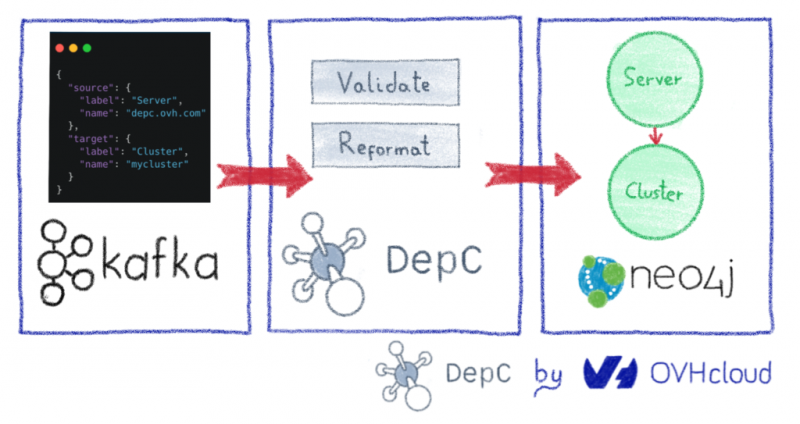
В 2018 году мы запустили один из крупнейших проектов в истории OVH: миграцию 3 миллионов веб-сайтов, размещенных в нашем центре обработки данных в Париже. Если вы хотите узнать причины этого титанического проекта, мы рассмотрели их в этом посте.
Пришло время объяснить, как мы продвигались в этом проекте. Мы уже говорили о наших эксплуатационных ограничениях, таких как обеспечение того, чтобы мы не влияли на веб-сайты, даже если мы не контролируем исходный код, и ограничение времени простоя. У нас также было много технических ограничений, связанных с архитектурой наших сервисов. Мы подробно рассмотрим наши различные сценарии миграции в следующей статье, а сегодня мы объясним, как работает инфраструктура, на которой размещены ваши веб-сайты.
Анатомия веб-хостинга
Для работы веб-сайтам и веб-приложениям обычно нужны две вещи :
- Исходный код, отвечающий за выполнение поведения веб-сайта
- T он данные , используемые в исходном коде , чтобы настроить опыт
Чтобы сайт работал , исходный код запускается на одном или нескольких серверах, среда которых настроена с помощью инструментов, связанных с используемыми языками программирования. В настоящее время PHP доминирует на рынке, но выбор не ограничивается этим языком.
Чтобы эти серверы оставались в рабочем состоянии, их необходимо обслуживать и обновлять, а их работу необходимо постоянно контролировать. Эта роль обычно отличается от роли разработчиков, которые несут ответственность за создание исходного кода веб-сайта. Если вас интересуют эти роли, мы рекомендуем узнать больше о системных администраторах и DevOps, а также об их конкретных навыках.
Для владельца веб-сайта мониторинг инфраструктуры и ее операций может быть очень дорогостоящим: вам нужна достаточно большая команда, чтобы поддерживать присутствие 24 часа в сутки, 365 дней в году. С такой командой разработчики могут полагаться только на разовые запросы на обслуживание, когда владелец веб-сайта хочет внести изменения.
Именно этот уровень управления мы предлагаем через наше решение для веб-хостинга. Вместо того, чтобы набирать команду системных администраторов для каждого веб-сайта, мы наняли команду технических экспертов, которые заботятся обо всех веб-сайтах, которые мы размещаем. То же самое и с данными, которые хранятся на определенных серверах и управляются теми же группами экспертов.
Таким образом, каждому веб-сайту не нужно использовать ресурсы всего сервера. С помощью наших решений мы объединяем ресурсы в нашей инфраструктуре, поэтому отдельные серверы могут использоваться для одновременного запуска нескольких веб-сайтов.
Все эти эффекты масштаба позволяют нам предлагать недорогие решения для веб-хостинга (от 1,49 евро в месяц), сохраняя при этом высокий уровень качества. Мы очень коротко объясним, как мы рассчитываем качество обслуживания, но если вы не хотите ждать, посмотрите конференцию, которую наши разработчики провели на FOSDEM 2019.
Чтобы достичь необходимого уровня качества при управлении таким количеством веб-сайтов, мы адаптировали нашу инфраструктуру.
Техническая архитектура наших решений для веб-хостинга
Классический подход к созданию службы веб-хостинга заключается в установке сервера, настройке баз данных и среды выполнения исходного кода, а затем размещении там новых клиентов до тех пор, пока сервер не заполнится, прежде чем переходить к следующему серверу.
Это очень эффективно, но у этого типа архитектуры есть некоторые недостатки :
- В случае поломки восстановление может быть долгим. Если у вас нет репликации системы в реальном времени, что очень дорого, вам нужно восстановить данные из резервной копии, а затем перенести их на новую машину, прежде чем повторно открывать службу для клиентов. Хотя вероятность аппаратного или программного сбоя невелика, это обычная операция в крупных инфраструктурах.
- Чтобы иметь дело с новыми технологиями, было бы предпочтительнее внедрять их на новых серверах только на первом этапе, а затем уделять время постепенному развертыванию их на существующих серверах на будущих этапах.
Однако на таком быстро развивающемся рынке, как Интернет, становится трудно поддерживать разнородную инфраструктуру. Затем технические группы должны адаптироваться и работать с несколькими различными конфигурациями, что увеличивает риск регресса или поломки. А командам поддержки становится очень сложно запоминать все различные конфигурации и отслеживать текущие изменения. - Каждый программный блок по своей сути сложен, поэтому для достижения максимальной производительности и качества обслуживания мы создали группы, специализирующиеся на каждой технологии: база данных, среда PHP, системы хранения, сеть… Может быть сложно заставить все эти группы взаимодействовать на одном сервере., и приводят к недопониманию относительно доступности веб-сайтов.
- Трудно выделить клиента, который потребляет больше ресурсов, чем в среднем. Если вам повезет, вы не будете на том же сервере, что и этот клиент, но если да, то производительность вашего веб-сайта может пострадать в результате потребления ресурсов.
Как вы можете видеть, в нашем масштабе, мы решили взять другой подход, в виде хорошо известного шаблона для приложений , которые должны иметь дело с нагрузкой : н- уровневой архитектуры .
N- уровневая архитектура
Участки с высоким уровнем нагрузки могут использовать п — уровень архитектуру, чтобы предоставить больше ресурсов для каждого программного кирпича, распределяя их между несколькими серверами. Если мы пойдем дальше с нашим разделением кода / данных, нам понадобится три сервера для запуска веб-сайта:
- Сервер, ответственный за выполнение исходного кода
- Два часто используемых сервера хранения : сервер базы данных и файловый сервер
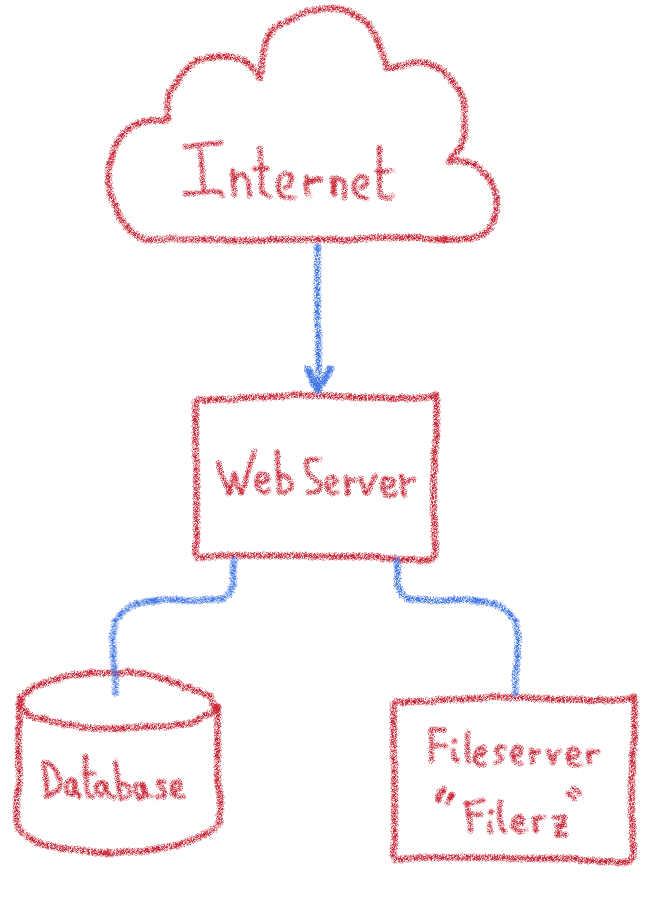
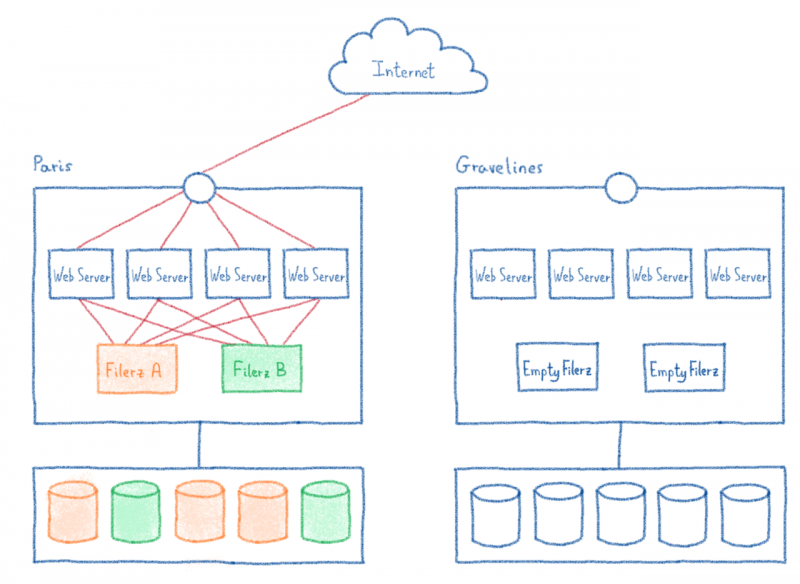
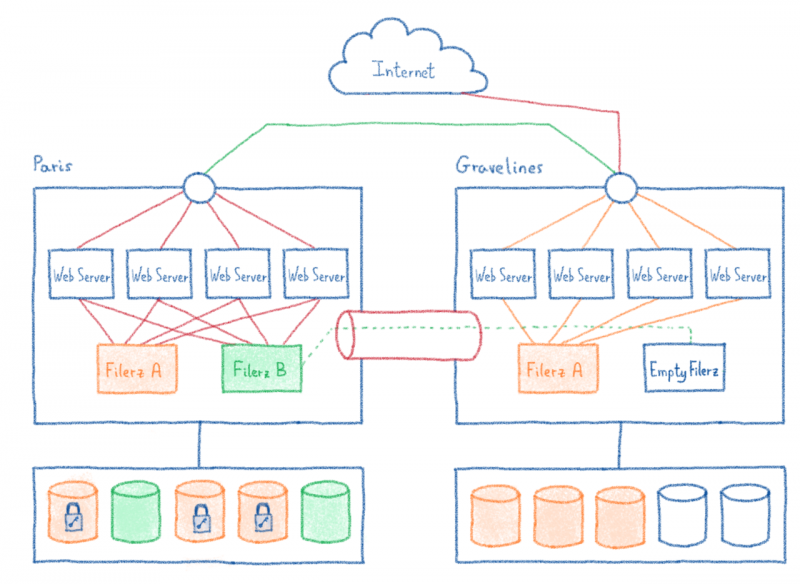
Файловые серверы: Filerz
Это серверы, на которых мы храним файлы, составляющие веб-сайт (обычно исходный код веб-сайта). Они оснащены специальным оборудованием, обеспечивающим быстрый доступ к данным и надежность. Мы также используем специальную файловую систему ZFS, которая позволяет нам легко управлять локальным и удаленным резервным копированием.
Ими управляет специальная группа хранения, которая также предоставляет услуги этого типа нескольким другим командам в OVH (веб-хостинг, электронная почта…). Если вас это интересует, они также предлагают NAS-HA, который вы найдете в общедоступном каталоге наших выделенных серверов.
В случае сбоя мы сохраняем запас запчастей и серверов наготове, чтобы восстановить обслуживание как можно быстрее.
Серверы баз данных
Серверы баз данных обычно используются веб-сайтами для динамического размещения данных сайта. Они используют систему управления базами данных (СУБД) (MySQL с нашими решениями), которая структурирует данные и делает их доступными через язык запросов (в нашем случае SQL).
Эти серверы также требуют специального оборудования для хранения данных, особенно большого объема оперативной памяти, чтобы использовать преимущества систем кэширования СУБД и быстрее отвечать на поисковые запросы.
Этими машинами управляет специальная команда базы данных, которая отвечает за эту инфраструктуру. Команда базы данных предлагает эти услуги общественности через предложение CloudDB, а также обрабатывает частный SQL.
В Париже эти серверы размещены в частном облаке (SDDC), что позволяет переключать виртуальные машины на лету с одной физической машины на другую в случае возникновения проблем. Это помогает сократить время простоя во время обслуживания и время восстановления в случае отказа.
Веб-серверы
Это серверы, которые получают запросы и выполняют исходный код веб-сайта. Они получают свои данные из файлов и баз данных, предоставленных ранее описанными Filerz и серверами баз данных. Основное требование к этим серверам — хорошие ресурсы ЦП, необходимые для выполнения исходного кода.
Поскольку эти веб-серверы не имеют состояния (т.е. они не хранят никаких данных локально), можно добавить их больше и распределить нагрузку по нескольким машинам. Это позволяет нам распределять веб-сайты по разным серверам и избегать искажений при использовании в инфраструктуре, поскольку использование динамически распределяется по всем серверам фермы.
Если один из серверов выходит из строя, другие серверы в ферме доступны для поддержания трафика. Это позволяет нам использовать широкий спектр серверов, имеющихся в нашем инвентаре, при условии, что они имеют хорошие возможности ЦП.
Балансировка нагрузки
Запросы не приходят на предполагаемый веб-сервер по волшебству. Для этого вам нужна точка входа, которая отправляет запросы на правильный сервер. Эта технология называется «балансировкой нагрузки».
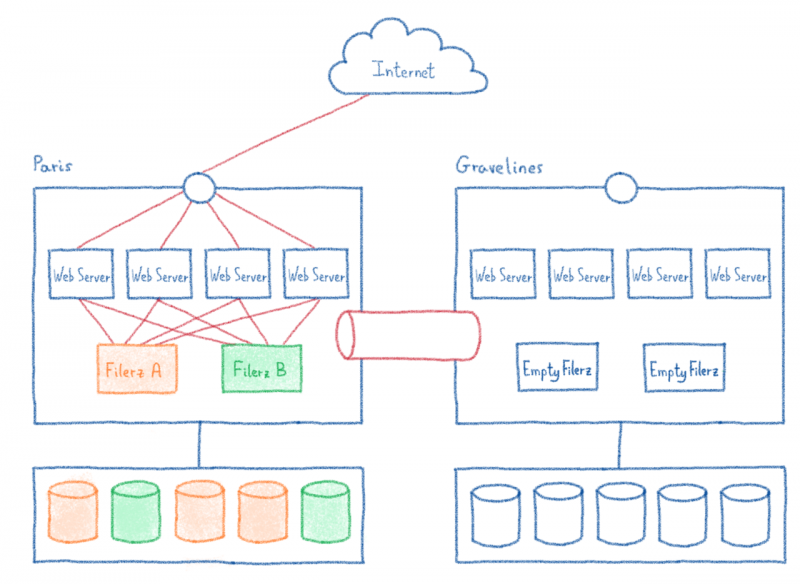
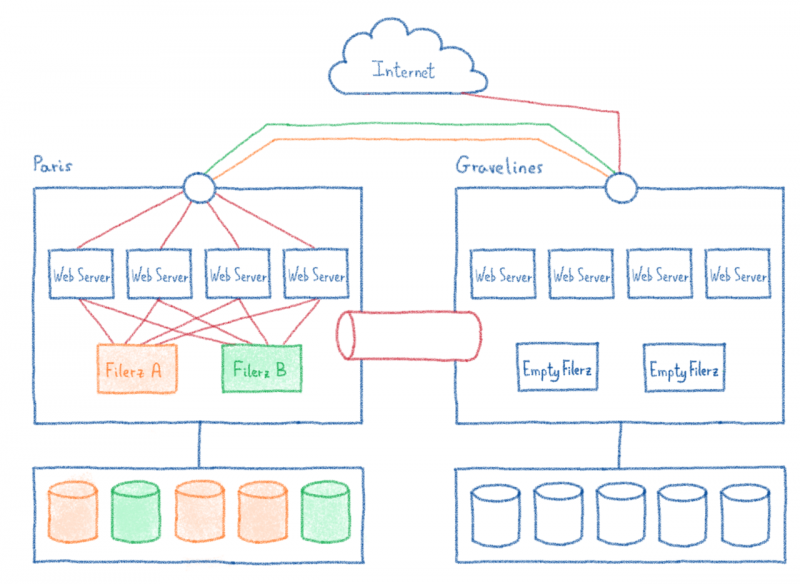
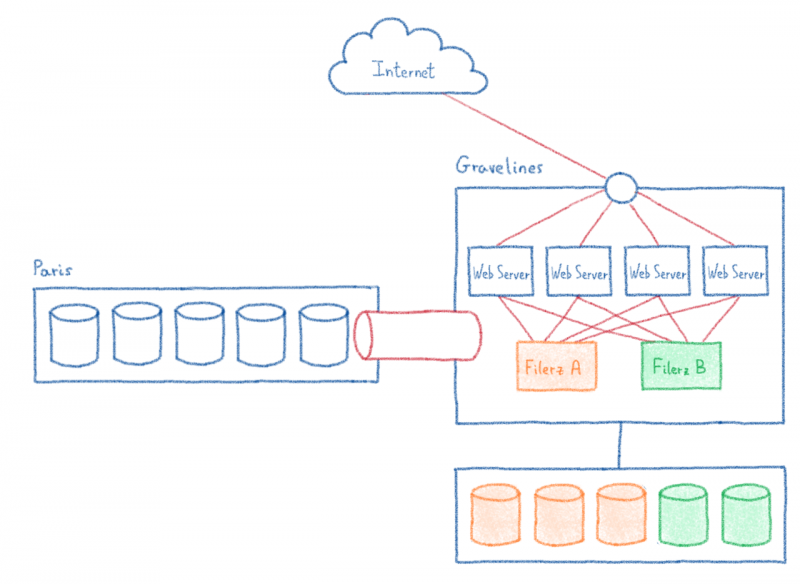
В нашем центре обработки данных в Париже есть серверы, оборудование которых полностью предназначено для балансировки нагрузки. Однако в нашей новой инфраструктуре Gravelines мы используем публичный кирпич: IPLB.
Трафик веб-сайта поступает на несколько IP-адресов (
docs.ovh.com/en/hosting/list-addresses-ip-clusters-and-web-hostings/#cluster-025 ), которые мы выделяем для нашей службы веб-хостинга.. Эти IP-адреса управляются нашими балансировщиками нагрузки. Следовательно, они являются отправной точкой нашей инфраструктуры. Кроме того, мы реализовали самые лучшие анти DDoS технологии, чтобы защитить веб — сайтов наших клиентов.
Эти нагрузки балансиры работают отлично для больших объемов трафика веб — сайта, распространение на нескольких веб — серверов, так как запросы распределяются справедливо, с помощью алгоритмов балансировки нагрузки. Но наши требования другие. Мы хотим иметь несколько различных сайтов на в одном сервере, и изменить распределение на основе нескольких критериев: хостинг пакет клиента (как более премиальные предложения включают меньше веб — сайтов на одном сервере), и ресурсы, необходимые для непрерывного распределения нагрузки.
Мы также предлагаем решения с гарантированными ресурсами, такие как Performance Hosting, или даже полностью выделенные, например Cloud Web.
Фактически, распределение нагрузки очень сильно привязано к нашим клиентам. Мы изменили систему распространения, добавив блок, предназначенный для OVH, с именем predictor, который выбирает веб-сервер в соответствии с веб-сайтом запроса. В предикторы адаптации к метрикам нашей инфраструктуры, и информация, предоставленная нашей системой.
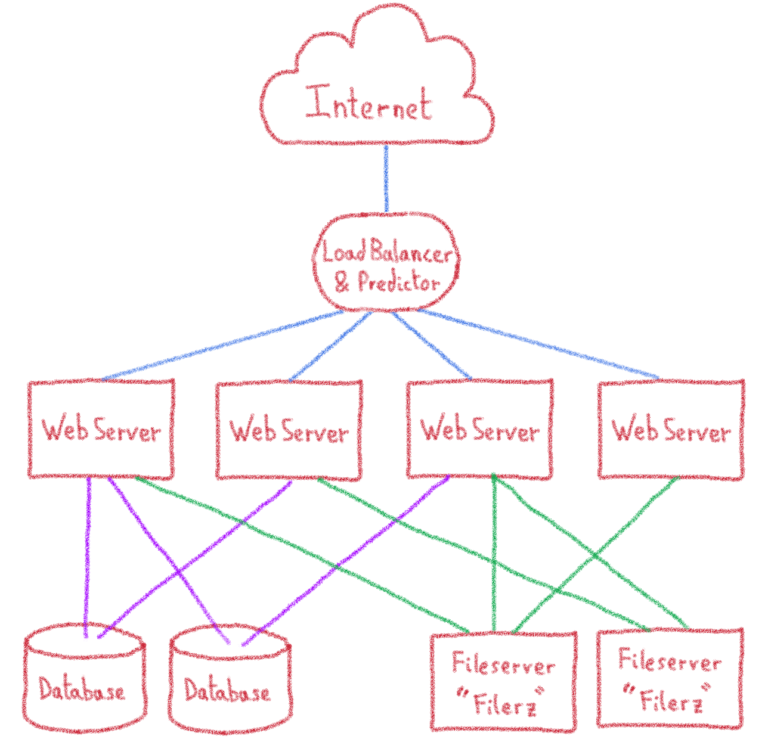
Все это делает нашу инфраструктуру немного сложнее, чем обычно, хотя ж е не будет идти гораздо дальше в детали того, чтобы держать вещи простым и в рамках этого блога. Это должно было дать достаточно обзора, чтобы объяснить возможные сценарии миграции.
Благодаря добавлению балансировки нагрузки, а также нескольких серверов баз данных и файлового хранилища эта архитектура позволяет нам размещать невероятно большое количество различных веб-сайтов. Но, как знают все администраторы инфраструктуры, «дерьмо случается!». Рано или поздно случится сбой. Поэтому необходимо знать, как реагировать в таких случаях, чтобы минимизировать воздействие.
Домены сбоя
Один из методов уменьшения воздействия сбоев — ограничение их периметра путем создания доменов сбоя. За пределами мира информатики мы видим аналогичные концепции в управлении лесным хозяйством с использованием пустых участков в качестве противопожарных пробок или в строительной индустрии с дверями с тем же названием.
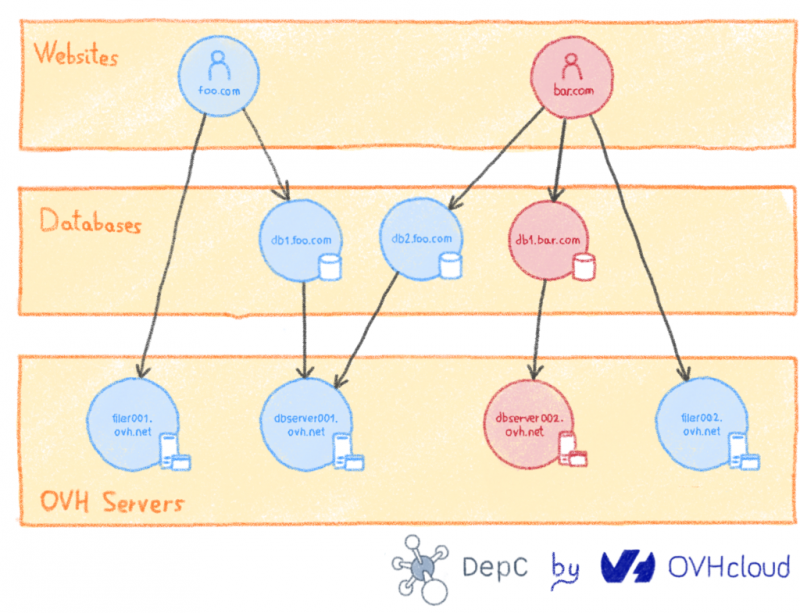
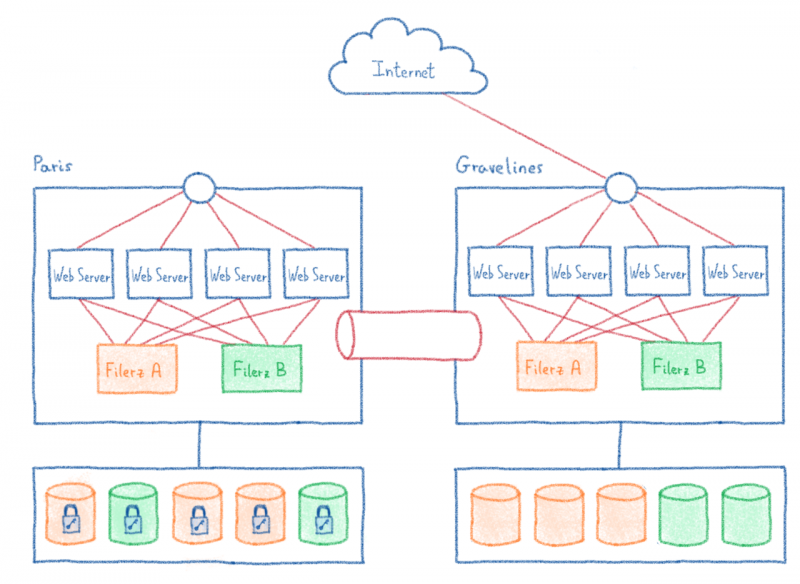
В нашем бизнесе речь идет о разделении инфраструктуры на части и распределении клиентов по разным кластерам. Поэтому мы разделили инфраструктуру Парижа на 12 идентичных кластеров. В каждом кластере мы находим балансировщик нагрузки, веб-серверы и Filerz. Я е один из кластеров идет вниз, « только « 1/12 из клиентов с сайтов, размещенных на этом центре обработки данных затронуты.
Серверы баз данных рассматриваются отдельно. Хотя мы не выделяем это как функцию, мы разрешаем нашим клиентам совместно использовать свои базы данных между своими хостинговыми решениями, когда им необходимо обмениваться данными. Поскольку клиент не может выбрать кластер своих веб-сайтов, мы отделили базы данных от кластеров, чтобы сделать их доступными для всего центра обработки данных.
Итак, в последний раз нам нужно обновить схему нашей инфраструктуры…
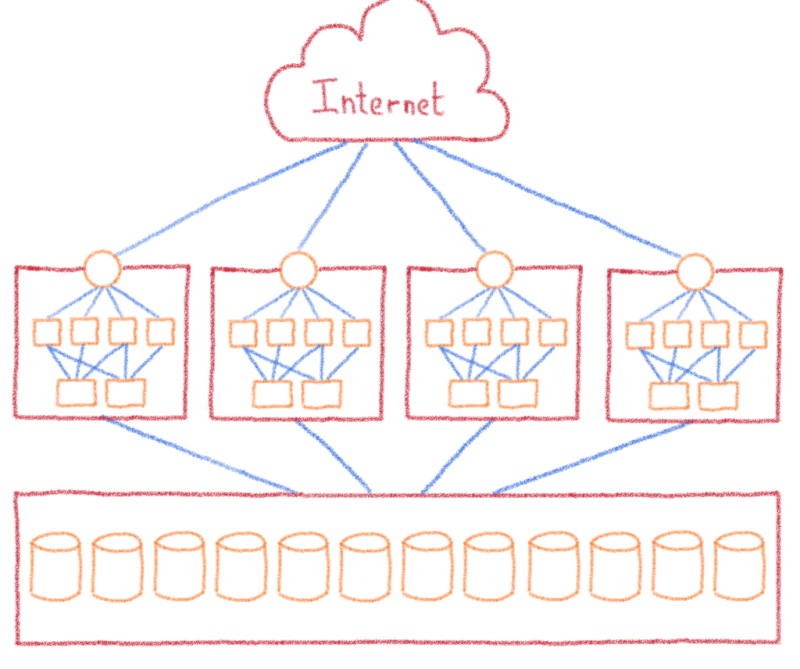
Управление инфраструктурой
Вся эта инфраструктура находится в ведении нашей информационной системы, с использованием конфигурации в режиме реального времени, которая формирует на связь между панелью управления OVH, в OVH API, и самой инфраструктурой.
Информационная система включает исчерпывающее представление инфраструктуры, что позволяет адаптировать доставку новых учетных записей, управлять изменениями в наших предложениях и выполнять технические действия с учетными записями.
Например, когда вы создаете новую базу данных в своем пакете хостинга, информационная система позаботится о выборе сервера, на котором она будет расположена, чтобы убедиться, что она создана в той же инфраструктуре, прежде чем уведомить вас о ее доступности по электронной почте или API.
Поздравляем… теперь вы знаете немного больше о нашей архитектуре! Чтобы узнать, где работает ваш собственный веб-сайт, вы можете найти имена серверов баз данных, Filerz и кластеров, связанных с вашим хостингом, в панели управления OVH.
Технические ограничения для миграции
Эта архитектура накладывает некоторые технические ограничения, если веб-сайты, размещенные на ней, будут продолжать работать по назначению:
- Все веб-сайты в одном кластере имеют один и тот же IP-адрес.
- Серверы баз данных и кластеры хостинга не коррелируют
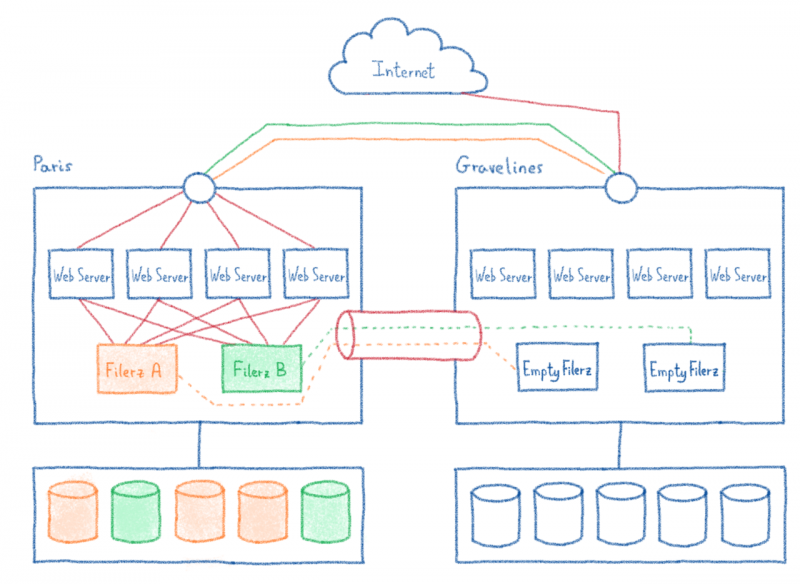
- Чтобы перенести веб-сайт, вы должны синхронизировать его миграцию с миграцией всех связанных с ним элементов, то есть балансировщика нагрузки , Filerz и баз данных.
- Исходный код веб-сайта может использовать базу данных, на которую нет ссылок на его веб-хостинге.
- Исходный код может включать ссылки на инфраструктуру (абсолютная ссылка, включая номер файла , имя кластера, имя серверов баз данных ...)
Теперь вы знаете все операционные и технические ограничения, связанные с проектом миграции центра обработки данных. В следующей статье мы обсудим различные сценарии миграции, которые мы рассмотрели, и тот, который мы в итоге выбрали.