Бизнес-аналитика (BI) — это способность собирать существенные данные из информационной системы для подачи в хранилище данных (DWH) или озеро данных. Обычно они предоставляют копию данных, которые будут использоваться для приложений бизнес-аналитики. Для подпитки DWH могут применяться разные стратегии. Одна из таких стратегий -
Change Data Capture (CDC), которая представляет собой способность фиксировать
изменяющиеся состояния из базы данных и преобразовывать их в
события, которые можно использовать для других целей. Большинство баз данных предназначены для целей
OLTP и хорошо для этого разработаны. Тем не менее, разные варианты использования потребуют одних и тех же данных с разными шаблонами доступа. Эти варианты использования (большие данные, ETL и потоковая обработка и др.) В основном подпадают под Баннер
OLAP . Их смешение поставит под угрозу OLTP и производственную среду, поэтому нам нужно включить OLAP ненавязчивым образом.
OVH, как облачный провайдер, управляет многочисленными базами данных как для своих клиентов, так и для собственных нужд. Управление жизненным циклом базы данных всегда включает в себя как поддержание инфраструктуры в актуальном состоянии, так и синхронизацию с циклом разработки, чтобы согласовать программное обеспечение с его зависимостью от базы данных. Например, приложению может потребоваться MySQL 5.0, который затем может быть объявлен как EOL (End Of Life). В этом случае приложение необходимо изменить для поддержки (скажем) MySQL 5.5. Мы не изобретаем велосипед здесь — этим процессом уже несколько десятилетий управляют операторы и команды разработчиков.
Это усложняется, если у вас нет контроля над приложением. Например, представьте, что третья сторона предоставляет вам приложение для обеспечения зашифрованных транзакций. У вас нет абсолютно никакого контроля над этим приложением или связанной с ним базой данных. Тем не менее, вам по-прежнему нужны данные из базы данных.
В этом сообщении в блоге описан аналогичный пример, с которым мы столкнулись при создании озера данных OVH с помощью собственной разработки CDC. Эта история происходит в начале 2015 года, хотя я все же думаю, что ею стоит поделиться.
Разработка ненавязчивого процесса сбора измененных данных
Обычно перед тем, как приступить к разработке, рекомендуется определить состояние технологии, поскольку это сэкономит время и укрепит сообщества. Еще в начале 2015 года, когда впервые появился ландшафт CDC (
Debezium , аналогичное решение с открытым исходным кодом, появилось только в конце того же года), единственное существующее решение — Databus — появилось от LinkedIn. Архитектура Databus была довольно сложной, и проект не был очень активным. Кроме того, это не решало наших требований к безопасности, и мы пришли из сильной культуры эксплуатации, поэтому запуск JVM на сервере базы данных был явно непозволительным для наших рабочих групп.
Хотя не существовало программного обеспечения CDC, соответствующего нашим требованиям, в конце концов мы нашли библиотеку репликации binlog, которую можно было бы интегрировать с некоторыми из них в Go. Binlog — это имя MySQL для базы данных WAL.
Наши требования были довольно простыми:
- Избегайте решений на основе JVM (JVM и контейнеры в то время не работали должным образом, и было бы трудно получить поддержку от Ops)
- Агент CDC, необходимый для подключения к шлюзу CDC для высокозащищенных сред (а не шлюзу для агентов)
- Шлюз CDC может контролировать флот своих агентов
- Агент CDC может фильтровать и сериализовать события, чтобы протолкнуть их с помощью контроля обратного давления.
- Агент CDC может сбросить БД, чтобы получить первый снимок, поскольку бинлоги не всегда доступны с самого начала.
Вот глобальный дизайн проекта Menura:
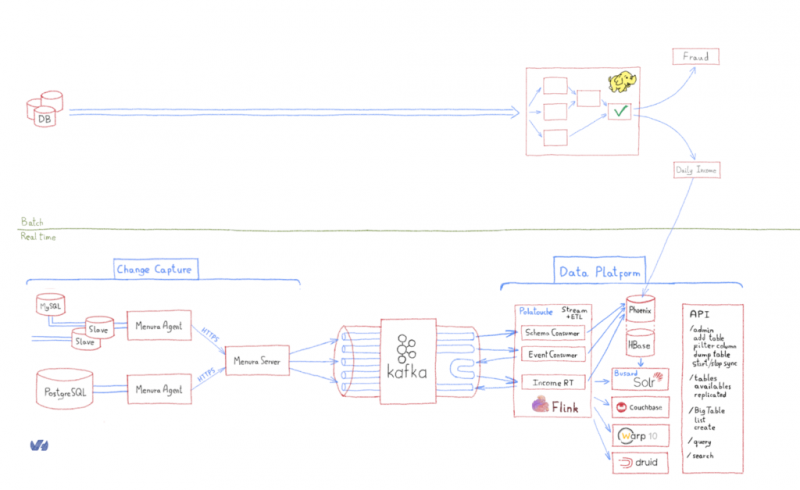
Менура — это род
лирохвостов : птицы, способные воспроизводить любой звук. Большинство BI связанных компонентов являются «птицы», так как они часть
B usiness
I ntelligence
R &
D проекта!
Автоматизация плоскости управления BI
Поскольку Menura была развернута на серверах баз данных, она могла отображать доступные базы данных и таблицы в
плоскости управления BI , чтобы пользователь мог запросить синхронизацию с заданной таблицей. Протокол управления имел несколько простых задач:
- Добавить и настроить источник базы данных
- Управление удаленной конфигурацией
- Картографический агент / картография таблиц
- Дамп таблиц базы данных
- Управление CDC (запуск / остановка синхронизации, фиксация смещений бинлогов…)
В то время gRPC только зарождался, но мы увидели в этом проекте, с его прочной основой, возможность примирить Protobuf, экономичность и языковое разнообразие. Кроме того, возможность настройки RPC с двунаправленной потоковой передачей была интересна с точки зрения реализации соединений клиент-сервер с RPC-серверами, поэтому мы сделали ее основой протокола управления.
gRPC использует
буфер протокола как IDL для сериализации структурированных данных. Каждый StreamRequest состоит из заголовка для управления мультитенантностью. Это означает, что если бы наши клиенты решили назвать свои источники одним и тем же именем, мы могли бы выделить управляющие сообщения по арендатору, а не только по источнику. Поэтому мы находим RequestType, как определено в Protobuf v3:
enum RequestType {
Control_Config = 0;
Control_Hearbeat = 1;
Control_MySQLClient = 10;
Control_MySQLBinlog = 11;
Control_Syslog = 12;
Control_PgSQLClient = 13;
Control_PgSQLWal = 14;
Control_PgSQLLogDec = 15;
Control_Kafka = 16;
Control_MSSQLClient = 17;
}
Этот RequestType позволил нам получить исходные плагины со специализированными структурами, которые они ожидают. Обратите внимание, что мы отделили клиентов БД от репликации БД (binlog, WAL…). Основная причина в том, что они не имеют одной и той же области видимости, поэтому библиотеки не совпадают. Поэтому имело смысл держать их отдельно.
Другая причина заключается в том, что репликация действует как подчиненное устройство для базы данных, что означает, что процесс репликации не занимает значительного места, в то время как клиент, сбрасывающий базу данных, может подразумевать блокировку строк или таблиц, учитывая базу данных и ее обрабатывающий механизм. Это могло привести к тому, что у нас будет два разных ведомых устройства, или репликация будет подключена к ведущему устройству, а клиент — к ведомому.
Эти опасения подтолкнули нас к модульной конструкции агента Menura:
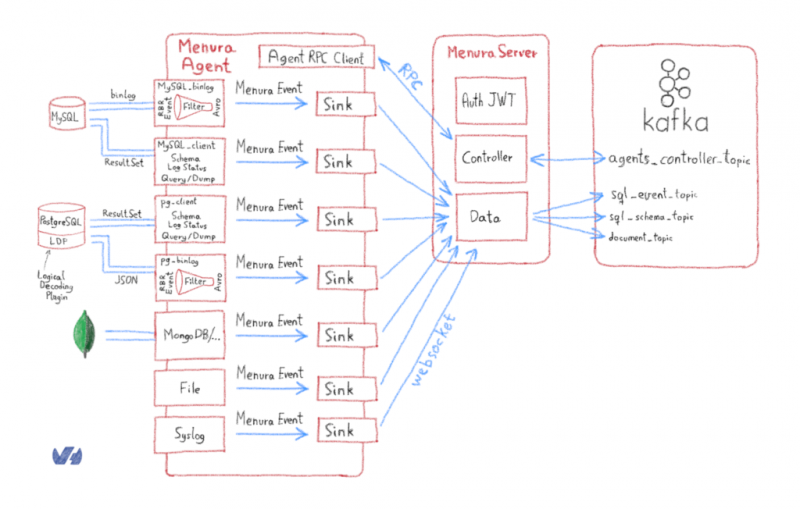
Фильтрация данных
Важной функцией была возможность фильтровать события или столбцы. На то было две причины:
- Мы столкнулись с базами данных с таким количеством таблиц или столбцов, что нам потребовалось немного снизить уровень шума.
- Нам не обязательно нужно было получать определенные данные из базы данных
Фильтрация ближе всего к базе данных, безусловно, была лучшим выбором, особенно для наших клиентов, поскольку они могли добавлять или проверять фильтры сами. Для этого мы определили
политику фильтрации, которая имитирует политики IPTables с
принятием или
удалением значений по умолчанию. Затем исходный фильтр описал, как таблицы и столбцы будут вести себя в зависимости от политики:
filter_policy: accept/drop
filter:
table_a:
table_b:
ignored_columns:
— sensibleColumn
Падение политик упадет что - нибудь по умолчанию, за исключением таблиц явно перечисленных в фильтре, в то время как
принимать политик удалять таблицы , перечисленные в качестве пустой в фильтре, за исключением таблиц , которые имеют
ignored_columns ключ, чтобы фильтр только столбцы с их именами.
Валидации в гетерогенных системах
В некоторых случаях вы можете подтвердить, что обрабатываете аналитическое задание на тех же данных, из которых состоит настоящая база данных. Например, для расчета выручки за определенный период требуются достоверные данные от даты до даты. Проверка состояния репликации между базой данных и озером данных была сложной задачей. На самом деле проверки целостности не реализуются с той же логикой в базах данных или хранилищах, поэтому нам нужен был способ абстрагировать их от собственной реализации. Мы подумали об использовании структуры данных
Merkle Tree , чтобы мы могли поддерживать дерево целостности с блоками или строками. Если ключ / значение отличается от базы данных, то это будет отражать глобальный или промежуточный хэш целостности, и нам нужно будет сканировать только листовой блок, который имеет несогласованный хэш между обеими системами.
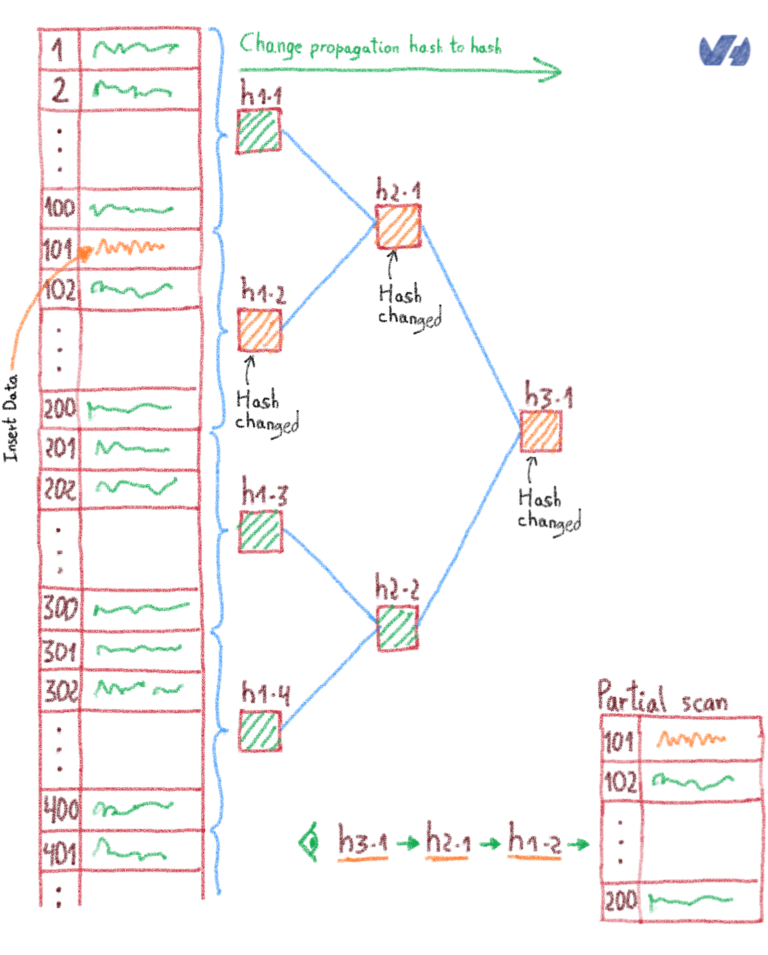
Соберем все вместе
Как мы уже говорили во введении, CDC настроен на преобразование изменений базы данных в обрабатываемые события. Цель здесь — эффективно и действенно удовлетворять любые бизнес-потребности, требующие данных. Вот два примера того, что мы сделали с данными, которые теперь были доступны в виде событий…
Соединения между базами данных в реальном времени
Пока мы строили озеро данных из реплицированных таблиц, и поскольку этот проект был в основном для целей бизнес-аналитики, мы рассмотрели возможность добавления некоторых аналитических данных в реальном времени на основе той же логики, которую мы используем с пакетными заданиями и заданиями
Apache Pig . С 2015 года самой продвинутой структурой обработки потоков является
Apache Flink , которую мы использовали для обработки соединений в реальном времени между различными базами данных и таблицами.
Алексис проделал потрясающую работу, описав процесс соединения, который мы внедрили в Apache Flink, так что в дополнение к репликации баз данных мы также создали новую агрегированную таблицу. В самом деле, мы могли бы написать целую запись в блоге только по этой теме ...
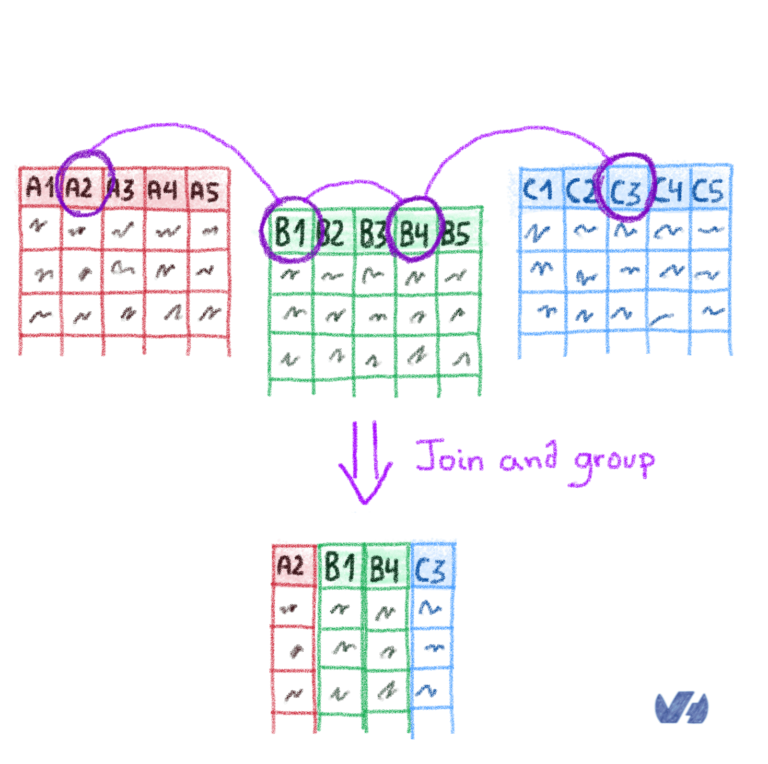
Мы выбрали Apache Flink по нескольким причинам:
- Его документация была восхитительной
- Его основной движок был великолепен и намного превосходил Apache Spark (проекта Tungsten там даже не было).
- Это был европейский проект , поэтому мы были близки к редактору и его сообществу.
Индексирование в реальном времени
Теперь у нас есть таблица реального времени, загруженная в
Apache HBase , и нам нужно было добавить к ней возможность запросов. Хотя HBase был хорош с точки зрения хранения, он не предоставлял никаких возможностей поиска, а его схема доступа не была идеальной для сканирования по критерию поиска.
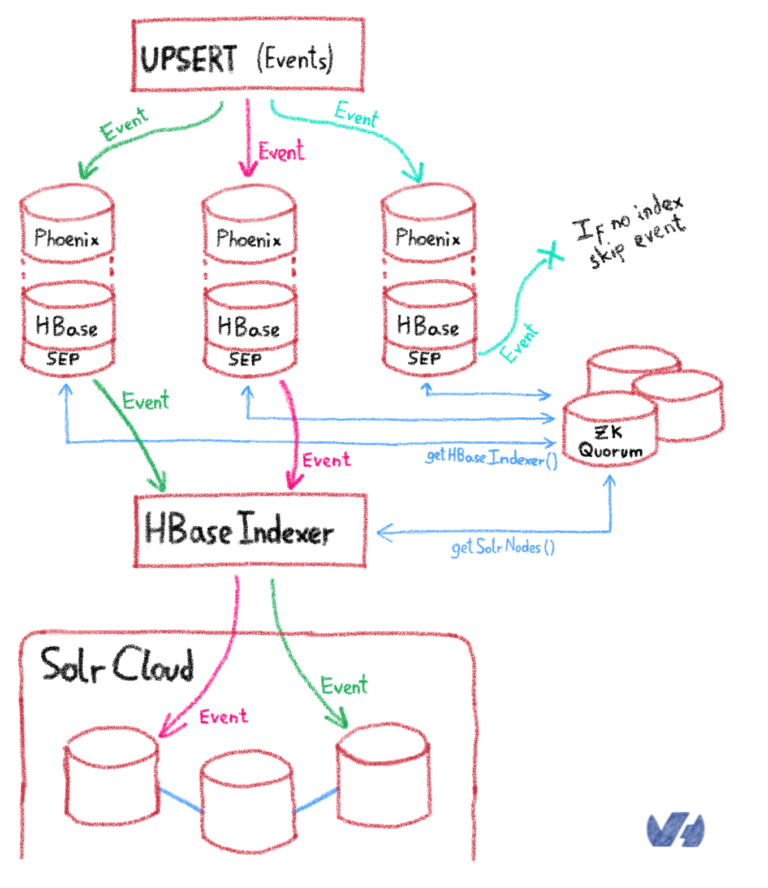
Здесь
Гийом сотворил чудо! Повторно используя
Lily , индексатор HBase, предоставляющий концепцию SEP (обработчик побочных эффектов), ему удалось повторно внедрить схему агрегированной таблицы в Lily, чтобы построить отображение типов данных, необходимое для чтения значений байтовых массивов HBase, перед их индексированием в Solr. Теперь у нас была
панель мониторинга в
реальном времени, представляющая собой агрегированную объединенную таблицу в реальном времени, обработанную на основе сбора данных об изменении в реальном времени. Бум!
Именно тогда мы начали привлекать реальных клиентов к нашему новому решению.
Жить!
Если по-прежнему существует необходимость продемонстрировать, что тестирование в среде моделирования — это не то же самое, что тестирование в производственной среде, эта следующая часть, вероятно, разрешит спор…
После настройки конвейера данных мы обнаружили несколько ошибок в производственной среде. Вот два из них:
Чередующиеся события
Согласно определению MySQL, структура события состоит из заголовка и поля данных.
В
репликации на основе строк (RBR), в отличие от
репликации на основе операторов (SBR), событие каждой строки реплицируется с соответствующими данными. Операторы DML разделены на две части:
- А TABLE_MAP_EVENT
- A ROWS_EVENT(может быть WRITE, UPDATEили DELETE)
Первое событие, TABLE_MAP_EVENTописывает метаданные содержимого второго события. Эти метаданные содержат:
- Включенные поля
- Растровые изображения с нулевыми значениями
- Схема предстоящих данных
- Метаданные для предоставленной схемы
Второе событие WRITE_ROWS_EVENT(для вставок) содержит данные. Чтобы декодировать его, вам нужно, чтобы предыдущее TABLE_MAP_EVENTсобытие знало, как использовать это событие, сопоставляя соответствующее MYSQL_TYPE_* и считывая количество байтов, ожидаемых для каждого типа.
Иногда некоторые события не обрабатывались должным образом, поскольку несогласованность между метаданными и данными приводила к VARCHARдекодированию DATETIMEзначений как значений и т. Д.
После некоторой отладки выяснилось, что команда DBA добавила триггеры в некоторые таблицы MySQL. Когда несколько дней спустя реплики были перестроены, они унаследовали эти функции и начали регистрировать события, производимые этими триггерами.
Дело в том, что в MySQL триггеры являются внутренними. В binlog каждое событие, исходящее от мастера, отправляется следующим образом:
TableMapEvent_a
TableMapEvent_a
WriteEvent_a
TableMapEvent_b
WriteEvent_b
TableMapEvent_c
WriteEvent_c
a, bи cпредставляет события для разных таблиц schema.tables.
Поскольку триггеры не поступают от ведущего устройства, когда ведомое устройство получает a TableMapEventдля определенной таблицы, оно запускает другой TableMapEvent для специализированной таблицы (
_event). То же самое относится и к WriteEvent.
Когда MySQL запускает событие, он отправляет его в двоичный журнал, поэтому вы закончите мультиплексированием двух TableMapEvents, а затем двух RowsEvents, как показано ниже:TableMapEvent_a
TableMapEvent_a_event
WriteEvent_a
WriteEvent_a_event
Понял! Когда мы пытались декодировать WriteEvent_a, предыдущее TableMapEvent предназначалось для TableMapEvent_a_event, а не для TableMapEvent_a, поэтому он пытался декодировать событие с неправильной схемой.
Нам нужно было найти способ сопоставить WriteEvent с соответствующим TableMapEvent. В идеале в структуре должен был быть TableID, который мы могли бы использовать для этого. В конце концов, нам просто нужно было буферизовать все TableMapEvents, сделав их доступными для всех RowsEvent, начать чтение RowsEvent, выбрать TableID, а затем получить метаданные Columns из соответствующего TableMapEvent. Исправлена!
Неуловимая десятичная дробь ...
Мы также столкнулись с произвольной ошибкой в библиотеке, из-за которой Menura взорвалась. И снова мы углубились в библиотеку binlog, чтобы шаг за шагом отладить процесс декодирования. Мы определили кортежи таблицы / столбца, чтобы ограничить вывод журнала до более разумной скорости. А RowEventвыглядело так:DEBUG MR: TableMapEvent.read() : event.TableName = myTable
DEBUG MR: TableMapEvent.read() : columnCount= 16
DEBUG MR: TableMapEvent.read() : Read Next columnTypeDef= [3 3 15 246 0 0 12 0 15 12 12 15 3 3 15 15]
DEBUG MR: readStringLength() : r.Next(int(12))
DEBUG MR: TableMapEvent.read() : ReadStringLength columnMetaDef= [255 0 10 2 40 0 10 0 255 0 255 3]
DEBUG MR: TableMapEvent.read() : columnNullBitMap= [10 198]
DEBUG MR: TableMapEvent.read() : switch columnTypeDef[3]=f6
DEBUG MR: TableMapEvent.read() : switch : case metaOffset+=2
DEBUG MR: TableMapEvent.read() : column.MetaInfo
DEBUG MR: TableMapEvent.read() : column.MetaInfo = [10 2]
В этом журнале есть довольно интересные части процесса декодирования, на которые стоит обратить внимание. В первом столбце представлена следующая схема:TableMapEvent.read() : Read Next columnTypeDef= [3 3 15 246 0 0 12 0 15 12 12 15 3 3 15 15]
Некоторые из этих типов данных требуют чтения метаданных. Например, вот соответствующий журнал с метаданными столбца:TableMapEvent.read() : ReadStringLength columnMetaDef= [255 0 10 2 40 0 10 0 255 0 255 3]
Кроме того, NullBitMapважен столбец, так как мы должны знать, какие нулевые значения следует игнорировать при декодировании буфера.
Этот сбой происходил не каждый день, и трассировка стека не указывала мне на фиксированную часть кода. Похоже на сдвиг в декодировании, который может вызвать произвольные сбои, когда приведение типов данных невозможно. Для отладки на более глубоком уровне нам нужно было регистрировать больше. Итак, мы зарегистрировали текущее смещение буфера, размер, прочитанный для каждого типа данных, метаданные для каждого типа данных и значение. Вот пример
DEBUG MR: rowsEvent.read(): pack.Len() BEFORE : 59
DEBUG MR: rowsEvent.read(): Column.MetaInfo: &{246 [10 2] true}
DEBUG MR: rowsEvent.read(): switch column.Type= 246
DEBUG MR: case MYSQL_TYPE_NEWDECIMAL
DEBUG MR: readNewDecimal() precision= 10 scale= 2
DEBUG MR: readNewDecimal() size= 5
DEBUG MR: readNewDecimal() buff=8000000000
DEBUG MR: readNewDecimal() decimalpack=0000000000
DEBUG MR: rowsEvent.read(): pack.Len() AFTER : 54
DEBUG MR: rowsEvent.read(): value : 0
DEBUG MR: rowsEvent.read(): pack.Len() BEFORE : 54
DEBUG MR: rowsEvent.read(): Column.MetaInfo: &{0 [] false}
DEBUG MR: rowsEvent.read(): switch column.Type= 0
Что касается предыдущей схемы, у нас есть 16 столбцов, и согласно документации MySQL наши типы данных предоставляют метаданные, как в следующей таблице: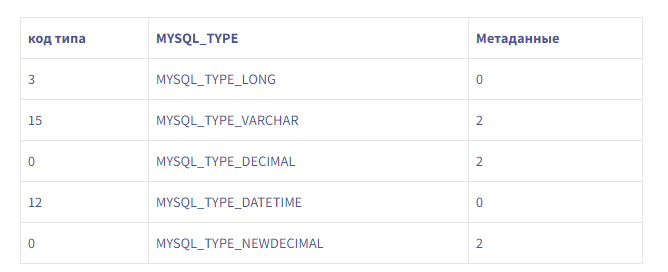 Это дает нам 18 байтов метаданных для схемы этого примера, в отличие от 10 байтов в пакете.Мы также обнаружили, что MySQL явно не отправлял метаданные, необходимые для чтения DECIMALзначений в пакете. Было ли это нормальным поведением?Документация MySQL ясна: чтобы прочитать DECIMALзначение, вам нужны метаданные (точность, масштаб и т. Д.). Период.Однако мы обнаружили, что с этим MYSQL_TYPE_DECIMALобращались как MYSQL_TYPE_NEWDECIMAL.
Это дает нам 18 байтов метаданных для схемы этого примера, в отличие от 10 байтов в пакете.Мы также обнаружили, что MySQL явно не отправлял метаданные, необходимые для чтения DECIMALзначений в пакете. Было ли это нормальным поведением?Документация MySQL ясна: чтобы прочитать DECIMALзначение, вам нужны метаданные (точность, масштаб и т. Д.). Период.Однако мы обнаружили, что с этим MYSQL_TYPE_DECIMALобращались как MYSQL_TYPE_NEWDECIMAL.case MYSQL_TYPE_DECIMAL, MYSQL_TYPE_NEWDECIMAL:
value.value = pack.readNewDecimal(int(column.MetaInfo[0]), int(column.MetaInfo[1]))
Мы отступили и стали искать, как это MYSQL_TYPE_DECIMALреализовано в других библиотеках binlog. Я не был администратором баз данных, но мне показалось странным, что в схеме, использующей DECIMALзначения, на самом деле используются два разных типа данных MySQL.
Хорошо… «Хьюстон, у нас проблема».
Во-первых, никто не внедрял его MYSQL_TYPE_DECIMAL, и по очень веской причине: мы не должны его получать, поскольку он устарел из MySQL, начиная с версии 5.0. Это означало, что в базе данных, лежащей в основе, работала таблица, созданная (в лучшем случае) из MySQL 4.9, в то время как база данных была обновлена без надлежащего ALTER для автоматического преобразования типов данных в MYSQL_TYPE_NEWDECIMAL.
Во-вторых, поскольку у нас нет никакого контроля над базой данных, как нам декодировать MYSQL_TYPE_DECIMAL…
Первая попытка: игнорировать
Сначала мы обошли эту проблему, фактически не прочитав два байта метаданных при анализе MYSQL_TYPE_DECIMALстолбца. Это остановило повреждение смещения метаданных, и другие типы данных теперь были согласованы с их метаданными.
Мы пропустили десятичное значение, но мы могли продолжить чтение других типов данных. Ну, вроде того… Так было лучше, но для того, чтобы читать значения после a MYSQL_TYPE_DECIMALв буфере данных, нам нужно было знать, сколько байтов нужно прочитать.Вторая попытка: наивный подход (т.е. догадки!)
Десятичное значение — это дробное число, обычно кодируемое как число с плавающей запятой. Например, в DECIMAL(10,2)столбце восемь разрядов целого числа и две цифры дробной части. Целые цифры определяют количество байтов, которые необходимо прочитать. Например, мы читаем четыре байта для целой части и один байт для дробной части. Это было бы так просто… если бы у нас были метаданные.
На практике MySQL не предоставляет никаких метаданных для DECIMALзначений, поэтому мы проигнорировали их в первой итерации, чтобы сохранить другие данные. Вы когда-нибудь пробовали декодировать старые бинлоги с помощью официального инструмента mysqlbinlog? Если бы у вас был MYSQL_TYPE_DECIMALв ваших данных, то он бы перестал там декодировать. Да… MySQL не умеет декодировать собственный формат данных!
Кто-то может возразить, что если MySQL не предоставляет никаких метаданных, это потому, что он хранит их внутри, в фиксированном размере. Ну нет!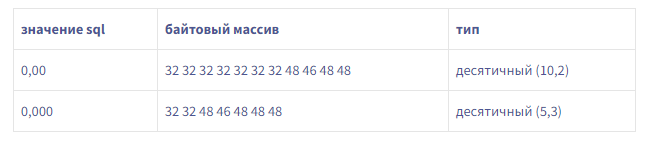
Вот как это работает… Десятичные числа в протоколе кодируются как VARCHAR. Я попытался прочитать значение, предполагая, что пробел заполнен, отметил обнаруженную точку и попытался прочитать дробные данные, которые казались последовательными для десятичной дроби. Если это не так, я, в конце концов, не прочитал последний байт в буфере и перешел к следующему типу данных. И это сработало. В течение времени…DEBUG MR: case MYSQL_TYPE_DECIMAL
DEBUG MR: readOldDecimalV2: byte = 32
DEBUG MR: readOldDecimalV2: continue
DEBUG MR: readOldDecimalV2: byte = 32
DEBUG MR: readOldDecimalV2: continue
DEBUG MR: readOldDecimalV2: byte = 32
DEBUG MR: readOldDecimalV2: continue
DEBUG MR: readOldDecimalV2: byte = 32
DEBUG MR: readOldDecimalV2: continue
DEBUG MR: readOldDecimalV2: byte = 32
DEBUG MR: readOldDecimalV2: continue
DEBUG MR: readOldDecimalV2: byte = 32
DEBUG MR: readOldDecimalV2: continue
DEBUG MR: readOldDecimalV2: byte = 32
DEBUG MR: readOldDecimalV2: continue
DEBUG MR: readOldDecimalV2: byte = 48
DEBUG MR: readOldDecimalV2: start writing
DEBUG MR: readOldDecimalV2: byte = 46
DEBUG MR: readOldDecimalV2: dot found
DEBUG MR: readOldDecimalV2: writing
DEBUG MR: readOldDecimalV2: byte = 48
DEBUG MR: readOldDecimalV2: writing
DEBUG MR: readOldDecimalV2: byte = 48
DEBUG MR: readOldDecimalV2: writing
DEBUG MR: readOldDecimalV2: byte = 32
DEBUG MR: readOldDecimalV2: unread, break
DEBUG MR: readOldDecimalV2: converting to float : 0.00
DEBUG MR: rowsEvent.read(): pack.Len() AFTER : 43
DEBUG MR: rowsEvent.read(): value : 0
Мы надеемся, что мы не встретим следующий тип VARCHAR с длиной, которую можно было бы проанализировать как значение DIGIT, но динамический размер значения DECIMAL означает, что должны быть доступны метаданные для правильного чтения. Другого пути нет.
Третья попытка: когда дело доходит до хорошего раба, компромиссов нет!
Мы спросили себя, что отличает mysqlbinlog от MySQL Slave, когда дело доходит до чтения двоичных журналов. Мы обнаружили, что единственная разница заключалась в том, что истинное ведомое устройство знало DECIMALсхему и связанные с ней метаданные при получении этих данных. Таким образом, ему не пришлось бы ничего гадать — просто прочтите нужное количество байтов в соответствии с известной схемой.
В итоге мы реализовали клиент MySQL в нашем источнике mysqlbinlog, который изначально сбрасывал схемы таблиц для передачи значения NumericScale в библиотеку декодирования. Проблема здесь в том, что строки не идентифицируются в схемах по их ColumnName. MySQL поддерживает OrdinalPositionстолбцы в таблице, но это не идентификатор, указанный в протоколе binlog (это было бы слишком просто!). Вы должны поддерживать свой собственный индекс столбца из схемы, чтобы он соответствовал тому, который вы получите в протоколе binlog. Как только он у вас есть, просто найдите значение десятичной шкалы, чтобы узнать, сколько байтов вам еще нужно прочитать после точки.
Таким образом, библиотека декодирования теперь могла декодировать MYSQL_TYPE_DECIMALиз потока событий binlog. Ура!!!TL; DR
В итоге создание стека бизнес-аналитики с нуля заняло примерно шесть месяцев. В команду входило 2,5 человека: Алексис Жендронно, Гийом Салоу (который присоединился к нам через три месяца) и я. Он продемонстрировал принцип сбора измененных данных, применяемый к реальным вариантам использования, позволяя в реальном времени получать информацию о продажах, запасах и многом другом, без какого-либо влияния на производственную среду. Команда росла по мере расширения масштабов проекта за счет новых, более требовательных клиентов, таких как группы финансовых услуг и управленческого контроля. Спустя несколько недель нам удалось запустить его на Apache Flink на основе того же конвейера данных, который с тех пор стал надежным источником для расчета доходов и других бизнес-KPI.
Мы многому научились из этого проекта. Ключевой урок заключается в том, насколько важным может быть контроль над вашим техническим долгом и какое влияние это может оказать на другие команды и проекты. Кроме того, работа с Apache Flink над рядом проектов оказалась прекрасным опытом для наших команд.
Вся команда проделала отличную работу, и Димитри Капитан собирается открыть исходный код агента сбора данных, который использовался в предварительных лабораториях: сборщик данных OVH. Если вы заинтересованы в более подробном обсуждении системы отслеживания измененных данных в OVH, не стесняйтесь присоединиться к нам в Gitter команды или написать мне в Twitter.