Плюсы и минусы IPMI
Что такое IPMI? Какова цель IPMI? Зачем мне нужен IPMI? Все это справедливые вопросы. В мире хостинг-провайдеров IPMI или (интерфейс интеллектуального управления платформой) используется почти так же, как «SDDC (программно-определяемый центр обработки данных)» или «IaaS (инфраструктура как услуга)», но что это означает и почему вы должны забота?
IPMI был создан в результате сотрудничества между Intel, Dell, Hewlett Packard и NEC. С момента своего создания он стал отраслевым стандартом как важное аппаратное решение, которое позволяет администраторам серверов отслеживать состояние оборудования, регистрировать данные сервера и разрешать доступ к серверу без физического доступа к серверу. Получая доступ к серверу через IPMI, вам предоставляется доступ к BIOS системы, наличие этого доступа позволяет вам установить или переустановить вашу собственную операционную систему, исправить любые ошибки в конфигурации сети или повторно включить доступ по SSH или RDP с помощью KVM (Keyboard Video Mouse) доступ к сервер.
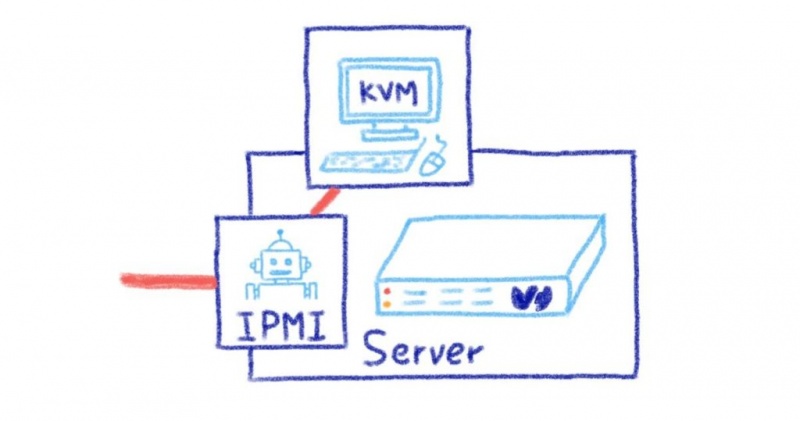
Используя инфраструктуру OVHcloud®, вы сможете использовать IPMI и получить доступ к BIOS вашего сервера. Это позволяет вам быть эффективным администратором сервера и устранять любые проблемы, которые могут возникнуть с вашим сервером, а также устанавливать любую операционную систему, совместимую с компонентами вашего сервера.
В OVHcloud для нас важно, чтобы у наших клиентов была свобода и гибкость для инновационных решений любой задачи или проблемы, которую они видят перед собой; использование IPMI — это один из способов предоставить нашим клиентам такую свободу.
Чтобы узнать больше о том, как получить доступ к IPMI из OVHcloud Manager и как установить операционную систему, использующую IPMI, обратитесь к следующим руководствам, которые шаг за шагом проведут вас через процесс: Начало работы с IPMI, Как установить ОС с IPMI.
IPMI был создан в результате сотрудничества между Intel, Dell, Hewlett Packard и NEC. С момента своего создания он стал отраслевым стандартом как важное аппаратное решение, которое позволяет администраторам серверов отслеживать состояние оборудования, регистрировать данные сервера и разрешать доступ к серверу без физического доступа к серверу. Получая доступ к серверу через IPMI, вам предоставляется доступ к BIOS системы, наличие этого доступа позволяет вам установить или переустановить вашу собственную операционную систему, исправить любые ошибки в конфигурации сети или повторно включить доступ по SSH или RDP с помощью KVM (Keyboard Video Mouse) доступ к сервер.
Используя инфраструктуру OVHcloud®, вы сможете использовать IPMI и получить доступ к BIOS вашего сервера. Это позволяет вам быть эффективным администратором сервера и устранять любые проблемы, которые могут возникнуть с вашим сервером, а также устанавливать любую операционную систему, совместимую с компонентами вашего сервера.
В OVHcloud для нас важно, чтобы у наших клиентов была свобода и гибкость для инновационных решений любой задачи или проблемы, которую они видят перед собой; использование IPMI — это один из способов предоставить нашим клиентам такую свободу.
Чтобы узнать больше о том, как получить доступ к IPMI из OVHcloud Manager и как установить операционную систему, использующую IPMI, обратитесь к следующим руководствам, которые шаг за шагом проведут вас через процесс: Начало работы с IPMI, Как установить ОС с IPMI.