Водяное охлаждение: от инноваций к революционным изменениям - Часть I
Одним из успехов OVHcloud является наша способность разрабатывать и продвигать инновации как в ИТ, так и в промышленных практиках. В течение двух десятилетий мы ставили инновации в центр нашей стратегии, это часть нашей ДНК. Мы постоянно исследуем и разрабатываем новые технологии, чтобы оптимизировать работу наших услуг.
Мы производим собственные серверы, строим собственные центры обработки данных и поддерживаем прочные долгосрочные отношения с другими технологическими партнерами с четкой целью: предоставлять самые инновационные решения с наилучшим соотношением цена / производительность. Самый очевидный пример, тесно связанный с нашей разработкой, — это идея использования воды для охлаждения наших серверов.

Мы начали использовать водяное охлаждение в промышленных масштабах в 2003 году, хотя это противоречило общепринятым в то время представлениям. Эта технология позволила нам последовательно повышать производительность серверов при одновременном снижении энергопотребления в наших центрах обработки данных. Задача заключалась не только в том, чтобы найти правильное соотношение между давлением, расходом, температурой и диаметром труб, но, прежде всего, в производстве решения в массовом масштабе.
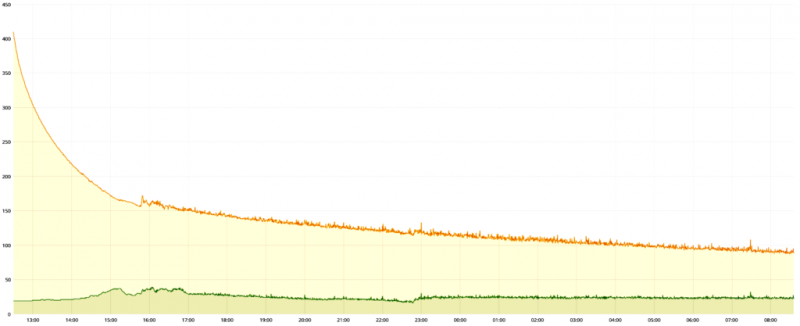
Экологические проблемы, связанные с цифровыми услугами, также вызывают серьезную озабоченность, особенно для наших центров обработки данных. Мы хорошо осознаем свое собственное воздействие на окружающую среду и постоянно стремимся снижать его на ежедневной основе. После подачи электроэнергии охлаждение серверов обычно является наиболее затратным занятием для хостинг-провайдеров с точки зрения электричества.
Водяное охлаждение в сочетании с системой охлаждения наружным воздухом позволяет нам значительно оптимизировать эффективность использования энергии (PUE) наших центров обработки данных. А меньшее потребление электроэнергии означает меньшие затраты для нас и наших клиентов, а также меньшее воздействие на окружающую среду.
С 2003 года мы разрабатываем собственную систему водяного охлаждения и устанавливаем ее в наших новых центрах обработки данных. Наши исторические заказчики первыми воспользовались новаторским и высокоэффективным процессом в промышленных масштабах.
Наши первые поколения технологии водоблоков были разработаны нашими командами и изготовлены на стороне. Эти водоблоки имели оптимальную производительность 60 Вт при температуре воды 30 ° C.
В первом поколении водяного охлаждения использовались очень простые водоблоки с двумя медными выпуклыми концами, обжатыми вместе:

На следующей итерации наших водоблоков мы добавили некоторые изменения для повышения надежности и снижения затрат:

Чтобы облегчить монтаж труб и улучшить герметичность, мы снова изменили технологию водоблока, введя компрессионные фитинги, которые более надежны и легче соединяются.

На разрезе водоблока показана ранняя структура теплогидравлики, где полностью гладкая поверхность основания образует резервуар с крышкой:

В отличие от других поставщиков мы полностью контролируем нашу цепочку создания стоимости, что означает, что мы можем предлагать передовые решения по очень конкурентоспособной цене, а это очень важно для наших клиентов.
В течение этого периода мы по-прежнему разрабатывали наши водоблоки внутри и производили их внешне. Оптимальная мощность для этого поколения водоблоков — 60 Вт при температуре воды 30 ° C.
Наши водоблоки продолжали развиваться. Мы заменили медную выпуклую торцевую опорную пластину простой пластиной. Крест на крышке заменили крестиком внутри водоблока. Это позволило нам еще больше снизить стоимость водоблоков без снижения производительности.

Мы всегда стараемся быть новаторами и прокладывать свой собственный путь. С 2013 года мы постоянно переосмысливали нашу технологию водяного охлаждения, улучшая производительность, работу и стоимость. Эти постоянные инновации позволяют нам идти в ногу с постоянно растущими потребностями наших клиентов в увеличении вычислительной мощности и емкости хранения данных, а также в постоянно увеличивающемся количестве выделяемого тепла.
Водоблоки, созданные в этот период, полностью отличались от предыдущих поколений. Мы заменили сварку затяжкой на винтах, а выпуклые верхние пластины были заменены пластинами со встроенными впускными и выпускными отверстиями для воды.

На этом этапе мы начали делать вариации водоблока, например адаптировать их к меньшим форм-факторам GPU:

Здесь вы можете сравнить стандартный водоблок процессора и более компактный водоблок графического процессора:

Мы также разработали несколько специальных конструкций водоблоков, адаптированных к конкретным ограничениям:

Хорошим примером является водоблок, который мы разработали для процессоров высокой плотности IBM Power 8. На следующем снимке вы можете увидеть крышку и опорные плиты этого специального водоблока:

Крышка и опорные пластины водяного блока, используемые в процессорах IBM Power8 высокой плотности
В предыдущих абзацах описывалась наша технология водоблоков в 2014 году. С тех пор мы прошли долгий путь. Мы использовали новые технологии, такие как 3D-печать, и внесли некоторые фундаментальные изменения в дизайн.
В ближайшие недели мы опубликуем следующие статьи в нашей серии о водяном охлаждении. Они расскажут историю развития наших водоблоков с 2015 года. Мы сосредоточимся на нынешнем поколении и дадим вам краткий обзор будущих улучшений.
Следите за нашей следующей публикацией, чтобы узнать больше о водяном охлаждении OVHcloud!
Мы производим собственные серверы, строим собственные центры обработки данных и поддерживаем прочные долгосрочные отношения с другими технологическими партнерами с четкой целью: предоставлять самые инновационные решения с наилучшим соотношением цена / производительность. Самый очевидный пример, тесно связанный с нашей разработкой, — это идея использования воды для охлаждения наших серверов.
Мы начали использовать водяное охлаждение в промышленных масштабах в 2003 году, хотя это противоречило общепринятым в то время представлениям. Эта технология позволила нам последовательно повышать производительность серверов при одновременном снижении энергопотребления в наших центрах обработки данных. Задача заключалась не только в том, чтобы найти правильное соотношение между давлением, расходом, температурой и диаметром труб, но, прежде всего, в производстве решения в массовом масштабе.
Экологические проблемы, связанные с цифровыми услугами, также вызывают серьезную озабоченность, особенно для наших центров обработки данных. Мы хорошо осознаем свое собственное воздействие на окружающую среду и постоянно стремимся снижать его на ежедневной основе. После подачи электроэнергии охлаждение серверов обычно является наиболее затратным занятием для хостинг-провайдеров с точки зрения электричества.
Водяное охлаждение в сочетании с системой охлаждения наружным воздухом позволяет нам значительно оптимизировать эффективность использования энергии (PUE) наших центров обработки данных. А меньшее потребление электроэнергии означает меньшие затраты для нас и наших клиентов, а также меньшее воздействие на окружающую среду.
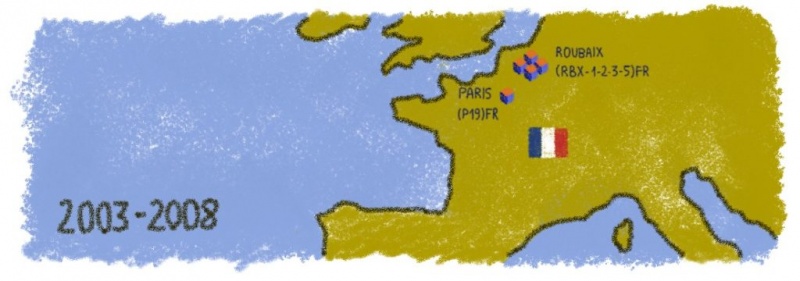
2003-2008 гг.
С 2003 года мы разрабатываем собственную систему водяного охлаждения и устанавливаем ее в наших новых центрах обработки данных. Наши исторические заказчики первыми воспользовались новаторским и высокоэффективным процессом в промышленных масштабах.
Наши первые поколения технологии водоблоков были разработаны нашими командами и изготовлены на стороне. Эти водоблоки имели оптимальную производительность 60 Вт при температуре воды 30 ° C.
В первом поколении водяного охлаждения использовались очень простые водоблоки с двумя медными выпуклыми концами, обжатыми вместе:
На следующей итерации наших водоблоков мы добавили некоторые изменения для повышения надежности и снижения затрат:
- Технология опрессовки заменена пайкой
- Вставные фитинги из нержавеющей стали заменили латунные
- К крышке также добавлен крестик, чтобы водоблок лучше фиксировался на чипе.
Чтобы облегчить монтаж труб и улучшить герметичность, мы снова изменили технологию водоблока, введя компрессионные фитинги, которые более надежны и легче соединяются.
На разрезе водоблока показана ранняя структура теплогидравлики, где полностью гладкая поверхность основания образует резервуар с крышкой:
2011 г.
В отличие от других поставщиков мы полностью контролируем нашу цепочку создания стоимости, что означает, что мы можем предлагать передовые решения по очень конкурентоспособной цене, а это очень важно для наших клиентов.
В течение этого периода мы по-прежнему разрабатывали наши водоблоки внутри и производили их внешне. Оптимальная мощность для этого поколения водоблоков — 60 Вт при температуре воды 30 ° C.
Наши водоблоки продолжали развиваться. Мы заменили медную выпуклую торцевую опорную пластину простой пластиной. Крест на крышке заменили крестиком внутри водоблока. Это позволило нам еще больше снизить стоимость водоблоков без снижения производительности.
2013-2014 гг.
Мы всегда стараемся быть новаторами и прокладывать свой собственный путь. С 2013 года мы постоянно переосмысливали нашу технологию водяного охлаждения, улучшая производительность, работу и стоимость. Эти постоянные инновации позволяют нам идти в ногу с постоянно растущими потребностями наших клиентов в увеличении вычислительной мощности и емкости хранения данных, а также в постоянно увеличивающемся количестве выделяемого тепла.
Водоблоки, созданные в этот период, полностью отличались от предыдущих поколений. Мы заменили сварку затяжкой на винтах, а выпуклые верхние пластины были заменены пластинами со встроенными впускными и выпускными отверстиями для воды.
Прочие факторы
На этом этапе мы начали делать вариации водоблока, например адаптировать их к меньшим форм-факторам GPU:
Здесь вы можете сравнить стандартный водоблок процессора и более компактный водоблок графического процессора:
Мы также разработали несколько специальных конструкций водоблоков, адаптированных к конкретным ограничениям:
Хорошим примером является водоблок, который мы разработали для процессоров высокой плотности IBM Power 8. На следующем снимке вы можете увидеть крышку и опорные плиты этого специального водоблока:
Крышка и опорные пластины водяного блока, используемые в процессорах IBM Power8 высокой плотности
2015 и далее
В предыдущих абзацах описывалась наша технология водоблоков в 2014 году. С тех пор мы прошли долгий путь. Мы использовали новые технологии, такие как 3D-печать, и внесли некоторые фундаментальные изменения в дизайн.
В ближайшие недели мы опубликуем следующие статьи в нашей серии о водяном охлаждении. Они расскажут историю развития наших водоблоков с 2015 года. Мы сосредоточимся на нынешнем поколении и дадим вам краткий обзор будущих улучшений.
Следите за нашей следующей публикацией, чтобы узнать больше о водяном охлаждении OVHcloud!