Kubinception и etcd
Запуск Kubernetes поверх Kubernetes был хорошей идеей для компонентов уровня управления без сохранения состояния… но как насчет etcd?

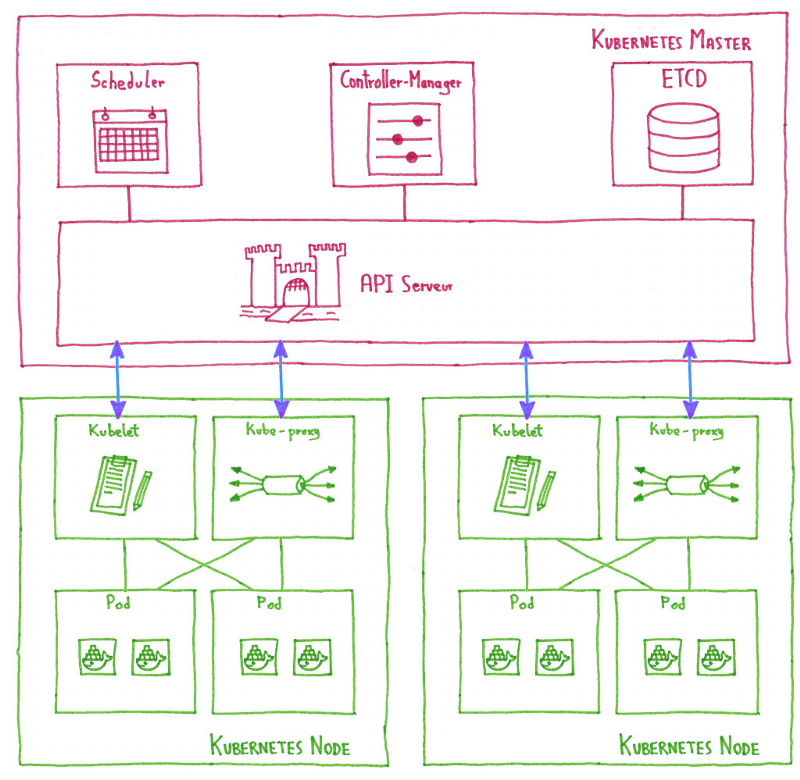
В нашем предыдущем посте мы описали архитектуру Kubinception, как мы запускаем Kubernetes поверх Kubernetes для компонентов без сохранения состояния на плоскостях управления клиентских кластеров. Но как насчет компонента с отслеживанием состояния, etcd?
Необходимость очевидна: каждый кластер клиентов должен иметь доступ к etcd, чтобы иметь возможность хранить и извлекать данные. Весь вопрос в том, где и как развернуть etcd, чтобы сделать его доступным каждому клиентскому кластеру.
Самая простая идея не всегда бывает удачной
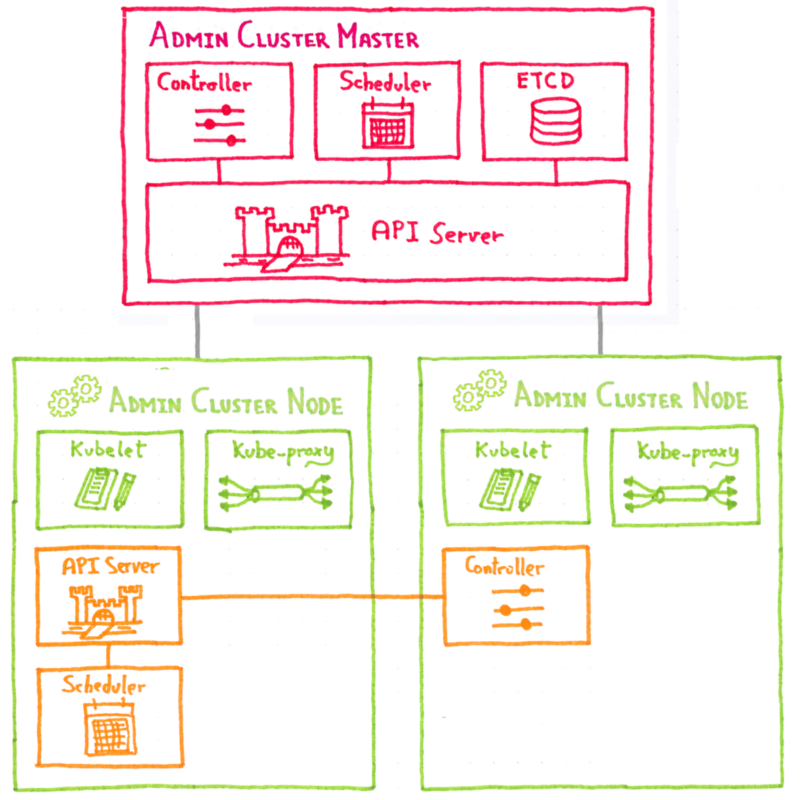
Первый подход заключается в простом следовании логике Kubinception : для каждого кластера клиентов развертывание кластера etcd в качестве модулей, работающих в кластере администрирования.
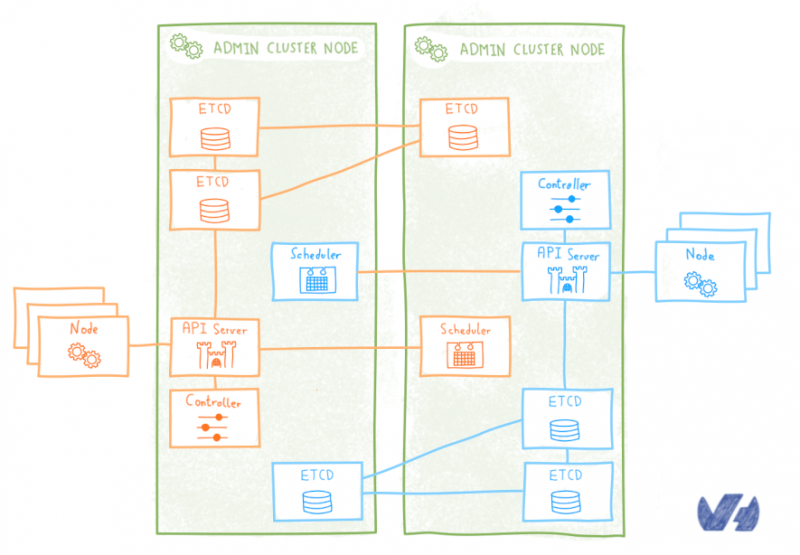
Этот полный подход Kubinception имеет то преимущество, что он прост , он кажется расширением того, что мы делаем с компонентами без сохранения состояния. Но при детальном рассмотрении обнаруживаются его недостатки . Развертывание кластера etcd не так просто и просто, как развертывание без сохранения состояния, и, будучи критически важным для работы кластера, мы не могли просто справиться с этим вручную , нам нужен был автоматизированный подход для управления им на более высоком уровне.
Использование оператора
Не только мы думали, что сложность развертывания и эксплуатации кластера etcd в Kubernetes была чрезмерной, разработчики CoreOS заметили это и в 2016 году выпустили элегантное решение проблемы: etcd оператор .
Оператор — это особый контроллер, который расширяет Kubernetes API, чтобы легко создавать, настраивать и управлять экземплярами сложных (часто распределенных) приложений с отслеживанием состояния в Kubernetes. Для справки, понятие оператора было введено в CoreOS оператором etcd .
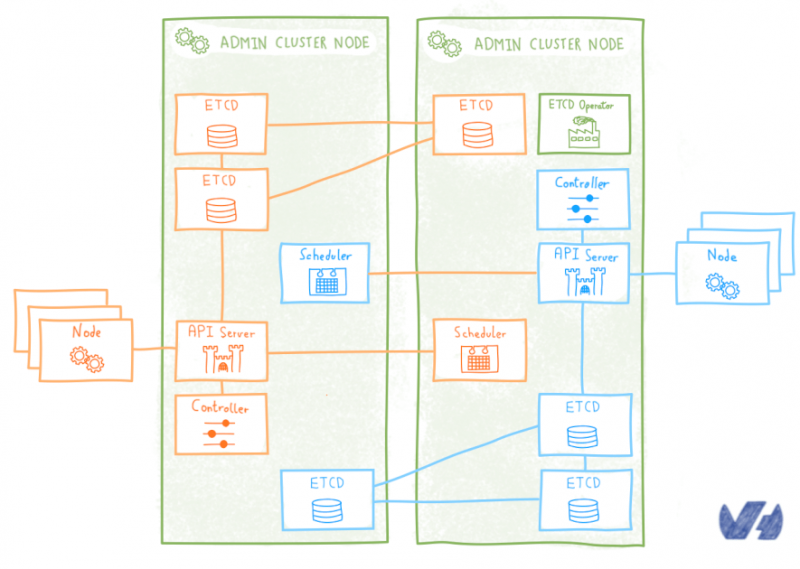
Оператор etcd управляет кластерами etcd, развернутыми в Kubernetes, и автоматизирует рабочие задачи: создание, уничтожение, изменение размера, восстановление после сбоя, последовательное обновление, резервное копирование…
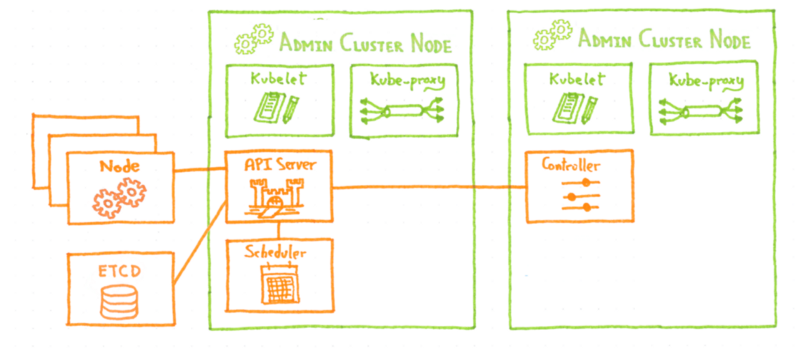
Как и в предыдущем решении, кластер etcd для каждого клиентского кластера развертывается в виде модулей в административном кластере. По умолчанию оператор etcd развертывает кластер etcd, используя локальное непостоянное хранилище для каждого модуля etcd. Это означает, что если все поды умрут (что маловероятно) или будут перенесены и будут созданы на другом узле (что гораздо более вероятно), мы можем потерять данные etcd . А без него клиентские Kubernetes замурованы.
Оператор etcd можно настроить на использование постоянных томов (PV) для хранения данных, поэтому теоретически проблема была решена. Теоретически, потому что управление томами не было достаточно зрелым, когда мы его тестировали, и если модуль etcd был убит и перепланирован, новый модуль не смог получить свои данные на PV. Таким образом, риск полной потери кворума и блокировки клиентского кластера все еще оставался у оператора etcd.
Короче говоря, мы немного поработали с оператором etcd и сочли его недостаточно зрелым для нашего использования.
StatefulSet
Помимо оператора, еще одним решением было использование StatefulSet , разновидность распределенного развертывания, хорошо подходящего для управления распределенными приложениями с отслеживанием состояния.
Существует официальная диаграмма ETCD Helm, которая позволяет развертывать кластеры ETCD как StafefulSets, в которой некоторая гибкость оператора и удобство использования сводятся к более надежному управлению PV, которое гарантирует, что перенесенный модуль etcd получит свои данные.
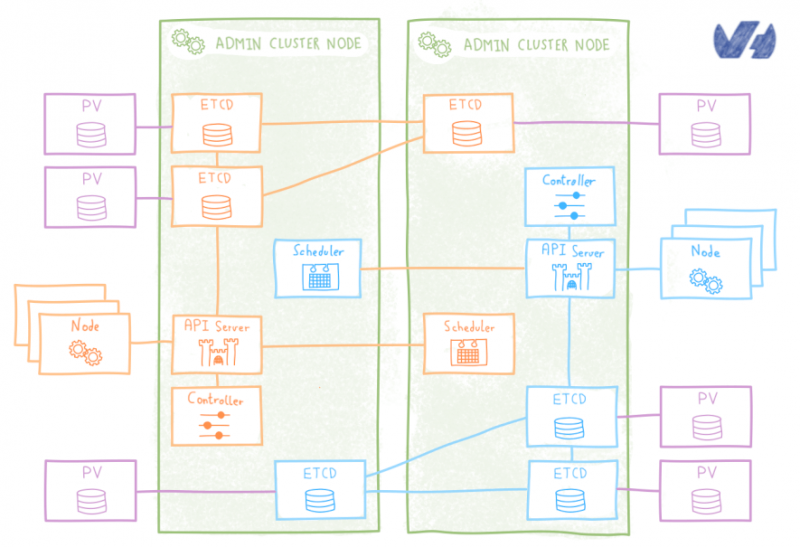
Etcd StatefulSet менее удобен , чем оператор etcd, поскольку он не предлагает простой API для таких операций, как масштабирование, переключение при отказе, последовательное обновление или резервное копирование. Взамен вы получите реальные улучшения в управлении фотоэлектрической системой . StatefulSet поддерживает закрепленную идентичность для каждого сообщения etcd, и этот постоянный идентификатор сохраняется при любом изменении расписания , что позволяет просто связать его с его PV.
Система настолько устойчива, что, даже если мы потеряем все поды etcd, когда Kubernetes изменит их расписание, они найдут свои данные, и кластер продолжит работать без проблем.
Постоянные тома, задержка и простой расчет затрат
Etcd StatefulSet казался хорошим решением … пока мы не начали интенсивно его использовать. Etcd StatefulSet использует PV, то есть тома сетевого хранилища . И etcd довольно чувствителен к задержкам в сети , их производительность сильно падает, когда они сталкиваются с задержками.
Даже если бы задержку можно было контролировать (и это большое « если» ), чем больше мы думали об этой идее, тем больше она казалась дорогим решением. Для каждого клиентского кластера нам потребуется развернуть три модуля (фактически удваивая количество модулей ) и три связанных PV, это плохо масштабируется для управляемой услуги.
В сервисе OVH Managed Kubernetes мы выставляем счет нашим клиентам в соответствии с количеством используемых ими рабочих узлов, т.е. плоскость управления бесплатна. Это означает, что для того, чтобы сервис был конкурентоспособным, важно держать под контролем ресурсы, потребляемые плоскостями управления, чтобы не удваивать количество модулей с помощью etcd.
С Kubinception мы пытались мыслить нестандартно , казалось, что для etcd нам нужно снова выйти из этой коробки.
Многопользовательский кластер etcd
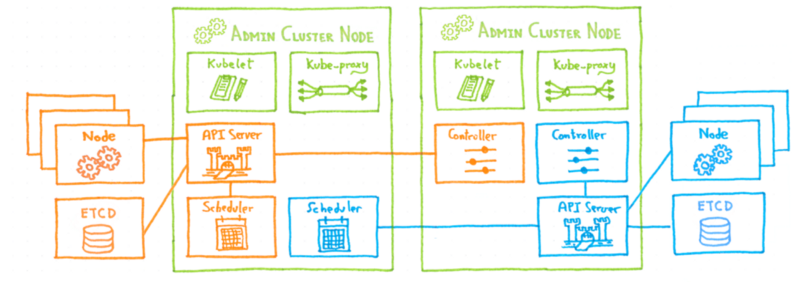
Если мы не хотели развертывать etcd внутри Kubernetes, альтернативой было развертывание снаружи. Мы решили развернуть мультитенантный кластер etcd на выделенных серверах . Все клиентские кластеры будут использовать один и тот же ETCD, каждый сервер API получит свое собственное пространство в этом мультитенантном кластере etcd.
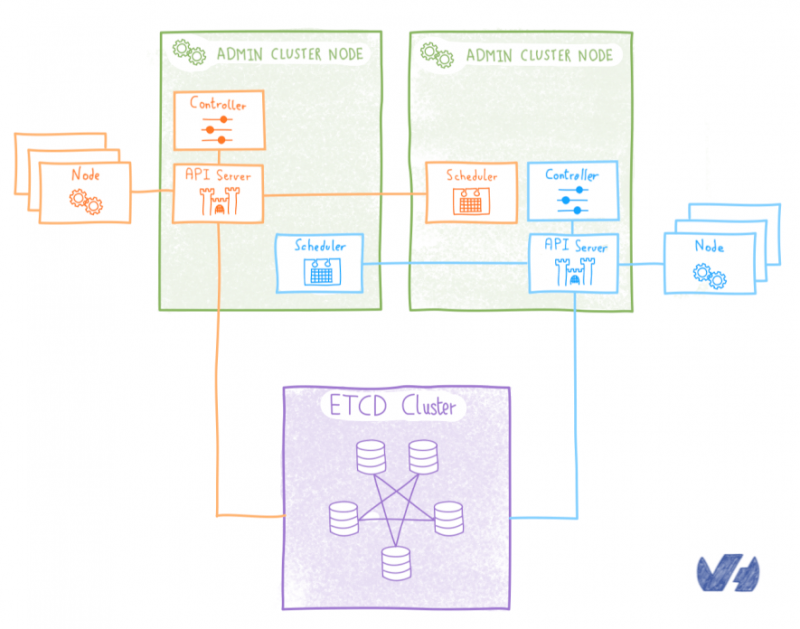
Благодаря этому решению надежность гарантируется обычными механизмами etcd, нет проблем с задержкой, поскольку данные находятся на локальном диске каждого узла etcd, а количество модулей остается под контролем, поэтому оно решает основные проблемы, которые у нас были с другое решение. Компромисс здесь является то , что нам нужно установить и эксплуатировать этот внешний etcd кластер и управление контролем доступа , чтобы убедиться , что каждый сервер доступ API только для своих собственных данных.
Что дальше?
В следующих статьях серии Kubernetes мы погрузимся в другие аспекты построения OVH Managed Kubernetes и дадим клавиатуру некоторым из наших бета-клиентов, чтобы они рассказали о своем опыте использования сервиса.
На следующей неделе давайте сосредоточимся на другой теме, мы займемся языком запросов TSL , и почему мы создали и открыли исходный код…