Как отслеживать свой кластер Kubernetes с помощью OVH Observability
Наши коллеги из команды K8S на прошлой неделе запустили решение OVH Managed Kubernetes, в котором они управляют главными компонентами Kubernetes и создают ваши узлы поверх нашего решения Public Cloud. Я не буду описывать здесь детали того, как это работает, но в блогах уже есть много сообщений об этом ( здесь и здесь, чтобы вы начали).
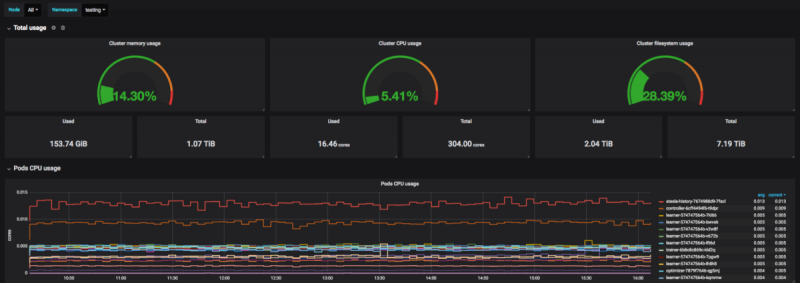
В команде Prescience мы используем Kubernetes уже больше года. Наш кластер включает 40 узлов, работающих поверх PCI. Мы постоянно запускаем около 800 модулей и в результате генерируем множество показателей.
Сегодня мы рассмотрим, как мы обрабатываем эти метрики для мониторинга нашего кластера Kubernetes, и (что не менее важно!) Как это сделать с вашим собственным кластером.
Как и в любой другой инфраструктуре, вам необходимо отслеживать свой кластер Kubernetes. Вам необходимо точно знать, как ведут себя ваши узлы, кластер и приложения после их развертывания, чтобы предоставлять надежные услуги вашим клиентам. Чтобы сделать это с нашим собственным кластером, мы используем OVH Observability.
OVH Observability не зависит от серверной части, поэтому мы можем передавать метрики в одном формате и запрашивать в другом. Он может обрабатывать:
Он также включает управляемую Grafana для отображения показателей и создания панелей мониторинга.
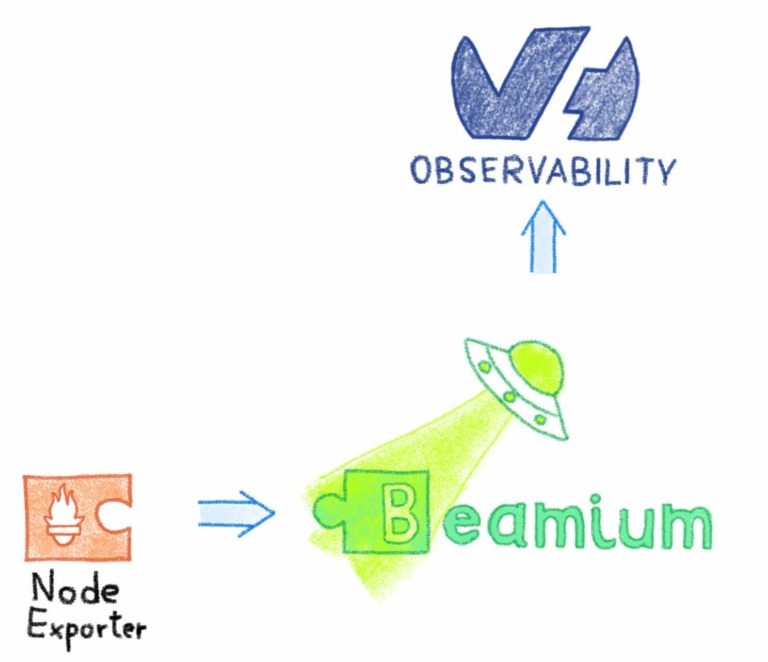
Первое, что нужно контролировать, — это состояние узлов. Все остальное начинается с этого.
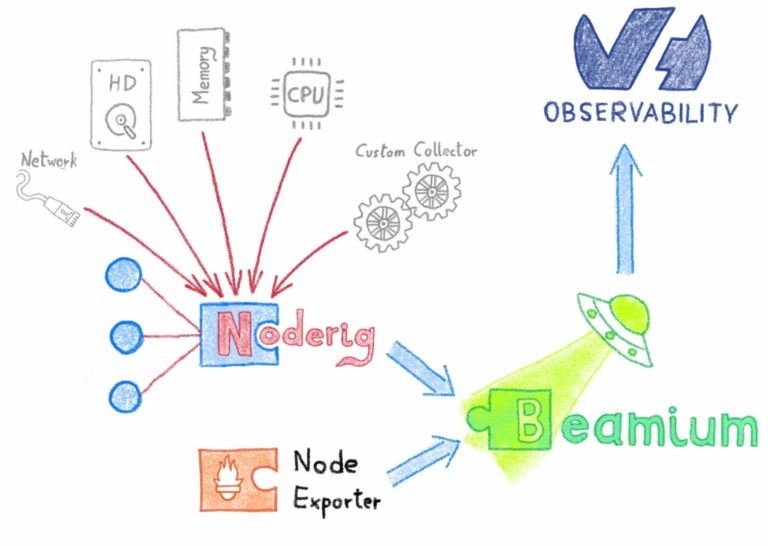
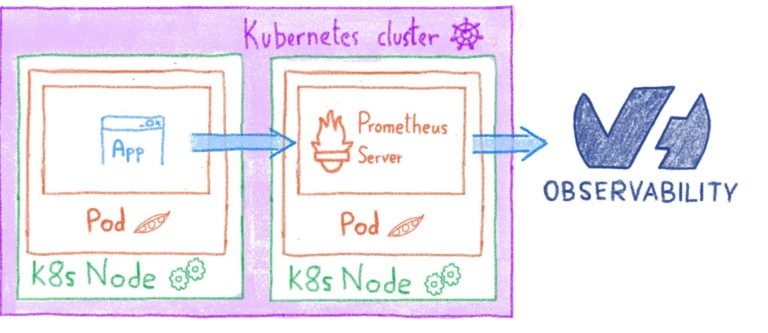
Чтобы контролировать ваши узлы, мы будем использовать Noderig и Beamium, как описано здесь. Мы также будем использовать Kubernetes DaemonSets для запуска процесса на всех наших узлах.
Итак, приступим к созданию пространства имен…
Затем создайте секрет с метриками токена записи, которые вы можете найти в панели управления OVH.
Скопируйте metrics.ymlв файл и примените конфигурацию с помощью kubectl
Не стесняйтесь менять уровни коллектора, если вам нужна дополнительная информация.
Затем примените конфигурацию с помощью kubectl…
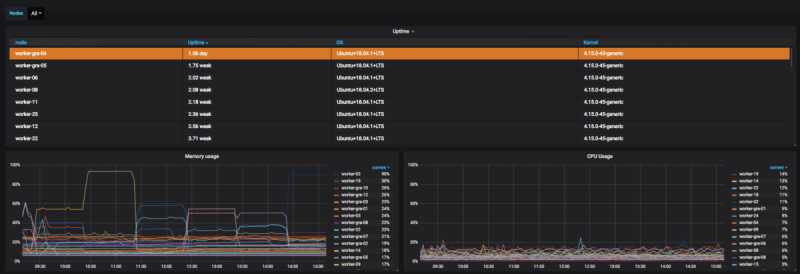
Вы можете импортировать нашу панель управления в свою Grafana отсюда и сразу же просматривать некоторые показатели о ваших узлах.
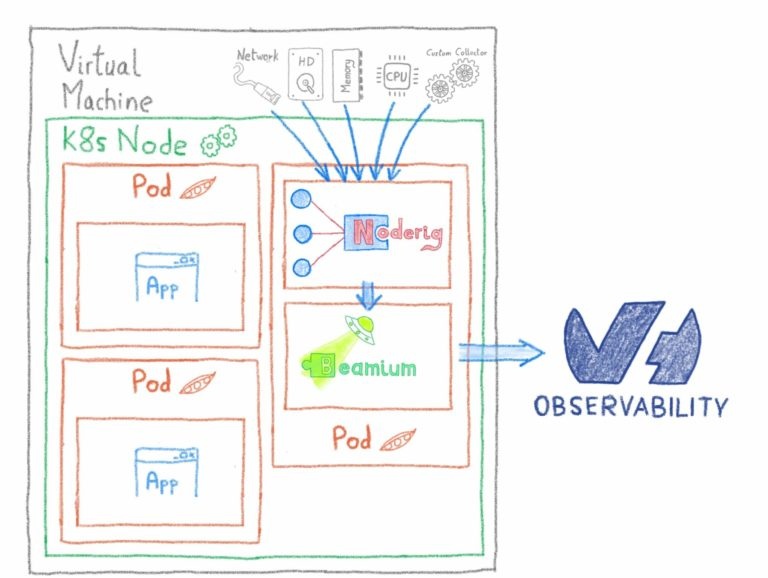
Поскольку OVH Kube — это управляемая служба, вам не нужно контролировать apiserver, etcd или панель управления. Об этом позаботится команда OVH Kubernetes. Поэтому мы сосредоточимся на показателях cAdvisor и показателях состояния Kube.
Самым зрелым решением для динамического считывания метрик внутри Kube (на данный момент) является Prometheus.
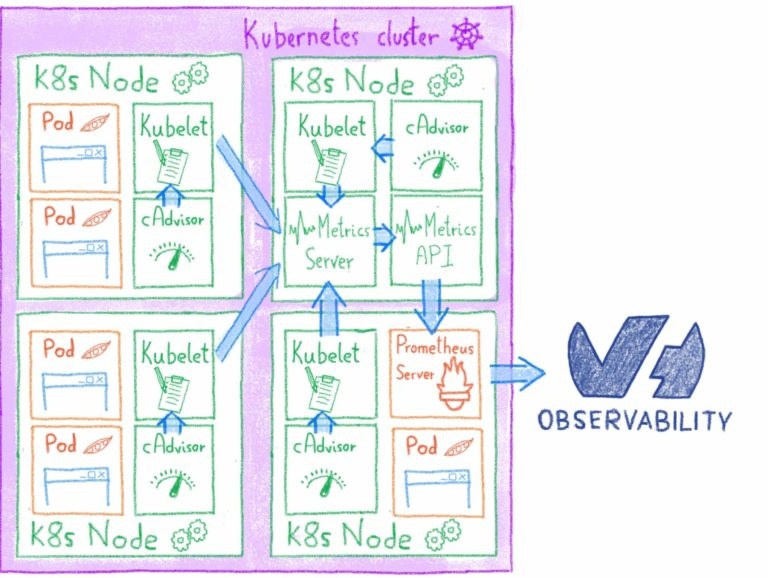
В следующем выпуске Beamium мы сможем воспроизвести функции скребка Prometheus.
Чтобы установить сервер Prometheus, вам необходимо установить Helm в кластере…
Затем вам нужно создать следующие два файла: prometheus.yml и values.yml.
Не забудьте заменить свой токен!
Скребок Прометей довольно мощный. Вы можете изменить метку своего временного ряда, оставить несколько, которые соответствуют вашему регулярному выражению, и т. Д. Эта конфигурация удаляет множество бесполезных метрик, поэтому не стесняйтесь настраивать его, если вы хотите увидеть больше метрик cAdvisor (например).
Установите его с помощью Helm…
Добавить добавить секрет базовой аутентификации…
Вы можете получить доступ к интерфейсу сервера Prometheus через prometheus.domain.com.
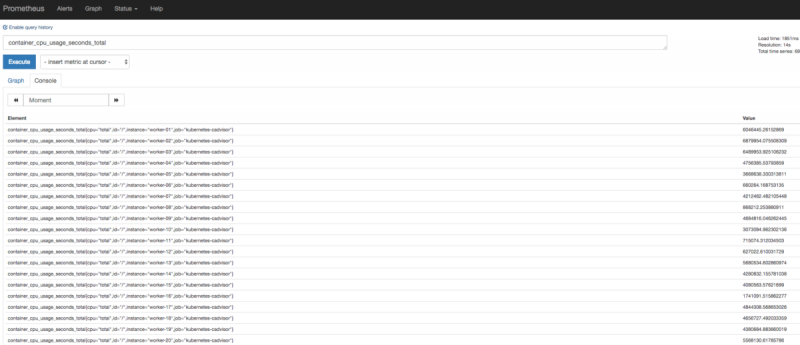
Вы увидите все показатели для своего кластера, хотя только тот, который вы отфильтровали, будет перенесен в метрики OVH.
Интерфейсы Prometheus — хороший способ изучить ваши метрики, поскольку довольно просто отображать и контролировать вашу инфраструктуру. Вы можете найти нашу панель управления здесь.
Как сказал @ Martin Schneppenheim в этом посте, для правильного управления кластером Kubernetes вам также необходимо отслеживать ресурсы пода.
Мы установим Kube Eagle, который будет извлекать и предоставлять некоторые метрики о запросах и ограничениях ЦП и ОЗУ, чтобы они могли быть получены только что установленным сервером Prometheus.
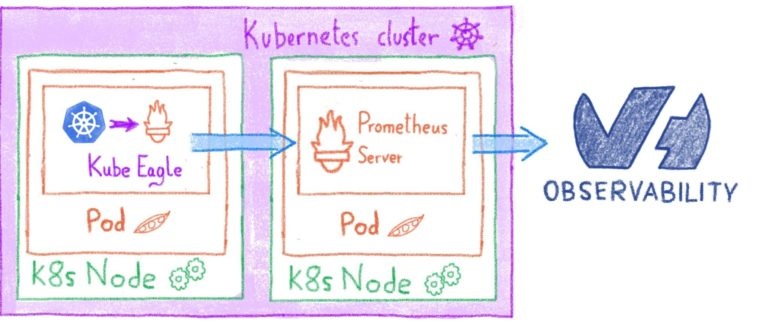
Создайте файл с именем eagle.yml.
Затем добавьте импорт этой панели управления Grafana (это та же панель, что и Kube Eagle, но перенесена на Warp10).
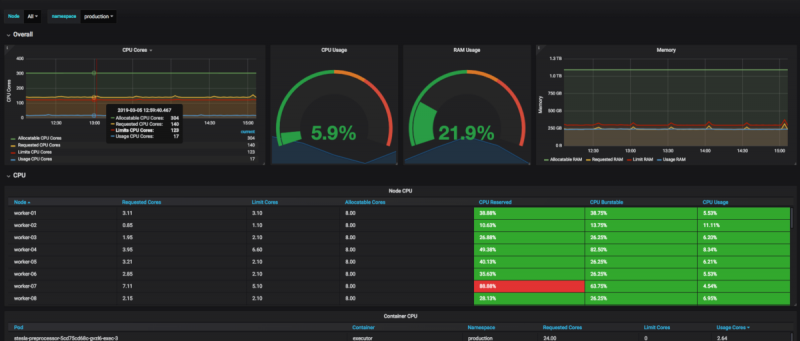
Теперь у вас есть простой способ контролировать ресурсы вашего модуля в кластере!
Как Прометей узнает, что ему нужно соскрести куба-орла? Если вы посмотрите на метаданные eagle.yml, вы увидите, что:
Эти аннотации запустят процесс автоматического обнаружения Prometheus (описанный в prometheus.ymlстроке 114).
Это означает, что вы можете легко добавить эти аннотации к модулям или службам, которые содержат экспортер Prometheus, а затем пересылать эти метрики в OVH Observability. Вы можете найти неполный список экспортеров Прометея здесь.
Как вы видели на странице prometheus.yml, мы попытались отфильтровать множество бесполезных показателей. Например, cAdvisor в новом кластере, всего с тремя настоящими производственными модулями, а также со всей системой kube и пространством имен Prometheus, имеет около 2600 метрик на узел. Используя интеллектуальный подход к очистке, вы можете сократить это количество до 126 серий.
Вот таблица, показывающая приблизительное количество метрик, которые вы создадите, в зависимости от количества узлов (N) и количества производственных модулей (P), которые у вас есть:
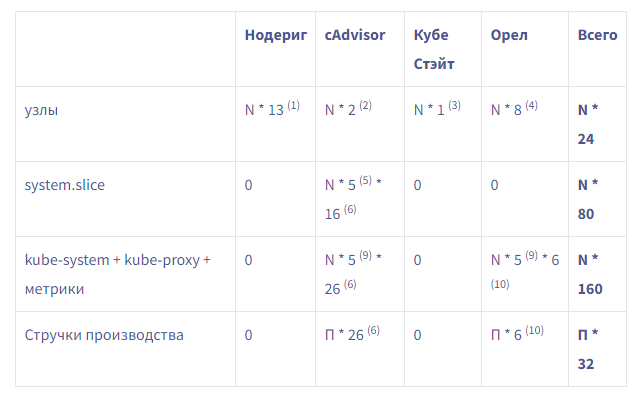
Например, если вы запустите три узла с 60 подами, вы сгенерируете 264 * 3 + 32 * 60 ~ = 2700 метрик.
NB: модуль имеет уникальное имя, поэтому при повторном развертывании развертывания вы будете каждый раз создавать 32 новых метрики.
(1) Метрики Noderig: os.mem / os.cpu / os.disk.fs / os.load1 / os.net.dropped (in/out) / os.net.errs (in/out) / os.net.packets (in/out) / os.net.bytes (in/out)/ os.uptime
(2) метрики узлов cAdvisor: machine_memory_bytes / machine_cpu_cores
(3) Метрики узлов состояния Kube: kube_node_info
(4) Показатели узлов Kube Eagle: eagle_node_resource_allocatable_cpu_cores / eagle_node_resource_allocatable_memory_bytes / eagle_node_resource_limits_cpu_cores / eagle_node_resource_limits_memory_bytes / eagle_node_resource_requests_cpu_cores / eagle_node_resource_requests_memory_bytes / eagle_node_resource_usage_cpu_cores / eagle_node_resource_usage_memory_bytes
(5) С помощью наших фильтров мы будем отслеживать около пяти system.slices.
(6) Показатели указываются для каждого контейнера. Pod — это набор контейнеров (минимум два): ваш контейнер + контейнер паузы для сети. Таким образом, мы можем рассматривать (2 * 10 + 6) для количества метрик в пакете. 10 показателей из cAdvisor и шесть для сети (см. Ниже) и для system.slice у нас будет 10 + 6, потому что он рассматривается как один контейнер.
(7) cAdvisor предоставит следующие показатели для каждого контейнера :container_start_time_seconds / container_last_seen / container_cpu_usage_seconds_total / container_fs_io_time_seconds_total / container_fs_write_seconds_total / container_fs_usage_bytes / container_fs_limit_bytes / container_memory_working_set_bytes / container_memory_rss / container_memory_usage_bytes
(8) cAdvisor предоставит следующие показатели для каждого интерфейса: container_network_receive_bytes_total * per interface / container_network_transmit_bytes_total * per interface
(9) kube-dns / beamium-noderig-metrics / kube-proxy / canal / metrics-server
(10) Показатели модулей Kube Eagle: eagle_pod_container_resource_limits_cpu_cores / eagle_pod_container_resource_limits_memory_bytes / eagle_pod_container_resource_requests_cpu_cores / eagle_pod_container_resource_requests_memory_bytes / eagle_pod_container_resource_usage_cpu_cores / eagle_pod_container_resource_usage_memory_bytes
Как видите, отслеживать кластер Kubernetes с помощью OVH Observability очень просто. Вам не нужно беспокоиться о том, как и где хранить свои метрики, и вы можете сосредоточиться на использовании кластера Kubernetes для эффективной обработки бизнес-нагрузок, как это делаем мы в группе обслуживания машинного обучения.
Следующим шагом будет добавление системы предупреждений, чтобы уведомить вас, когда ваши узлы не работают (например). Для этого вы можете использовать бесплатный инструмент OVH Alert Monitoring.
В команде Prescience мы используем Kubernetes уже больше года. Наш кластер включает 40 узлов, работающих поверх PCI. Мы постоянно запускаем около 800 модулей и в результате генерируем множество показателей.
Сегодня мы рассмотрим, как мы обрабатываем эти метрики для мониторинга нашего кластера Kubernetes, и (что не менее важно!) Как это сделать с вашим собственным кластером.
Показатели OVH
Как и в любой другой инфраструктуре, вам необходимо отслеживать свой кластер Kubernetes. Вам необходимо точно знать, как ведут себя ваши узлы, кластер и приложения после их развертывания, чтобы предоставлять надежные услуги вашим клиентам. Чтобы сделать это с нашим собственным кластером, мы используем OVH Observability.
OVH Observability не зависит от серверной части, поэтому мы можем передавать метрики в одном формате и запрашивать в другом. Он может обрабатывать:
- Graphite
- InfluxDB
- Metrics2.0
- OpentTSDB
- Prometheus
- Warp10
Он также включает управляемую Grafana для отображения показателей и создания панелей мониторинга.
Узлы мониторинга
Первое, что нужно контролировать, — это состояние узлов. Все остальное начинается с этого.
Чтобы контролировать ваши узлы, мы будем использовать Noderig и Beamium, как описано здесь. Мы также будем использовать Kubernetes DaemonSets для запуска процесса на всех наших узлах.
Итак, приступим к созданию пространства имен…
kubectl create namespace metricsЗатем создайте секрет с метриками токена записи, которые вы можете найти в панели управления OVH.
kubectl create secret generic w10-credentials --from-literal=METRICS_TOKEN=your-token -n metricsСкопируйте metrics.ymlв файл и примените конфигурацию с помощью kubectl
metrics.yml
# This will configure Beamium to scrap noderig
# And push metrics to warp 10
# We also add the HOSTNAME to the labels of the metrics pushed
---
apiVersion: v1
kind: ConfigMap
metadata:
name: beamium-config
namespace: metrics
data:
config.yaml: |
scrapers:
nodering:
url: http://0.0.0.0:9100/metrics
period: 30000
format: sensision
labels:
app: nodering
sinks:
warp:
url: https://warp10.gra1.metrics.ovh.net/api/v0/update
token: $METRICS_TOKEN
labels:
host: $HOSTNAME
parameters:
log-file: /dev/stdout
---
# This is a custom collector that report the uptime of the node
apiVersion: v1
kind: ConfigMap
metadata:
name: noderig-collector
namespace: metrics
data:
uptime.sh: |
#!/bin/sh
echo 'os.uptime' `date +%s%N | cut -b1-10` `awk '{print $1}' /proc/uptime`
---
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: metrics-daemon
namespace: metrics
spec:
selector:
matchLabels:
name: metrics-daemon
template:
metadata:
labels:
name: metrics-daemon
spec:
terminationGracePeriodSeconds: 10
hostNetwork: true
volumes:
- name: config
configMap:
name: beamium-config
- name: noderig-collector
configMap:
name: noderig-collector
defaultMode: 0777
- name: beamium-persistence
emptyDir:{}
containers:
- image: ovhcom/beamium:latest
imagePullPolicy: Always
name: beamium
env:
- name: HOSTNAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: TEMPLATE_CONFIG
value: /config/config.yaml
envFrom:
- secretRef:
name: w10-credentials
optional: false
resources:
limits:
cpu: "0.05"
memory: 128Mi
requests:
cpu: "0.01"
memory: 128Mi
workingDir: /beamium
volumeMounts:
- mountPath: /config
name: config
- mountPath: /beamium
name: beamium-persistence
- image: ovhcom/noderig:latest
imagePullPolicy: Always
name: noderig
args: ["-c", "/collectors", "--net", "3"]
volumeMounts:
- mountPath: /collectors/60/uptime.sh
name: noderig-collector
subPath: uptime.sh
resources:
limits:
cpu: "0.05"
memory: 128Mi
requests:
cpu: "0.01"
memory: 128MiНе стесняйтесь менять уровни коллектора, если вам нужна дополнительная информация.
Затем примените конфигурацию с помощью kubectl…
$ kubectl apply -f metrics.yml
# Then, just wait a minutes for the pods to start
$ kubectl get all -n metrics
NAME READY STATUS RESTARTS AGE
pod/metrics-daemon-2j6jh 2/2 Running 0 5m15s
pod/metrics-daemon-t6frh 2/2 Running 0 5m14s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE AGE
daemonset.apps/metrics-daemon 40 40 40 40 40 122dВы можете импортировать нашу панель управления в свою Grafana отсюда и сразу же просматривать некоторые показатели о ваших узлах.
OVH Метрики
Поскольку OVH Kube — это управляемая служба, вам не нужно контролировать apiserver, etcd или панель управления. Об этом позаботится команда OVH Kubernetes. Поэтому мы сосредоточимся на показателях cAdvisor и показателях состояния Kube.
Самым зрелым решением для динамического считывания метрик внутри Kube (на данный момент) является Prometheus.
В следующем выпуске Beamium мы сможем воспроизвести функции скребка Prometheus.
Чтобы установить сервер Prometheus, вам необходимо установить Helm в кластере…
kubectl -n kube-system create serviceaccount tiller
kubectl create clusterrolebinding tiller \
--clusterrole cluster-admin \
--serviceaccount=kube-system:tiller
helm init --service-account tillerЗатем вам нужно создать следующие два файла: prometheus.yml и values.yml.
# Based on https://github.com/prometheus/prometheus/blob/release-2.2/documentation/examples/prometheus-kubernetes.yml
serverFiles:
prometheus.yml:
remote_write:
- url: "https://prometheus.gra1.metrics.ovh.net/remote_write"
remote_timeout: 120s
bearer_token: $TOKEN
write_relabel_configs:
# Filter metrics to keep
- action: keep
source_labels: [__name__]
regex: "eagle.*|\
kube_node_info.*|\
kube_node_spec_taint.*|\
container_start_time_seconds|\
container_last_seen|\
container_cpu_usage_seconds_total|\
container_fs_io_time_seconds_total|\
container_fs_write_seconds_total|\
container_fs_usage_bytes|\
container_fs_limit_bytes|\
container_memory_working_set_bytes|\
container_memory_rss|\
container_memory_usage_bytes|\
container_network_receive_bytes_total|\
container_network_transmit_bytes_total|\
machine_memory_bytes|\
machine_cpu_cores"
scrape_configs:
# Scrape config for Kubelet cAdvisor.
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
metric_relabel_configs:
# Only keep systemd important services like docker|containerd|kubelet and kubepods,
# We also want machine_cpu_cores that don't have id, so we need to add the name of the metric in order to be matched
# The string will concat id with name and the separator is a ;
# `/;container_cpu_usage_seconds_total` OK
# `/system.slice;container_cpu_usage_seconds_total` OK
# `/system.slice/minion.service;container_cpu_usage_seconds_total` NOK, Useless
# `/kubepods/besteffort/e2514ad43202;container_cpu_usage_seconds_total` Best Effort POD OK
# `/kubepods/burstable/e2514ad43202;container_cpu_usage_seconds_total` Burstable POD OK
# `/kubepods/e2514ad43202;container_cpu_usage_seconds_total` Guaranteed POD OK
# `/docker/pod104329ff;container_cpu_usage_seconds_total` OK, Container that run on docker but not managed by kube
# `;machine_cpu_cores` OK, there is no id on these metrics, but we want to keep them also
- source_labels: [id,__name__]
regex: "^((/(system.slice(/(docker|containerd|kubelet).service)?|(kubepods|docker).*)?);.*|;(machine_cpu_cores|machine_memory_bytes))$"
action: keep
# Remove Useless parents keys like `/kubepods/burstable` or `/docker`
- source_labels: [id]
regex: "(/kubepods/burstable|/kubepods/besteffort|/kubepods|/docker)"
action: drop
# cAdvisor give metrics per container and sometimes it sum up per pod
# As we already have the child, we will sum up ourselves, so we drop metrics for the POD and keep containers metrics
# Metrics for the POD don't have container_name, so we drop if we have just the pod_name
- source_labels: [container_name,pod_name]
regex: ";(.+)"
action: drop
# Scrape config for service endpoints.
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
# Example scrape config for pods
#
# The relabeling allows the actual pod scrape endpoint to be configured via the
# following annotations:
#
# * `prometheus.io/scrape`: Only scrape pods that have a value of `true`
# * `prometheus.io/path`: If the metrics path is not `/metrics` override this.
# * `prometheus.io/port`: Scrape the pod on the indicated port instead of the
# pod's declared ports (default is a port-free target if none are declared).
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod_name
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: host
- action: labeldrop
regex: (pod_template_generation|job|release|controller_revision_hash|workload_user_cattle_io_workloadselector|pod_template_hash)values.yml
alertmanager:
enabled: false
pushgateway:
enabled: false
nodeExporter:
enabled: false
server:
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: traefik
ingress.kubernetes.io/auth-type: basic
ingress.kubernetes.io/auth-secret: basic-auth
hosts:
- prometheus.domain.com
image:
tag: v2.7.1
persistentVolume:
enabled: falseНе забудьте заменить свой токен!
Скребок Прометей довольно мощный. Вы можете изменить метку своего временного ряда, оставить несколько, которые соответствуют вашему регулярному выражению, и т. Д. Эта конфигурация удаляет множество бесполезных метрик, поэтому не стесняйтесь настраивать его, если вы хотите увидеть больше метрик cAdvisor (например).
Установите его с помощью Helm…
helm install stable/prometheus \
--namespace=metrics \
--name=metrics \
--values=values/values.yaml \
--values=values/prometheus.yamlДобавить добавить секрет базовой аутентификации…
$ htpasswd -c auth foo
New password: <bar>
New password:
Re-type new password:
Adding password for user foo
$ kubectl create secret generic basic-auth --from-file=auth -n metrics
secret "basic-auth" createdВы можете получить доступ к интерфейсу сервера Prometheus через prometheus.domain.com.
Вы увидите все показатели для своего кластера, хотя только тот, который вы отфильтровали, будет перенесен в метрики OVH.
Интерфейсы Prometheus — хороший способ изучить ваши метрики, поскольку довольно просто отображать и контролировать вашу инфраструктуру. Вы можете найти нашу панель управления здесь.
Метрики ресурсов
Как сказал @ Martin Schneppenheim в этом посте, для правильного управления кластером Kubernetes вам также необходимо отслеживать ресурсы пода.
Мы установим Kube Eagle, который будет извлекать и предоставлять некоторые метрики о запросах и ограничениях ЦП и ОЗУ, чтобы они могли быть получены только что установленным сервером Prometheus.
Создайте файл с именем eagle.yml.
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
labels:
app: kube-eagle
name: kube-eagle
namespace: kube-eagle
rules:
- apiGroups:
- ""
resources:
- nodes
- pods
verbs:
- get
- list
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
labels:
app: kube-eagle
name: kube-eagle
namespace: kube-eagle
subjects:
- kind: ServiceAccount
name: kube-eagle
namespace: kube-eagle
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-eagle
---
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: kube-eagle
labels:
app: kube-eagle
name: kube-eagle
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: kube-eagle
name: kube-eagle
labels:
app: kube-eagle
spec:
replicas: 1
selector:
matchLabels:
app: kube-eagle
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
prometheus.io/path: "/metrics"
labels:
app: kube-eagle
spec:
serviceAccountName: kube-eagle
containers:
- name: kube-eagle
image: "quay.io/google-cloud-tools/kube-eagle:1.0.0"
imagePullPolicy: IfNotPresent
env:
- name: PORT
value: "8080"
ports:
- name: http
containerPort: 8080
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: http
readinessProbe:
httpGet:
path: /health
port: http$ kubectl create namespace kube-eagle
$ kubectl apply -f eagle.ymlЗатем добавьте импорт этой панели управления Grafana (это та же панель, что и Kube Eagle, но перенесена на Warp10).
Теперь у вас есть простой способ контролировать ресурсы вашего модуля в кластере!
Пользовательские показатели
Как Прометей узнает, что ему нужно соскрести куба-орла? Если вы посмотрите на метаданные eagle.yml, вы увидите, что:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080" # The port where to find the metrics
prometheus.io/path: "/metrics" # The path where to find the metricsЭти аннотации запустят процесс автоматического обнаружения Prometheus (описанный в prometheus.ymlстроке 114).
Это означает, что вы можете легко добавить эти аннотации к модулям или службам, которые содержат экспортер Prometheus, а затем пересылать эти метрики в OVH Observability. Вы можете найти неполный список экспортеров Прометея здесь.
Объемный анализ
Как вы видели на странице prometheus.yml, мы попытались отфильтровать множество бесполезных показателей. Например, cAdvisor в новом кластере, всего с тремя настоящими производственными модулями, а также со всей системой kube и пространством имен Prometheus, имеет около 2600 метрик на узел. Используя интеллектуальный подход к очистке, вы можете сократить это количество до 126 серий.
Вот таблица, показывающая приблизительное количество метрик, которые вы создадите, в зависимости от количества узлов (N) и количества производственных модулей (P), которые у вас есть:
Например, если вы запустите три узла с 60 подами, вы сгенерируете 264 * 3 + 32 * 60 ~ = 2700 метрик.
NB: модуль имеет уникальное имя, поэтому при повторном развертывании развертывания вы будете каждый раз создавать 32 новых метрики.
(1) Метрики Noderig: os.mem / os.cpu / os.disk.fs / os.load1 / os.net.dropped (in/out) / os.net.errs (in/out) / os.net.packets (in/out) / os.net.bytes (in/out)/ os.uptime
(2) метрики узлов cAdvisor: machine_memory_bytes / machine_cpu_cores
(3) Метрики узлов состояния Kube: kube_node_info
(4) Показатели узлов Kube Eagle: eagle_node_resource_allocatable_cpu_cores / eagle_node_resource_allocatable_memory_bytes / eagle_node_resource_limits_cpu_cores / eagle_node_resource_limits_memory_bytes / eagle_node_resource_requests_cpu_cores / eagle_node_resource_requests_memory_bytes / eagle_node_resource_usage_cpu_cores / eagle_node_resource_usage_memory_bytes
(5) С помощью наших фильтров мы будем отслеживать около пяти system.slices.
(6) Показатели указываются для каждого контейнера. Pod — это набор контейнеров (минимум два): ваш контейнер + контейнер паузы для сети. Таким образом, мы можем рассматривать (2 * 10 + 6) для количества метрик в пакете. 10 показателей из cAdvisor и шесть для сети (см. Ниже) и для system.slice у нас будет 10 + 6, потому что он рассматривается как один контейнер.
(7) cAdvisor предоставит следующие показатели для каждого контейнера :container_start_time_seconds / container_last_seen / container_cpu_usage_seconds_total / container_fs_io_time_seconds_total / container_fs_write_seconds_total / container_fs_usage_bytes / container_fs_limit_bytes / container_memory_working_set_bytes / container_memory_rss / container_memory_usage_bytes
(8) cAdvisor предоставит следующие показатели для каждого интерфейса: container_network_receive_bytes_total * per interface / container_network_transmit_bytes_total * per interface
(9) kube-dns / beamium-noderig-metrics / kube-proxy / canal / metrics-server
(10) Показатели модулей Kube Eagle: eagle_pod_container_resource_limits_cpu_cores / eagle_pod_container_resource_limits_memory_bytes / eagle_pod_container_resource_requests_cpu_cores / eagle_pod_container_resource_requests_memory_bytes / eagle_pod_container_resource_usage_cpu_cores / eagle_pod_container_resource_usage_memory_bytes
Вывод
Как видите, отслеживать кластер Kubernetes с помощью OVH Observability очень просто. Вам не нужно беспокоиться о том, как и где хранить свои метрики, и вы можете сосредоточиться на использовании кластера Kubernetes для эффективной обработки бизнес-нагрузок, как это делаем мы в группе обслуживания машинного обучения.
Следующим шагом будет добавление системы предупреждений, чтобы уведомить вас, когда ваши узлы не работают (например). Для этого вы можете использовать бесплатный инструмент OVH Alert Monitoring.