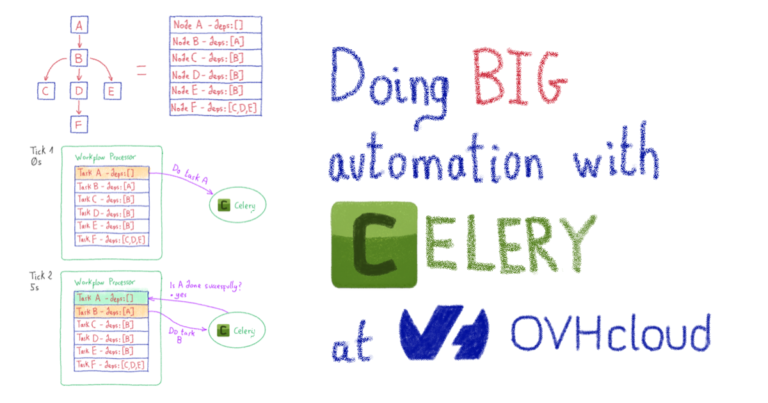
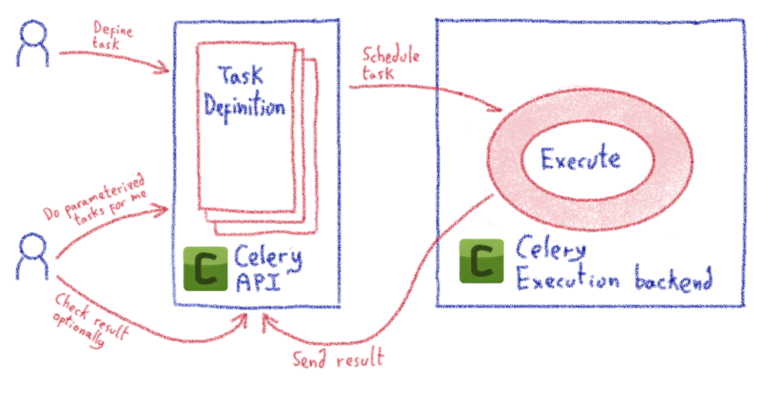
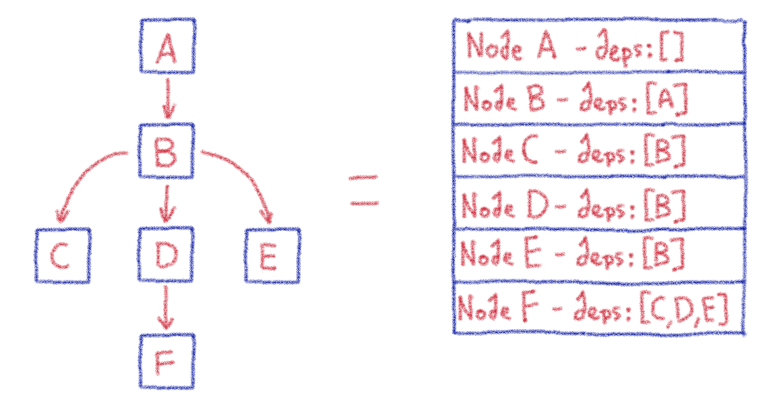
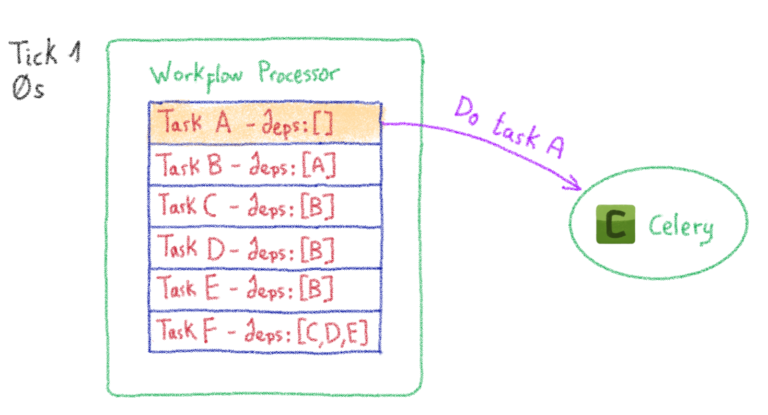
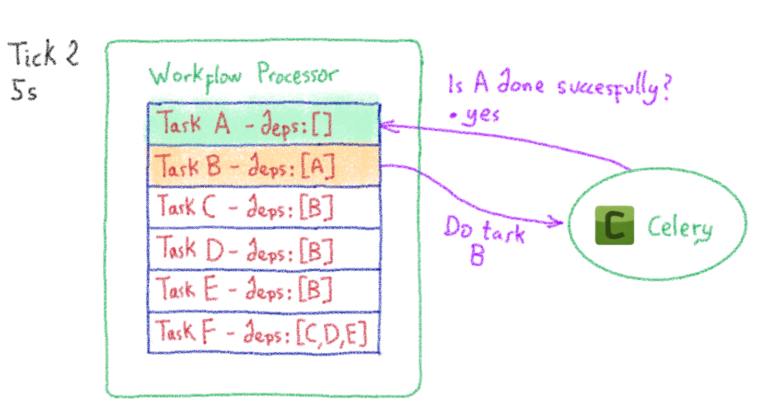
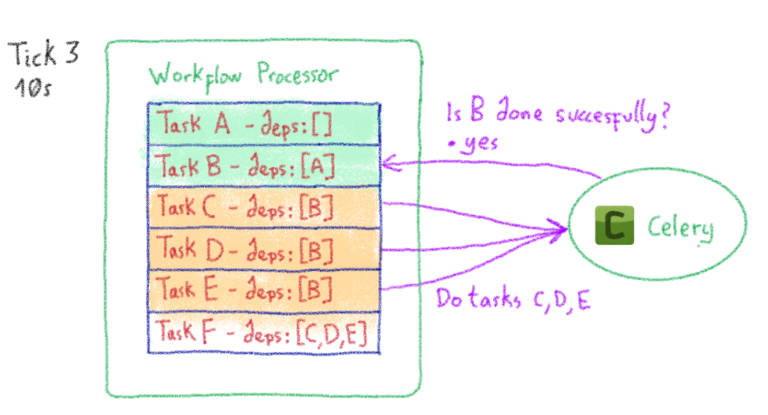
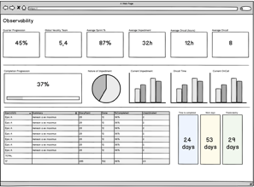
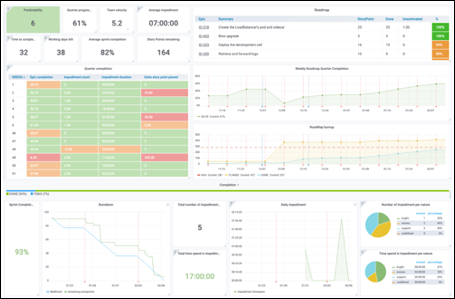
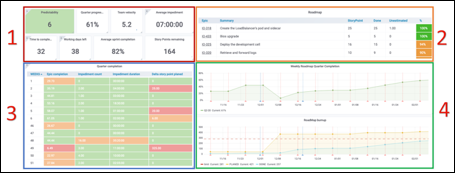
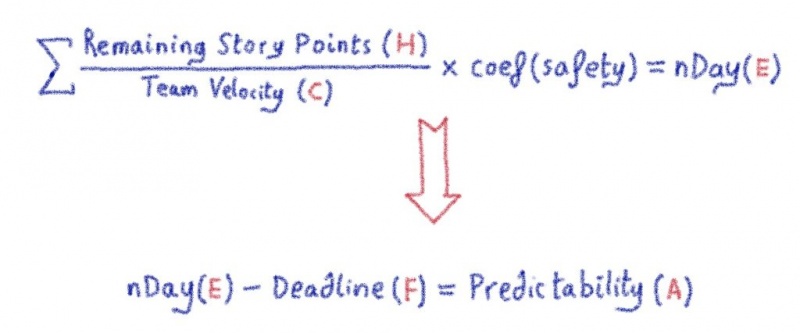
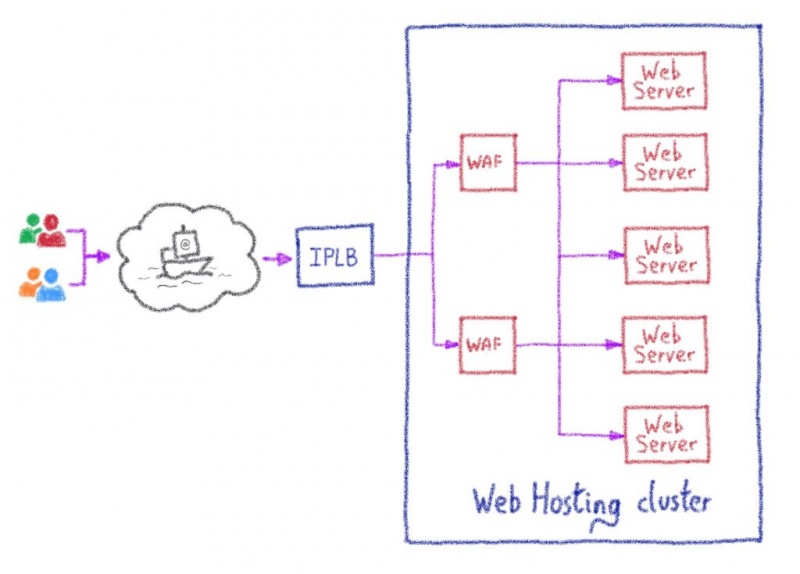
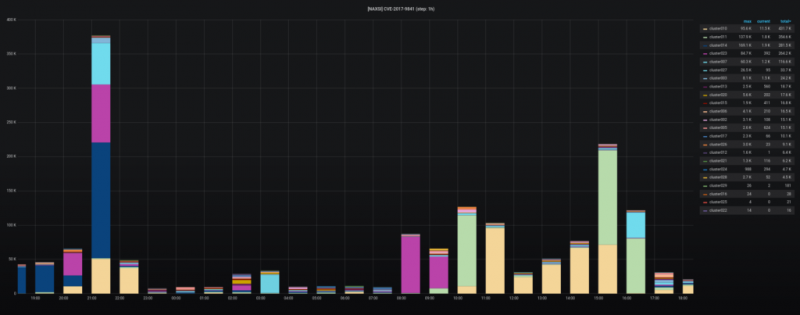
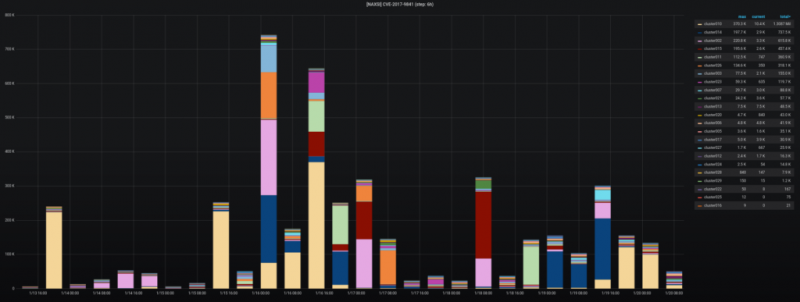
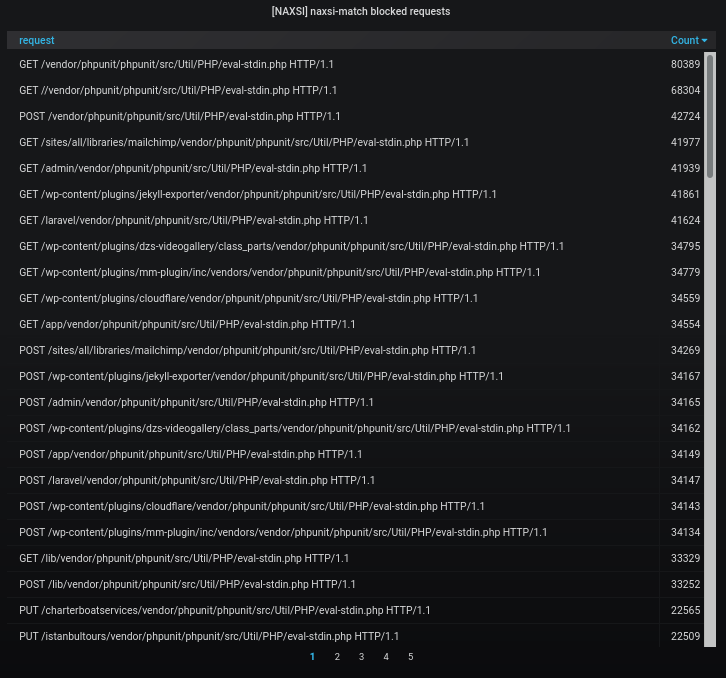
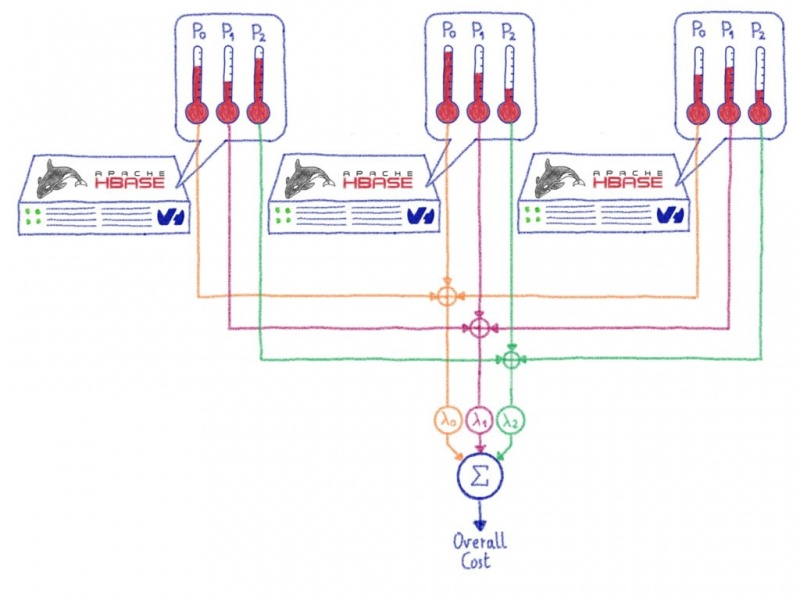
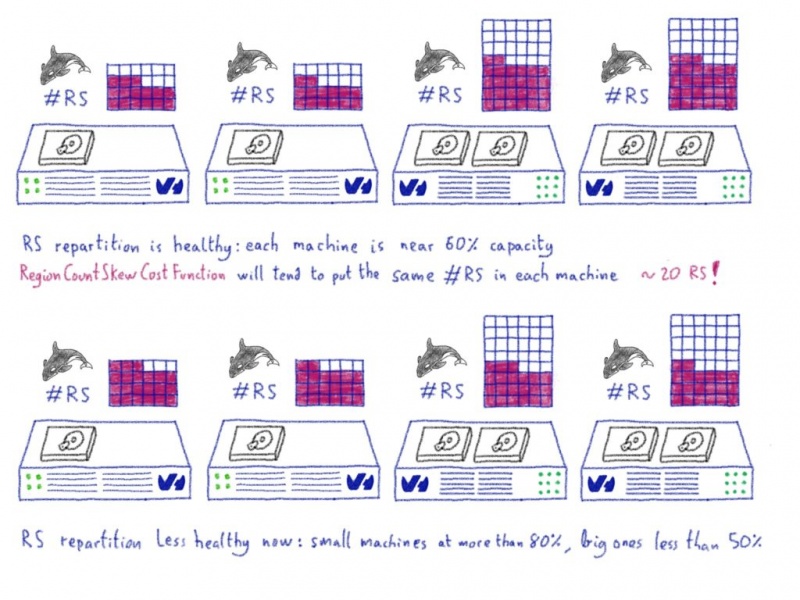
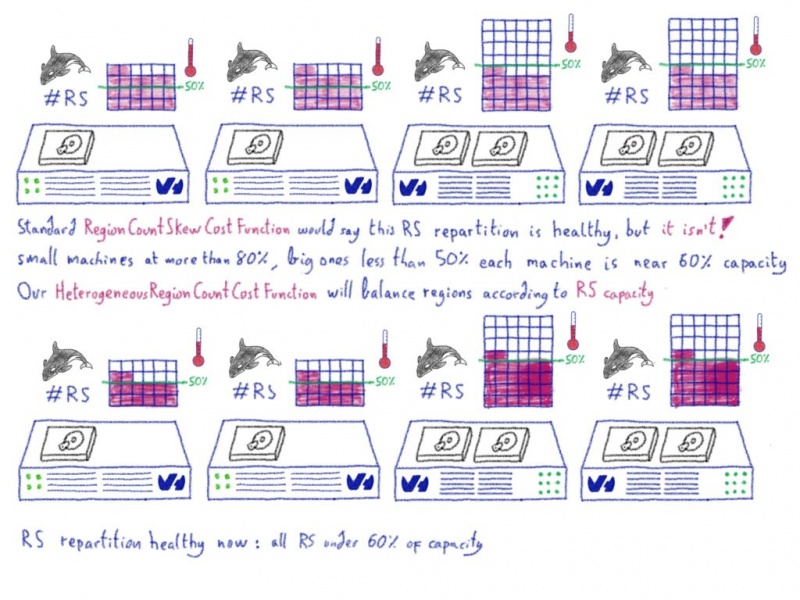
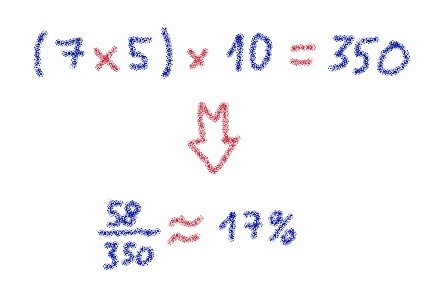Машинное обучение: от идеи к реальности
Поскольку в настоящее время вы читаете сообщение в блоге технологической компании, держу пари, что вы уже слышали об искусственном интеллекте и машинном обучении десятки раз в этом месяце.

И это прекрасно понятно! Здоровье, реклама, азартные игры, страхование, банковское дело, электронная коммерция… что угодно. За шумихой скрывается реальность, и мы можем с уверенностью сказать, что теперь любой сектор может эффективно использовать машинное обучение.
Но как это работает? Это сложно на начальном этапе? Какие ресурсы для этого требуются?
Как и многие компании, вы, возможно, уже планируете использовать машинное обучение в 2020 году и задаетесь вопросом, с какими проблемами вы столкнетесь, когда начнете работу. Что ж, давайте узнаем вместе!

Искусственный интеллект — и его подкатегория, машинное обучение — это быстрорастущие науки, в которых мы только начинаем работать.
Многое еще предстоит открыть, поэтому знания и инструменты развиваются быстрыми темпами, что может привести к противоречивым аргументам.
«Нет-нет для статистики…»
«Это не для нас… Мы небольшая компания…»
Я слышал такие реплики довольно часто. Блин, а они были правы? Что на самом деле происходит за кулисами?
Давайте проведем параллель с повседневной ситуацией… Все люди учатся естественно. Мы рождены с когнитивными функциями, которые помогают нам в этом каждый день. Выслушав своих родителей, 2–3-летний ребенок сможет определить положительное или отрицательное предложение. Он основан на нескольких параметрах, включая интонацию голоса, внешний вид, сами слова, контекст… То же самое происходит чуть позже со словами. После прочтения предложений в книге ребенок в возрасте от 5 до 6 лет должен уметь распознавать позитив и негатив.
Представьте, что вы хотите имитировать этот анализ настроений с помощью компьютера. Хороший способ начать — взять большой набор слов с соответствующими показателями положительности / отрицательности (мы можем назвать это «набором данных»).
Затем вы можете начать обнаруживать некоторые закономерности. Например, слово «круто» часто встречается, когда предложение помечено как положительное.
А что, если вместо слов вы захотите обнаружить закономерность в полных предложениях с учетом эмодзи, языка и т. Д. И выполнить это на очень больших наборах данных? Вы можете добиться этого без машинного обучения, но это может быть сложно.
Для достижения этой цели машинное обучение будет использовать мощность множества компьютеров и определенного программного обеспечения в соответствии с этим классическим рабочим процессом:
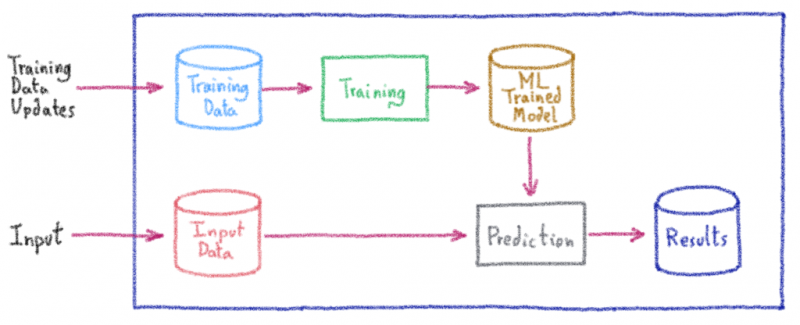
Первый шаг — получить чистые и полезные данные, называемые здесь «обучающими данными». В нашем предыдущем примере он состоит из классифицированных слов / предложений с оценкой тональности. Это одна из самых сложных частей процесса (получение актуальных и важных данных).
Если у вас есть данные, вы можете использовать специальную программную платформу для машинного обучения, такую как библиотеки Python, Pandas или Scikit-Learn, или студию искусственного интеллекта с визуальными интерфейсами, чтобы «учиться». Этот шаг потребует много энергии (вычислений), так как он будет пробовать различные статистические подходы, чтобы найти лучшие шаблоны.
Как только вы найдете наиболее подходящий шаблон, он сгенерирует то, что мы называем «моделью машинного обучения».
Как только вы его получите, эта модель сможет делать прогнозы. Если вы поместите новые данные в эту модель («вход» в схеме), будет сделан прогноз, дающий вам некоторые результаты. Впоследствии, чтобы оставаться в курсе, вам, возможно, придется периодически переобучать модель, используя более точные данные, новые алгоритмы и т. Д.
Этот вид процесса был ракетостроением несколько лет назад, но сегодня, поскольку требуемая мощность гораздо более доступна, благодаря поставщикам облачных услуг и достижениям в инструментах обработки данных, его можно реализовать с очень низкими затратами.
«Но… поскольку язык моей страны одинаков для всех компаний, может быть, я найду заранее созданную модель машинного обучения, которую смогу использовать для анализа настроений?»
Это дух! Для базовых проектов, в которых не требуется настройка, вы можете найти множество готовых решений. Навыки науки о данных не требуются, поскольку эти модели создаются сторонними организациями. Если у вас есть возможность использовать API, вы сможете их использовать. А если вы хотите попробовать несколько забавных моделей бесплатно, вы можете изучить рынок искусственного интеллекта OVH Labs ( market-place.ai.ovh.net/).
Подводя итог: независимо от размера вашей компании, машинное обучение может удовлетворить ваши потребности и принести реальную пользу. Он основан на инструментах статистики, но имеет несколько иные концепции и те же цели. Сегодня, благодаря участникам с открытым исходным кодом, вы можете найти множество готовых программных инструментов для машинного обучения, но когда вам нужна большая точность, это потребует некоторых навыков в области науки о данных.
Даже не зная об этом, вы каждый день получаете пользу от машинного обучения в больших масштабах. У вас есть учетная запись электронной почты с функцией фильтрации спама? Машинное обучение. Вы смотрели Netflix и получили хорошие рекомендации? Машинное обучение. Вы использовали Waze, чтобы избежать пробок сегодня утром? Машинное обучение.
Если крупные компании используют его ежедневно, рост малых и средних компаний впечатляет.
Прежде всего, существует огромная разница между использованием программного обеспечения, которое уже оборудовано для машинного обучения, и разработкой собственного проекта машинного обучения.
Вот несколько простых реальных примеров, которые можно было бы развернуть за несколько шагов с помощью готовых решений (наука о данных не требуется!):
Использовать его так же просто, как этот пример кода для обнаружения объектов на изображениях (Python, Go, Java… даже PHP может его использовать):
curl -X POST «api-market-pl
Результаты будут представлены с оценкой вероятности:

Более сложные варианты использования, такие как прогнозирование ваших запасов или доходов, обнаружение мошенничества и борьба с ним, или прогнозирование отключений и планового обслуживания, потребуют дополнительных знаний.
Каждой компании предстоит изучить несколько факторов. Вы можете попробовать готовые сервисы, но их точность не обязательно оправдает ваши ожидания.
Если это звучит знакомо, вас очень заинтересует следующая глава…
Извилистый путь к точным результатам
Как только вы перепрыгнете через мысленную пропасть сложности машинного обучения, вам придется встретиться и победить других монстров.
Здесь, вместо того чтобы использовать готовые решения, мы будем делать это сами…
Создание модели машинного обучения: теория

И… реальность для специалиста по данным
Мы встречаемся с компаниями и клиентами из разных областей, и каждый раз, когда мы обсуждаем с ними машинное обучение, никаких сюрпризов. Это всегда одни и те же болевые точки, которые можно резюмировать следующим образом:
Шаг 1. Выбор идей / проектов и внутреннее сопровождение. Сначала это может показаться довольно простым, но все же критически важным. Специалисты по обработке данных не обладают знаниями в области маркетинга, здравоохранения или финансов, поэтому варианты использования должны исходить от конечных пользователей, а не от вашего ИТ-отдела.
Кроме того, этим запросчикам необходимо правильно определить свои потребности, а затем точно следовать проектам. Всегда просите их объяснить, чего они хотят достичь, когда у них будут ваши прогнозы.
Для крупных компаний необходим руководитель проекта на стороне конечного пользователя.
Шаг №2 . Проблемы с данными . Это часто решается путем правильного определения того, что мы ищем (например, шаг №1), а затем экспорта данных и их проверки вручную, где это возможно. Вы можете, например, проверить свои продажи и запасы, чтобы убедиться, что вы не пропустили данные. Если вам нужно продолжить очистку данных и измерение объема, это можно сделать вручную (со временем) или с помощью специальных инструментов, таких как OVHcloud AutoML, студии науки о данных, такие как Dataiku (которая доступна в бесплатной версии) или Apache Spark для обработки данных.
Но не только инструменты, но и понимание ваших данных является здесь основой.
Шаг №3 и №4 . Недостаток знаний в области науки о данных и точности моделей . Эти проблемы изначально могут быть решены путем сотрудничества с вашими партнерами. Например, в этой области сейчас специализируются многие консалтинговые фирмы, и это касается не только крупных компаний. И не забывайте, что вы также можете использовать готовые решения для начальных тестов, такие как те, которые доступны через OVHcloud AI Marketplace, поскольку это не потребует каких-либо навыков в области анализа данных.
Еще один вариант для изучения — это обучение некоторых из ваших сотрудников. Как мы уже упоминали ранее, программные инструменты и библиотеки теперь доступны широким массам, и, поскольку машинное обучение сегодня весьма интересно, вы можете легко найти добровольцев. Доступны онлайн-курсы обучения, такие как datacamp.com, openclassrooms.com, или обучающие видео от Udemy, Coursera или Pluralsight. Просто имейте в виду, что для этого потребуются статистика, алгебра и навыки общения, а не только программирование.
Шаг №5 . Теперь с OVHcloud перейти от прототипа к производству можно всего за две минуты! Мы только что выпустили новый инструмент под названием OVHcloud Serving Engine , который позволяет развертывать модели в нашем общедоступном облаке и доступен бесплатно на этапе раннего доступа.
Мы также развернули предварительно обученные модели для анализа настроений на французском и английском языках. Не стесняйтесь опробовать их в нашей панели управления публичным облаком!
Шаг №6. Бюджет. Честно говоря, вы можете начать заниматься машинным обучением на собственном ноутбуке. После этого вы можете использовать облачные ресурсы для обучения, но получение некоторых начальных результатов не будет вам дорого стоить. После того, как вы доказали, что результаты достижимы при небольшом бюджете, увеличение бюджета следует рассматривать как вложение, а не как затраты. Вы всегда можете делать это постепенно, поскольку облако изначально работает именно так — вы платите только за то, что потребляете.
Я надеюсь, что после прочтения этого сообщения в блоге вы будете более уверены в изучении машинного обучения в этом году! OVHcloud впервые начал изучать эти темы пять лет назад и с тех пор приобрел много знаний в этой области. Сегодня мы лучше можем создавать инструменты и услуги нашей мечты, а затем предоставлять их вам. После выпуска нашей AI Studio и AI Marketplace мы будем сопровождать вас от НИОКР до производства с помощью механизма обслуживания OVHcloud.
Я рекомендую вам прочитать об этом в нашем следующем блоге! Будьте на связи…
И это прекрасно понятно! Здоровье, реклама, азартные игры, страхование, банковское дело, электронная коммерция… что угодно. За шумихой скрывается реальность, и мы можем с уверенностью сказать, что теперь любой сектор может эффективно использовать машинное обучение.
Но как это работает? Это сложно на начальном этапе? Какие ресурсы для этого требуются?
Как и многие компании, вы, возможно, уже планируете использовать машинное обучение в 2020 году и задаетесь вопросом, с какими проблемами вы столкнетесь, когда начнете работу. Что ж, давайте узнаем вместе!
Но… что скрывается за машинным обучением?
Искусственный интеллект — и его подкатегория, машинное обучение — это быстрорастущие науки, в которых мы только начинаем работать.
Многое еще предстоит открыть, поэтому знания и инструменты развиваются быстрыми темпами, что может привести к противоречивым аргументам.
«Нет-нет для статистики…»
«Это не для нас… Мы небольшая компания…»
Я слышал такие реплики довольно часто. Блин, а они были правы? Что на самом деле происходит за кулисами?
Давайте проведем параллель с повседневной ситуацией… Все люди учатся естественно. Мы рождены с когнитивными функциями, которые помогают нам в этом каждый день. Выслушав своих родителей, 2–3-летний ребенок сможет определить положительное или отрицательное предложение. Он основан на нескольких параметрах, включая интонацию голоса, внешний вид, сами слова, контекст… То же самое происходит чуть позже со словами. После прочтения предложений в книге ребенок в возрасте от 5 до 6 лет должен уметь распознавать позитив и негатив.
Представьте, что вы хотите имитировать этот анализ настроений с помощью компьютера. Хороший способ начать — взять большой набор слов с соответствующими показателями положительности / отрицательности (мы можем назвать это «набором данных»).
Затем вы можете начать обнаруживать некоторые закономерности. Например, слово «круто» часто встречается, когда предложение помечено как положительное.
А что, если вместо слов вы захотите обнаружить закономерность в полных предложениях с учетом эмодзи, языка и т. Д. И выполнить это на очень больших наборах данных? Вы можете добиться этого без машинного обучения, но это может быть сложно.
Для достижения этой цели машинное обучение будет использовать мощность множества компьютеров и определенного программного обеспечения в соответствии с этим классическим рабочим процессом:
Первый шаг — получить чистые и полезные данные, называемые здесь «обучающими данными». В нашем предыдущем примере он состоит из классифицированных слов / предложений с оценкой тональности. Это одна из самых сложных частей процесса (получение актуальных и важных данных).
Если у вас есть данные, вы можете использовать специальную программную платформу для машинного обучения, такую как библиотеки Python, Pandas или Scikit-Learn, или студию искусственного интеллекта с визуальными интерфейсами, чтобы «учиться». Этот шаг потребует много энергии (вычислений), так как он будет пробовать различные статистические подходы, чтобы найти лучшие шаблоны.
Как только вы найдете наиболее подходящий шаблон, он сгенерирует то, что мы называем «моделью машинного обучения».
Как только вы его получите, эта модель сможет делать прогнозы. Если вы поместите новые данные в эту модель («вход» в схеме), будет сделан прогноз, дающий вам некоторые результаты. Впоследствии, чтобы оставаться в курсе, вам, возможно, придется периодически переобучать модель, используя более точные данные, новые алгоритмы и т. Д.
Этот вид процесса был ракетостроением несколько лет назад, но сегодня, поскольку требуемая мощность гораздо более доступна, благодаря поставщикам облачных услуг и достижениям в инструментах обработки данных, его можно реализовать с очень низкими затратами.
«Но… поскольку язык моей страны одинаков для всех компаний, может быть, я найду заранее созданную модель машинного обучения, которую смогу использовать для анализа настроений?»
Это дух! Для базовых проектов, в которых не требуется настройка, вы можете найти множество готовых решений. Навыки науки о данных не требуются, поскольку эти модели создаются сторонними организациями. Если у вас есть возможность использовать API, вы сможете их использовать. А если вы хотите попробовать несколько забавных моделей бесплатно, вы можете изучить рынок искусственного интеллекта OVH Labs ( market-place.ai.ovh.net/).
Подводя итог: независимо от размера вашей компании, машинное обучение может удовлетворить ваши потребности и принести реальную пользу. Он основан на инструментах статистики, но имеет несколько иные концепции и те же цели. Сегодня, благодаря участникам с открытым исходным кодом, вы можете найти множество готовых программных инструментов для машинного обучения, но когда вам нужна большая точность, это потребует некоторых навыков в области науки о данных.
Итак… Как машинное обучение может помочь вашей компании в повседневной жизни?
Даже не зная об этом, вы каждый день получаете пользу от машинного обучения в больших масштабах. У вас есть учетная запись электронной почты с функцией фильтрации спама? Машинное обучение. Вы смотрели Netflix и получили хорошие рекомендации? Машинное обучение. Вы использовали Waze, чтобы избежать пробок сегодня утром? Машинное обучение.
Если крупные компании используют его ежедневно, рост малых и средних компаний впечатляет.
Прежде всего, существует огромная разница между использованием программного обеспечения, которое уже оборудовано для машинного обучения, и разработкой собственного проекта машинного обучения.
Вот несколько простых реальных примеров, которые можно было бы развернуть за несколько шагов с помощью готовых решений (наука о данных не требуется!):
- Анализ настроений в социальных сетях вашего бренда, таких как Twitter и Facebook ( « На этой неделе, 67% людей говорили о нас положительно . « )
- Обнаруживать наготу на изображениях, загруженных на форумы, блоги, сообщества…
- Обнаруживать ненавистные тексты в комментариях, обзорах продуктов…
- Найдите объекты на изображениях и пометьте их (полезно для классификации продуктов и для SEO)
Использовать его так же просто, как этот пример кода для обнаружения объектов на изображениях (Python, Go, Java… даже PHP может его использовать):
curl -X POST «api-market-pl
curl -X POST "https://api-market-place.ai.ovh.net/image-recognition/detect" -H "accept: application/json" -H "X-OVH-Api-Key: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX" -H "Content-Type: application/json" -d '{"url":"https://mywebsite.com/images/input.jpg", "top_k": 2}'Результаты будут представлены с оценкой вероятности:
Более сложные варианты использования, такие как прогнозирование ваших запасов или доходов, обнаружение мошенничества и борьба с ним, или прогнозирование отключений и планового обслуживания, потребуют дополнительных знаний.
Каждой компании предстоит изучить несколько факторов. Вы можете попробовать готовые сервисы, но их точность не обязательно оправдает ваши ожидания.
Если это звучит знакомо, вас очень заинтересует следующая глава…
Извилистый путь к точным результатам
Как только вы перепрыгнете через мысленную пропасть сложности машинного обучения, вам придется встретиться и победить других монстров.
Здесь, вместо того чтобы использовать готовые решения, мы будем делать это сами…
Создание модели машинного обучения: теория
И… реальность для специалиста по данным
Мы встречаемся с компаниями и клиентами из разных областей, и каждый раз, когда мы обсуждаем с ними машинное обучение, никаких сюрпризов. Это всегда одни и те же болевые точки, которые можно резюмировать следующим образом:
- Идеи, отбор проектов и внутреннее наблюдение ( «Вы уверены, что этот проект машинного обучения принесет пользу?» )
- Проблемы с данными: недостаточно данных, предвзятость в данных, конфиденциальные данные…
- Отсутствие опыта в области науки о данных
- Точность модели (т.е. полученные вами результаты нельзя использовать)
- Переход от прототипа к производству: развертывание, масштабирование, управление версиями и т. Д.
- Бюджет
Шаг 1. Выбор идей / проектов и внутреннее сопровождение. Сначала это может показаться довольно простым, но все же критически важным. Специалисты по обработке данных не обладают знаниями в области маркетинга, здравоохранения или финансов, поэтому варианты использования должны исходить от конечных пользователей, а не от вашего ИТ-отдела.
Кроме того, этим запросчикам необходимо правильно определить свои потребности, а затем точно следовать проектам. Всегда просите их объяснить, чего они хотят достичь, когда у них будут ваши прогнозы.
Для крупных компаний необходим руководитель проекта на стороне конечного пользователя.
Шаг №2 . Проблемы с данными . Это часто решается путем правильного определения того, что мы ищем (например, шаг №1), а затем экспорта данных и их проверки вручную, где это возможно. Вы можете, например, проверить свои продажи и запасы, чтобы убедиться, что вы не пропустили данные. Если вам нужно продолжить очистку данных и измерение объема, это можно сделать вручную (со временем) или с помощью специальных инструментов, таких как OVHcloud AutoML, студии науки о данных, такие как Dataiku (которая доступна в бесплатной версии) или Apache Spark для обработки данных.
Но не только инструменты, но и понимание ваших данных является здесь основой.
Шаг №3 и №4 . Недостаток знаний в области науки о данных и точности моделей . Эти проблемы изначально могут быть решены путем сотрудничества с вашими партнерами. Например, в этой области сейчас специализируются многие консалтинговые фирмы, и это касается не только крупных компаний. И не забывайте, что вы также можете использовать готовые решения для начальных тестов, такие как те, которые доступны через OVHcloud AI Marketplace, поскольку это не потребует каких-либо навыков в области анализа данных.
Еще один вариант для изучения — это обучение некоторых из ваших сотрудников. Как мы уже упоминали ранее, программные инструменты и библиотеки теперь доступны широким массам, и, поскольку машинное обучение сегодня весьма интересно, вы можете легко найти добровольцев. Доступны онлайн-курсы обучения, такие как datacamp.com, openclassrooms.com, или обучающие видео от Udemy, Coursera или Pluralsight. Просто имейте в виду, что для этого потребуются статистика, алгебра и навыки общения, а не только программирование.
Шаг №5 . Теперь с OVHcloud перейти от прототипа к производству можно всего за две минуты! Мы только что выпустили новый инструмент под названием OVHcloud Serving Engine , который позволяет развертывать модели в нашем общедоступном облаке и доступен бесплатно на этапе раннего доступа.
Мы также развернули предварительно обученные модели для анализа настроений на французском и английском языках. Не стесняйтесь опробовать их в нашей панели управления публичным облаком!
Шаг №6. Бюджет. Честно говоря, вы можете начать заниматься машинным обучением на собственном ноутбуке. После этого вы можете использовать облачные ресурсы для обучения, но получение некоторых начальных результатов не будет вам дорого стоить. После того, как вы доказали, что результаты достижимы при небольшом бюджете, увеличение бюджета следует рассматривать как вложение, а не как затраты. Вы всегда можете делать это постепенно, поскольку облако изначально работает именно так — вы платите только за то, что потребляете.
Вывод
Я надеюсь, что после прочтения этого сообщения в блоге вы будете более уверены в изучении машинного обучения в этом году! OVHcloud впервые начал изучать эти темы пять лет назад и с тех пор приобрел много знаний в этой области. Сегодня мы лучше можем создавать инструменты и услуги нашей мечты, а затем предоставлять их вам. После выпуска нашей AI Studio и AI Marketplace мы будем сопровождать вас от НИОКР до производства с помощью механизма обслуживания OVHcloud.
Я рекомендую вам прочитать об этом в нашем следующем блоге! Будьте на связи…