
Короткий рассказ
По мере того, как мы продолжаем улучшать нашу инфраструктуру хранения и внедрять новые технологии хранения, мы регулярно совершенствуем наши методологии и инструменты тестирования. С тысячами ссылок на оборудование и равным количеством конфигураций количество тестов, которые нам нужно достичь, является экспоненциальным. Вот почему так важно индустриализировать процесс.
Стремясь повысить прозрачность, мы решили проводить тесты с точки зрения конечного пользователя. Это означает, что всю оркестровку, которую мы описываем в этом сообщении блога, может выполнить любой из наших клиентов размещенного частного облака.
Инструменты и оркестровка
FIO, vdbench, I / O Meter, (dd!) — это лишь некоторые из широко используемых и проверенных инструментов для тестирования хранилища. Они дают вам обзор чистой производительности для данного типа хранилища. Но что, если вы хотите протестировать всю инфраструктуру от начала до конца? Это может включать 1, 10, 100, 1000 виртуальных машин или более, с несколькими настройками диска / рейда, несколькими размерами дисков, несколькими размерами блоков. И все это с различными типичными рабочими нагрузками, состоящими из определенного процента операций чтения / записи, последовательных или случайных, и выполняемых таким количеством потоков. Вам также нужно будет использовать рабочие нагрузки, соответствующие вашим производственным рабочим нагрузкам. На самом деле комбинации бесконечны.
Имея все это в виду, для нашей первой итерации мы начали использовать HCIbench для автоматизации наших тестов.
Тест гиперконвергентной инфраструктуры
HCibench ( flings.vmware.com/hcibench ) — это бесплатный инструмент автоматизации тестов с открытым исходным кодом. Он определяет себя как «Тест гиперконвергентной инфраструктуры». По сути, это оболочка для автоматизации популярных и проверенных инструментов тестирования производительности с открытым исходным кодом: Vdbench и Fio, упрощающая автоматизацию тестирования в кластере HCI. HCIBench стремится упростить и ускорить тестирование производительности клиентских POC последовательным и контролируемым образом. Этот инструмент полностью автоматизирует сквозной процесс развертывания тестовых виртуальных машин, координации выполнения рабочих нагрузок, агрегирования результатов тестирования, анализа производительности и сбора необходимых данных для устранения неполадок.
HCIbench так же просто установить, как развернуть OVA (Open Virtual Appliance) в вашей инфраструктуре VMware:
После настройки HCIbench просто укажите в браузере адрес https: // IP: 8483, и вы готовы приступить к тестированию:
После того, как вы ввели свои учетные данные vCenter и некоторую дополнительную информацию (центр обработки данных, кластер, сеть, хранилище данных и т. Д.), Вы сможете установить настройки гостевых виртуальных машин:
- Количество виртуальных машин для развертывания
- Количество дисков для каждой ВМ
- Размер диска
- Инструмент тестирования (FIO или vdbench)
- Файл параметров ввода-вывода (подробности см. Ниже)
- Продолжительность
- И более …
Затем HCIbench возьмет на себя все операции по развертыванию / утилизации виртуальных машин и выполнит ваш тест. Результаты доступны в различных формах, от интерфейсов Grafana до файлов Excel или просто текстовых файлов для дальнейшего внешнего анализа…
Файлы параметров рабочей нагрузки, моделирование операций ввода-вывода
Файлы параметров рабочей нагрузки (здесь используются vdbench) лежат в основе всех операций тестирования. Они описывают модель ввода-вывода, которую вы хотите использовать для данной конечной точки хранилища. Доступны проценты чтения / записи, случайные / последовательные, размер блока, потоки и многие другие параметры.
Мы выбрали 3 разных подхода для оценки наших платформ хранения: общие рабочие нагрузки, рабочие нагрузки приложений и производственные рабочие нагрузки.
«Общие» рабочие нагрузки
Под «общими» рабочими нагрузками мы понимаем все рабочие нагрузки, которые выглядят как «ТОЛЬКО СЛУЧАЙНОЕ ЧТЕНИЕ» или «ТОЛЬКО ПОСЛЕДОВАТЕЛЬНЫЕ ЗАПИСИ». Они позволяют нам проверить, как тип хранилища реагирует на линейные случаи и как он работает с «крайними» случаями.
Пример «универсального» файла параметров рабочей нагрузки vdbench
root@photon-HCIBench [ /opt/automation/vdbench-param-files ]# cat
GENERIC-ONLY-READS-RANDOM-16K-vdb-1vmdk-80ws-16k-100rdpct-100randompct-4threads
*SD: Storage Definition
*WD: Workload Definition
*RD: Run Definitionsd=sd1,
lun=/dev/sda,openflags=o_direct,
hitarea=0,range=(0,80),
threads=4,
wd=wd1,
sd=sd1,
rd=run1,
xfersize=16k,
rdpct=100,
seekpct=100,
iorate=max,
elapsed=120,
interval=1«Приложения»
Под «прикладными» рабочими нагрузками мы понимаем рабочие нагрузки, которые соответствуют типичным производственным сценариям использования, таким как «РАБОЧАЯ ЗАГРУЗКА БАЗЫ ДАННЫХ», «РАБОЧАЯ ЗАГРУЗКА VDI», «РЕЗЕРВНАЯ РАБОЧАЯ ЗАГРУЗКА» и т. Д. отлично.
Пример файла параметров рабочей нагрузки vdbench «Приложение»
root@photon-HCIBench [ /opt/automation/vdbench-param-files ]# cat
OLTP-SQL-Oracle-Exchange-vdb-1vmdk-80ws-16k-100random-70rdpct-4threads
*SD: Storage Definition
*WD: Workload Definition
*RD: Run Definitionsd=sd1,
lun=/dev/sda,
openflags=o_direct,
hitarea=0,range=(0,80),
threads=4wd=wd1,
sd=(sd1),
xfersize=16k,
rdpct=70,
seekpct=100,
rd=run1,
wd=wd1,
iorate=max,
elapsed=120,
interval=1«Производственные» нагрузки.
Наконец, еще один подход, над которым мы работаем, — это возможность «записывать» производственную рабочую нагрузку и «воспроизводить» ее на другой конечной точке хранилища, чтобы оценить, как целевое хранилище работает с вашей производственной рабочей нагрузкой, без необходимости запускать на нем реальное производство. Хитрость здесь в том, чтобы использовать сочетание 3 инструментов: blktrace, btrecord и btreplay, чтобы отслеживать и отслеживать вызовы ввода-вывода низкого уровня и иметь возможность воспроизвести эти следы на другой платформе хранения.
В следующих статьях блога мы поделимся с вами этой функцией, следите за обновлениями!
Индустриализация HCIbench работает с планировщиком Rundeck
Как мы видели, за несколько щелчков мышью мы можем определить и запустить тестовый сценарий для конкретной рабочей нагрузки. Развертывание и повторное использование тестовых виртуальных машин полностью автоматизировано. Что, если в следующий раз мы захотим повторить несколько сценариев? Например, в рамках общей проверки новой платформы хранения? На этом этапе мы начали использовать Rundeck ( www.rundeck.com), бесплатный планировщик автоматизации Runbook с открытым исходным кодом, перед HCIbench. Идея состоит в том, чтобы иметь возможность создавать полные коллекции сценариев тестов.
Первым шагом было понять, как HCIbench работает под капотом, чтобы мы могли управлять им через планировщик Rundeck. HCIbench разработан для использования через веб-интерфейс, но все его механизмы выполняются с помощью чистых и отдельных скриптов, таких как start / stop / kill. Все настройки тестов хранятся в чистом плоском файле конфигурации, который легко преобразовать в шаблон…
Создание шаблона файла конфигурации HCIbench
root@photon-HCIBench [ /opt/automation/conf ]# cat template.yaml
vc: '<VCENTER_HOSTIP>'
vc_username: '<USERNAME>'
vc_password: '<PASSWORD>'
datacenter_name: '<DATACENTER>'
cluster_name: '<CLUSTER>'
number_vm: '<NUMBERVM>'
testing_duration: '<DURATION>'
datastore_name:- '<DATASTORE>'
output_path: '<OUTPUT_PATH>'
...Скамья «корневая работа»
Задание rundeck состоит из последовательности шагов, которые будут выполняться для определенного списка узлов. В нашем контексте узлы — это виртуальные машины, на которых работает HCIbench.
То, что мы называем стендовым «корневым заданием», — это задание rundeck, которое является основной точкой входа в стенд. Его общая роль заключается в том, чтобы вызывать другие рабочие места и запускать один конкретный стенд.
Опции (параметры) этого задания — это все элементы из шаблона конфигурации HCIbench (см. Выше).
Рабочий процесс для этого задания следующий:
— Параметры задания синтаксического анализа
— Подключение SSH к виртуальной машине HCIbench
- Заполнение шаблона конфигурации соответствующими параметрами задания
— Запуск HCIbench
Скамейка
Во-вторых, у нас есть «скамейки запасные». С помощью rundeck API мы создали задания для каждой рабочей нагрузки, чтобы иметь возможность запускать стенды индивидуально или в группе по мере необходимости. Каждое из этих «стендовых заданий» вызывает описанное выше «корневое задание» с соответствующими параметрами стендового анализа.
«Супер» вакансии
Наконец-то у нас есть «Супер вакансии». Это коллекции заданий, их рабочие процессы — это серии вызовов стендовых заданий. Мы используем механизм каскадных опций для передачи опций через задания. В приведенном ниже примере мы тестируем кластер vSAN через полную панель моделей ввода-вывода.
Еще одна интересная особенность использования Rundeck в качестве планировщика HCIbench — это возможность хранить все журналы с виртуальных машин HCIbench и время каждого теста в одном месте. Таким образом, можно легко просматривать и искать по всем нашим тестам или ориентироваться на конкретное поведение, показанное на графике.
Результаты и варианты использования
vSANИнтеграция vSAN в наш продукт Hosted Private Cloud была типичным эталонным проектом, в котором нам нужно было не только проверить, как вся платформа работает в каждой области, но и уточнить дизайн самой платформы. С одной стороны, мы оценили дизайн оборудования с несколькими ссылками на диски, а с другой стороны, мы улучшили дизайн программного обеспечения, оценив различные группы дисков vSAN и конфигурации кеша.
Влияние нового ядра на массивы хранения
Еще один интересный случай использования — это оценка влияния нового ядра на массивы хранения на базе OmniOS ( www.omniosce.org). OmniOS — это бесплатная операционная система с открытым исходным кодом, основанная на OpenSolaris, которая объединяет некоторые замечательные технологии, такие как ZFS, DTrace, Crossbow, SMF, Bhyve, KVM и поддержку зон Linux. Этот случай показывает не только немного лучшие характеристики, но и значительное улучшение обработки операций ввода-вывода.
Действительно, среди множества различных тестов новое ядро (r151022) показывает гораздо более стабильные и линейные операции ввода-вывода. Этот стенд также подтверждает несколько исправлений ZFS / NFS, которые были включены в это ядро, которые устраняют проблемы с задержкой во время отправки / получения снимка ZFS.
Индустриализация наших тестов позволила нам отслеживать производительность нашего хранилища. Прежде всего, поскольку мы создавали их для наших пользователей, мы согласны с тем, что получат наши клиенты. Кроме того, тесты дают нам представление об устранении проблем с хранением, которые очень специфичны и / или видны только с виртуальных машин. Мы планируем расширить это, чтобы мы могли проверить, как работает вычислительная сторона (CPU / RAM /…). Наконец, теперь мы сосредоточены на функции записи / воспроизведения рабочей нагрузки, позволяющей нашим пользователям прогнозировать, как их производственная рабочая нагрузка будет работать на платформах «XYZ», без необходимости фактически запускать на ней свою производственную среду. Мы подробно расскажем об этом в следующих статьях блога, следите за обновлениями!
0 комментариев