Гибкая телеметрия в OVHCloud - Часть III
Эта статья является третьей в серии статей, мы рекомендуем сначала прочитать часть 1 и часть 2:
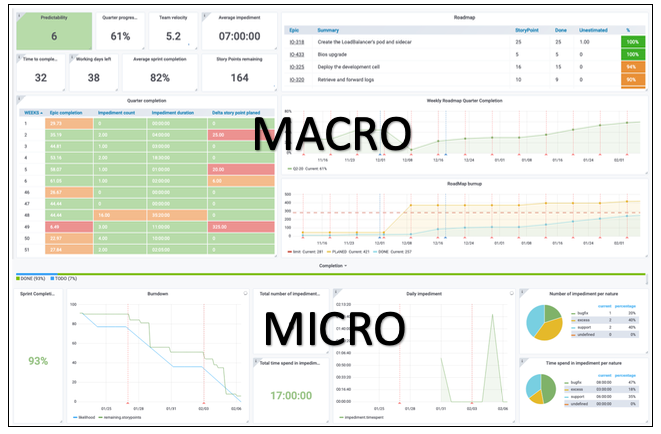
В последнем посте, посвященном гибкой телеметрии, мы сосредоточимся на микровидении. В любом проекте разделение микро и макро видения жизненно важно для эффективного общения.
Для команд разработчиков микровидение имеет решающее значение. В то время как макроэкономическая перспектива важна для достижения таких целей, как сроки поставки, наблюдение за микродетализацией разработки обеспечивает хорошее качество продукта. Вот как нам удалось достичь этой важной цели:
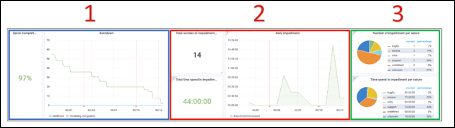
Три блока данных
В этой части нашей панели инструментов отображаются три важных элемента информации, касающихся хода наших спринтов: ожидаемое, неожиданное и причина неожиданного.
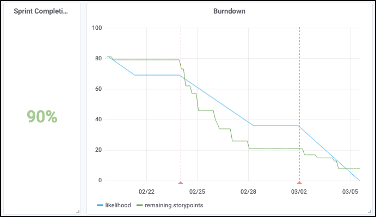
BurdownChart
(1) Это прогресс текущего спринта и его процент завершения. Процент выполнения просто вычисляется:
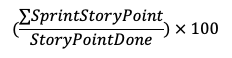
(2) Это показывает, сколько раз команда разработчиков выходила из спринта, чтобы что-то исправить, и время завершения. На прилагаемом графике показаны пиковые дни, когда команда была мобилизована.
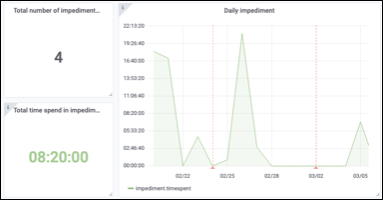
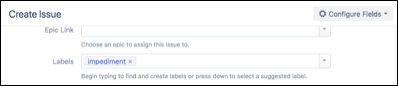
Чтобы сообщить об этом типе информации:
Накопленная информация затем отображается на нашей панели инструментов. Это помогает нам понять, почему спринт не продвигается. Когда команды проводят недели на устранение неполадок, мы можем объяснить почему.
(3) В последней части рассказывается, почему команды вмешались, когда они вышли из спринта. Эти ценные данные дают нам четкое представление о ситуации. Если команда тратит 90% своего времени на устранение ошибок или устранение неполадок в поддержке, это дает информацию о процессах принятия решений для будущих проектов.
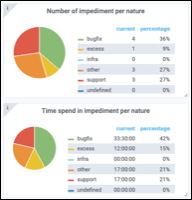
Природа препятствия
Пример: мы предоставляем 30 часов на исправление ошибок во время спринтов; должны ли мы сосредоточиться на создании чего-то нового или сокращении технического долга?
Вывод: Сегодня Agile-телеметрию используют 19 команд в OVHCloud. Это облегчает и позволяет нам измерять производительность и прогресс команд удаленно и в режиме реального времени. Он также предоставляет нам актуальную информацию, необходимую для реализации наших проектов. Именно эта методология получила награду Innovations Awards для сотрудников OVHCloud.
Если вы хотите погрузиться в Agile Telemetry, вы можете сделать это прямо сейчас!!! Просто возьмите нашу панель инструментов с открытым исходным кодом и нашего бота Jerem — github.com/ovh/jerem.
- Рождение гибкой телеметрии в OVHcloud — Часть I
- Гибкая телеметрия в OVHCloud — Часть II
В последнем посте, посвященном гибкой телеметрии, мы сосредоточимся на микровидении. В любом проекте разделение микро и макро видения жизненно важно для эффективного общения.
Макро и Микровидение
Для команд разработчиков микровидение имеет решающее значение. В то время как макроэкономическая перспектива важна для достижения таких целей, как сроки поставки, наблюдение за микродетализацией разработки обеспечивает хорошее качество продукта. Вот как нам удалось достичь этой важной цели:
Микровидение
Три блока данных
В этой части нашей панели инструментов отображаются три важных элемента информации, касающихся хода наших спринтов: ожидаемое, неожиданное и причина неожиданного.
BurdownChart
(1) Это прогресс текущего спринта и его процент завершения. Процент выполнения просто вычисляется:
(2) Это показывает, сколько раз команда разработчиков выходила из спринта, чтобы что-то исправить, и время завершения. На прилагаемом графике показаны пиковые дни, когда команда была мобилизована.
Чтобы сообщить об этом типе информации:
- Команды добавляют в поле «Ярлык» JIRA заголовок: препятствие.
- Они регистрируют время, проведенное в поле «Журнал работы» в JIRA.
Накопленная информация затем отображается на нашей панели инструментов. Это помогает нам понять, почему спринт не продвигается. Когда команды проводят недели на устранение неполадок, мы можем объяснить почему.
NB: Важно отделить спринт от препятствий. Эти две части информации позволяют сравнить «ожидаемое» и «неожиданное». Это позволяет предложить 2 типа графиков.
(3) В последней части рассказывается, почему команды вмешались, когда они вышли из спринта. Эти ценные данные дают нам четкое представление о ситуации. Если команда тратит 90% своего времени на устранение ошибок или устранение неполадок в поддержке, это дает информацию о процессах принятия решений для будущих проектов.
Природа препятствия
Пример: мы предоставляем 30 часов на исправление ошибок во время спринтов; должны ли мы сосредоточиться на создании чего-то нового или сокращении технического долга?
Вывод: Сегодня Agile-телеметрию используют 19 команд в OVHCloud. Это облегчает и позволяет нам измерять производительность и прогресс команд удаленно и в режиме реального времени. Он также предоставляет нам актуальную информацию, необходимую для реализации наших проектов. Именно эта методология получила награду Innovations Awards для сотрудников OVHCloud.
Если вы хотите погрузиться в Agile Telemetry, вы можете сделать это прямо сейчас!!! Просто возьмите нашу панель инструментов с открытым исходным кодом и нашего бота Jerem — github.com/ovh/jerem.