Повышение качества данных с Apache Spark
Сегодня мы предлагаем вам гостевой пост от Хьюберта Стефани, директора по инновациям и соучредителя Novagen Conseil.

Как консультанты по данным и активные пользователи Apache Spark, для нас большая честь стать первыми последователями OVHcloudData Processing. В качестве первого варианта использования для тестирования этого предложения мы выбрали наш процесс оценки качества.
Как консалтинговая компания, базирующаяся в Париже, мы разрабатываем комплексные и инновационные стратегии обработки данных для наших крупных корпоративных и государственных клиентов: ведущих банков состояния, государственных органов, розничных торговцев, индустрии моды, лидеров транспорта и т. Д. Мы предлагаем им крупномасштабную бизнес-аналитику, озеро данных создание и управление, бизнес-инновации с наукой о данных. В нашей лаборатории данных мы выбираем лучшую в своем классе технологию и создаем то, что мы называем «ускорителями», то есть готовые к развертыванию или настраиваемые активы данных.
Когда дело доходит до выбора нового технологического решения, у нас есть следующий контрольный список:
Около месяца назад Бастьен Вердебаут, менеджер по продуктам OVHcloud по данным и ИИ, обратился к нам с просьбой протестировать свой новый продукт OVHcloud Data Processing, созданный на основе Apache Spark. Конечно, да!
Одна из причин, по которой мы так стремились открыть эту обработку данных в качестве сервисного решения, заключалась в том, что мы широко используем Apache Spark; это наш швейцарский армейский нож для обработки данных.
Мы постоянно разрабатываем программные активы на базе Apache Spark для решения повторяющихся проблем, таких как:
Мы рассмотрели следующие характеристики обработки данных OVHCloud :
Эти характеристики побудили нас выбрать наш процесс оценки качества в качестве идеального варианта использования, который требует как интерактивности, так и настраиваемых вычислительных ресурсов для обеспечения качественных ключевых показателей эффективности с помощью процессов Spark.

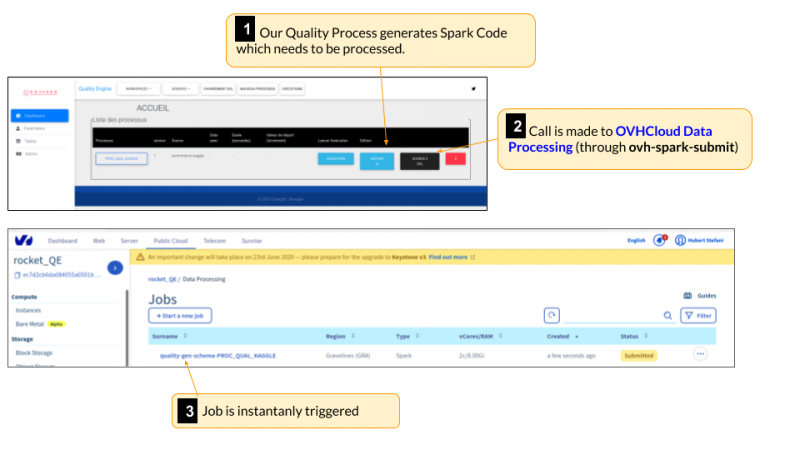
Соответствующая команда, сгенерированная нашим программным обеспечением:
У нас есть команда, которая очень похожа на обычную искру-отправку, за исключением пути к jar, который требует, чтобы двоичный файл находился в корзине объектного хранилища, к которой мы обращаемся с быстрой спецификацией URL-адреса. (NB: эта команда могла быть создана с помощью вызова API обработки данных OVHCloud).
Начиная с этого момента, мы можем теперь точно настроить наш портфель процессов и поиграть с распределением различной мощности с небольшими ограничениями (за исключением квот, назначаемых любому проекту общедоступного облака).
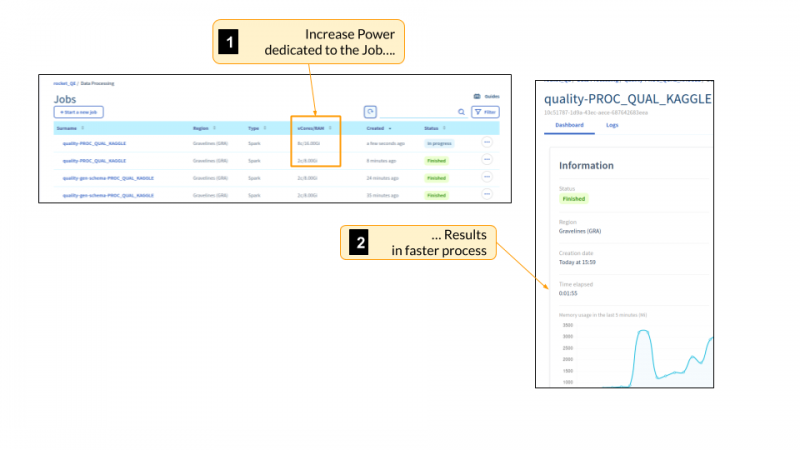
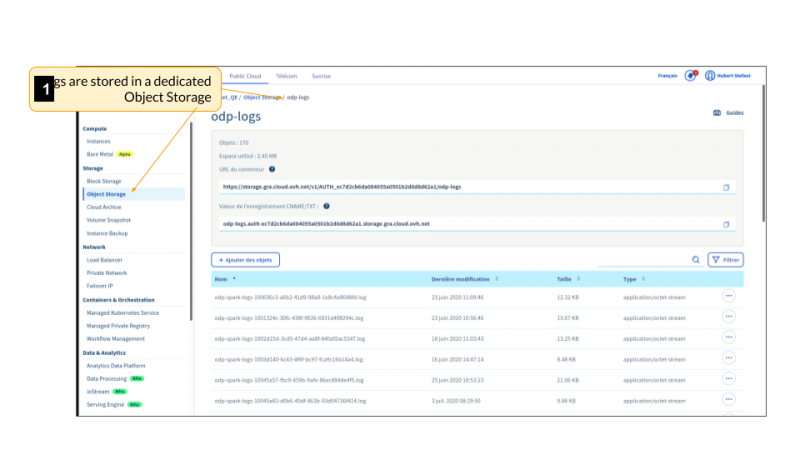
В конце концов, для настройки и посмертного анализа работы мы можем воспользоваться сохраненными файлами журнала. Примечательно, что OVHcloud Data Processing предлагает отображение журналов заданий в реальном времени, что очень удобно и обеспечивает дополнительный контроль через информационные панели Grafana.
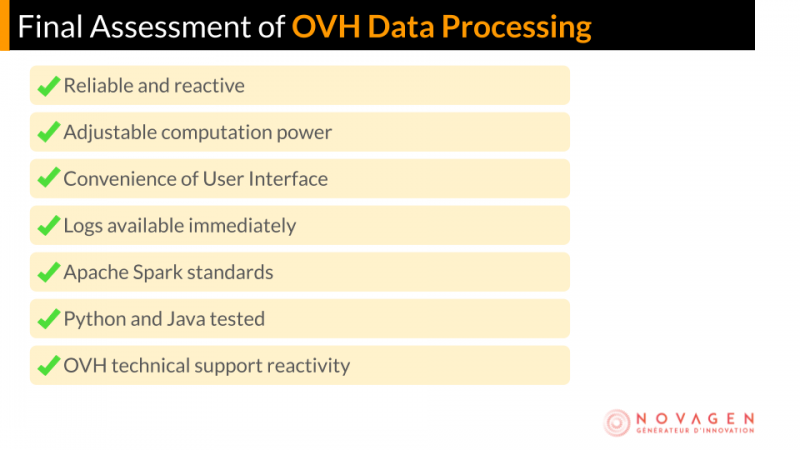
Это первый, но важный тест обработки данных OVHcloud; На данный момент он отлично подходит для варианта использования процесса качества Novagen и позволил нам подтвердить несколько важных моментов, когда дело доходит до тестирования нового решения для обработки данных:
Как консультанты по данным и активные пользователи Apache Spark, для нас большая честь стать первыми последователями OVHcloudData Processing. В качестве первого варианта использования для тестирования этого предложения мы выбрали наш процесс оценки качества.
Как консалтинговая компания, базирующаяся в Париже, мы разрабатываем комплексные и инновационные стратегии обработки данных для наших крупных корпоративных и государственных клиентов: ведущих банков состояния, государственных органов, розничных торговцев, индустрии моды, лидеров транспорта и т. Д. Мы предлагаем им крупномасштабную бизнес-аналитику, озеро данных создание и управление, бизнес-инновации с наукой о данных. В нашей лаборатории данных мы выбираем лучшую в своем классе технологию и создаем то, что мы называем «ускорителями», то есть готовые к развертыванию или настраиваемые активы данных.
Когда дело доходит до выбора нового технологического решения, у нас есть следующий контрольный список:
- Инновации и эволюционность : глубина функциональности, дополнительная ценность и удобство использования
- Производительность и рентабельность : внутренние характеристики, но также и техническая архитектура, адаптируемая к потребностям клиентов.
- Открытые стандарты и управление : для поддержки облачных или мультиоблачных стратегий наших клиентов мы предпочитаем полагаться на открытые стандарты для развертывания на различных объектах и сохранения обратимости.
Apache Spark, наш швейцарский армейский нож
Около месяца назад Бастьен Вердебаут, менеджер по продуктам OVHcloud по данным и ИИ, обратился к нам с просьбой протестировать свой новый продукт OVHcloud Data Processing, созданный на основе Apache Spark. Конечно, да!
Одна из причин, по которой мы так стремились открыть эту обработку данных в качестве сервисного решения, заключалась в том, что мы широко используем Apache Spark; это наш швейцарский армейский нож для обработки данных.
- Он работает с очень большим объемом данных,
- Он отвечает потребностям инженерии данных и науки о данных,
- Это позволяет обрабатывать данные в состоянии покоя и передавать данные в потоковом режиме.
- Это де-факто стандарт для рабочих нагрузок с данными в локальной среде и в облаке,
- Он предлагает встроенные API для Python, Scala, Java и R.
Мы постоянно разрабатываем программные активы на базе Apache Spark для решения повторяющихся проблем, таких как:
- Обработка ETL в среде озера данных,
- KPI качества поверх источников озера данных,
- Алгоритм машинного обучения для обработки естественного языка, прогнозы временных рядов…
Идеальный вариант использования: оценка качества данных
Мы рассмотрели следующие характеристики обработки данных OVHCloud :
- Механизм обработки построен на основе Apache Spark 2.4.3
- Задания запускаются через несколько секунд (против минут для запуска кластера)
- Возможность регулировать мощность, выделенную для различных заданий Spark : от низкого энергопотребления (1 драйвер и 1 исполнитель с 4 ядрами и 8 ГБ памяти) до крупномасштабной обработки (потенциальные сотни ядер и ГБ памяти)
- Полное разделение вычислений и хранилищ в соответствии со стандартом облачных архитектур , включая API-интерфейсы S3 для доступа к данным, хранящимся на уровне хранилища объектов.
- Выполнение и мониторинг заданий через интерфейс командной строки и API
Эти характеристики побудили нас выбрать наш процесс оценки качества в качестве идеального варианта использования, который требует как интерактивности, так и настраиваемых вычислительных ресурсов для обеспечения качественных ключевых показателей эффективности с помощью процессов Spark.
Обработка данных OVHCloud на работе
Соответствующая команда, сгенерированная нашим программным обеспечением:
./ovh-spark-submit --projectid ec7d2cb6da084055a0501b2d8d8d62a1 \
--class tech.novagen.spark.Launcher --driver-cores 4 --driver-memory 8G \
--executor-cores 4 --executor-memory 8G --num-executors 5 \
swift://sparkjars/QualitySparkExecutor-1.0-spark.jar --apiServer=5.1.1.2:80У нас есть команда, которая очень похожа на обычную искру-отправку, за исключением пути к jar, который требует, чтобы двоичный файл находился в корзине объектного хранилища, к которой мы обращаемся с быстрой спецификацией URL-адреса. (NB: эта команда могла быть создана с помощью вызова API обработки данных OVHCloud).
Начиная с этого момента, мы можем теперь точно настроить наш портфель процессов и поиграть с распределением различной мощности с небольшими ограничениями (за исключением квот, назначаемых любому проекту общедоступного облака).
Отображение журналов заданий в реальном времени
В конце концов, для настройки и посмертного анализа работы мы можем воспользоваться сохраненными файлами журнала. Примечательно, что OVHcloud Data Processing предлагает отображение журналов заданий в реальном времени, что очень удобно и обеспечивает дополнительный контроль через информационные панели Grafana.
Это первый, но важный тест обработки данных OVHcloud; На данный момент он отлично подходит для варианта использования процесса качества Novagen и позволил нам подтвердить несколько важных моментов, когда дело доходит до тестирования нового решения для обработки данных:
Это начало этого продукта, и мы внимательно рассмотрим его функции. Команда OVHCloud представила часть своей дорожной карты, и она выглядит многообещающей!
Хуберт Стефани, директор по инновациям Novagen Conseil
0 комментариев