Вам нужно обработать ваши данные? Попробуйте новый сервис обработки данных OVHcloud!
Сегодня мы генерируем больше данных, чем когда-либо. 90 процентов глобальных данных были собраны за последние 2 года. По оценкам, к 2025 году объем данных в мире достигнет 175 зеттабайт. В общей сложности люди пишут 500 миллионов твитов в день, а автономные автомобили генерируют 20 ТБ данных каждый час. К 2025 году более 75 миллиардов устройств Интернета вещей будут подключены к Интернету, и все они будут генерировать данные. В настоящее время устройства и службы, генерирующие данные, есть повсюду.
Также существует понятие «исчерпание данных», которое является побочным продуктом онлайн-активности людей. Это данные, которые создаются в результате посещения кем-то веб-сайта, покупки продукта или поиска чего-либо с помощью поисковой системы. Возможно, вы слышали, что эти данные называются метаданными.
Мы начнем тонуть в потоке данных, если не научимся плавать — как извлечь выгоду из огромного количества данных. Для этого нам необходимо иметь возможность обрабатывать данные с целью принятия более эффективных решений, предотвращения мошенничества и опасностей, изобретения лучших продуктов или даже предсказания будущего. Возможности безграничны.
Но как мы можем обработать такой огромный объем данных? Конечно, по старинке сделать это невозможно. Нам необходимо модернизировать наши методы и оборудование.
Большие данные — это наборы данных, объем, скорость и разнообразие которых слишком велики для обработки на локальном компьютере. Итак, каковы требования к обработке «больших данных»?

Данные есть везде и доступны в огромных количествах. Во-первых, давайте применим старое правило: «Разделяй и властвуй».
Разделение данных означает, что нам потребуется распределить данные и задачи обработки по нескольким компьютерам. Их нужно будет настроить в кластере, чтобы выполнять эти различные задачи параллельно и получить разумное повышение производительности и скорости.
Предположим, вам нужно было узнать, что сейчас в твиттере. Вам придется обработать около 500 миллионов твитов на одном компьютере за час. Не все так просто, правда? И как вы выиграете, если на обработку уйдет месяц? Какая ценность в том, чтобы найти тренд дня месяц спустя?
Распараллеливание — это больше, чем просто «хорошо иметь». Это требование!
Второй шаг — это создание и эффективное управление этими кластерами.
Здесь у вас есть несколько вариантов, например, создание кластеров со своими собственными серверами и управление ими самостоятельно. Но это требует много времени и довольно дорого. В нем также отсутствуют некоторые функции, которые вы, возможно, захотите использовать, например гибкость. По этим причинам облако с каждым днем становится все лучше и лучше для многих компаний.
Эластичность, которую обеспечивают облачные решения, помогает компаниям быть гибкими и адаптировать инфраструктуру к своим потребностям. При обработке данных, например, нам нужно будет иметь возможность легко масштабировать наш вычислительный кластер, чтобы адаптировать вычислительную мощность к объему данных, которые мы хотим обработать, в соответствии с нашими ограничениями (время, затраты и т. Д.).
И тогда, даже если вы решите использовать облачного провайдера, у вас будет несколько решений на выбор, каждое из которых имеет свои недостатки. Одно из этих решений — создать вычислительный кластер на выделенных серверах или экземплярах общедоступного облака и отправить в кластер различные задания по обработке. Главный недостаток этого решения заключается в том, что если обработка не выполняется, вы все равно платите за зарезервированные, но неиспользуемые ресурсы обработки.
Поэтому более эффективным способом было бы создать выделенный кластер для каждого задания обработки с соответствующими ресурсами для этого задания, а затем удалить кластер после этого. Каждое новое задание будет иметь собственный кластер нужного размера, порожденный по запросу. Но это решение было бы возможным, только если бы создание вычислительного кластера заняло всего несколько секунд, а не минуты или часы.
При создании обрабатывающего кластера также можно учитывать локальность данных. Здесь облачные провайдеры обычно предлагают несколько регионов, разбросанных по центрам обработки данных, расположенным в разных странах. У него два основных преимущества:
Первый не связан напрямую с местонахождением данных, это скорее юридический вопрос. В зависимости от того, где находятся ваши клиенты и ваши данные, вам может потребоваться соблюдать местные законы и правила о конфиденциальности данных. Возможно, вам придется хранить свои данные в определенном регионе или стране и не иметь возможности обрабатывать их за пределами страны. Таким образом, чтобы создать кластер компьютеров в этом регионе, проще обрабатывать данные, соблюдая местные политики конфиденциальности.
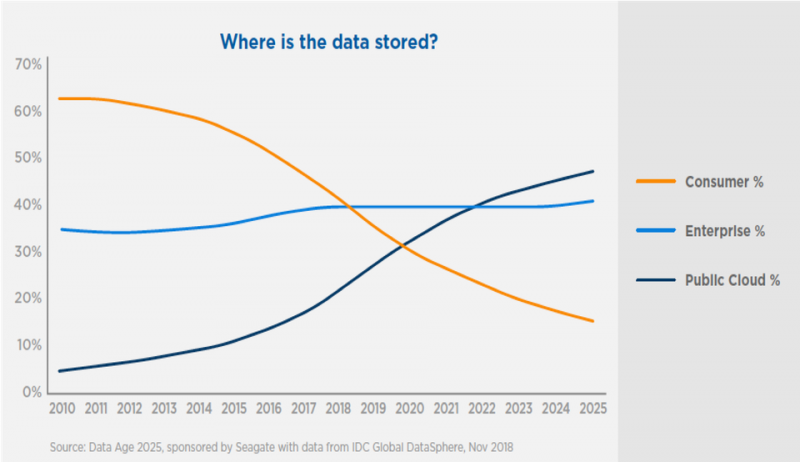
Второе преимущество — это, конечно, возможность создавать кластеры обработки в непосредственной близости от ваших данных. По оценкам, к 2025 году почти 50 процентов данных в мире будут храниться в облаке. Объем локального хранения данных сокращается.
Следовательно, использование облачных провайдеров, имеющих несколько регионов, дает компаниям преимущество наличия кластеров обработки рядом с их физическим расположением данных — это значительно сокращает время (и затраты!), Необходимое для получения данных.
Хотя обработка ваших данных в облаке может и не быть требованием сама по себе, это, безусловно, более выгодно, чем делать это самостоятельно.
Третий и последний шаг — решить, как вы собираетесь обрабатывать свои данные, то есть с помощью каких инструментов. Опять же, вы можете сделать это самостоятельно, реализовав механизм распределенной обработки на любом языке по вашему выбору. Но где в этом веселье? (хорошо, для некоторых из нас это может быть довольно весело!)
Но это было бы астрономически сложно. Вам нужно будет написать код, чтобы разделить данные на несколько частей и отправить каждую часть на компьютер в вашем кластере. Затем каждый компьютер будет обрабатывать свою часть данных, и вам нужно будет найти способ получить результаты каждой части и повторно собрать все в согласованный результат. Короче говоря, потребовалось бы много работы с большим количеством отладки.
Apache Spark
Но есть технологии, которые были разработаны специально для этого. Они автоматически распределяют данные и обрабатывают задачи и получают результаты за вас. В настоящее время самой популярной технологией распределенных вычислений, особенно применительно к предметам Data Science, является Apache Spark.
Apache Spark — это распределенная среда кластерных вычислений с открытым исходным кодом. Он намного быстрее, чем предыдущий, Hadoop MapReduce, благодаря таким функциям, как обработка в памяти и отложенная оценка.
Apache Spark — ведущая платформа для крупномасштабного SQL, пакетной обработки, потоковой обработки и машинного обучения. Для кодирования в Apache Spark у вас есть возможность использовать разные языки программирования (включая Java, Scala, Python, R и SQL). Он может работать локально на одной машине или в кластере компьютеров для распределения своих задач.
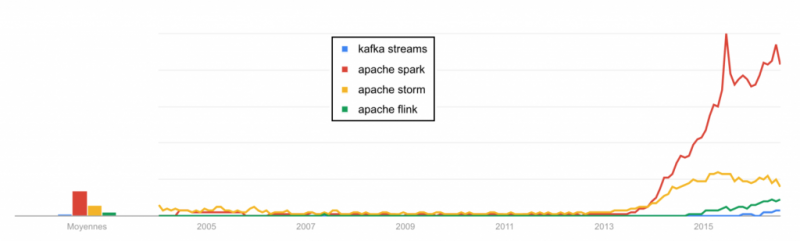
Как видно на приведенной выше диаграмме данных тенденций Google, есть альтернативы. Но Apache Spark определенно зарекомендовал себя как лидер в области инструментов распределенных вычислений.
OVHcloud — лидер европейских хостинговых и облачных провайдеров с широким спектром облачных сервисов, таких как публичное и частное облако, управляемый Kubernetes и облачное хранилище. Но помимо всех услуг хостинга и облачных сервисов, OVHcloud также предоставляет ряд услуг для анализа больших данных и искусственного интеллекта, а также платформ.
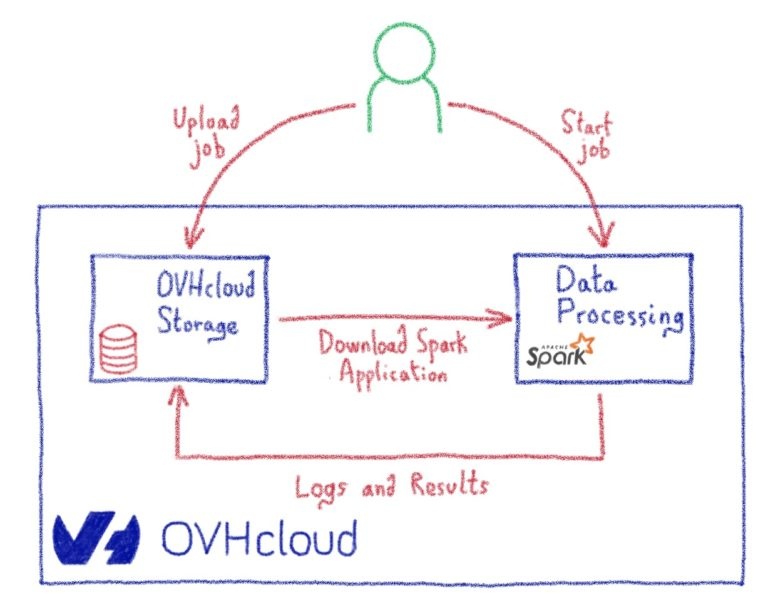
Одной из услуг обработки данных, предлагаемой OVHcloud, является обработка данных OVHcloud (ODP). Это служба, которая позволяет отправлять задание на обработку, не беспокоясь о кластере, стоящем за ним. Вам просто нужно указать ресурсы, необходимые для работы, и служба абстрагирует создание кластера и уничтожит его для вас, как только ваша работа будет завершена. Другими словами, вам больше не нужно думать о кластерах. Решите, сколько ресурсов вам понадобится для эффективной обработки данных, а затем позвольте OVHcloud Data Processing сделать все остальное.
Кластеры Spark для конкретных задач по запросу
Служба развернет временный кластер Apache Spark для конкретного задания, а затем автоматически настроит и защитит его. Вам не нужно иметь никаких предварительных знаний или навыков, связанных с облаком, сетями, системами управления кластерами, безопасностью и т. Д. Вам нужно только сосредоточиться на своем алгоритме обработки и коде Apache Spark.
Эта служба загрузит ваш код Apache Spark из одного из ваших контейнеров объектного хранилища и спросит вас, сколько ОЗУ и ядер ЦП вы хотели бы использовать в своей работе. Вам также нужно будет указать регион, в котором будет выполняться обработка. И последнее, но не менее важное: затем вам нужно будет выбрать версию Apache Spark, которую вы хотите использовать для запуска вашего кода. После этого служба запустит ваше задание в течение нескольких секунд в соответствии с указанными параметрами до его завершения. Больше нечего делать с твоей стороны. Ни создания кластера, ни разрушения кластера. Просто сосредоточьтесь на своем коде.
Ресурсы вашего локального компьютера больше не ограничивают объем данных, которые вы можете обработать. Вы можете запускать любое количество заданий обработки параллельно в любом регионе и любой версии Spark. Это также очень быстро и очень просто.
На вашей стороне Вам просто необходимо:
Это разные шаги, которые происходят при запуске задания обработки на платформе OVHcloud Data Processing (ODP):
Есть три различных способа отправить задание на обработку в ODP, в зависимости от ваших требований. Этими тремя способами являются OVHcloud Manager, OVHcloud API и CLI (интерфейс командной строки).
1. OVHcloud Manager
Чтобы отправить задание с помощью OVHcloud Manager, вам необходимо перейти на OVHcloud.com и войти в свою учетную запись OVHcloud (или создать ее, если необходимо). Затем перейдите на страницу «Общедоступное облако», выберите ссылку «Обработка данных» на левой панели и отправьте задание, нажав «Начать новое задание».
Перед отправкой задания вам необходимо создать контейнер в OVHcloud Object Storage, щелкнув ссылку «Object Storage» на левой панели и загрузить свой код Apache Spark и любые другие необходимые файлы.
2. OVHcloud API
Вы можете отправить задание в ODP с помощью OVHcloud API. Для получения дополнительной информации вы можете посетить веб-страницу API OVHcloud api.ovh.com/. Вы можете создать автоматизацию отправки заданий с помощью ODP API.
3. ODP CLI (интерфейс командной строки)
ODP имеет интерфейс командной строки с открытым исходным кодом, который вы можете найти в общедоступном GitHub OVH по адресу github.com/ovh/data-processing-spark-submit ). Используя CLI, вы можете загружать свои файлы и коды и создавать кластер Apache Spark с помощью всего одной команды.
Вы можете всегда запускать задачи обработки на локальном компьютере или создать кластер Apache Spark в своем локальном офисе с любым поставщиком облачных услуг. Это означает, что вы можете управлять этим кластером самостоятельно или используя аналогичные сервисы других конкурентов. Но у ODP есть несколько преимуществ, хорошо иметь их в виду, принимая решение:
С развитием новых технологий и устройств нас наводняют данные. Для бизнеса и научных исследований все более важно обрабатывать наборы данных и понимать, в чем заключается ценность. Предоставляя услугу обработки данных OVHcloud (ODP), наша цель — предоставить вам одну из самых простых и эффективных платформ для обработки ваших данных. Просто сосредоточьтесь на своем алгоритме обработки, а все остальное ODP сделает за вас.
Также существует понятие «исчерпание данных», которое является побочным продуктом онлайн-активности людей. Это данные, которые создаются в результате посещения кем-то веб-сайта, покупки продукта или поиска чего-либо с помощью поисковой системы. Возможно, вы слышали, что эти данные называются метаданными.
Мы начнем тонуть в потоке данных, если не научимся плавать — как извлечь выгоду из огромного количества данных. Для этого нам необходимо иметь возможность обрабатывать данные с целью принятия более эффективных решений, предотвращения мошенничества и опасностей, изобретения лучших продуктов или даже предсказания будущего. Возможности безграничны.
Но как мы можем обработать такой огромный объем данных? Конечно, по старинке сделать это невозможно. Нам необходимо модернизировать наши методы и оборудование.
Большие данные — это наборы данных, объем, скорость и разнообразие которых слишком велики для обработки на локальном компьютере. Итак, каковы требования к обработке «больших данных»?
1- Параллельная обработка данных
Данные есть везде и доступны в огромных количествах. Во-первых, давайте применим старое правило: «Разделяй и властвуй».
Разделение данных означает, что нам потребуется распределить данные и задачи обработки по нескольким компьютерам. Их нужно будет настроить в кластере, чтобы выполнять эти различные задачи параллельно и получить разумное повышение производительности и скорости.
Предположим, вам нужно было узнать, что сейчас в твиттере. Вам придется обработать около 500 миллионов твитов на одном компьютере за час. Не все так просто, правда? И как вы выиграете, если на обработку уйдет месяц? Какая ценность в том, чтобы найти тренд дня месяц спустя?
Распараллеливание — это больше, чем просто «хорошо иметь». Это требование!
2- Обработка данных в облаке
Второй шаг — это создание и эффективное управление этими кластерами.
Здесь у вас есть несколько вариантов, например, создание кластеров со своими собственными серверами и управление ими самостоятельно. Но это требует много времени и довольно дорого. В нем также отсутствуют некоторые функции, которые вы, возможно, захотите использовать, например гибкость. По этим причинам облако с каждым днем становится все лучше и лучше для многих компаний.
Эластичность, которую обеспечивают облачные решения, помогает компаниям быть гибкими и адаптировать инфраструктуру к своим потребностям. При обработке данных, например, нам нужно будет иметь возможность легко масштабировать наш вычислительный кластер, чтобы адаптировать вычислительную мощность к объему данных, которые мы хотим обработать, в соответствии с нашими ограничениями (время, затраты и т. Д.).
И тогда, даже если вы решите использовать облачного провайдера, у вас будет несколько решений на выбор, каждое из которых имеет свои недостатки. Одно из этих решений — создать вычислительный кластер на выделенных серверах или экземплярах общедоступного облака и отправить в кластер различные задания по обработке. Главный недостаток этого решения заключается в том, что если обработка не выполняется, вы все равно платите за зарезервированные, но неиспользуемые ресурсы обработки.
Поэтому более эффективным способом было бы создать выделенный кластер для каждого задания обработки с соответствующими ресурсами для этого задания, а затем удалить кластер после этого. Каждое новое задание будет иметь собственный кластер нужного размера, порожденный по запросу. Но это решение было бы возможным, только если бы создание вычислительного кластера заняло всего несколько секунд, а не минуты или часы.
Местоположение данных
При создании обрабатывающего кластера также можно учитывать локальность данных. Здесь облачные провайдеры обычно предлагают несколько регионов, разбросанных по центрам обработки данных, расположенным в разных странах. У него два основных преимущества:
Первый не связан напрямую с местонахождением данных, это скорее юридический вопрос. В зависимости от того, где находятся ваши клиенты и ваши данные, вам может потребоваться соблюдать местные законы и правила о конфиденциальности данных. Возможно, вам придется хранить свои данные в определенном регионе или стране и не иметь возможности обрабатывать их за пределами страны. Таким образом, чтобы создать кластер компьютеров в этом регионе, проще обрабатывать данные, соблюдая местные политики конфиденциальности.
Второе преимущество — это, конечно, возможность создавать кластеры обработки в непосредственной близости от ваших данных. По оценкам, к 2025 году почти 50 процентов данных в мире будут храниться в облаке. Объем локального хранения данных сокращается.
Следовательно, использование облачных провайдеров, имеющих несколько регионов, дает компаниям преимущество наличия кластеров обработки рядом с их физическим расположением данных — это значительно сокращает время (и затраты!), Необходимое для получения данных.
Хотя обработка ваших данных в облаке может и не быть требованием сама по себе, это, безусловно, более выгодно, чем делать это самостоятельно.
3- Обработка данных с помощью наиболее подходящей технологии распределенных вычислений
Третий и последний шаг — решить, как вы собираетесь обрабатывать свои данные, то есть с помощью каких инструментов. Опять же, вы можете сделать это самостоятельно, реализовав механизм распределенной обработки на любом языке по вашему выбору. Но где в этом веселье? (хорошо, для некоторых из нас это может быть довольно весело!)
Но это было бы астрономически сложно. Вам нужно будет написать код, чтобы разделить данные на несколько частей и отправить каждую часть на компьютер в вашем кластере. Затем каждый компьютер будет обрабатывать свою часть данных, и вам нужно будет найти способ получить результаты каждой части и повторно собрать все в согласованный результат. Короче говоря, потребовалось бы много работы с большим количеством отладки.
Apache Spark
Но есть технологии, которые были разработаны специально для этого. Они автоматически распределяют данные и обрабатывают задачи и получают результаты за вас. В настоящее время самой популярной технологией распределенных вычислений, особенно применительно к предметам Data Science, является Apache Spark.
Apache Spark — это распределенная среда кластерных вычислений с открытым исходным кодом. Он намного быстрее, чем предыдущий, Hadoop MapReduce, благодаря таким функциям, как обработка в памяти и отложенная оценка.
Apache Spark — ведущая платформа для крупномасштабного SQL, пакетной обработки, потоковой обработки и машинного обучения. Для кодирования в Apache Spark у вас есть возможность использовать разные языки программирования (включая Java, Scala, Python, R и SQL). Он может работать локально на одной машине или в кластере компьютеров для распределения своих задач.
Как видно на приведенной выше диаграмме данных тенденций Google, есть альтернативы. Но Apache Spark определенно зарекомендовал себя как лидер в области инструментов распределенных вычислений.
Обработка данных OVHcloud (ODP)
OVHcloud — лидер европейских хостинговых и облачных провайдеров с широким спектром облачных сервисов, таких как публичное и частное облако, управляемый Kubernetes и облачное хранилище. Но помимо всех услуг хостинга и облачных сервисов, OVHcloud также предоставляет ряд услуг для анализа больших данных и искусственного интеллекта, а также платформ.
Одной из услуг обработки данных, предлагаемой OVHcloud, является обработка данных OVHcloud (ODP). Это служба, которая позволяет отправлять задание на обработку, не беспокоясь о кластере, стоящем за ним. Вам просто нужно указать ресурсы, необходимые для работы, и служба абстрагирует создание кластера и уничтожит его для вас, как только ваша работа будет завершена. Другими словами, вам больше не нужно думать о кластерах. Решите, сколько ресурсов вам понадобится для эффективной обработки данных, а затем позвольте OVHcloud Data Processing сделать все остальное.
Кластеры Spark для конкретных задач по запросу
Служба развернет временный кластер Apache Spark для конкретного задания, а затем автоматически настроит и защитит его. Вам не нужно иметь никаких предварительных знаний или навыков, связанных с облаком, сетями, системами управления кластерами, безопасностью и т. Д. Вам нужно только сосредоточиться на своем алгоритме обработки и коде Apache Spark.
Эта служба загрузит ваш код Apache Spark из одного из ваших контейнеров объектного хранилища и спросит вас, сколько ОЗУ и ядер ЦП вы хотели бы использовать в своей работе. Вам также нужно будет указать регион, в котором будет выполняться обработка. И последнее, но не менее важное: затем вам нужно будет выбрать версию Apache Spark, которую вы хотите использовать для запуска вашего кода. После этого служба запустит ваше задание в течение нескольких секунд в соответствии с указанными параметрами до его завершения. Больше нечего делать с твоей стороны. Ни создания кластера, ни разрушения кластера. Просто сосредоточьтесь на своем коде.
Ресурсы вашего локального компьютера больше не ограничивают объем данных, которые вы можете обработать. Вы можете запускать любое количество заданий обработки параллельно в любом регионе и любой версии Spark. Это также очень быстро и очень просто.
Как это работает?
На вашей стороне Вам просто необходимо:
- Создайте контейнер в OVHcloud Object Storage и загрузите в этот контейнер код Apache Spark и любые другие необходимые файлы. Будьте осторожны, чтобы не помещать свои данные в один и тот же контейнер, так как весь контейнер будет загружен службой.
- Затем вам нужно определить механизм обработки (например, Apache Spark) и его версию, а также географический регион и количество необходимых ресурсов (ядер ЦП, ОЗУ и количество рабочих узлов). Есть три разных способа выполнить это (панель управления OVHcloud, API или ODP CLI)
Это разные шаги, которые происходят при запуске задания обработки на платформе OVHcloud Data Processing (ODP):
- ODP возьмет на себя управление развертыванием и выполнением вашей работы в соответствии с заданными вами спецификациями.
- Перед тем как начать работу, ODP загрузит все файлы, которые вы загрузили в указанный контейнер.
- Затем ODP выполнит вашу работу в специальной среде, созданной специально для вашей работы. Помимо ограничения на доступные порты (список доступен здесь ), ваша работа может затем подключиться к любому источнику данных (базам данных, хранилищу объектов и т. Д.) Для чтения или записи данных (если они доступны через Интернет)
- Когда задание завершено, ODP сохраняет журналы вывода выполнения в ваше объектное хранилище, а затем немедленно удаляет весь кластер.
- С вас будет взиматься плата за указанное вами количество ресурсов и только за время расчета вашего задания на поминутной основе.
Различные способы подачи заявки?
Есть три различных способа отправить задание на обработку в ODP, в зависимости от ваших требований. Этими тремя способами являются OVHcloud Manager, OVHcloud API и CLI (интерфейс командной строки).
1. OVHcloud Manager
Чтобы отправить задание с помощью OVHcloud Manager, вам необходимо перейти на OVHcloud.com и войти в свою учетную запись OVHcloud (или создать ее, если необходимо). Затем перейдите на страницу «Общедоступное облако», выберите ссылку «Обработка данных» на левой панели и отправьте задание, нажав «Начать новое задание».
Перед отправкой задания вам необходимо создать контейнер в OVHcloud Object Storage, щелкнув ссылку «Object Storage» на левой панели и загрузить свой код Apache Spark и любые другие необходимые файлы.
2. OVHcloud API
Вы можете отправить задание в ODP с помощью OVHcloud API. Для получения дополнительной информации вы можете посетить веб-страницу API OVHcloud api.ovh.com/. Вы можете создать автоматизацию отправки заданий с помощью ODP API.
3. ODP CLI (интерфейс командной строки)
ODP имеет интерфейс командной строки с открытым исходным кодом, который вы можете найти в общедоступном GitHub OVH по адресу github.com/ovh/data-processing-spark-submit ). Используя CLI, вы можете загружать свои файлы и коды и создавать кластер Apache Spark с помощью всего одной команды.
Некоторые преимущества ODP
Вы можете всегда запускать задачи обработки на локальном компьютере или создать кластер Apache Spark в своем локальном офисе с любым поставщиком облачных услуг. Это означает, что вы можете управлять этим кластером самостоятельно или используя аналогичные сервисы других конкурентов. Но у ODP есть несколько преимуществ, хорошо иметь их в виду, принимая решение:
- Не требуется никаких навыков или опыта в управлении кластером или настройке .
- Не ограничен в ресурсах и легко и быстро. (Единственное ограничение — это квота вашей облачной учетной записи)
- Модель с оплатой по мере использования с простой ценой и без скрытых затрат. (поминутная оплата)
- Определение ресурса для каждого задания (больше ресурсов не теряется по сравнению с объединенным кластером)
- Простота управления версией Apache Spark (вы выбираете версию для каждого задания, и вы даже можете иметь разные задания с разными версиями Apache Spark одновременно)
- Выбор региона (вы можете выбрать разные регионы в зависимости от местоположения данных или политики конфиденциальности данных)
- Начните обработку данных всего за несколько секунд
- Журналы в реальном времени (когда ваша работа выполняется, вы будете получать журналы в реальном времени на панели клиентов)
- Полный выходной журнал будет доступен сразу после завершения работы (некоторым конкурентам требуется несколько минут, чтобы доставить вам журналы)
- Автоматизация отправки заданий (с помощью ODP API или CLI)
- Конфиденциальность данных (OVHcloud — европейская компания, и все клиенты строго защищены европейским GDPR)
Вывод
С развитием новых технологий и устройств нас наводняют данные. Для бизнеса и научных исследований все более важно обрабатывать наборы данных и понимать, в чем заключается ценность. Предоставляя услугу обработки данных OVHcloud (ODP), наша цель — предоставить вам одну из самых простых и эффективных платформ для обработки ваших данных. Просто сосредоточьтесь на своем алгоритме обработки, а все остальное ODP сделает за вас.
0 комментариев