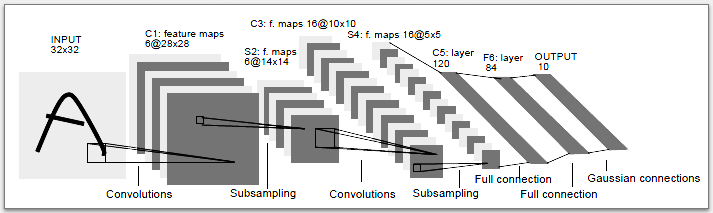
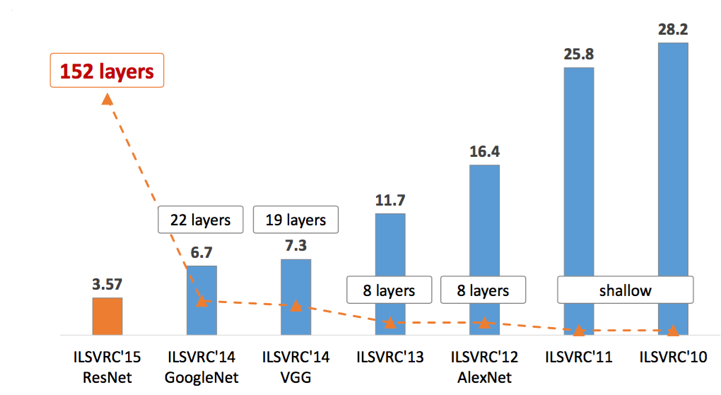
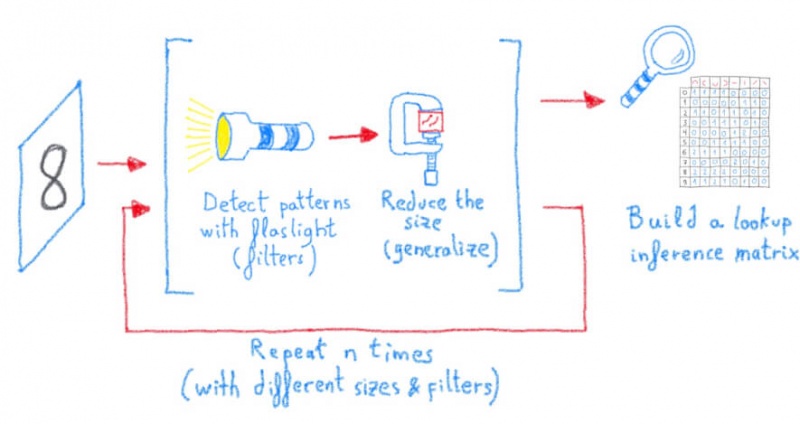
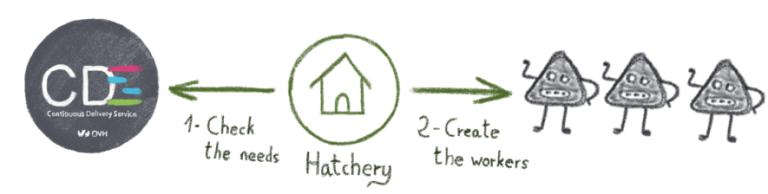
Интегрируйте свое частное облако с Active Directory
Федерация — это бета-функция, предлагаемая всем клиентам OVH Private Cloud с vCenter 6.5 . Если вы хотите принять участие в бета-тестировании, обратитесь в нашу службу поддержки. Это позволяет использовать внешний Microsoft Active Directory в качестве источника аутентификации для доступа к серверу VMware vCenter . Реализация этой функции стало возможным благодаря OvH в команде DevOps , которые разработали инновационный и уникальный API , который добавляет дополнительные возможности для тех , предлагаемых VMware. Действительно, в настоящий момент невозможно настроить источники идентификаторов через собственный API vCenter.

В этом посте мы рассмотрим, как активировать федерацию в вашем решении для частного облака, а также о преимуществах этого.
По умолчанию права доступа к vCenter в частном облаке управляются непосредственно этим vCenter. Пользователи создаются локально (localos или домен SSO), и все механизмы управления доступом ( RBAC ) управляются службой SSO . Включение федерации делегирует управление пользователями Microsoft Active Directory (AD). В результате сервер vCenter будет взаимодействовать с контроллером домена, чтобы гарантировать, что пользователь, пытающийся подключиться, является тем, кем он себя называет. VCenter сохраняет управление ролями и привилегиями для объектов, которыми он управляет. После настройки федерации можно связать пользователей AD с ролями vCenter, чтобы они могли получать доступ и / или управлять определенными объектами в инфраструктуре (виртуальными машинами, сетями, папками и т. Д.).
Одним из основных применений этого будет облегчение доступа к vCenter для администраторов за счет уменьшения количества учетных записей, необходимых для обслуживания различных элементов инфраструктуры. Кроме того, появится возможность расширить и унифицировать политику управления паролями между Active Directory и vCenter Private Cloud.
Тот факт, что федерацией можно управлять через API OVH, позволяет автоматизировать настройку, а также поддерживать ее в рабочем состоянии. Наконец, очень просто добавить проверки в любой инструмент мониторинга (Nagios, Zabbix, Sensu и т. Д.) Для мониторинга состояния Федерации и прав, назначенных пользователям.
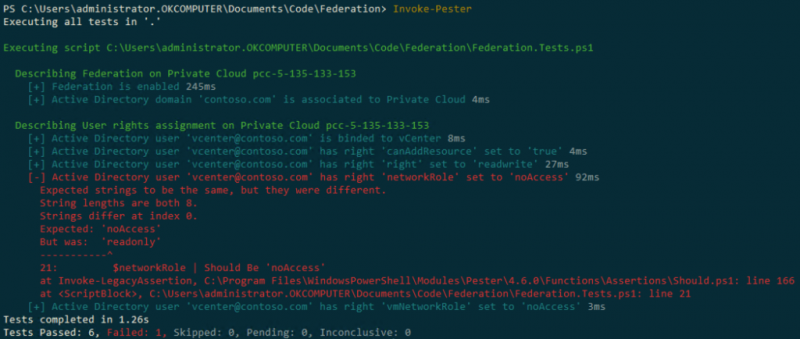
Вот пример простого сценария PowerShell, который будет периодически проверять, находится ли конфигурация федерации в желаемом состоянии:
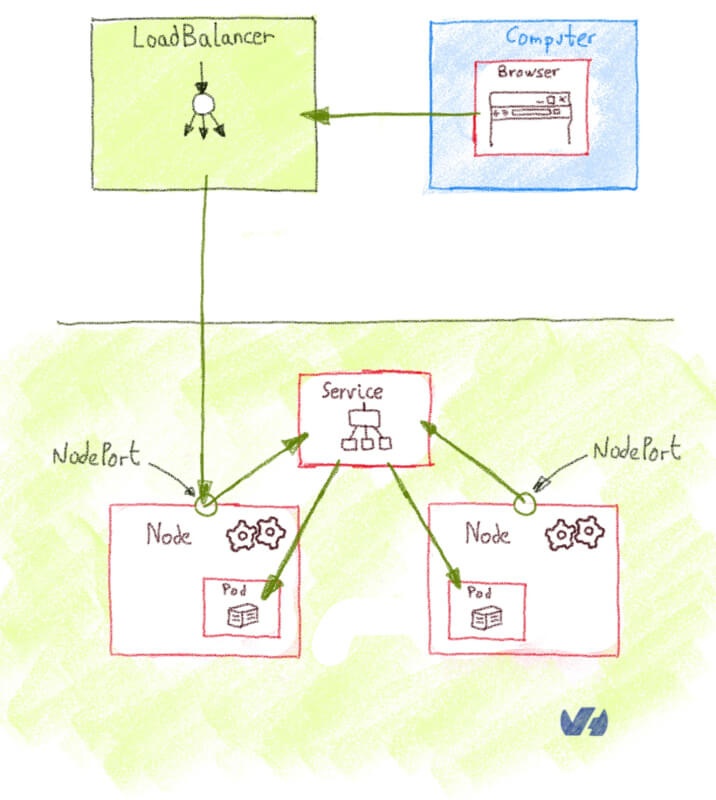
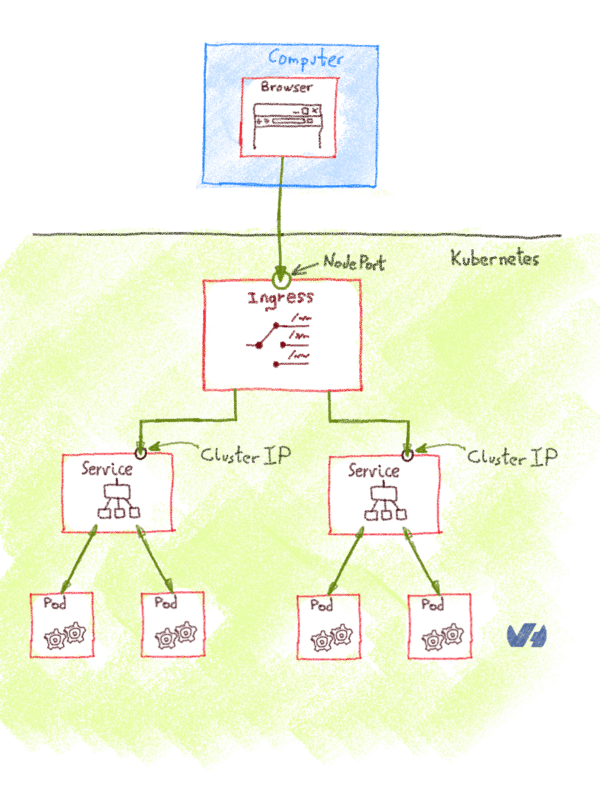
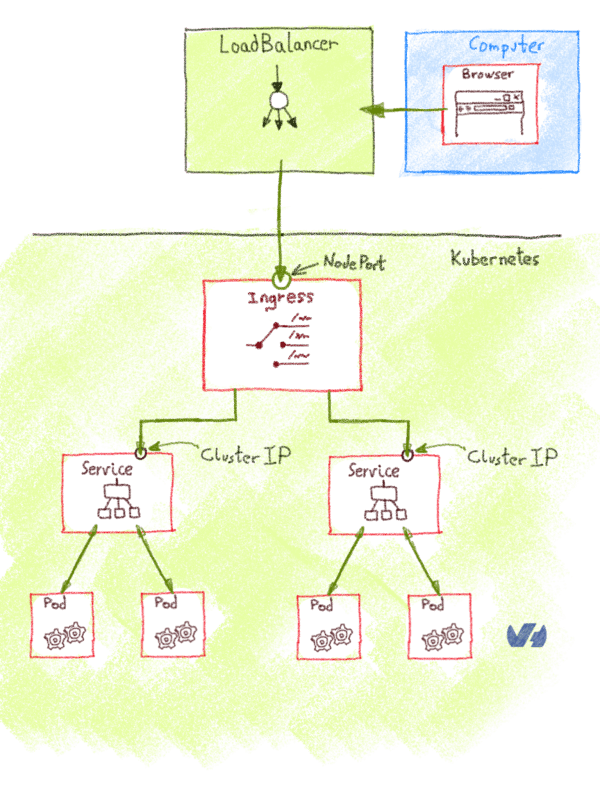
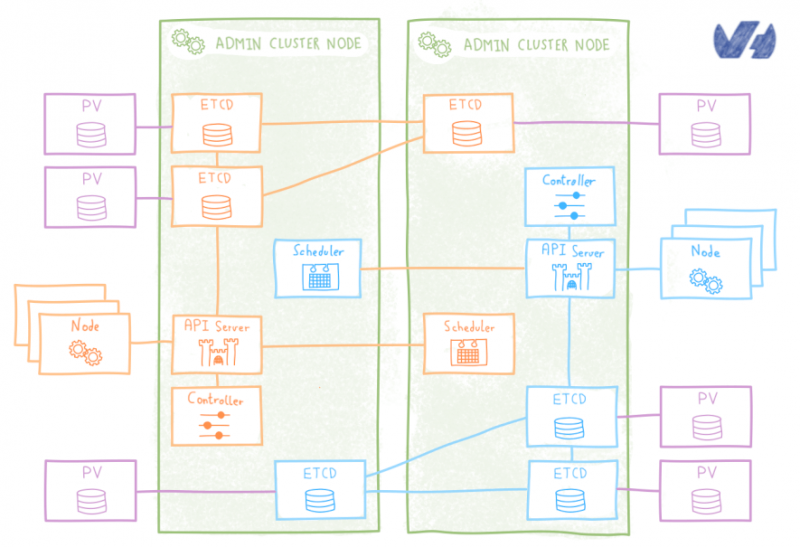
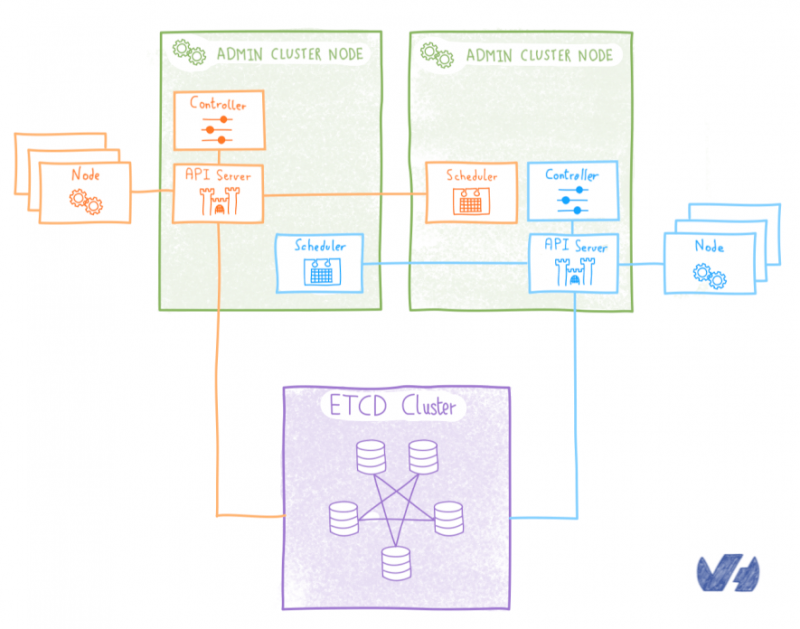
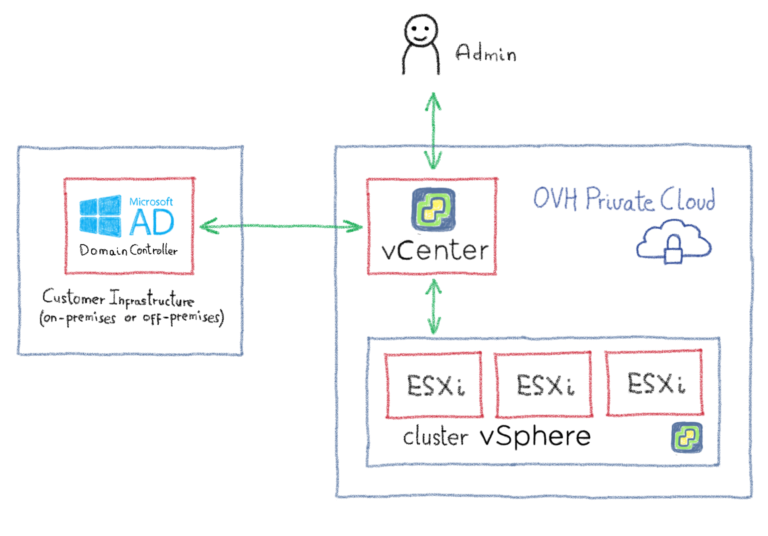
Поскольку vCenter должен будет взаимодействовать с контроллерами домена, первым шагом будет разрешение потоков между этими элементами. Есть несколько способов достичь этой цели, например, объединить OVHCloud Connectс частным шлюзом . Для изучения всех различных возможностей потребуется целая статья, поэтому мы советуем вам связаться с OVH или одним из наших партнеров, чтобы помочь вам в выборе наиболее подходящей архитектуры. Следующая диаграмма дает вам упрощенный обзор того, как это может выглядеть:
После подключения вам необходимо убедиться, что вы собрали следующую информацию, прежде чем начинать процесс настройки:
Обратите внимание, что в настоящее время невозможно иметь несколько пользователей с одним и тем же коротким именем, независимо от того, управляются ли они локально или с помощью Active Directory.
После того, как вы соберете всю необходимую информацию, можно будет активировать и настроить Федерацию. Операция будет проходить в три этапа:
На данный момент конфигурация доступна только через OVH API, но в среднесрочной перспективе это будет возможно сделать через панель управления OVH. API предлагает все необходимые параметры для активации, настройки или даже удаления федерации частного облака:
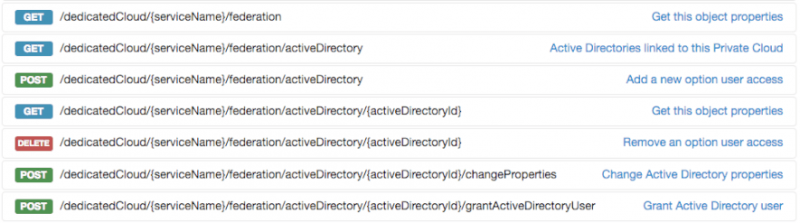
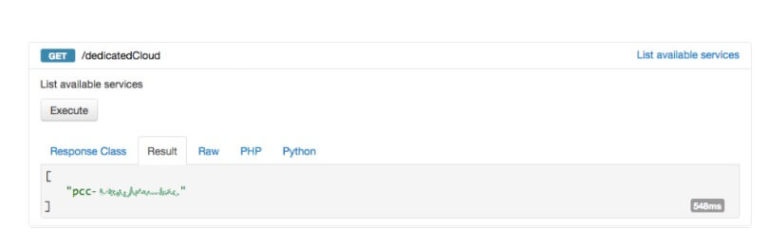
Перейдите на сайт проводника API и выполните аутентификацию, используя свои учетные данные OVH. Если у вас его еще нет, получите имя (также называемое serviceName в API) своего частного облака, так как оно будет обязательным для всех остальных шагов настройки. Вы можете получить доступ к этой информации, выполнив GET для URI / SpecialCloud:
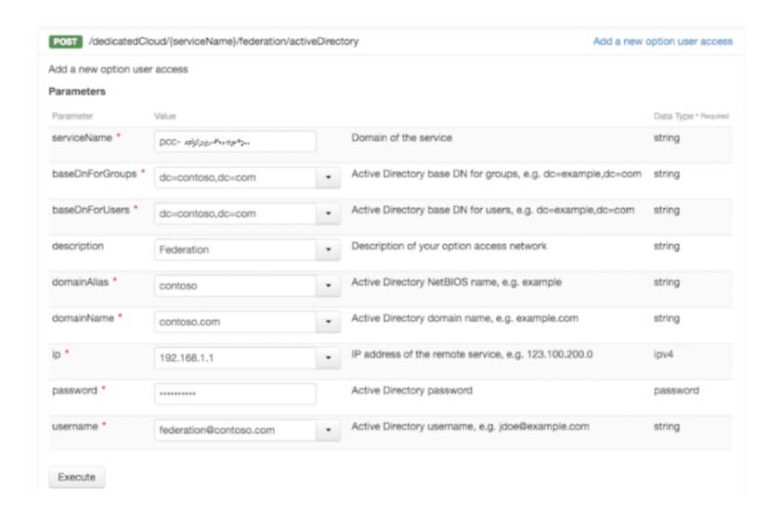
Включите федерацию, предоставив всю информацию об Active Directory с помощью POST в URI- адресе / SpecialCloud / {serviceName} / federation / activeDirectory . Вся запрашиваемая информация обязательна:
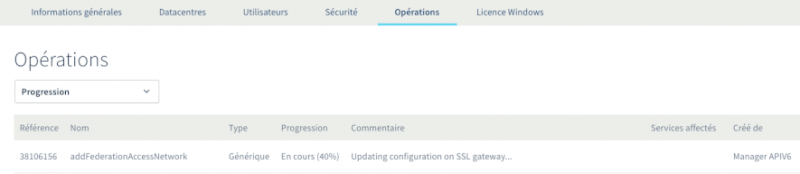
Активация Федерации займет некоторое время и будет происходить в фоновом режиме. Вы можете следить за ходом операции через панель управления OVH:
После завершения вы можете получить идентификатор федерации, отправив запрос GET на URI- адрес / SpecialCloud / {serviceName} / federation / activeDirectory :
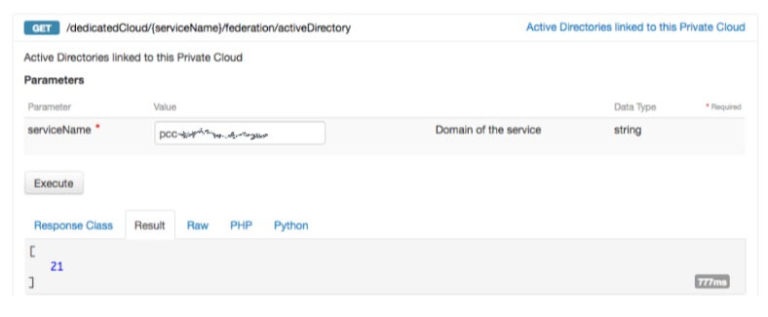
Теперь, когда ваш AD объявлен в vCenter Private Cloud, мы сможем привязать к нему пользователей Active Directory. Обратите внимание, что даже если ваши пользователи связаны, с ними не будет связанных ролей vCenter, поэтому они не смогут войти в систему.
Чтобы привязать пользователя, вам нужно будет отправить запрос POST на /dedicatedCloud/{serviceName}/federation/activeDirectory/{activeDirectory}/grantActiveDirectoryUser URI, указав полное имя пользователя:
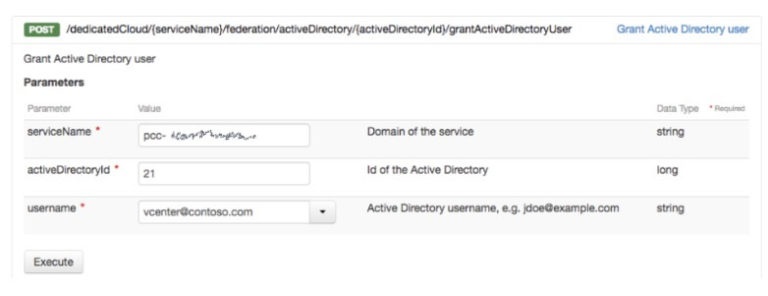
Убедитесь, что пользователь присутствует в поисковом подразделении, которое вы указали при связывании AD с vCenter. Еще раз, вы можете проверить, что задача импорта выполнена через API или через панель управления:

Вы также должны получить электронное письмо о том, что пользователь был импортирован.
Последним шагом будет предоставление пользователям прав доступа к различным объектам виртуальной инфраструктуры. Этот шаг не отличается от обычного способа управления правами пользователей частного облака. Это можно сделать через API или панель управления OVH.

Теперь вы должны иметь возможность войти в свой vCenter с пользователями вашего AD и начать управлять своим частным облаком!
В этом посте мы увидели, как активировать опцию «Федерация» и какие преимущества она дает пользователям частного облака OVH. В следующей публикации мы поговорим о еще одной новой функции: Granular Rights. Так что следите за новостями в блоге OVH!
В этом посте мы рассмотрим, как активировать федерацию в вашем решении для частного облака, а также о преимуществах этого.
Зачем?
По умолчанию права доступа к vCenter в частном облаке управляются непосредственно этим vCenter. Пользователи создаются локально (localos или домен SSO), и все механизмы управления доступом ( RBAC ) управляются службой SSO . Включение федерации делегирует управление пользователями Microsoft Active Directory (AD). В результате сервер vCenter будет взаимодействовать с контроллером домена, чтобы гарантировать, что пользователь, пытающийся подключиться, является тем, кем он себя называет. VCenter сохраняет управление ролями и привилегиями для объектов, которыми он управляет. После настройки федерации можно связать пользователей AD с ролями vCenter, чтобы они могли получать доступ и / или управлять определенными объектами в инфраструктуре (виртуальными машинами, сетями, папками и т. Д.).
Одним из основных применений этого будет облегчение доступа к vCenter для администраторов за счет уменьшения количества учетных записей, необходимых для обслуживания различных элементов инфраструктуры. Кроме того, появится возможность расширить и унифицировать политику управления паролями между Active Directory и vCenter Private Cloud.
Тот факт, что федерацией можно управлять через API OVH, позволяет автоматизировать настройку, а также поддерживать ее в рабочем состоянии. Наконец, очень просто добавить проверки в любой инструмент мониторинга (Nagios, Zabbix, Sensu и т. Д.) Для мониторинга состояния Федерации и прав, назначенных пользователям.
Вот пример простого сценария PowerShell, который будет периодически проверять, находится ли конфигурация федерации в желаемом состоянии:
Архитектура и предпосылки
Поскольку vCenter должен будет взаимодействовать с контроллерами домена, первым шагом будет разрешение потоков между этими элементами. Есть несколько способов достичь этой цели, например, объединить OVHCloud Connectс частным шлюзом . Для изучения всех различных возможностей потребуется целая статья, поэтому мы советуем вам связаться с OVH или одним из наших партнеров, чтобы помочь вам в выборе наиболее подходящей архитектуры. Следующая диаграмма дает вам упрощенный обзор того, как это может выглядеть:
После подключения вам необходимо убедиться, что вы собрали следующую информацию, прежде чем начинать процесс настройки:
- Ваши учетные данные OVH (ник и пароль)
- Имя вашего частного облака (в форме
)pcc-X-X-X-X - Необходимая информация об инфраструктуре Active Directory, а именно:
- Краткое и длинное имя домена Active Directory (например,
иcontoso
)contoso.com - IP-адрес контроллера домена
- Имя пользователя и пароль учетной записи AD с достаточными правами для просмотра каталога
- Расположение групп и пользователей в иерархии AD как «базовое DN» (пример:)
. Следует отметить, что хотя информация о группе является обязательной, в настоящее время ее невозможно использовать для управления аутентификацией.OU = Users, DC = contoso, DC = com - Список пользователей Active Directory, которых вы хотите привязать к vCenter. Необходимо будет указать имена пользователей в виде username@FQDN.domain (например,
)federation@contoso.com
- Краткое и длинное имя домена Active Directory (например,
Обратите внимание, что в настоящее время невозможно иметь несколько пользователей с одним и тем же коротким именем, независимо от того, управляются ли они локально или с помощью Active Directory.
Активация и настройка
После того, как вы соберете всю необходимую информацию, можно будет активировать и настроить Федерацию. Операция будет проходить в три этапа:
- Активация связи между Active Directory и частным облаком
- Привязка одного или нескольких пользователей AD к частному облаку
- Назначение прав пользователям
На данный момент конфигурация доступна только через OVH API, но в среднесрочной перспективе это будет возможно сделать через панель управления OVH. API предлагает все необходимые параметры для активации, настройки или даже удаления федерации частного облака:
Включение соединения между AD и частным облаком
Перейдите на сайт проводника API и выполните аутентификацию, используя свои учетные данные OVH. Если у вас его еще нет, получите имя (также называемое serviceName в API) своего частного облака, так как оно будет обязательным для всех остальных шагов настройки. Вы можете получить доступ к этой информации, выполнив GET для URI / SpecialCloud:
Включите федерацию, предоставив всю информацию об Active Directory с помощью POST в URI- адресе / SpecialCloud / {serviceName} / federation / activeDirectory . Вся запрашиваемая информация обязательна:
Активация Федерации займет некоторое время и будет происходить в фоновом режиме. Вы можете следить за ходом операции через панель управления OVH:
После завершения вы можете получить идентификатор федерации, отправив запрос GET на URI- адрес / SpecialCloud / {serviceName} / federation / activeDirectory :
Привязка одного или нескольких пользователей AD
Теперь, когда ваш AD объявлен в vCenter Private Cloud, мы сможем привязать к нему пользователей Active Directory. Обратите внимание, что даже если ваши пользователи связаны, с ними не будет связанных ролей vCenter, поэтому они не смогут войти в систему.
Чтобы привязать пользователя, вам нужно будет отправить запрос POST на /dedicatedCloud/{serviceName}/federation/activeDirectory/{activeDirectory}/grantActiveDirectoryUser URI, указав полное имя пользователя:
Убедитесь, что пользователь присутствует в поисковом подразделении, которое вы указали при связывании AD с vCenter. Еще раз, вы можете проверить, что задача импорта выполнена через API или через панель управления:
Вы также должны получить электронное письмо о том, что пользователь был импортирован.
Назначение прав доступа
Последним шагом будет предоставление пользователям прав доступа к различным объектам виртуальной инфраструктуры. Этот шаг не отличается от обычного способа управления правами пользователей частного облака. Это можно сделать через API или панель управления OVH.
Теперь вы должны иметь возможность войти в свой vCenter с пользователями вашего AD и начать управлять своим частным облаком!
В этом посте мы увидели, как активировать опцию «Федерация» и какие преимущества она дает пользователям частного облака OVH. В следующей публикации мы поговорим о еще одной новой функции: Granular Rights. Так что следите за новостями в блоге OVH!
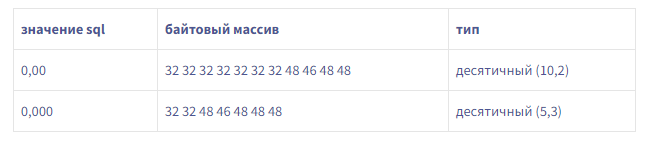
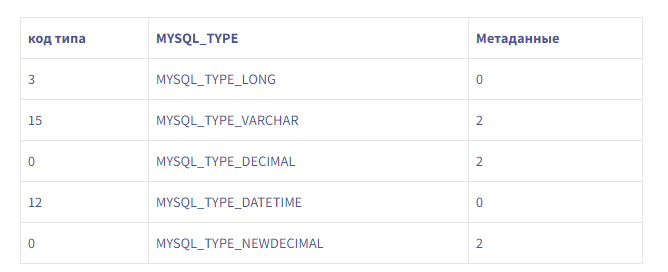 Это дает нам 18 байтов метаданных для схемы этого примера, в отличие от 10 байтов в пакете.Мы также обнаружили, что MySQL явно не отправлял метаданные, необходимые для чтения DECIMALзначений в пакете. Было ли это нормальным поведением?Документация MySQL ясна: чтобы прочитать DECIMALзначение, вам нужны метаданные (точность, масштаб и т. Д.). Период.Однако мы обнаружили, что с этим MYSQL_TYPE_DECIMALобращались как MYSQL_TYPE_NEWDECIMAL.
Это дает нам 18 байтов метаданных для схемы этого примера, в отличие от 10 байтов в пакете.Мы также обнаружили, что MySQL явно не отправлял метаданные, необходимые для чтения DECIMALзначений в пакете. Было ли это нормальным поведением?Документация MySQL ясна: чтобы прочитать DECIMALзначение, вам нужны метаданные (точность, масштаб и т. Д.). Период.Однако мы обнаружили, что с этим MYSQL_TYPE_DECIMALобращались как MYSQL_TYPE_NEWDECIMAL.