Декларативные интеграционные тесты в микросервисной среде

В OVHcloud группа доменных имен в настоящее время управляет в общей сложности 5 миллионами доменных имен. Чтобы справиться с этим объемом и предвидеть будущий рост, мы переводим нашу информационную систему с монолитной на архитектуру, основанную на микросервисах.
Хотя эта продолжающаяся миграция дает множество преимуществ по сравнению с монолитным подходом (наиболее очевидным является масштабируемость), по мере продвижения к нашей цели возникает несколько проблем. По своей природе микросервисы предполагают гораздо больше сетевых сообщений (в нашем случае HTTP) и имеют гораздо больше зависимостей от внешних служб; таких как базы данных, кеши, очереди и т. д. В этом контексте модульного тестирования каждой службы по отдельности недостаточно. Критически важным становится тестирование интеграции между всеми сервисами.
Мы должны быть в состоянии гарантировать, что развертывания не повлияют на то, что работало ранее, и что новые функции работают должным образом. Вот почему мы уделяем большое внимание интеграции и функциональным тестам. Для написания эффективных и релевантных тестов необходимо использовать соответствующий инструментарий. В нашем случае нам нужны инструменты, соответствующие нашим потребностям:
- Автоматизированная цепочка инструментов . Это очевидный вопрос; но автоматизация тестов значительно экономит время, поскольку позволяет нам запускать их автоматически на нашей платформе непрерывной интеграции при каждом отдельном изменении. Это также помогает нам создавать постоянно растущий набор тестов, которые действуют как цепочка без регрессии.
- Простые в запуске интеграционные тесты . Упрощение запуска интеграционных тестов, даже локально, повышает вероятность того, что команда будет их запускать, обновлять и писать в качестве подстраховки. Даже тесты, требующие нескольких взаимодействующих сервисов (базы данных, очереди, внешние API), должны легко запускаться.
- Простые в написании интеграционные тесты . Опыт разработчиков важен, команда с большей вероятностью напишет тесты, если это будет легко.
Тестирование в соответствующем масштабе
Помимо обычных модульных тестов, мы запускаем два вида тестов API. Это дает нам детализацию и охват, необходимые для безопасного развертывания.
В OVHcloud службы домена развернуты следующим образом:
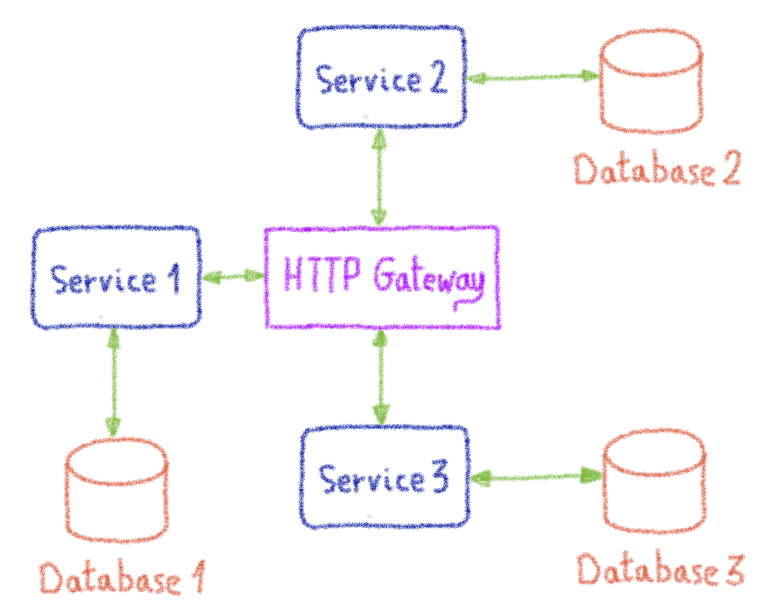
Службы общаются через центральный HTTP-шлюз, роль которого заключается в управлении маршрутизацией вызовов между службами с использованием заголовков HTTP и обеспечении безопасности. Каждый HTTP-вызов между службами проходит через шлюз.
Поскольку эти службы предоставляют API-интерфейсы через конечные точки HTTP, тестирование API является идеальным способом их тестирования. Чтобы это работало эффективно, с сервисами следует обращаться как с черными ящиками, а тесты должны использовать только их API. Но на самом деле используется тестирование серого ящика. Это связано с тем, что мы знаем детали реализации сервисов и вводим наборы данных непосредственно в базы данных перед тестированием.
Как описано на диаграмме выше, если мы хотим протестировать службу Service 1, нам требуется, чтобы была доступна среда со шлюзом и, возможно, Service 2 или Service 3. Это быстро становится трудно настроить; особенно, если требуется протестировать все сервисы.
Итак, чтобы протестировать API сервиса, нам нужен способ изолировать его от других. Это то, что мы будем называть изолированными сервисными тестами в оставшейся части сообщения в блоге.
Изолированные сервисные тесты
Изолированные сервисные тесты — это своего рода тест между модульным тестом и интеграционным тестом. Служба запускается в контролируемой среде, а ее API тестируются с помощью различных средств. В тестах изолированных сервисов мы допускаем следующие действия:
- выполнять вызовы API или отправлять события,
- манипулировать базами данных,
- делать утверждения, используя:
- ответы на вызовы API,
- события, отправленные в очереди,
- прямые запросы к базам данных.
Для этого мы запускаем службы с их техническими зависимостями (базы данных, очереди, кеши и т. Д.), Но заменяем HTTP-шлюз на фиктивный HTTP-сервер. Такой подход помогает нам избежать развертывания других сервисов и позволяет нам просто имитировать их.
Наши тесты выполняет тестовый раннер. Перед выполнением реальных тестов роль исполнителя тестов состоит в том, чтобы заполнить данные среды:
- базы данных заполняются с использованием стратегии «очистить, вставить» ,
- HTTP-макеты регистрируются на макетном сервере.
Это позволяет нам правильно сфокусировать наши тесты. Чтобы протестировать службу, нам нужно установить состояние ответов базы данных и внешних служб.
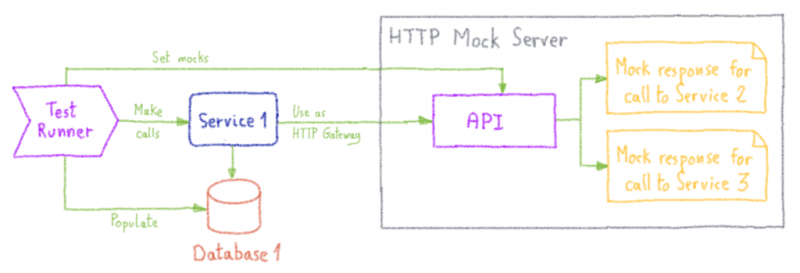
Эти тесты автоматически выполняются при каждом слиянии в промежуточной ветви службы и служат в качестве функциональных нерегрессионных тестов.
Хотя этот метод полезен, его недостаточно. Поскольку вызовы имитируются, их необходимо обновлять вручную при каждом изменении задействованных служб. Также макеты могут не совсем соответствовать действительности. Вот почему мы сочетаем его с более полными интеграционными тестами.
Интеграционные тесты
Цель этих тестов — развернуть все службы, управляемые группой доменных имен, в том же состоянии, что и в производственной среде. Мы по-прежнему используем имитирующий HTTP-сервер вместо HTTP-шлюза, потому что есть еще некоторые внешние службы, которые мы хотим имитировать. Но сервисы, принадлежащие нашей команде, не имитируются, мы их разворачиваем и регистрируем на макетном сервере как бэкенды.
Таким образом, мы можем соединить все наши сервисы вместе и имитировать только вызовы внешних сервисов.
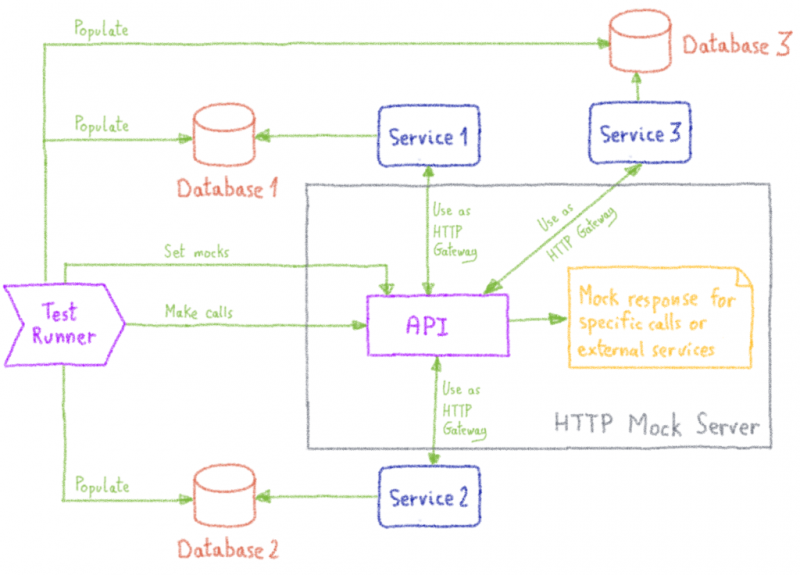
Мы используем это для тестирования сложных рабочих процессов, состоящих из нескольких обращений к различным службам. В качестве конкретного примера он позволяет нам протестировать рабочий процесс воронки заказов, сделав те же вызовы, что и воронка заказов.
Но в отличие от тестов изолированных сервисов, они выполняются только один раз в день. Это связано с тем, что для этого требуется развертывание всех наших сервисов в краткосрочной среде, непосредственно на платформе непрерывной интеграции, что может занять некоторое время.
Выполнение тестов
Технический стек
Описанный выше метод является универсальным и может применяться с использованием любых необходимых вам инструментов. Нам нужны абстрактные строительные блоки:
- тестовый бегун,
- фиктивный HTTP-сервер,
- платформа непрерывной интеграции.
Venom, средство выполнения декларативных тестов
Venom — это фреймворк для декларативного интеграционного тестирования, разработанный в OVHcloud. Venom предоставляет примитивы для выполнения HTTP-вызовов, управления базами данных и очередями сообщений и многого другого. Он также предоставляет мощный контекст для написания утверждений. Это совершенно необязательно, простые сценарии оболочки будут работать нормально, хотя они менее выразительны и их сложнее написать.
В Venom наборы тестов написаны на YAML. Это упрощает чтение и хранение наборов тестов вместе с исходным кодом тестируемой службы. Набор тестов — это просто последовательность тестовых примеров, состоящая из нескольких шагов. Шаги — это действия, последовательно выполняемые в службе или в ее среде, для которых мы можем выполнять утверждения.
name: Testing "Users" service
version: "2"
testcases:
- name: Initialize database fixtures
steps:
- type: dbfixtures
database: postgres
dsn: "{{.postgres_dsn}}"
migrations: ../../testdata/schemas
folder: ../../testdata/fixtures
- name: Try to retrieve data about user 313
steps:
- type: http
method: GET
url: "{{.service_url}}/api/v1/users/313"
assertions:
- result.statuscode ShouldEqual 200
- result.bodyjson.id ShouldEqual 313
- result.bodyjson.first_name ShouldEqual John
- result.bodyjson.last_name ShouldEqual Doe
- name: Try to update the name of user 313
steps:
# Perform the update
- type: http
method: PATCH
url: "{{.service_url}}/api/v1/users/313"
body: |
{
"first_name": "Jane",
"last_name": "Smith"
}
assertions:
- result.statuscode ShouldEqual 200
# Check that the first name and last name were correctly updated
- type: http
method: GET
url: "{{.service_url}}/api/v1/users/313"
assertions:
- result.statuscode ShouldEqual 200
- result.bodyjson.id ShouldEqual 313
- result.bodyjson.first_name ShouldEqual Jane
- result.bodyjson.last_name ShouldEqual SmithПриведенный выше набор тестов выполняет базовые тесты в службе CRUD «Пользователи». Сам набор тестов не запускает ни службу, ни ее зависимости, он предполагает, что они уже запущены.
Сначала в базу данных загружаются приборы. Это полезно для начала тестирования большинства конечных точек без необходимости вручную регистрировать их через API. Затем выполняется несколько вызовов и проверяются утверждения, чтобы убедиться, что все работает должным образом.
Убийственная особенность Venom заключается в том, что он включает в себя множество исполнителей, которые могут потребоваться для тестирования любой службы с произвольными зависимостями: необработанные скрипты, HTTP, gRPC, SQL (MySQL и PostgreSQL), Redis, Kafka (производитель и потребитель), RabbitMQ., и даже SMTP и IMAP для проверки отправки электронной почты!
Smocker, имитирующий HTTP-сервер
Как показано выше, нам нужен сервер, который может позволить нам имитировать HTTP-ответы и моделировать поведение HTTP-шлюза.

Venom позволяет нам делать утверждения о возвращаемых значениях HTTP-вызовов и о состоянии технических зависимостей. Но поскольку он не предоставляет только те функции, которые нам нужны, мы прибегаем к другому инструменту, Smocker, разработанному для нашего случая использования. Он имеет пользовательский интерфейс, который неоценим для итеративного написания макетов.
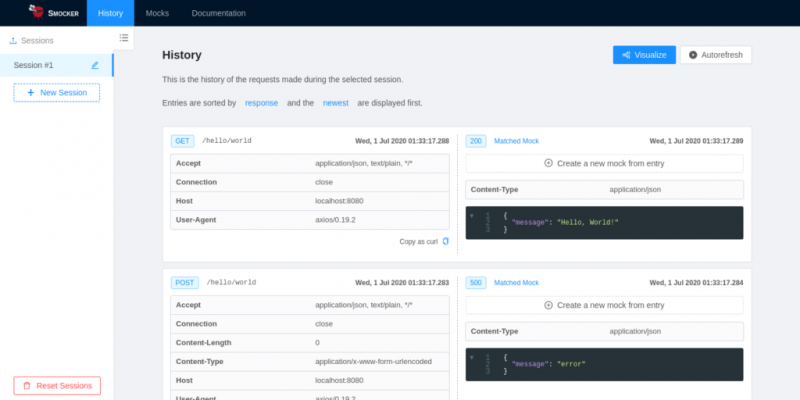
Благодаря Смокеру мы также можем выполнить еще несколько важных утверждений о внутреннем поведении нашего сервиса:
- утверждать, что вызываются правильные конечные точки,
- утверждать, что их звонили нужное количество раз,
- утверждают, что они вызываются с правильной полезной нагрузкой.
Эти функции помогают нам лучше понять внутреннюю структуру тестируемых нами сервисов и помогают нам идти в ногу с эволюцией потока выполнения.
Во-первых, им нужно зарегистрировать моки через API. Мок — это просто файл конфигурации, который инициирует отправку заданного HTTP-ответа, когда к конечной точке делается определенный вызов. У макета может быть несколько фильтров; такие как метод, путь, параметры запроса и т. д. Он также содержит некоторую контекстную информацию; включая максимальное количество звонков на маршруте, задержку ответа и т. д.
- request:
method: GET
path: /users/313
headers:
X-Service-Destination: users-service
response:
status: 200
headers:
Content-Type: application/json
body: |
{
"id": 313,
"first_name": "John",
"last_name": "Doe"
}Смокер может определять имитацию перенаправления вызовов в другое место назначения. Это позволяет имитировать работу HTTP-шлюза, определяя правильные макеты.
CDS, платформа непрерывной интеграции
CDS (служба непрерывной доставки) — это полнофункциональная платформа непрерывной доставки и автоматизации, разработанная собственными силами OVHcloud. Это мощная альтернатива другим существующим платформам; такие как Jenkins, Travis или GitLab-CI. CDS позволяет нам создавать сложные рабочие процессы выполнения, работающие в различных средах (виртуальных машинах, контейнерах).

CDS предоставляет концепцию требований, которые мы широко используем для создания экземпляра ожидаемой среды для выполнения наших тестов. Эта функция позволяет нам быстро объявлять технические услуги, которые нам понадобятся во время выполнения тестов (базы данных, очереди, кеши и т. Д.). Он очень похож, например, на раздел «услуги», доступный в файле Travis.
Собираем все вместе
Тесты хранятся вместе с исходным кодом сервисов, как правило, следующих этой иерархии:
tests/
venom/
schemas/
.sql
...
fixtures/
.yml
...
mocks/
test_suite.mocks.yml
test_suite.ymlДля каждой службы цель — иметь возможность запускать тесты локально. Шаги включают:
- настроить технические зависимости (базы данных, кеши и т. д.) и фиктивный сервер в контейнерах Docker,
- использовать переменные в файлах тестов Venom, чтобы иметь возможность манипулировать ими с помощью Venom (инициализировать наборы данных, заполнить кеш и т. д.),
- назначить фиктивный сервер нашим HTTP-шлюзом, используя переменные среды при запуске службы,
- заполните переменные Venom при запуске теста.
Набор тестов Venom может выглядеть так:
version: "2"
name: Contacts endpoints testsuite
testcases:
- name: Save a new contact successfully
steps:
- type: dbfixtures
database: postgres
dsn: "{{.pgsql_dsn}}"
migrations: ../schemas
folder: ../fixtures
- type: http
method: POST
url: "{{.mock_server}}/reset"
assertions:
- result.statuscode ShouldEqual 200
- type: http
method: POST
url: "{{.mock_server}}/mocks"
bodyFile: ./mocks/create_contact_mocks.yaml
assertions:
- result.statuscode ShouldEqual 200
- type: http
method: POST
headers:
Content-Type: application/json
url: "{{.my_app}}/contacts"
bodyFile: contact_create.json
assertions:
- result.statuscode ShouldEqual 201Веном будет:
- инициализировать базу данных, используя файлы миграции и фикстуры, доступные в / schemas и / fixtures ,
- сбросить фиктивный сервер,
- установить макеты в Smocker (макет сервера) с помощью
файла create_contact_mocks ,.yml - вызвать службу, используя файл contact_create.json в качестве полезной нагрузки, и сделать утверждения о результате.
Чтобы запустить этот тест, все, что нам нужно, это определить при запуске эти переменные Venom:
- pgsql_dsn : URL подключения к базе данных Postgres,
- mock_server : административный URL фиктивного сервера,
- my_app : URL-адрес службы для тестирования.
Эти переменные автоматически настраиваются в Makefile службы.
Локальный запуск функциональных тестов позволяет нам отлаживать наши сервисы шаг за шагом и в согласованном контексте. Поскольку наборы данных контролируются, довольно легко воспроизвести ошибки и построить эффективные нерегрессионные наборы.
После фиксации и объединения в промежуточной ветке эти тесты автоматически выполняются CDS. Он работает аналогично локальному выполнению, за исключением того, что это CDS, а не скрипт, который устанавливает технические зависимости. Служба также запускается как контейнер с использованием образа, созданного в предыдущем задании.
Как указано выше, технические зависимости, а также сервис объявлены как сервис в части требований задания CDS.
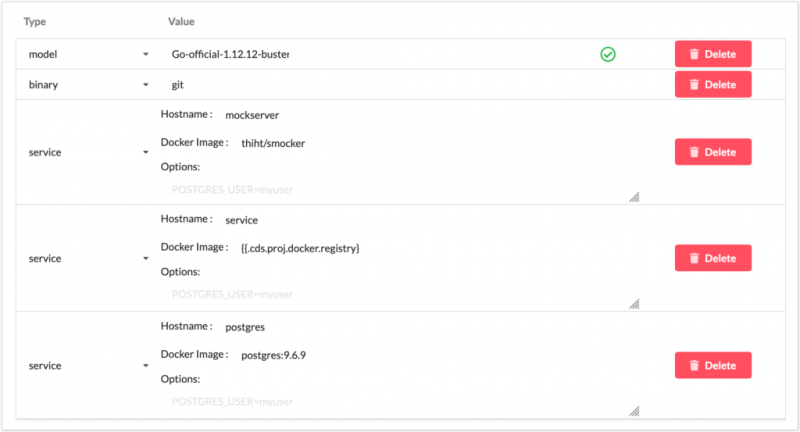
Это позволяет заполнить CDS, упомянутые выше переменные Venom следующим образом:
- pgsql_dsn : postgres: // myuser: password @ postgres / venom? sslmode = disable (пользователь, пароль и база данных устанавливаются с помощью параметров по требованию)
- mock_server : http: // mockserver: 8081 (порт администратора по умолчанию на Smocker)
- my_app : http: // myapp: 8080 (порт службы по умолчанию)
Благодаря командной строке Venom единственное, что осталось сделать в конвейере, — это выполнить тесты.
Конвейер тестирования включен в каждый из наших рабочих процессов, и развертывание в производственной среде обязательно блокируется, если какой-либо из тестов не проходит.
Ретроспектива
При настройке этих интеграционных тестов мы столкнулись с некоторыми трудностями:
- Срок изготовления был больше . Интеграционные тесты, выполняемые до того, как какое-либо развертывание помешало нам мгновенно развернуть исправления, они должны пройти тесты интеграции заранее. Это еще хуже, если исправление нарушает интеграционный тест. К счастью, в этом случае можно вручную принудительно выполнить развертывание через CDS.
- Интеграционные тесты часто довольно сложно поддерживать . Но формат YAML тестов и макетов позволяет нам комментировать их содержание, что облегчает поддержку.
Помимо этого, общий опыт использования этого метода тестирования чрезвычайно положительный .
Он добавляет дополнительную сеть безопасности для обеспечения функционального поведения сервисов в качестве нерегрессионных тестов. Более того, это позволяет нам иметь возможность заранее тестировать новые функции на нескольких сервисах с помощью обновленных макетов. И, наконец, это значительно упрощает воспроизведение функциональных ошибок и их отладку.
Стоимость, часто связанная с интеграционными тестами, может быть обескураживающей, но внедрение может быть легко выполнено постепенно, для каждой отдельной услуги.
Чтобы пойти еще дальше, сейчас мы думаем о внесении нескольких улучшений.
Покрытие кода
Наши микросервисы в основном написаны на Go. Go позволяет создать тестовый двоичный файл, включая профиль покрытия кода. Это можно использовать в дополнение к тестам Venom для генерации покрытия интеграционных тестов.
Покрытие кода — это полезная метрика, поскольку она позволяет обнаруживать участки кода, которые менее проверены.
Генерация документации
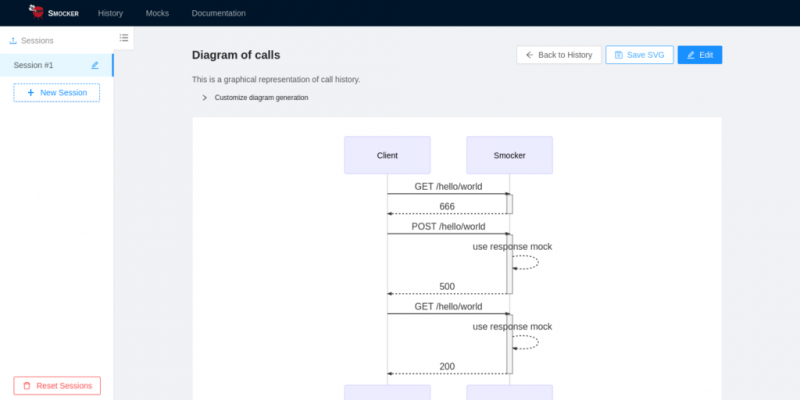
Поскольку Smocker, фиктивный HTTP-сервер, играет центральную роль в сетевом взаимодействии между сервисами, он может создавать диаграммы последовательности, описывающие поведение каждого вызова. Это можно использовать для динамического создания некоторых разделов нашей внутренней документации.
0 комментариев