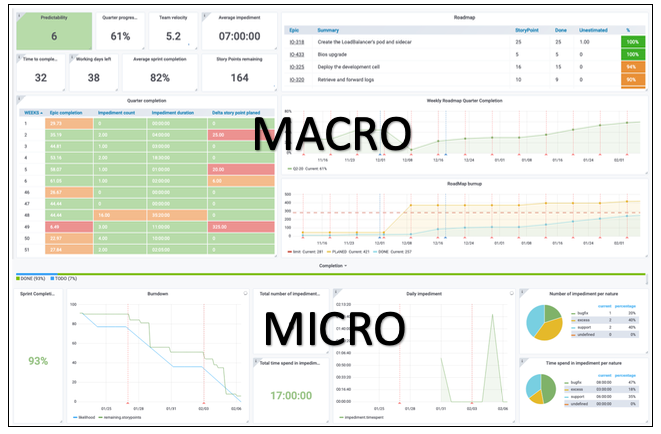
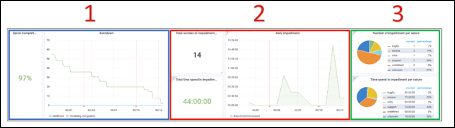
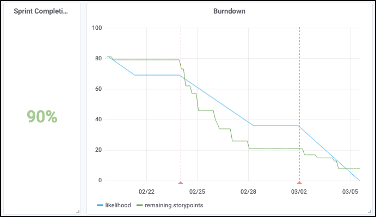
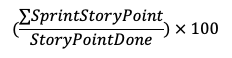OVHcloud недавно получил новое имя, чтобы подчеркнуть свою направленность: облако, чтобы дать вам возможность легко запускать свои рабочие нагрузки, не слишком заботясь о базовом оборудовании. Так зачем говорить о ПЛИС?
FPGA — это аппаратный ускоритель, реконфигурируемый чип, который может вести себя как заказной кремний, разработанный для конкретного приложения. Мы используем ПЛИС в качестве настраиваемых сетевых устройств для нашей системы защиты от атак. Но разработка ПЛИС сильно отличается от разработки программного обеспечения: она требует специализированного проприетарного программного обеспечения и длительных циклов разработки.

В этой статье я хотел бы сосредоточиться на том, как мы интегрируем разработку FPGA в рабочий процесс гибкой разработки программного обеспечения, используемый всеми другими разработчиками в OVHcloud.
Зачем использовать ПЛИС?
ПЛИС — чрезвычайно универсальные микросхемы, их можно использовать для построения схем для очень широкого круга приложений:
- обработка сигнала
- финансы
- машинное обучение (классификация)
- сеть
Их главный интерес заключается в том, что вы не ограничены архитектурой ЦП, вы можете создать свою собственную аппаратную архитектуру, адаптированную к приложению. Обычно это обеспечивает лучшую производительность, меньшее энергопотребление и меньшую задержку.
Для сетевых приложений преимущества:
- прямое подключение к каналам 100GbE: нет сетевой карты, нет канала PCIe, пакеты принимаются непосредственно на чип
- доступ к памяти с чрезвычайно низкой задержкой и очень быстрым произвольным доступом (QDR SRAM: каждый банк позволяет около 250 миллионов операций чтения и записи в секунду)
- возможность создавать собственные конвейеры обработки пакетов для максимального использования ресурсов чипа.
Это позволяет нам обрабатывать 300 миллионов пакетов в секунду и 400 Гбит / с на одной плате FPGA с потребляемой мощностью менее 70 Вт.
Чтобы узнать больше о ПЛИС, хорошим ресурсом является электронная книга ПЛИС для чайников.
Традиционный рабочий процесс разработки FPGA
Языки, используемые для разработки на ПЛИС, имеют сильную специфику: в отличие от стандартных последовательных языков все происходит параллельно, чтобы моделировать поведение миллионов транзисторов, работающих параллельно на кристалле. Используются два основных языка: VHDL и SystemVerilog. Мы используем SystemVerilog. Вот пример модуля SystemVerilog:
// Simple example module: a counter
// Will clear if clear is 1 during one clock cycle.
// Will increment at each clock cycle when enable is 1.
`timescale 1ns / 1ps
module counter
#(
// Number of bits of counter result
parameter WIDTH = 5
)
(
input clk,
// Control
input enable,
input clear,
// Result
output reg [WIDTH-1:0] count = '0
);
always_ff @(posedge clk) begin
if (clear) begin
count <= '0;
end else if (enable) begin
count <= count + 1;
end
end
endmodule
Модули можно объединять вместе, соединяя их входы и выходы для создания сложных систем.
Тестирование на тренажере
Очень важным инструментом при разработке на ПЛИС является симулятор: тестировать код непосредственно на реальной ПЛИС сложно и медленно. Чтобы ускорить процесс, симуляторы могут запускать код без специального оборудования. Они используются как для модульных тестов, чтобы протестировать каждый модуль в отдельности, так и для функциональных тестов, имитирующих всю конструкцию, контролирующих ее входы и проверяющих ее выходы. Вот результат на модуле счетчика:
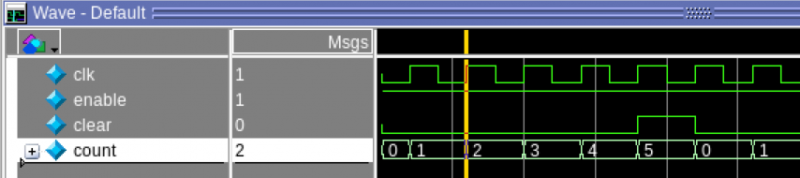
Это волна, показывающая значение каждого сигнала в каждом тактовом цикле. Конечно, симулятор также может работать без головы, и тестовая среда может быть модифицирована так, чтобы возвращать результат прошел / не прошел.
Базовый симулятор предоставляется Xilinx, производителем FPGA. Более продвинутые симуляторы предоставляются Mentor или Synopsys. Эти тренажеры являются коммерческими и требуют дорогих лицензий.
Создание двоичного файла
Как только все тесты пройдены, пора получить двоичный файл, который можно использовать для настройки FPGA. Крупнейшие поставщики FPGA, Intel и Xilinx, предоставляют собственные инструменты для этого процесса. Первый этап, синтез, преобразует исходный код в схему. Вторая фаза, «место и маршрут», представляет собой очень сложную задачу оптимизации, чтобы подогнать схему к ресурсам, предоставляемым ПЛИС, при соблюдении временных ограничений, чтобы схема могла работать на желаемой частоте. Это может длиться несколько часов, даже до одного дня для очень сложных конструкций. Этот процесс может завершиться неудачно, если дизайн чрезмерно ограничен, поэтому обычно приходится запускать несколько процессов с разными начальными числами, чтобы иметь больше шансов получить рабочий двоичный файл в конце.
Наш текущий рабочий процесс разработки FPGA
Наш текущий процесс разработки очень близок к традиционному. Но обычно разработка FPGA намного медленнее, чем разработка программного обеспечения. В OVHcloud мы можем разработать и отправить небольшую функцию за один день. Мы достигаем этого, используя рабочий процесс, используемый разработчиками программного обеспечения, и нашу облачную инфраструктуру. Вот глобальный рабочий процесс:
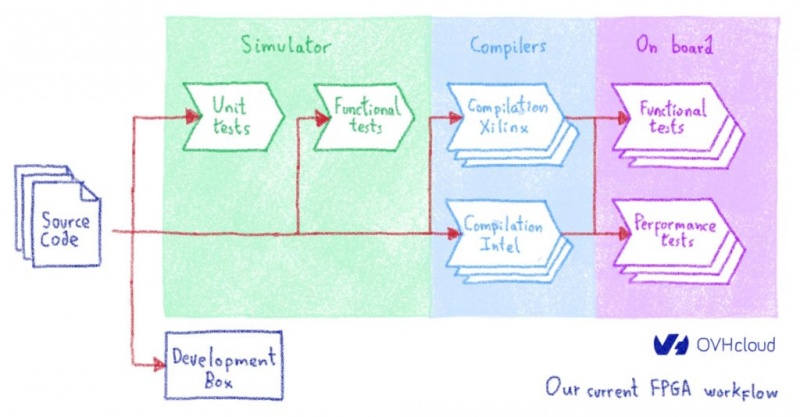
Весь рабочий процесс контролируется CDS, нашей системой непрерывной доставки с открытым исходным кодом. Все тесты, а также задания компиляции выполняются в публичном облаке, за исключением бортовых тестов, которые выполняются в нашей лаборатории.
Использование нашего публичного облака
Настройка всех машин выполняется Ansible. Есть несколько важных ролей для установки различных важных компонентов:
- симулятор
- компилятор Xilinx, Vivado
- компилятор Intel, Quartus
- сервер лицензий для симулятора и компиляторов
Сервер лицензий, а также блоки разработки — это давно работающие экземпляры общедоступного облака. Сервер лицензий — это наименьший из возможных экземпляров, ящик для разработки — это экземпляр с быстрым процессором и большим объемом оперативной памяти. Симулятор и компиляторы устанавливаются на модуле разработки. Авторизациями для доступа к серверу лицензий управляют группы безопасности OpenStack.
Экземпляры, используемые для моделирования тестов и для компиляции, при необходимости запускаются с использованием OpenStack API. Это очень важно, поскольку позволяет запускать несколько наборов тестов параллельно для разных разработчиков. Это также очень важно для составления. Мы компилируем наши проекты для нескольких целей (ПЛИС Stratix V для 10 Гбайт и ПЛИС Ultrascale + для 100 Гбайт), поэтому нам необходимо выполнять несколько заданий компиляции параллельно. Кроме того, мы запускаем задания параллельно с несколькими начальными числами, чтобы повысить наши шансы получить правильный двоичный файл. Поскольку сборка наших проектов может длиться 12 часов, очень важно начать достаточно параллельно, чтобы быть уверенным, что мы получим хотя бы один рабочий двоичный файл.
Запуск тестов
Функциональные тесты очень важны, потому что они проверяют каждую функцию, предоставляемую нашими проектами. Тесты разработаны на Python с использованием scapy для отправки трафика и анализа результатов. Они могут работать как с имитацией проекта, так и с реальным дизайном на реальных платах FPGA. CDS может автоматически запускать тесты на реальных платах, зарезервировав лабораторные серверы и подключившись к ним через SSH. Тот же процесс используется для тестов производительности.
Результатом такой инфраструктуры является то, что разработчики могут разместить новую функцию в ветке нашего репозитория git, и они получат полные результаты модульных и функциональных тестов через 30 минут. Если все в порядке, они могут запустить компиляцию и проверить результат на борту на следующий день. Затем им просто нужно пометить новую версию пакета, чтобы появилась новая версия. После этого команда, управляющая производством, может развернуть новую версию с помощью ansible.
Идти дальше
Мы максимально автоматизировали наш процесс и используем инфраструктуру общедоступного облака для ускорения рабочего процесса. Но в настоящее время мы все еще используем вполне традиционный процесс разработки FPGA. Существует множество различных подходов для дальнейшего развития, и, поскольку мы хотим приблизить процесс разработки FPGA к разработке программного обеспечения, мы рассмотрели многие из них.
HLS
Очень распространенный подход — использовать синтез высокого уровня (HLS). Он заключается в использовании языка высокого уровня для разработки модулей вместо SystemVerilog. С Vivado HLS можно разрабатывать на C ++. Также возможно использование OpenCL, который мы протестировали на платах Intel. Принцип HLS состоит в том, чтобы извлечь алгоритм из кода высокого уровня, а затем автоматически построить лучшую конвейерную архитектуру на FPGA. Но мы занимаемся обработкой пакетов, наши алгоритмы очень простые. Сложность нашего кода заключается в самой архитектуре, позволяющей поддерживать очень высокие скорости передачи данных. Таким образом, мы не смогли эффективно использовать HLS, код, который мы получили, был на самом деле более сложным, чем та же функция в SystemVerilog.
Долото
SystemVerilog является чрезвычайно низкоуровневым и не позволяет использовать высокий уровень абстракций (по крайней мере, если вы хотите, чтобы код можно было использовать компиляторами Intel и Xilinx). Что нам действительно нужно для упрощения разработки, так это возможность использовать более высокие уровни абстракции. Нам не нужен сложный компилятор, чтобы попытаться угадать лучшую архитектуру. Для этого у нас есть аспирант, который в настоящее время участвует в проекте с открытым исходным кодом: Chisel.
Chisel — это язык проектирования оборудования, основанный на Scala. Его главный интерес заключается в том, что он позволяет использовать весь уровень абстракции, предлагаемый Scala, для описания оборудования. Это также полностью открытый код, что очень необычно в мире разработки оборудования. Для тестирования он использует Verilator, симулятор с открытым исходным кодом. Это означает, что мы можем избавиться от проприетарных симуляторов и иметь полностью открытый набор инструментов, вплоть до компиляции.
В настоящее время нет инструментов с открытым исходным кодом для фазы размещения и маршрута, по крайней мере, на самых последних ПЛИС Xilinx и Intel. Но Chisel может генерировать Verilog, который может использоваться проприетарными компиляторами.
Мы планируем в ближайшее время использовать в производстве наши первые модули, разработанные в Chisel. Это должно помочь нам получить более удобный для повторного использования код и постепенно избавиться от проприетарных инструментов.
Смена парадигмы
Сообщество с открытым исходным кодом чрезвычайно важно для того, чтобы сделать разработку FPGA все ближе и ближе к разработке программного обеспечения. Признаком улучшения является постепенное появление ПЛИС начального уровня в FabLabs и проектах электроники для хобби. Мы надеемся, что Xilinx и Intel FPGA последуют за ними, и что однажды они перейдут на открытый исходный код для своих компиляторов, что может сделать их более эффективными и совместимыми. ПЛИС — это ускорители, которые предлагают невероятную гибкость и могут быть мощной альтернативой центральным и графическим процессорам, но для демократизации их использования в облачных средах сообществу открытого исходного кода необходимо стать намного сильнее.