Оповещение на основе сбора данных IPMI
Проблема, которую нужно решить…
Как постоянно контролировать работоспособность всех серверов OVH, не влияя на их производительность и не вторгаясь в операционные системы, работающие на них — вот вопрос, который необходимо решить. Конечная цель этого сбора данных — позволить нам обнаруживать и прогнозировать потенциальные отказы оборудования, чтобы улучшить качество обслуживания, предоставляемого нашим клиентам.
Мы начали с разделения проблемы на четыре основных этапа:
- Сбор информации
- Хранилище данных
- Аналитика данных
- Визуализация / действия
Сбор информации
Как мы незаметно собирали большие объемы данных о состоянии серверов за короткие промежутки времени?
Какие данные собирать?
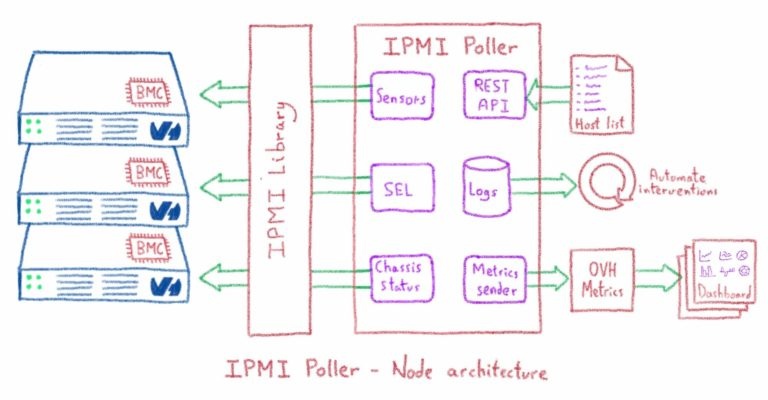
На современных серверах BMC (контроллер управления платой) позволяет нам контролировать обновления прошивки, перезагрузки и т. Д. Этот контроллер не зависит от системы, работающей на сервере. Кроме того, BMC дает нам доступ к датчикам для всех компонентов материнской платы через шину I2C. Для связи с BMC используется протокол IPMI, доступный через LAN (RMCP).
Что такое IPMI?
- Интеллектуальный интерфейс управления платформой.
- Возможности управления и мониторинга независимо от ОС хоста.
- Под руководством INTEL, впервые опубликовано в 1998 году.
- Поддерживается более чем 200 поставщиками компьютерных систем, такими как Cisco, DELL, HP, Intel, SuperMicro…
Зачем использовать IPMI?
- Доступ к аппаратным датчикам (температура процессора, температура памяти, состояние шасси, мощность и т. Д.).
- Отсутствие зависимости от ОС (т.е. безагентное решение)
- Функции IPMI доступны после сбоя ОС / системы
- Ограниченный доступ к функциям IPMI через права пользователя
Сбор данных из нескольких источников
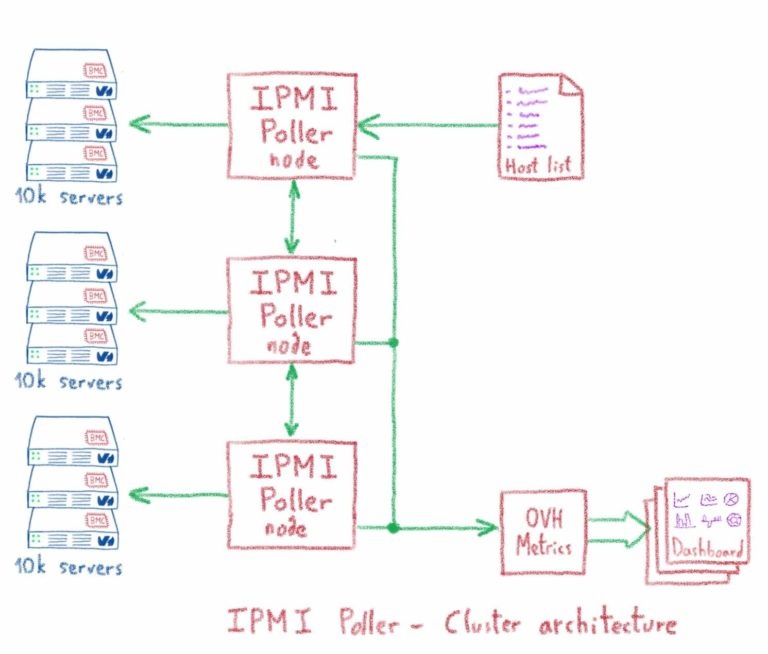
Нам был нужен масштабируемый и быстро реагирующий инструмент сбора данных из нескольких источников, чтобы получать данные IPMI примерно с 400 тыс. Серверов через фиксированные интервалы.

Мы решили построить наш сборщик данных IPMI на платформе Akka. Akka — это набор инструментов и среда выполнения с открытым исходным кодом, упрощающие создание параллельных и распределенных приложений на JVM.
Фреймворк Akka определяет построенную над потоком абстракцию под названием «актер». Этот субъект — это объект, который обрабатывает сообщения. Эта абстракция упрощает создание многопоточных приложений, поэтому нет необходимости бороться с тупиками. Выбрав политику диспетчера для группы субъектов, вы можете настроить приложение, чтобы оно было полностью реактивным и адаптировалось к нагрузке. Таким образом, мы смогли разработать эффективный сборщик данных, который мог адаптироваться к нагрузке, поскольку мы намеревались получать значение каждого датчика каждую минуту.
Кроме того, кластерная архитектура, предоставляемая фреймворком, позволила нам обрабатывать все серверы в центре обработки данных с помощью одного кластера. Кластерная архитектура также помогла нам разработать отказоустойчивую систему, поэтому, если узел кластера выйдет из строя или станет слишком медленным, он автоматически перезапустится. Серверы, отслеживаемые отказавшим узлом, затем обрабатываются оставшимися действительными узлами кластера.
В кластерной архитектуре мы реализовали функцию кворума, чтобы отключить весь кластер, если не достигнуто минимальное количество запущенных узлов. С помощью этой функции мы можем легко решить проблему разделения мозга, так как при разрыве соединения между узлами кластер будет разделен на два объекта, а тот, который не достиг кворума, будет автоматически отключен.
REST API определен для связи со сборщиком данных двумя способами:
- Отправить конфигурации
- Для получения информации об отслеживаемых серверах
Узел кластера работает на одной JVM, и мы можем запустить один или несколько узлов на выделенном сервере. Каждый выделенный сервер, используемый в кластере, помещается в OVH VRACK. Пул шлюзов IPMI используется для доступа к BMC каждого сервера, при этом связь между шлюзом и сборщиком данных IPMI защищена соединениями IPSEC.
Хранилище данных

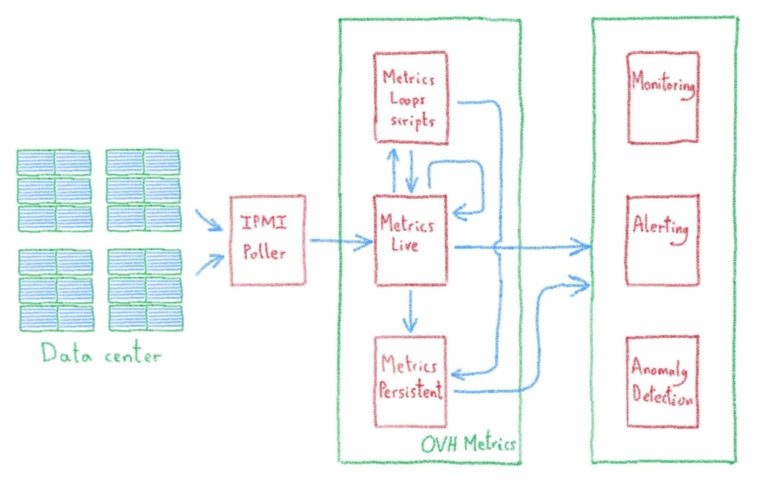
Разумеется, для хранения данных мы используем сервис OVH Metrics! Перед сохранением данных коллектор данных IPMI унифицирует показатели, квалифицируя каждый датчик. Окончательное название метрики определяется сущностью, к которой принадлежит датчик, и базовой единицей значения. Это упростит процессы последующей обработки и визуализацию / сравнение данных.
Каждый коллектор IPMI центра обработки данных отправляет свои данные на сервер кэширования в реальном времени Metrics с ограниченным временем сохранения. Вся важная информация сохраняется на сервере метрик OVH.
Аналитика данных

Мы храним наши метрики в warp10. Warp 10 поставляется с языком сценариев временных рядов: WarpScript, который пробуждает мощную аналитику, позволяющую легко манипулировать и постобработать (на стороне сервера) наши собранные данные.
Мы определили три уровня анализа для мониторинга работоспособности серверов:
- Простая метрика порогового значения на сервер.
- Используя службу метрических циклов OVH, мы собираем данные по стойке и по комнате и вычисляем среднее значение. Мы устанавливаем порог для этого среднего значения, это позволяет обнаруживать общие неисправности стоек или помещения в системе охлаждения или питания.
- Служба OVH MLS выполняет обнаружение некоторых аномалий в стойках и помещениях, прогнозируя возможное изменение показателей в зависимости от прошлых значений. Если значение метрики находится за пределами этого шаблона, возникает аномалия.
Визуализация / действия
Все предупреждения, генерируемые анализом данных, помещаются в TAT, который является инструментом OVH, который мы используем для обработки потока предупреждений.


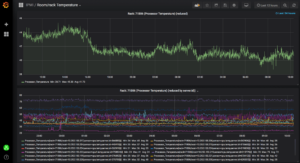
Grafana используется для мониторинга показателей. У нас есть информационные панели для визуализации показателей и агрегирования для каждой стойки и комнаты, обнаруженных аномалий и эволюции открытых предупреждений.