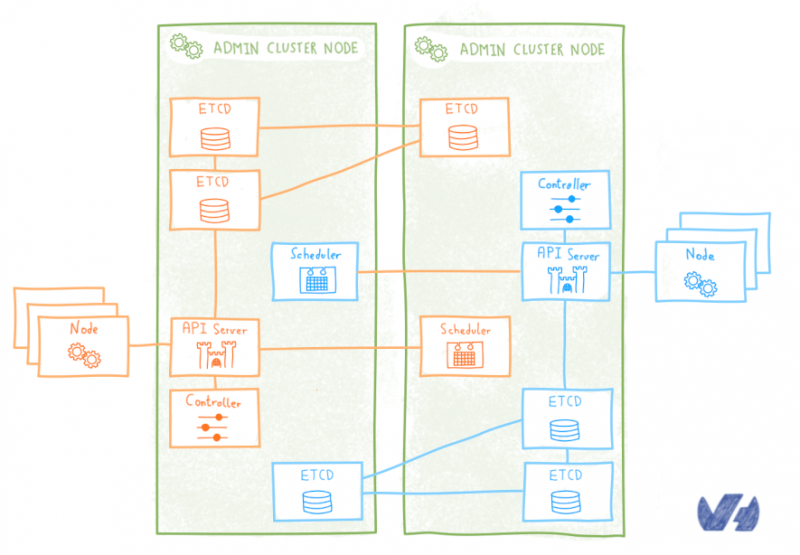
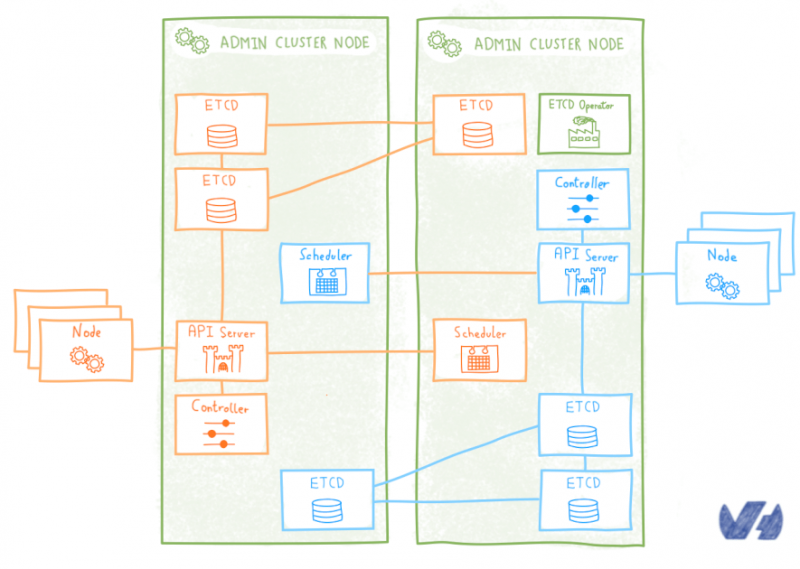
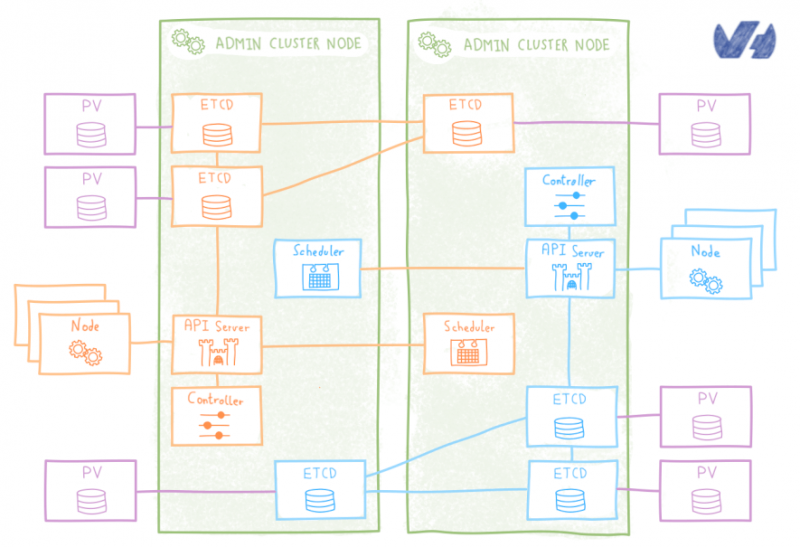
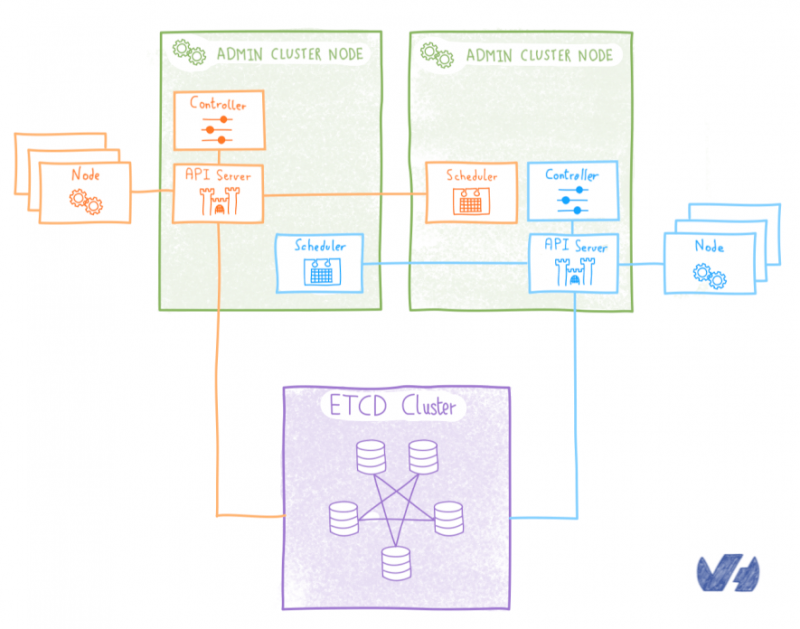
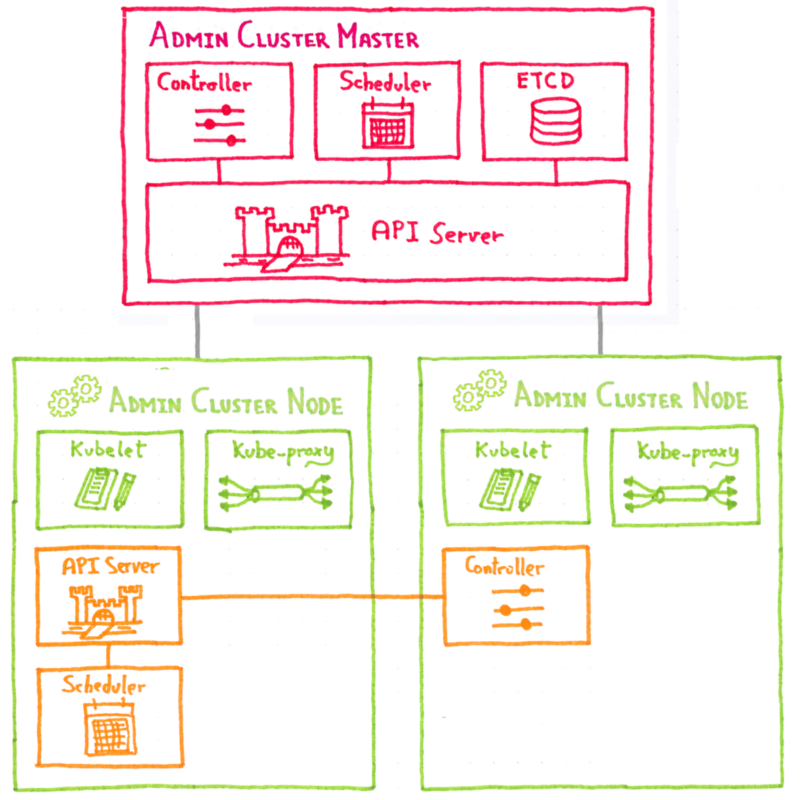
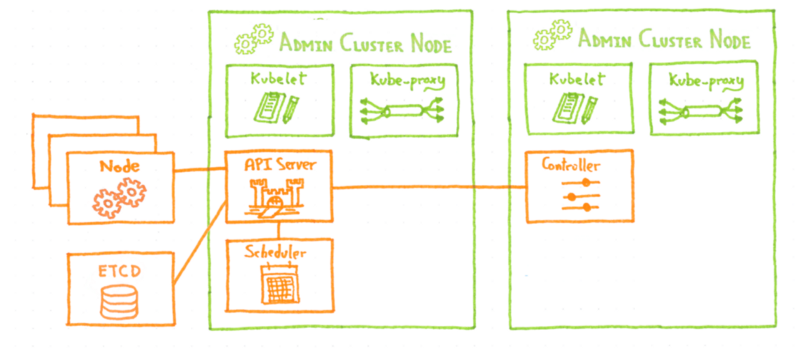
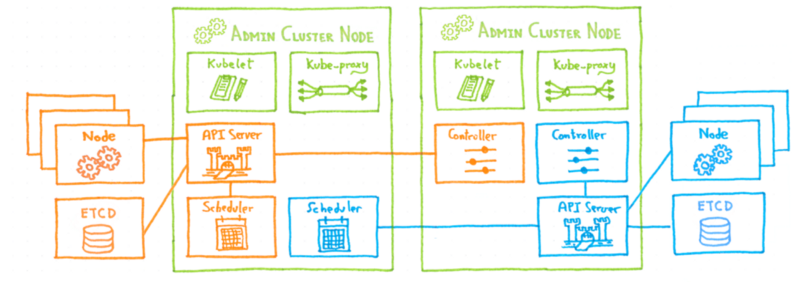
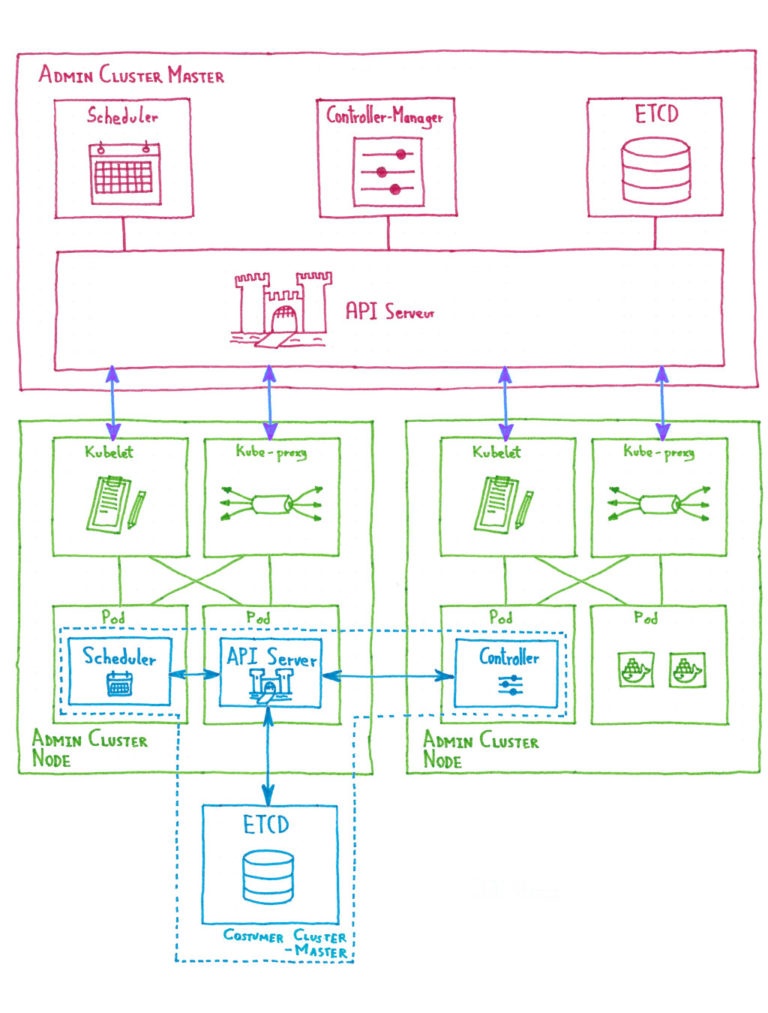
Как OVH управляет CI / CD в масштабе?
Процесс доставки — это набор шагов — от git commit до производства — которые выполняются для предоставления ваших услуг вашим клиентам. Опираясь на ценности Agile, непрерывная интеграция и непрерывная доставка (CI / CD) — это практики, которые нацелены на максимальную автоматизацию этого процесса.
Команда непрерывной доставки в OVH выполняет одну основную задачу: помочь разработчикам OVH индустриализировать и автоматизировать их процессы доставки. Команда CD здесь, чтобы отстаивать передовой опыт CI / CD и поддерживать наши инструменты экосистемы, уделяя максимальное внимание решениям как услуги.

Центром этой экосистемы является инструмент CDS, разработанный в OVH.
CDS — это программное решение с открытым исходным кодом, которое можно найти по адресу https://github.com/ovh/cds, с документацией по адресу https://ovh.github.io/cds .
CDS — это третье поколение инструментов CI / CD в OVH, следующее за двумя предыдущими решениями, основанными на Bash, Jenkins, Gitlab и Bamboo. Это результат 12-летнего опыта в области CI / CD. Ознакомившись с большинством стандартных инструментов отрасли, мы обнаружили, что ни один из них полностью не соответствовал нашим ожиданиям в отношении четырех выявленных нами ключевых аспектов. Вот что пытается решить CDS.
Вот эти четыре аспекта:
Ресурсы / рабочие CDS запускаются по запросу , чтобы гарантировать пользователям малое время ожидания без чрезмерного потребления простаивающих ресурсов.
В CDS любые действия (развертывание Kubernetes и OpenStack, отправка в Kafka, тестирование CVE…) могут быть записаны в подключаемых модулях высокого уровня , которые будут использоваться пользователями в качестве строительных блоков . Эти плагины просты в написании и использовании, поэтому легко и эффективно удовлетворить самые экзотические потребности..
CDS может запускать сложные рабочие процессы со всевозможными промежуточными этапами, включая сборку, тестирование, развертывание 1/10/100, ручные или автоматические шлюзы, откат, условные переходы… Эти рабочие процессы могут храниться в виде кода в репозитории git. CDS предоставляет базовые шаблоны рабочих процессов для наиболее распространенных сценариев основной группы, чтобы упростить процесс внедрения. Таким образом, создание функциональной цепочки CI / CD из ничего может быть быстрым и легким.
Наконец, ключевым аспектом является идея самообслуживания . После того, как проект CDS создается пользователями, они становятся полностью автономными в этом пространстве, с возможностью управлять конвейерами, делегировать права доступа и т. Д. Все пользователи могут свободно настраивать свое пространство по своему усмотрению и использовать то, что предоставляется. из коробки. Персональная настройка шаблонов рабочих процессов, подключаемых модулей, запуск сборки и тестов на настраиваемых вариантах виртуальных машин или настраиваемом оборудовании… все это можно сделать без какого-либо вмешательства со стороны администраторов CDS.
Одной из первоначальных задач CDS в OVH было создание и развертывание 150 приложений в виде контейнера менее чем за семь минут. Это стало реальностью с 2015 года. Так в чем же секрет? Автоматическое масштабирование по запросу!
При таком подходе у вас могут быть сотни рабочих моделей, которые CDS будет запускать через инкубатории при необходимости.
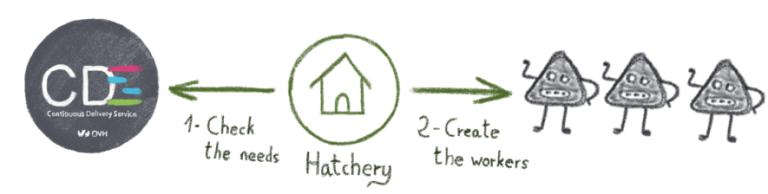
Инкубаторий похож на инкубатор: он рождает рабочих CDS и поддерживает над ними власть жизни и смерти.
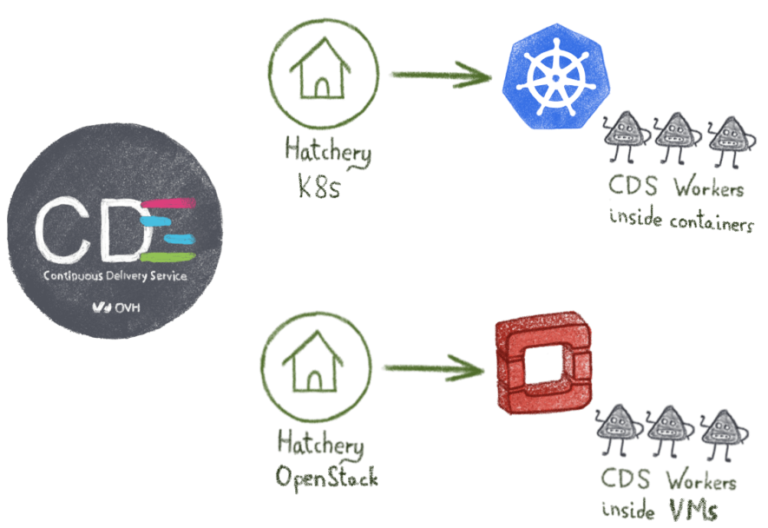
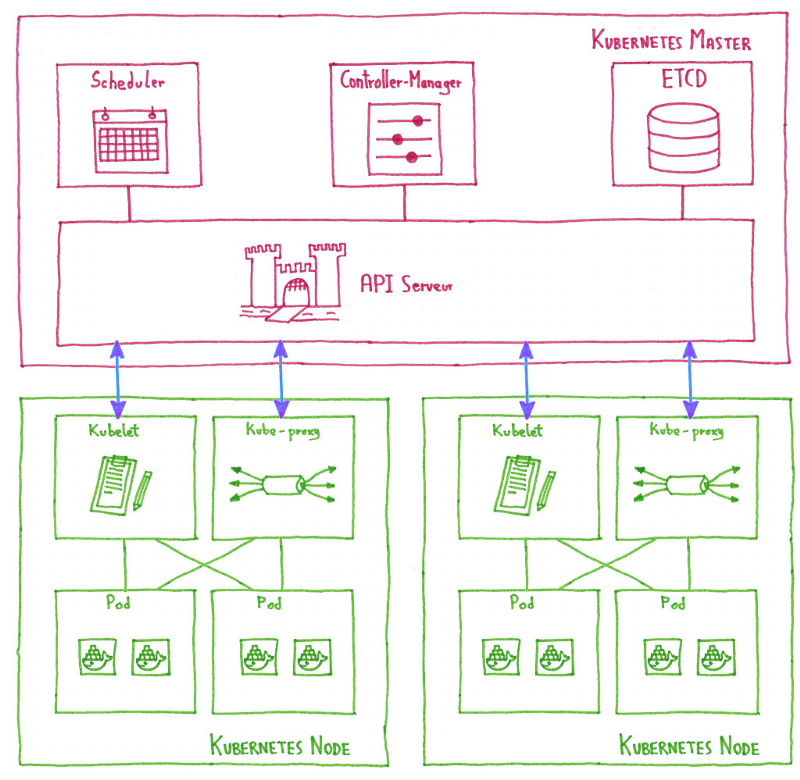
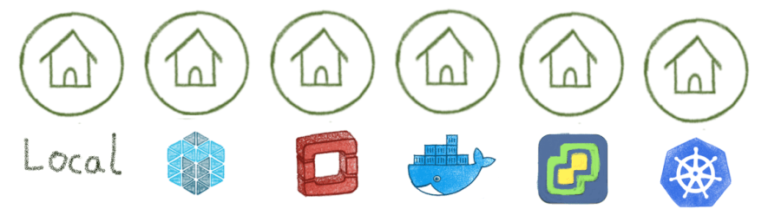
Каждый инкубаторий предназначен для оркестратора. Кроме того, один инстанс CDS может создавать рабочих на многих облачных платформах:
— Инкубаторий Kubernetes запускает рабочих в контейнерах
— Инкубаторий OpenStack запускает виртуальные машины
— Инкубаторий Swarm запускает докерные контейнеры
— Инкубаторий Marathon запускает докерные контейнеры
— Инкубаторий VSphere запускает виртуальные машины
— местный инкубатор запускает процесс на хосте
Это всего лишь предварительный просмотр CDS … Нам есть о чем вам рассказать! Инструмент CI / CD предлагает широкий спектр функций, которые мы подробно рассмотрим в наших следующих статьях . Мы обещаем, что до завершения 2019 года вы больше не будете смотреть на свой инструмент CI / CD таким же образом ...
Команда непрерывной доставки в OVH выполняет одну основную задачу: помочь разработчикам OVH индустриализировать и автоматизировать их процессы доставки. Команда CD здесь, чтобы отстаивать передовой опыт CI / CD и поддерживать наши инструменты экосистемы, уделяя максимальное внимание решениям как услуги.
Центром этой экосистемы является инструмент CDS, разработанный в OVH.
CDS — это программное решение с открытым исходным кодом, которое можно найти по адресу https://github.com/ovh/cds, с документацией по адресу https://ovh.github.io/cds .
CDS — это третье поколение инструментов CI / CD в OVH, следующее за двумя предыдущими решениями, основанными на Bash, Jenkins, Gitlab и Bamboo. Это результат 12-летнего опыта в области CI / CD. Ознакомившись с большинством стандартных инструментов отрасли, мы обнаружили, что ни один из них полностью не соответствовал нашим ожиданиям в отношении четырех выявленных нами ключевых аспектов. Вот что пытается решить CDS.
Вот эти четыре аспекта:
Эластичный
Ресурсы / рабочие CDS запускаются по запросу , чтобы гарантировать пользователям малое время ожидания без чрезмерного потребления простаивающих ресурсов.
Расширяемый
В CDS любые действия (развертывание Kubernetes и OpenStack, отправка в Kafka, тестирование CVE…) могут быть записаны в подключаемых модулях высокого уровня , которые будут использоваться пользователями в качестве строительных блоков . Эти плагины просты в написании и использовании, поэтому легко и эффективно удовлетворить самые экзотические потребности..
Гибко, но легко
CDS может запускать сложные рабочие процессы со всевозможными промежуточными этапами, включая сборку, тестирование, развертывание 1/10/100, ручные или автоматические шлюзы, откат, условные переходы… Эти рабочие процессы могут храниться в виде кода в репозитории git. CDS предоставляет базовые шаблоны рабочих процессов для наиболее распространенных сценариев основной группы, чтобы упростить процесс внедрения. Таким образом, создание функциональной цепочки CI / CD из ничего может быть быстрым и легким.
Самообслуживание
Наконец, ключевым аспектом является идея самообслуживания . После того, как проект CDS создается пользователями, они становятся полностью автономными в этом пространстве, с возможностью управлять конвейерами, делегировать права доступа и т. Д. Все пользователи могут свободно настраивать свое пространство по своему усмотрению и использовать то, что предоставляется. из коробки. Персональная настройка шаблонов рабочих процессов, подключаемых модулей, запуск сборки и тестов на настраиваемых вариантах виртуальных машин или настраиваемом оборудовании… все это можно сделать без какого-либо вмешательства со стороны администраторов CDS.
CI / CD в 2018 году — пять миллионов сотрудников!
- Около 5,7 млн работников запускались и удалялись по запросу.
- 3,7 млн контейнеров
- 2M виртуальных машин
Как это возможно?
Одной из первоначальных задач CDS в OVH было создание и развертывание 150 приложений в виде контейнера менее чем за семь минут. Это стало реальностью с 2015 года. Так в чем же секрет? Автоматическое масштабирование по запросу!
При таком подходе у вас могут быть сотни рабочих моделей, которые CDS будет запускать через инкубатории при необходимости.
Инкубаторий похож на инкубатор: он рождает рабочих CDS и поддерживает над ними власть жизни и смерти.
Каждый инкубаторий предназначен для оркестратора. Кроме того, один инстанс CDS может создавать рабочих на многих облачных платформах:
— Инкубаторий Kubernetes запускает рабочих в контейнерах
— Инкубаторий OpenStack запускает виртуальные машины
— Инкубаторий Swarm запускает докерные контейнеры
— Инкубаторий Marathon запускает докерные контейнеры
— Инкубаторий VSphere запускает виртуальные машины
— местный инкубатор запускает процесс на хосте
Что дальше?
Это всего лишь предварительный просмотр CDS … Нам есть о чем вам рассказать! Инструмент CI / CD предлагает широкий спектр функций, которые мы подробно рассмотрим в наших следующих статьях . Мы обещаем, что до завершения 2019 года вы больше не будете смотреть на свой инструмент CI / CD таким же образом ...