Проекты машинного обучения становятся все более важным компонентом сегодняшнего поиска более эффективных и сложных производственных процессов. OVH Prescience — это платформа машинного обучения, которая призвана облегчить концепцию, развертывание и обслуживание моделей в промышленном контексте. Система управляет конвейерами машинного обучения, от приема данных до мониторинга модели. Это включает автоматизацию предварительной обработки данных, выбора модели, оценки и развертывания на масштабируемой платформе.
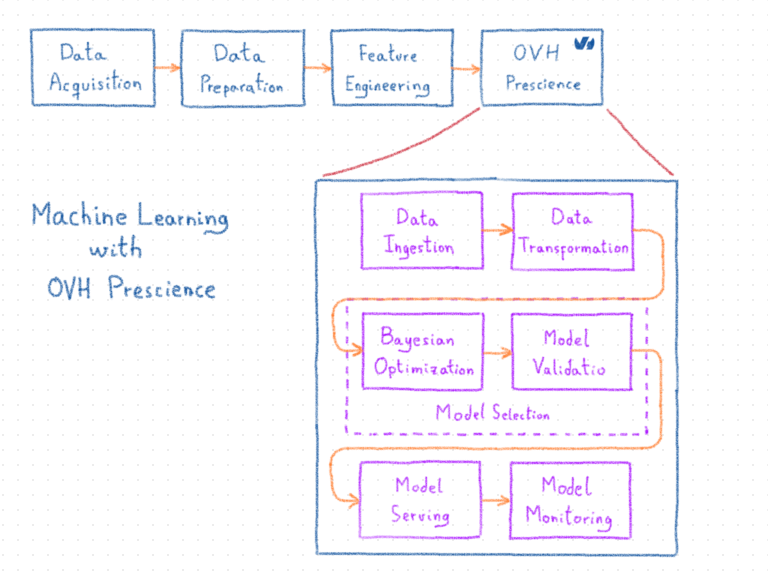
Предвидение поддерживает различные виды проблем, такие как регрессия, классификация, прогнозирование временных рядов и, в ближайшее время, обнаружение аномалий. Решение проблем достигается за счет использования как традиционных моделей машинного обучения, так и нейронных сетей.
В настоящее время Prescience используется в производственных масштабах для решения различных задач, с которыми сталкивается OVH, а его альфа-версия доступна для бесплатного изучения в OVH Labs. В этом сообщении блога мы познакомим вас с Prescience и проведем вас через типичный рабочий процесс вместе с его компонентами. Подробное представление компонентов будет доступно в будущих сообщениях блога.
Начало Предвидения
В какой-то момент все проекты машинного обучения сталкиваются с одной и той же проблемой: как преодолеть разрыв между прототипом системы машинного обучения и ее использованием в производственном контексте. Это было краеугольным камнем при разработке платформы машинного обучения в OVH.
Производственные ноутбуки
Чаще всего специалисты по обработке данных разрабатывают системы машинного обучения, которые включают обработку данных и выбор моделей в записных книжках. В случае успеха эти ноутбуки затем адаптируются для производственных нужд инженерами по обработке данных или разработчиками. Этот процесс обычно деликатный. Это занимает много времени и должно повторяться каждый раз, когда модель или обработка данных требует обновления. Эти проблемы приводят к созданию серийных моделей, которые, хотя и являются идеальными на момент поставки, могут со временем уйти от реальной проблемы. На практике обычно модели никогда не используются в производственных мощностях, несмотря на их качество, только потому, что конвейер данных слишком сложен (или утомителен) для того, чтобы вынимать их из ноутбука. В результате вся работа специалистов по данным идет напрасно.
В свете этого, первая проблема, которую необходимо было решить Prescience, заключалась в том, чтобы обеспечить простой способ развертывания и обслуживания моделей, позволяя при этом осуществлять мониторинг и эффективное управление моделями, включая (но не ограничиваясь) переобучение модели, оценку модели или запрос модели через обслуживающий REST API.
Расширенное прототипирование
Как только разрыв между прототипированием и производством был преодолен, вторая цель заключалась в сокращении фазы прототипирования проектов машинного обучения. Основное наблюдение заключается в том, что навыки специалистов по данным наиболее важны при их применении для подготовки данных или разработки функций. По сути, задача специалиста по обработке данных — правильно определить проблему. Это включает в себя описание данных, фактическую цель и правильную метрику для оценки. Тем не менее, выбор модели — это еще одна задача, выполняемая специалистом по анализу данных, и от этого специалиста гораздо меньше пользы. Действительно, одним из классических способов найти хорошую модель и ее параметры по-прежнему является перебор всех возможных конфигураций в заданном пространстве. В результате выбор модели может быть довольно кропотливым и трудоемким.
Следовательно, компании Prescience необходимо было предоставить специалистам по обработке данных эффективный способ тестирования и оценки алгоритмов, который позволил бы им сосредоточиться на добавлении ценности к данным и определению проблемы. Это было достигнуто путем добавления компонента оптимизации, который, учитывая пространство конфигурации, оценивает и тестирует конфигурации в нем, независимо от того, были ли они настроены специалистом по данным. Благодаря масштабируемой архитектуре мы можем быстро протестировать таким образом значительное количество возможностей. Компонент оптимизации также использует методы, чтобы попытаться превзойти метод грубой силы за счет использования байесовской оптимизации. Кроме того, протестированные конфигурации для данной проблемы сохраняются для последующего использования и для облегчения начала процесса оптимизации.
Расширение возможностей
В такой компании, как OVH, многие проблемы можно решить с помощью методов машинного обучения. К сожалению, невозможно назначить специалиста по данным для каждой из этих проблем, особенно если не установлено, стоит ли инвестировать в нее. Несмотря на то, что наши бизнес-специалисты не владеют всеми методами машинного обучения, они обладают обширным знанием данных. Основываясь на этих знаниях, они могут дать нам минимальное определение проблемы. Автоматизация предыдущих шагов (подготовка данных и выбор модели) позволяет специалистам быстро оценить возможные преимущества подхода машинного обучения. Затем для потенциальных проектов можно применить процесс быстрой победы / быстрой неудачи. Если это удастся, при необходимости мы можем привлечь к работе специалиста по данным.
Prescience также включает в себя автоматизированное управление конвейером, чтобы адаптировать необработанные данные для использования алгоритмами машинного обучения (например, предварительная обработка), затем выбрать подходящий алгоритм и его параметры (например, выбор модели), сохраняя автоматическое развертывание и мониторинг.
Архитектура Prescience и рабочие процессы машинного обучения
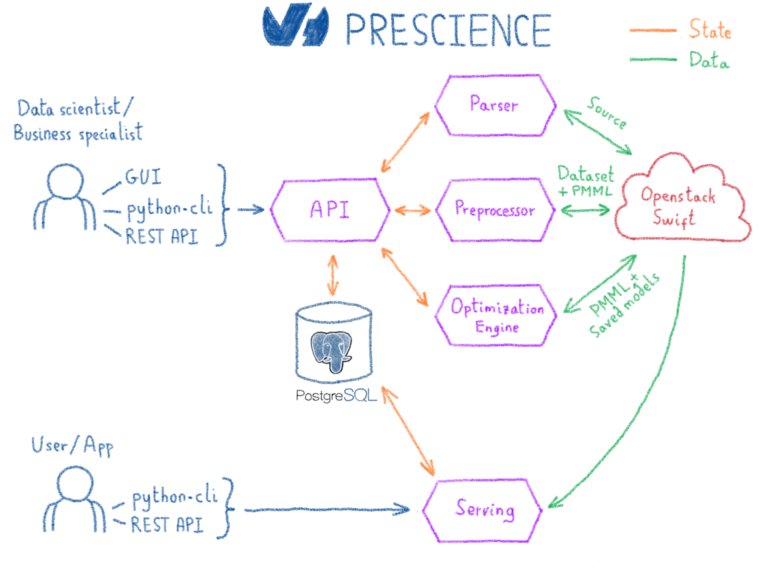
По сути, платформа Prescience построена на технологиях с открытым исходным кодом, таких как Kubernetes для операций, Spark для обработки данных и Scikit-learn, XGBoost, Spark MLlib и Tensorflow для библиотек машинного обучения. Большая часть разработок Prescience заключалась в объединении этих технологий. Кроме того, все промежуточные выходные данные системы — такие как предварительно обработанные данные, этапы преобразования или модели — сериализуются с использованием технологий и стандартов с открытым исходным кодом. Это предотвращает привязку пользователей к Prescience на случай, если когда-нибудь возникнет необходимость в использовании другой системы.
Взаимодействие пользователя с платформой Prescience стало возможным за счет следующих элементов:
- пользовательский интерфейс
- клиент python
- REST API
Давайте рассмотрим типичный рабочий процесс и дадим краткое описание различных компонентов ...
Прием данных
Первым шагом рабочего процесса машинного обучения является получение пользовательских данных. В настоящее время мы поддерживаем три типа источников, которые затем будут расширяться в зависимости от использования:
- CSV, отраслевой стандарт
- Паркет, который довольно крутой (плюс автодокументированный и сжатый)
- Временные ряды, благодаря OVH Observability, на платформе Warp10
Необработанные данные, предоставленные каждым из этих источников, редко используются алгоритмами машинного обучения как есть. Алгоритмы обычно ожидают, что числа будут работать. Таким образом, первый шаг рабочего процесса выполняется компонентом Parser. Единственная задача парсера — обнаруживать типы и имена столбцов в случае текстовых форматов, таких как CSV, хотя исходники Parquet и Warp10 включают схему, что делает этот шаг спорным. После ввода данных парсер извлекает статистику, чтобы точно охарактеризовать ее. Полученные данные вместе со статистикой хранятся в нашем серверном хранилище объектов — публичном облачном хранилище на базе OpenStack Swift.
Преобразование данных
После того, как типы выведены и статистика извлечена, данные все еще обычно необходимо обработать, прежде чем они будут готовы к машинному обучению. Этот шаг обрабатывается препроцессором. Основываясь на вычисленной статистике и типе проблемы, он определяет лучшую стратегию для применения к источнику. Например, если у нас есть одна категория, выполняется однократное кодирование. Однако, если у нас есть большое количество различных категорий, тогда выбирается более подходящий тип обработки, такой как кодирование уровня / воздействия. После вывода стратегия применяется к источнику, преобразовывая его в набор данных, который будет основой для последующего шага выбора модели.
Препроцессор выводит не только набор данных, но и сериализованную версию преобразований. Выбранный формат для сериализации — PMML (язык разметки прогнозных моделей). Это стандарт описания для совместного использования и обмена алгоритмами интеллектуального анализа данных и машинного обучения. Используя этот формат, мы сможем применить точно такое же преобразование во время обслуживания, когда столкнемся с новыми данными.
Выбор модели
Когда набор данных готов, следующим шагом будет попытка подобрать лучшую модель. В зависимости от проблемы пользователю предоставляется набор алгоритмов вместе с пространством их конфигурации. В зависимости от уровня своих навыков пользователь может настроить пространство конфигурации и предварительно выбрать подмножество алгоритмов, которые лучше подходят для задачи.
Байесовская оптимизация
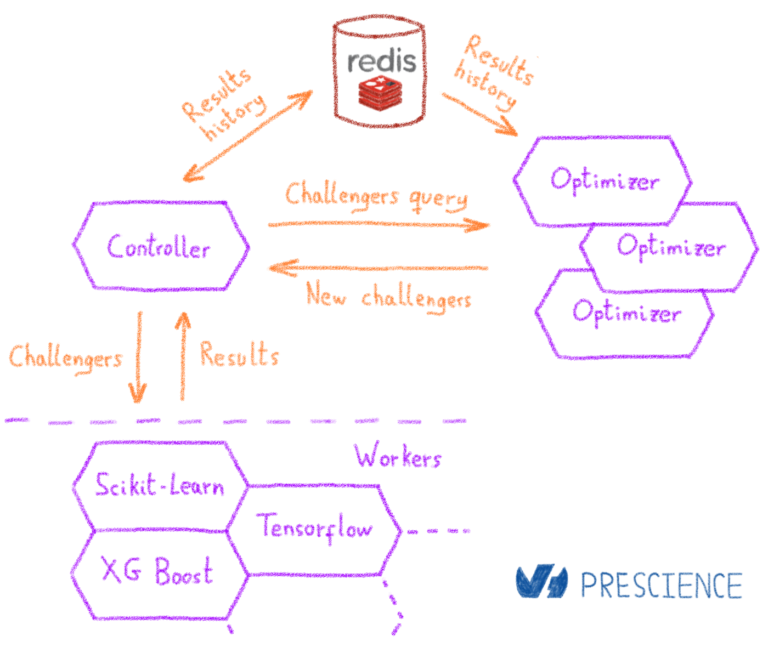
Компонент, который обрабатывает оптимизацию и выбор модели, — это механизм оптимизации. При запуске оптимизации подкомпонент, называемый контроллером, создает задачу внутренней оптимизации. Контроллер обрабатывает планирование различных шагов оптимизации, выполняемых во время задачи. Оптимизация достигается с помощью байесовских методов. По сути, байесовский подход заключается в изучении модели, которая сможет предсказать, какая конфигурация является наилучшей. Мы можем разбить шаги следующим образом:
- Модель находится в холодном состоянии. Оптимизатор возвращает контроллеру набор начальных конфигураций по умолчанию.
- Контроллер распределяет начальные конфигурации по кластеру учащихся.
- По завершении начальных настроек контроллер сохраняет результаты
- Оптимизатор запускает вторую итерацию и обучает модель доступным данным.
- На основе полученной модели оптимизатор выводит лучших претендентов, которые можно попробовать. Учитываются как их потенциальная эффективность, так и объем информации, которую они предоставят для улучшения модели выбора.
- Контроллер распределяет новый набор конфигураций по кластеру и ожидает новой информации, также известной как недавно оцененные конфигурации. Конфигурации оцениваются с использованием перекрестной проверки в K-кратном порядке, чтобы избежать переобучения.
- Когда становится доступной новая информация, запускается новая итерация оптимизации, и процесс начинается снова с шага 4.
- После заданного количества итераций оптимизация останавливается.
Проверка модели
После завершения оптимизации пользователь может либо запустить новую оптимизацию, используя существующие данные (следовательно, не возвращаясь в холодное состояние), либо выбрать конфигурацию в соответствии с ее оценочными баллами. После достижения подходящей конфигурации она используется для обучения окончательной модели, которая затем сериализуется либо в формате PMML, либо в формате сохраненной модели Tensorflow. Те же учащиеся, которые проводили оценки, проводят фактическое обучение.
В конце концов, окончательная модель сравнивается с набором тестов, извлеченным во время предварительной обработки. Этот набор никогда не используется во время выбора или обучения модели, чтобы обеспечить беспристрастность вычисленных показателей оценки. На основе полученных показателей оценки можно принять решение об использовании модели в производственной среде.
Модель сервировки
На этом этапе модель обучена, экспортируется и готова к обслуживанию. Последний компонент платформы Prescience — это Prescience Serving. Это веб-сервис, который использует PMML и сохраненные модели, а также предоставляет REST API поверх. Поскольку преобразования экспортируются вместе с моделью, пользователь может запросить новую развернутую модель, используя необработанные данные. Прогнозы теперь готовы к использованию в любом приложении.
Мониторинг модели
Кроме того, одной из характерных черт машинного обучения является его способность адаптироваться к новым данным. В отличие от традиционных, жестко заданных бизнес-правил, модель машинного обучения способна адаптироваться к базовым шаблонам. Для этого платформа Prescience позволяет пользователям легко обновлять источники, обновлять наборы данных и переобучать модели. Эти шаги жизненного цикла помогают поддерживать актуальность модели в отношении проблемы, которую необходимо решить. Затем пользователь может сопоставить свою частоту переобучения с генерацией новых квалифицированных данных. Они могут даже прервать процесс обучения в случае аномалии в конвейере генерации данных. Каждый раз, когда модель переобучается, вычисляется новый набор оценок и сохраняется в OVH Observability для мониторинга.
Как мы отмечали в начале этого сообщения в блоге, наличие точной модели не дает никаких гарантий относительно ее способности сохранять эту точность с течением времени. По многим причинам производительность модели может снизиться. Например, качество необработанных данных может ухудшиться, в конвейерах инженерии данных могут появиться некоторые аномалии или же сама проблема может дрейфовать, делая текущую модель неактуальной даже после повторного обучения. Поэтому важно постоянно контролировать производительность модели на протяжении всего жизненного цикла, чтобы не принимать решения на основе устаревшей модели.
Переход к компании, управляемой искусственным интеллектом
В настоящее время технология Prescience используется в OVH для решения нескольких промышленных задач, таких как предотвращение мошенничества и профилактическое обслуживание центров обработки данных.
С помощью этой платформы мы планируем предоставить все большему числу команд и служб в OVH возможность оптимизировать свои процессы с помощью машинного обучения. Нам особенно нравится наша работа с Time Series, которая играет решающую роль в эксплуатации и мониторинге сотен тысяч серверов и виртуальных машин.
Разработкой Prescience занимается команда Machine Learning Services. MLS состоит из четырех инженеров по машинному обучению: Маэля, Адриана, Рафаэля и меня. Команду возглавляет Гийом, который помог мне разработать платформу. Кроме того, в команду входят два специалиста по данным, Оливье и Клеман, которые занимались внутренними сценариями использования и предоставляли нам отзывы, и, наконец, Лоран: студент CIFRE, работающий над многоцелевой оптимизацией в Prescience в сотрудничестве с исследовательской группой ORKAD.
