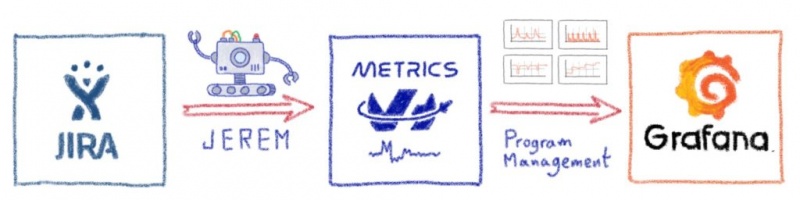
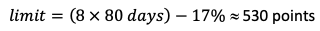Делаем БОЛЬШУЮ автоматизацию с помощью Celery
Вступление
TL; DR: вы можете пропустить вступление и сразу перейти к «Celery — Distributed Task Queue».
Здравствуйте! Меня зовут Бартош Рабьега, я работаю в команде R & D / DevOps в OVHcloud. В рамках нашей повседневной работы мы разрабатываем и поддерживаем проект Ceph-as-a-Service, чтобы обеспечить надежное распределенное хранилище высокой доступности для различных приложений. Мы имеем дело с более чем 60 ПБ данных в 10 регионах, поэтому, как вы можете себе представить, у нас впереди довольно много работы с точки зрения замены вышедшего из строя оборудования, обработки естественного роста, предоставления новых регионов и центров обработки данных, оценки нового оборудования, оптимизация конфигураций программного и аппаратного обеспечения, поиск новых решений для хранения данных и многое другое!
Из-за большого объема нашей работы нам нужно разгрузить как можно больше повторяющихся задач. И мы делаем это с помощью автоматизации.
Автоматизация вашей работы
В некоторой степени каждый ручной процесс можно описать как набор действий и условий. Если бы нам каким-то образом удалось заставить что-то автоматически выполнять действия и проверять условия, мы могли бы автоматизировать процесс, что привело бы к автоматизированному рабочему процессу. Взгляните на пример ниже, в котором показаны некоторые общие шаги по ручной замене оборудования в нашем проекте.
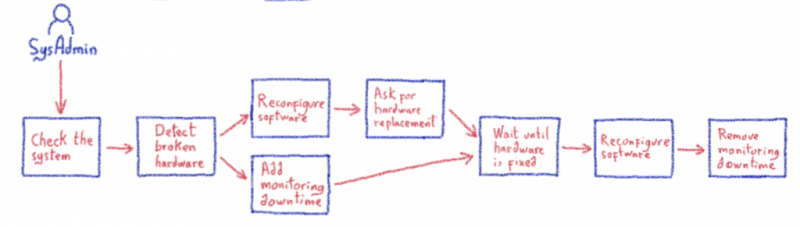
Хм… Что может помочь нам сделать это автоматически? Разве компьютер не кажется идеальным?
Сельдерей — распределенная очередь задач
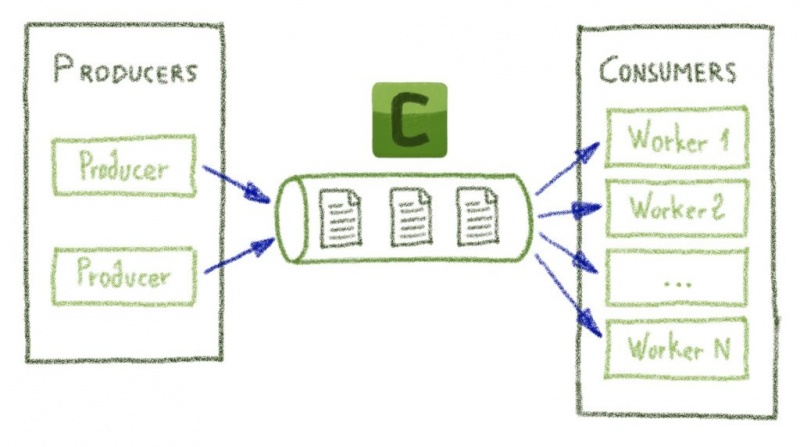
Celery — это хорошо известное и широко используемое программное обеспечение, которое позволяет нам обрабатывать задачи асинхронно. Описание проекта на его главной странице ( www.celeryproject.org/ ) может показаться немного загадочным, но мы можем сузить его базовую функциональность до примерно следующего:
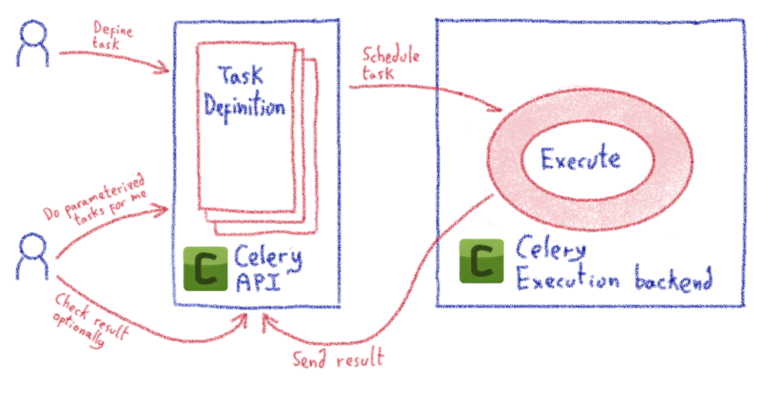
Такой механизм идеально подходит для таких задач, как асинхронная отправка электронных писем (например, «запустил и забыл»), но его также можно использовать для различных целей. Так с какими еще задачами он справился? В принципе, любые задачи можно реализовать на Python (основном языке Celery)! Я не буду вдаваться в подробности, поскольку они доступны в документации по Celery. Важно то, что, поскольку мы можем реализовать любую задачу, которую захотим, мы можем использовать ее для создания строительных блоков для нашей автоматизации.
Есть еще одна важная вещь… Celery изначально поддерживает объединение таких задач в рабочие процессы (примитивы Celery: цепочки, группы, аккорды и т. Д.). Итак, давайте рассмотрим несколько примеров…
Мы будем использовать следующие определения задач — одиночная задача, печать аргументов и kwargs:
@celery_app.task
def noop(*args, **kwargs):
# Task accepts any arguments and does nothing
print(args, kwargs)
return TrueТеперь мы можем выполнить задачу асинхронно, используя следующий код:
task = noop.s(777)
task.apply_async()Элементарные задачи можно параметризовать и объединить в сложный рабочий процесс с использованием методов сельдерея, то есть «цепочки», «группы» и «хорды». См. Примеры ниже. В каждом из них левая сторона показывает визуальное представление рабочего процесса, а правая — фрагмент кода, который его генерирует. Зеленая рамка — это отправная точка, после которой выполнение рабочего процесса продвигается по вертикали.
Цепочка — набор задач, обрабатываемых последовательно

workflow = (
chain([noop.s(i) for i in range(3)])
)Группа — набор параллельно обрабатываемых задач.
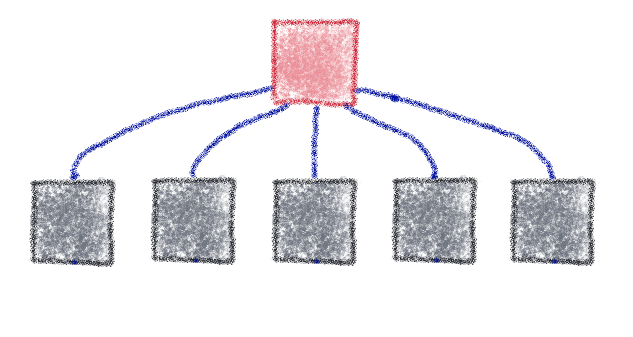
workflow = (
group([noop.s(i) for i in range(5)])
)Аккорд — группа задач, связанных со следующей задачей
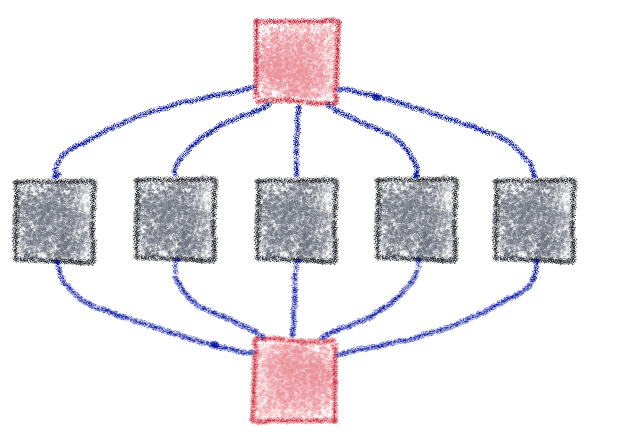
workflow = chord(
[noop.s(i) for i in range(5)],
noop.s(i)
)
# Equivalent:
workflow = chain([
group([noop.s(i) for i in range(5)]),
noop.s(i)
])Важный момент: выполнение рабочего процесса всегда останавливается в случае сбоя задачи. В результате цепочка не будет продолжена, если какая-то задача не удастся в ее середине. Это дает нам довольно мощный фреймворк для реализации аккуратной автоматизации, и именно это мы используем для Ceph-as-a-Service в OVHcloud! Мы реализовали множество небольших, гибких, параметризуемых задач, которые мы объединяем для достижения общей цели. Вот несколько реальных примеров элементарных задач, используемых для автоматического удаления старого оборудования:
- Изменить вес узла Ceph (используется для увеличения / уменьшения количества данных на узле. Запускает ребалансировку данных)
- Установите время простоя службы (перебалансировка данных запускает зонды мониторинга, но это ожидается, поэтому установите время простоя для этой конкретной записи мониторинга)
- Подождите, пока Ceph не станет здоровым (дождитесь завершения ребалансировки данных — повторяющаяся задача)
- Удалите узел Ceph из кластера (узел пуст, поэтому его можно просто удалить)
- Отправьте информацию техническим специалистам в DC (оборудование готово к замене)
- Добавить новый узел Ceph в кластер (установить новый пустой узел)
Мы параметризируем эти задачи и связываем их вместе, используя цепочки, группы и аккорды сельдерея для создания желаемого рабочего процесса. Затем Celery сделает все остальное, асинхронно выполняя рабочий процесс.
Большие рабочие процессы и сельдерей
По мере роста нашей инфраструктуры растут и наши автоматизированные рабочие процессы, с увеличением количества задач на рабочий процесс, более высокой сложностью рабочих процессов… Что мы понимаем под большим рабочим процессом? Рабочий процесс, состоящий из 1000-10 000 задач. Чтобы визуализировать это, взгляните на следующие примеры:
Несколько аккордов, связанных вместе (всего 57 заданий)
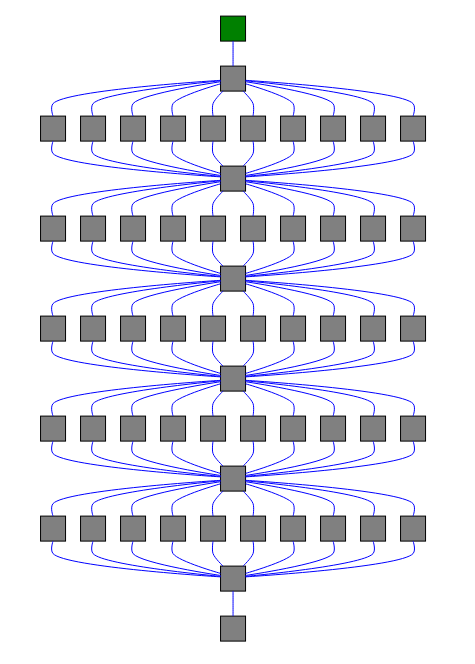
workflow = chain([
noop.s(0),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
noop.s()
])Более сложная структура графа, построенная из цепочек и групп (всего 23 задачи)
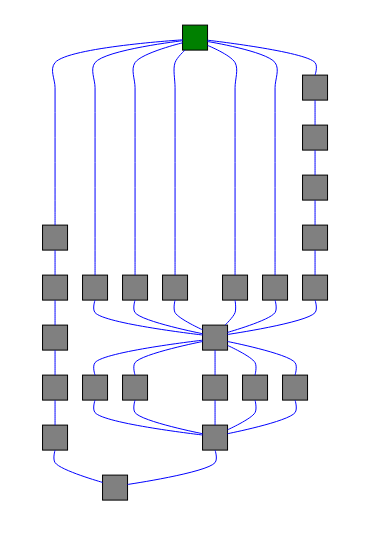
# | is ‘chain’ operator in celery
workflow = (
group(
group(
group([noop.s() for i in range(5)]),
chain([noop.s() for i in range(5)])
) |
noop.s() |
group([noop.s() for i in range(5)]) |
noop.s(),
chain([noop.s() for i in range(5)])
) |
noop.s()
)Как вы, наверное, догадались, когда задействовано 1000 задач, визуализация становится довольно большой и беспорядочной! Celery — мощный инструмент, обладающий множеством функций, которые хорошо подходят для автоматизации, но он по-прежнему испытывает трудности, когда дело доходит до обработки больших, сложных и длительных рабочих процессов. Организовать выполнение 10 000 задач с различными зависимостями — нетривиальная вещь. Когда наша автоматизация стала слишком большой, мы столкнулись с несколькими проблемами:
- Проблемы с памятью во время построения рабочего процесса (на стороне клиента)
- Проблемы с сериализацией (клиент -> бэкэнд-передача сельдерея)
- Недетерминированное, прерывистое выполнение рабочих процессов
- Проблемы с памятью у рабочих Celery (серверная часть Celery)
- Исчезающие задачи
- И более…
Взгляните на GitHub:
- https://github.com/celery/celery/issues/5000
- https://github.com/celery/celery/issues/5286
- https://github.com/celery/celery/issues/5327
- https://github.com/celery/celery/issues/3723
Использование сельдерея для нашего конкретного случая стало трудным и ненадежным. Встроенная поддержка рабочих процессов в Celery не кажется правильным выбором для обработки 100/1000/10 000 задач. В нынешнем состоянии этого просто недостаточно. Итак, вот мы стоим перед прочной бетонной стеной… Либо мы как-то исправляем Celery, либо переписываем нашу автоматизацию, используя другую структуру.
Сельдерей — исправить… или исправить?
Переписать всю нашу автоматизацию можно, хотя и относительно болезненно. Поскольку я довольно ленив, возможно, попытка исправить Celery была не совсем плохой идеей? Так что я потратил некоторое время, чтобы покопаться в коде Celery, и мне удалось найти части, отвечающие за построение рабочих процессов и выполнение цепочек и аккордов. Мне все еще было немного сложно понять все различные пути кода, обрабатывающие широкий спектр вариантов использования, но я понял, что можно реализовать чистую, прямую оркестровку, которая будет обрабатывать все задачи и их комбинации в одном путь. Более того, я понял, что интегрировать его в нашу автоматизацию не потребует слишком больших усилий (давайте не будем забывать о главной цели!).
К сожалению, внедрение новой оркестровки в проект Celery, вероятно, будет довольно сложным и, скорее всего, нарушит некоторую обратную совместимость. Поэтому я решил использовать другой подход — написать расширение или плагин, которые не требовали бы изменений в Celery. Что-то подключаемое и максимально неинвазивное. Так появился Celery Dyrygent…
Сельдерей Dyrygent
github.com/ovh/celery-dyrygent
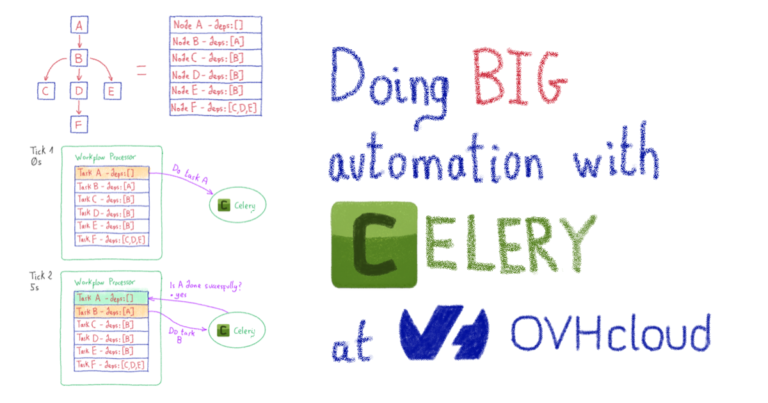
Как представить рабочий процесс
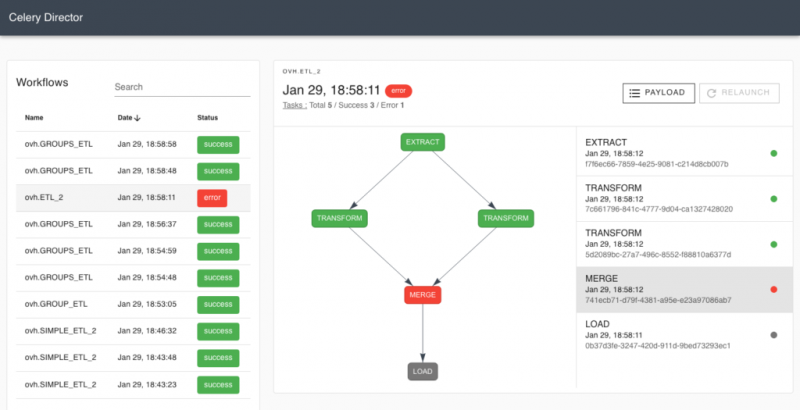
Вы можете представить себе рабочий процесс как направленный ациклический граф (DAG), где каждая задача является отдельным узлом графа. Когда дело доходит до ациклических графов, относительно легко хранить и разрешать зависимости между узлами, что приводит к простой оркестровке. Celery Dyrygent был реализован на основе этих функций. Каждая задача в рабочем процессе имеет уникальный идентификатор (Celery уже назначает идентификаторы задач, когда задача отправляется на выполнение), и каждая из них заключена в узел рабочего процесса. Каждый узел рабочего процесса состоит из сигнатуры задачи (простой сигнатуры сельдерея) и списка идентификаторов задач, от которых он зависит. См. Пример ниже:
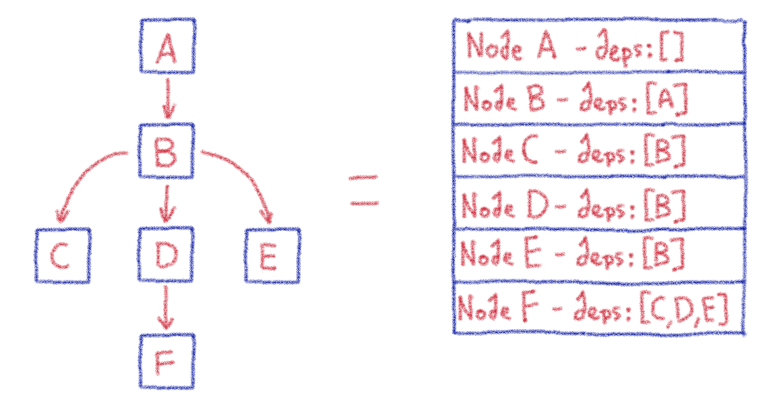
Как обработать рабочий процесс
Итак, мы знаем, как сохранить рабочий процесс простым и понятным способом. Теперь нам просто нужно его выполнить. Как насчет… сельдерея? Почему бы нет? Для этого Celery Dyrygent вводит задачу процессора рабочего процесса (обычная задача Celery ). Эта задача охватывает весь рабочий процесс и планирует выполнение примитивных задач в соответствии с их зависимостями. После того, как часть планирования завершена, задача повторяется («тикает» с некоторой задержкой).
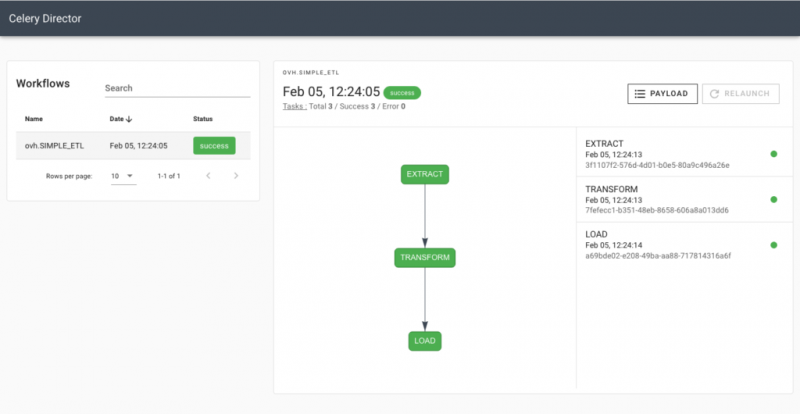
На протяжении всего цикла обработки процессор рабочих процессов сохраняет внутреннее состояние всего рабочего процесса. В результате он обновляет состояние при каждом повторении. Вы можете увидеть пример оркестровки ниже:
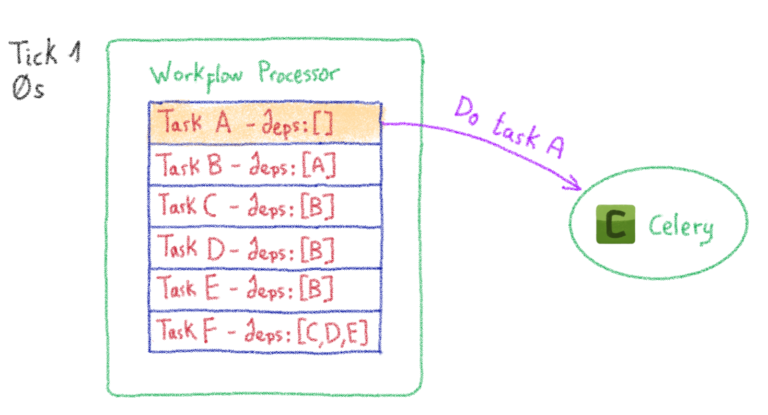
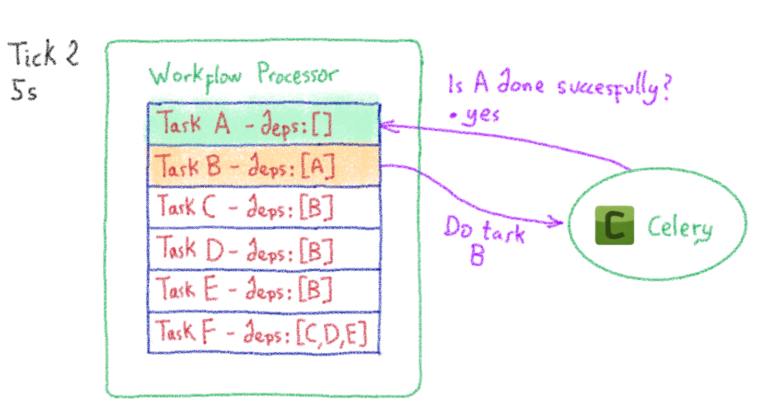
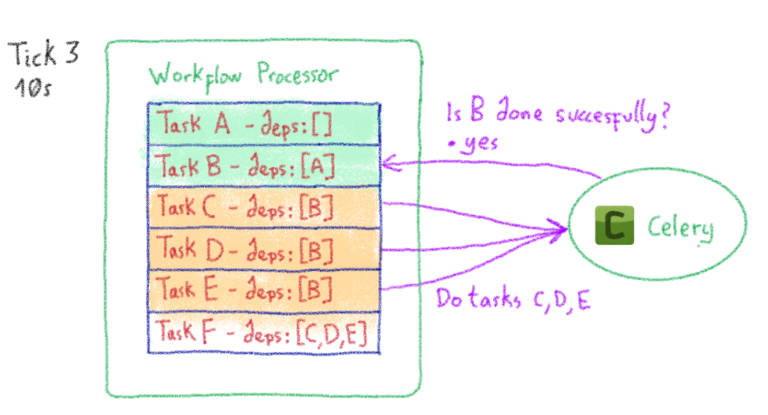
В частности, процессор рабочего процесса останавливает свое выполнение в двух случаях:
- После завершения всего рабочего процесса и успешного выполнения всех задач
- Когда он не может продолжить работу из-за сбоя задачи
Как интегрировать
Итак, как нам это использовать? К счастью, мне довольно легко удалось найти способ использовать Celery Dyrygent. Прежде всего, вам необходимо внедрить определение задачи процессора рабочего процесса в ваше приложение CeleryP:
from celery_dyrygent.tasks import register_workflow_processor
app = Celery() # your celery application instance
workflow_processor = register_workflow_processor(app)Затем вам нужно преобразовать рабочий процесс, определенный для Celery, в рабочий процесс Celery Dyrygent:
from celery_dyrygent.workflows import Workflow
celery_workflow = chain([
noop.s(0),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
noop.s()
])
workflow = Workflow()
workflow.add_celery_canvas(celery_workflow)Наконец, просто выполните рабочий процесс, как обычную задачу Celery:
workflow.apply_async()Это оно! Вы всегда можете вернуться, если хотите, так как небольшие изменения очень легко отменить.
Попробуйте!
Celery Dyrygent можно использовать бесплатно, а его исходный код доступен на Github ( github.com/ovh/celery-dyrygent ). Не стесняйтесь использовать его, улучшать, запрашивать функции и сообщать о любых ошибках! У него есть несколько дополнительных функций, не описанных здесь, поэтому я рекомендую вам взглянуть на файл readme проекта. Для наших требований к автоматизации это уже надежное, проверенное на практике решение. Мы используем его с конца 2018 года, и он обработал тысячи рабочих процессов, состоящих из сотен тысяч задач. Вот некоторая статистика производства за период с июня 2019 года по февраль 2020 года:
- Выполнено 936 248 элементарных задач
- Обработано 11 170 рабочих процессов
- 4098 задач в самом большом рабочем процессе
- ~ 84 задачи на рабочий процесс, в среднем
Автоматизация — это всегда хорошая идея!