Каждая компания видит, что объем
данных растет с экспоненциальной скоростью , и кажется, что нет способа уменьшить количество данных, на которые мы полагаемся каждый день. Но в то же время мы должны
извлекать пользу из этих данных, чтобы оптимизировать, улучшить и ускорить наш бизнес и то, как мы работаем. Для этого необходимо хранить, вычислять и улучшать большое количество данных, для чего необходимы
конкретные решения . Говоря конкретно, для больших баз данных, распределенных баз данных, кластеров больших данных и других ресурсоемких рабочих нагрузок требуются серверы с
высокопроизводительными устройствами хранения, предназначенными для выполнения операций чтения / записи с оптимальной скоростью.
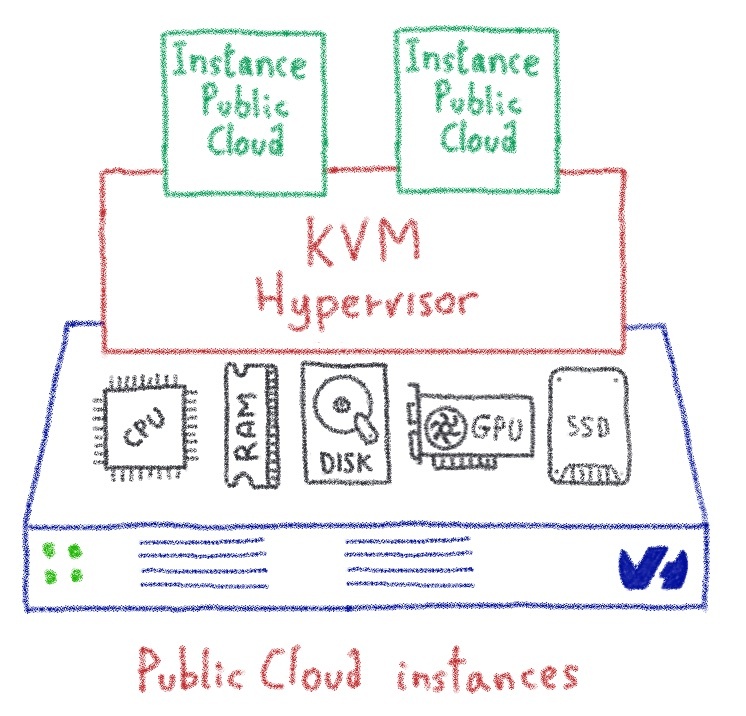
В OVHcloud мы любим
прагматичные решения . В этом духе несколько месяцев назад мы начали предлагать
графические процессоры в нашем публичном облаке , то есть предоставлять виртуальные машины с графическими процессорами. Но виртуализация графических процессоров в настоящее время не может обеспечить требуемый уровень производительности, поэтому мы решили
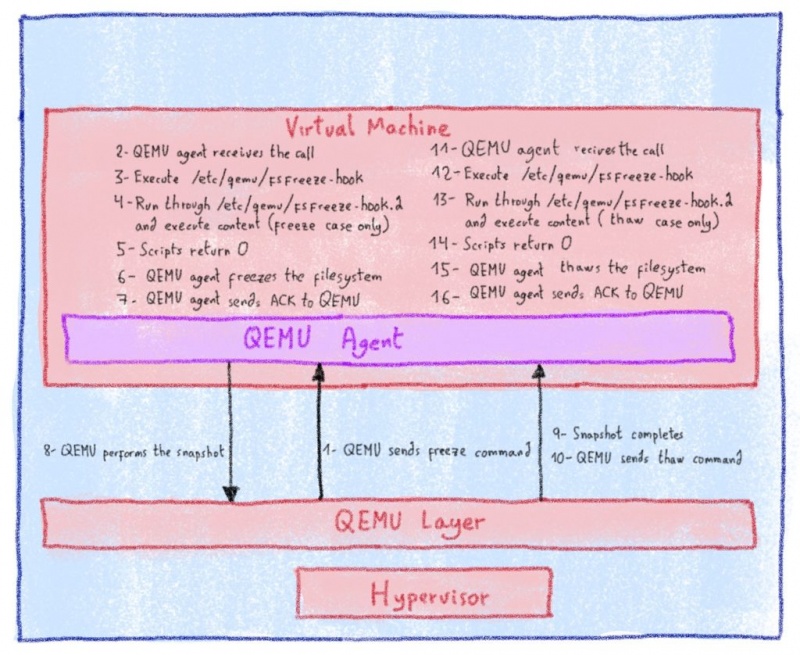
связать графические процессоры напрямую с виртуальными машинами , избегая уровня виртуализации. KVM — гипервизор нашего общественного Клауда — использование
libvirt
, которое имеет
PCI транзитного особенность , которая оказалась именно то , что нам нужно для этой цели.
Архитектура NVMe для наших экземпляров Public Cloud
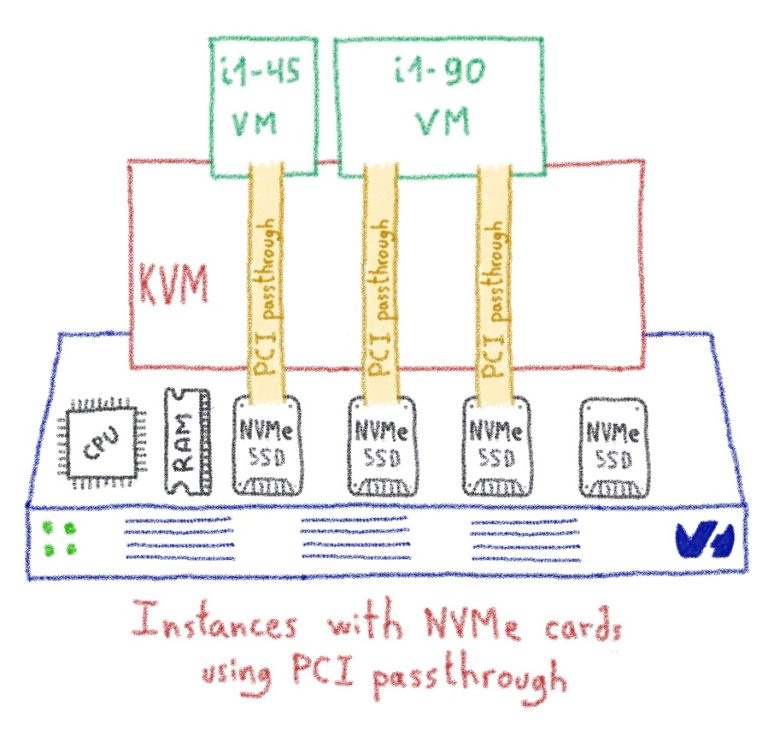
Чтобы обеспечить максимальную производительность хранилища, мы работали с рядом наших клиентов над PoC, в котором использовалась та же функция PCI Passthrough, чтобы включить самое быстрое устройство хранения в наши экземпляры Public Cloud:
карты NVMe с 1,8 ТБ пространства .
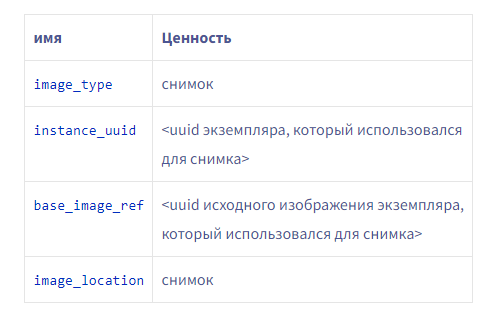
Когда дело доходит до хранения и данных о клиентах, мы должны быть уверены, что, когда клиент удаляет и выпускает экземпляр, мы должным образом
очищаем устройство перед тем, как передать его другому экземпляру. В этом случае мы
установили патч для OpenStack Nova , чтобы полностью стереть данные с устройства. Вкратце, когда экземпляр IOPS выпущен клиентом, он помещается в карантин, где внутренние инструменты запускают необходимые действия по удалению на устройстве. После завершения и проверки устройство и слот экземпляра возвращаются в Nova как «доступные».
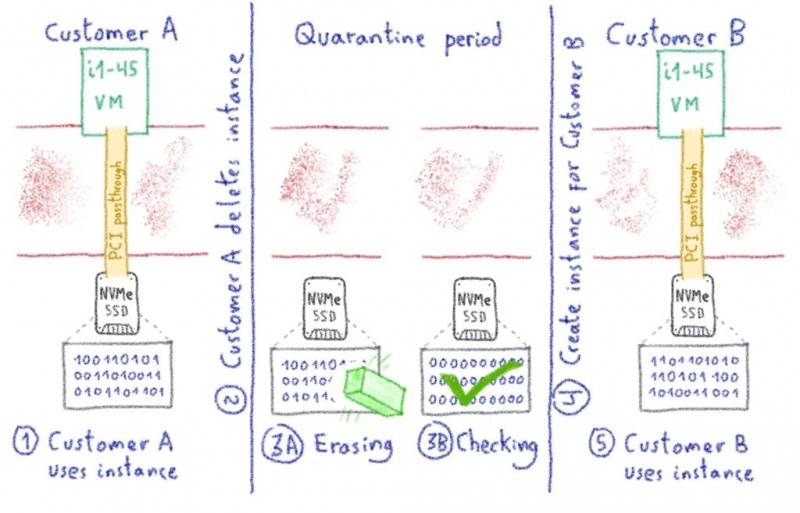
Очистите устройство перед его перераспределением
Вы говорите быстро, но как быстро?
Давайте перейдем к некоторым
конкретным примерам и не пожалеем времени, чтобы оценить потрясающую скорость этих новых экземпляров! Мы воспользуемся моделью самого большого экземпляра и запустим тест ввода-вывода на RAID 0. Таким образом, мы увидим, каковы ограничения, когда мы стремимся создать самое быстрое решение для хранения данных на простом экземпляре Public Cloud.
Сначала создайте экземпляр i1-180, используя OpenStack CLI.
$ openstack server create --flavor i1-180 --image "Ubuntu 19.04" \
--net Ext-Net --key-name mykey db01
Проверьте устройства NVMe на экземпляре.
$ lsblk | grep nvme
nvme2n1 259:0 0 1.8T 0 disk
nvme1n1 259:1 0 1.8T 0 disk
nvme0n1 259:2 0 1.8T 0 disk
nvme3n1 259:3 0 1.8T 0 disk
У нас есть четыре устройства NVMe, поэтому давайте создадим с ними RAID 0.
$ mdadm --create /dev/md1 --level 0 --raid-devices 4 \
/dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md1 started
Теперь отформатируем рейд-устройство.
$ mkfs.xfs /dev/md1
meta-data=/dev/md1 isize=512 agcount=32, agsize=58601344 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0
data = bsize=4096 blocks=1875243008, imaxpct=5
= sunit=128 swidth=512 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=521728, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
После монтирования файловой системы на / mnt мы готовы запустить тест.
Прочитать тест
Мы начнем с теста чтения, используя блоки размером 4 КБ, и поскольку у нас 32 виртуальных ядра в этой модели, мы будем использовать 32 задания. Пошли!
$ fio --bs=4k --direct=1 --rw=randread --randrepeat=0 \
--ioengine=libaio --iodepth=32 --runtime=120 --group_reporting \
--time_based --filesize=64m --numjobs=32 --name=/mnt/test
/mnt/test: (g=0): rw=randread, bs=® 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=32
[...]
fio-3.12
Starting 32 processes
Jobs: 32 (f=32): [r(32)][100.0%][r=9238MiB/s][r=2365k IOPS][eta 00m:00s]
/mnt/test: (groupid=0, jobs=32): err= 0: pid=3207: Fri Nov 29 16:00:13 2019
read: IOPS=2374k, BW=9275MiB/s (9725MB/s)(1087GiB/120002msec)
slat (usec): min=2, max=16031, avg= 7.39, stdev= 4.90
clat (usec): min=27, max=16923, avg=419.32, stdev=123.28
lat (usec): min=31, max=16929, avg=427.64, stdev=124.04
clat percentiles (usec):
| 1.00th=[ 184], 5.00th=[ 233], 10.00th=[ 269], 20.00th=[ 326],
| 30.00th=[ 363], 40.00th=[ 388], 50.00th=[ 412], 60.00th=[ 437],
| 70.00th=[ 465], 80.00th=[ 506], 90.00th=[ 570], 95.00th=[ 635],
| 99.00th=[ 775], 99.50th=[ 832], 99.90th=[ 971], 99.95th=[ 1037],
| 99.99th=[ 1205]
bw ( KiB/s): min=144568, max=397648, per=3.12%, avg=296776.28, stdev=46580.32, samples=7660
iops : min=36142, max=99412, avg=74194.06, stdev=11645.08, samples=7660
lat (usec) : 50=0.01%, 100=0.02%, 250=7.41%, 500=71.69%, 750=19.59%
lat (usec) : 1000=1.22%
lat (msec) : 2=0.07%, 4=0.01%, 10=0.01%, 20=0.01%
cpu : usr=37.12%, sys=62.66%, ctx=207950, majf=0, minf=1300
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=284924843,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=9275MiB/s (9725MB/s), 9275MiB/s-9275MiB/s (9725MB/s-9725MB/s), io=1087GiB (1167GB), run=120002-120002msec
Disk stats (read/write):
md1: ios=284595182/7, merge=0/0, ticks=0/0, in_queue=0, util=0.00%, aggrios=71231210/1, aggrmerge=0/0, aggrticks=14348879/0, aggrin_queue=120, aggrutil=99.95%
nvme0n1: ios=71231303/2, merge=0/0, ticks=14260383/0, in_queue=144, util=99.95%
nvme3n1: ios=71231349/0, merge=0/0, ticks=14361428/0, in_queue=76, util=99.89%
nvme2n1: ios=71231095/0, merge=0/0, ticks=14504766/0, in_queue=152, util=99.95%
nvme1n1: ios=71231096/4, merge=0/1, ticks=14268942/0, in_queue=108, util=99.93%
2370 тыс. Операций ввода-вывода в секунду. Потрясающие цифры, не правда ли?
Написать тест
Готовы к тесту записи?
$ fio --bs=4k --direct=1 --rw=randwrite --randrepeat=0 --ioengine=libaio --iodepth=32 --runtime=120 --group_reporting --time_based --filesize=64m --numjobs=32 --name=/mnt/test
/mnt/test: (g=0): rw=randwrite, bs=® 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=32
[...]
fio-3.12
Starting 32 processes
Jobs: 32 (f=32): [w(32)][100.0%][w=6702MiB/s][w=1716k IOPS][eta 00m:00s]
/mnt/test: (groupid=0, jobs=32): err= 0: pid=3135: Fri Nov 29 15:55:10 2019
write: IOPS=1710k, BW=6680MiB/s (7004MB/s)(783GiB/120003msec); 0 zone resets
slat (usec): min=2, max=14920, avg= 6.88, stdev= 6.20
clat (nsec): min=1152, max=18920k, avg=587644.99, stdev=735945.00
lat (usec): min=14, max=18955, avg=595.46, stdev=736.00
clat percentiles (usec):
| 1.00th=[ 21], 5.00th=[ 33], 10.00th=[ 46], 20.00th=[ 74],
| 30.00th=[ 113], 40.00th=[ 172], 50.00th=[ 255], 60.00th=[ 375],
| 70.00th=[ 644], 80.00th=[ 1139], 90.00th=[ 1663], 95.00th=[ 1991],
| 99.00th=[ 3490], 99.50th=[ 3949], 99.90th=[ 4686], 99.95th=[ 5276],
| 99.99th=[ 6521]
bw ( KiB/s): min=97248, max=252248, per=3.12%, avg=213714.71, stdev=32395.61, samples=7680
iops : min=24312, max=63062, avg=53428.65, stdev=8098.90, samples=7680
lat (usec) : 2=0.01%, 4=0.01%, 10=0.01%, 20=0.86%, 50=11.08%
lat (usec) : 100=15.35%, 250=22.16%, 500=16.34%, 750=6.69%, 1000=5.03%
lat (msec) : 2=17.66%, 4=4.38%, 10=0.44%, 20=0.01%
cpu : usr=20.40%, sys=41.05%, ctx=113183267, majf=0, minf=463
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=0,205207842,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
WRITE: bw=6680MiB/s (7004MB/s), 6680MiB/s-6680MiB/s (7004MB/s-7004MB/s), io=783GiB (841GB), run=120003-120003msec
Disk stats (read/write):
md1: ios=0/204947351, merge=0/0, ticks=0/0, in_queue=0, util=0.00%, aggrios=0/51301962, aggrmerge=0/0, aggrticks=0/27227774, aggrin_queue=822252, aggrutil=100.00%
nvme0n1: ios=0/51302106, merge=0/0, ticks=0/29636384, in_queue=865064, util=100.00%
nvme3n1: ios=0/51301711, merge=0/0, ticks=0/25214532, in_queue=932708, util=100.00%
nvme2n1: ios=0/51301636, merge=0/0, ticks=0/34347884, in_queue=1089896, util=100.00%
nvme1n1: ios=0/51302396, merge=0/0, ticks=0/19712296, in_queue=401340, util=100.00%
1710 тыс. Операций ввода-вывода в секунду при записи ...
Представьте, что вы могли бы сделать с таким решением для ваших баз данных или других
высокоинтенсивных транзакционных сценариев использования .
Конечно, для этого примера мы представляем оптимальный сценарий. RAID 0 по своей природе опасен, поэтому любой сбой на одном из устройств NVMe может повредить ваши данные. Это означает, что вы обязательно должны создавать резервные копии критически важных данных, но это само по себе открывает множество новых возможностей. Так что мы на
100% уверены, что ваши базы данных полюбят эти экземпляры! Вы можете найти более подробную информацию о них на нашем
веб-сайте Public Cloud .