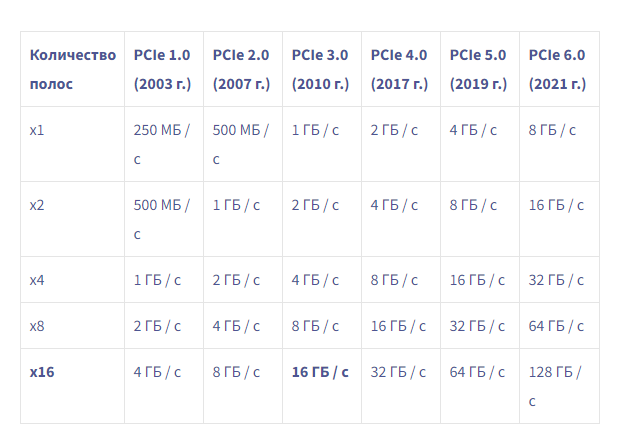
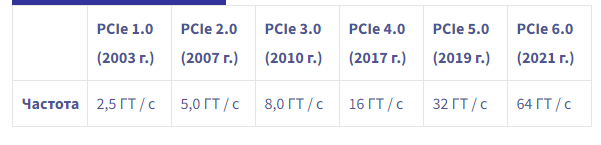
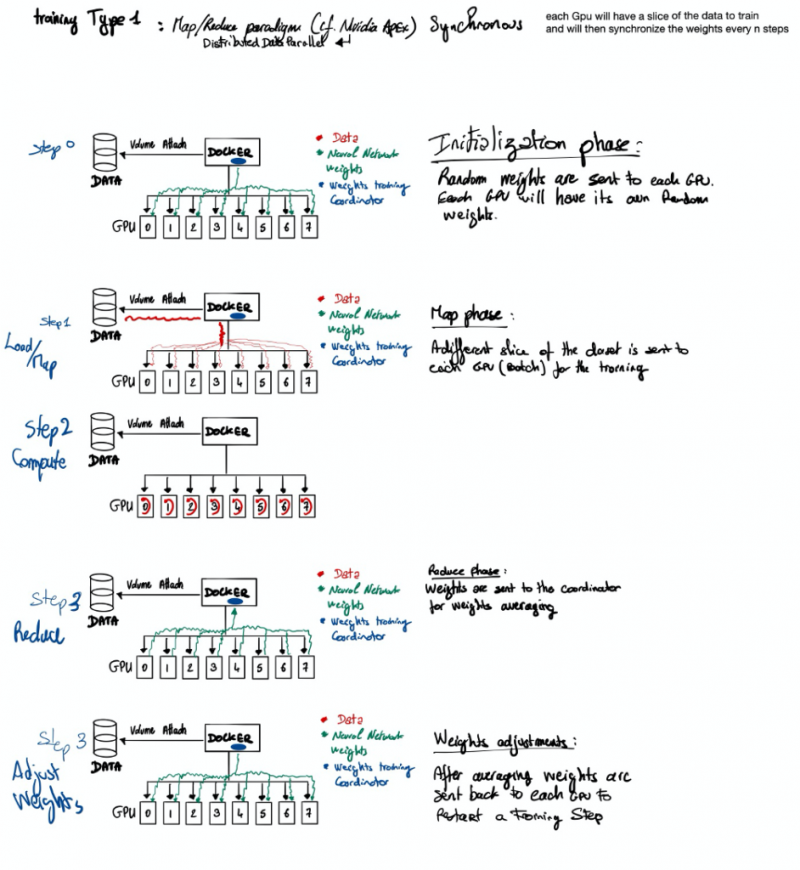
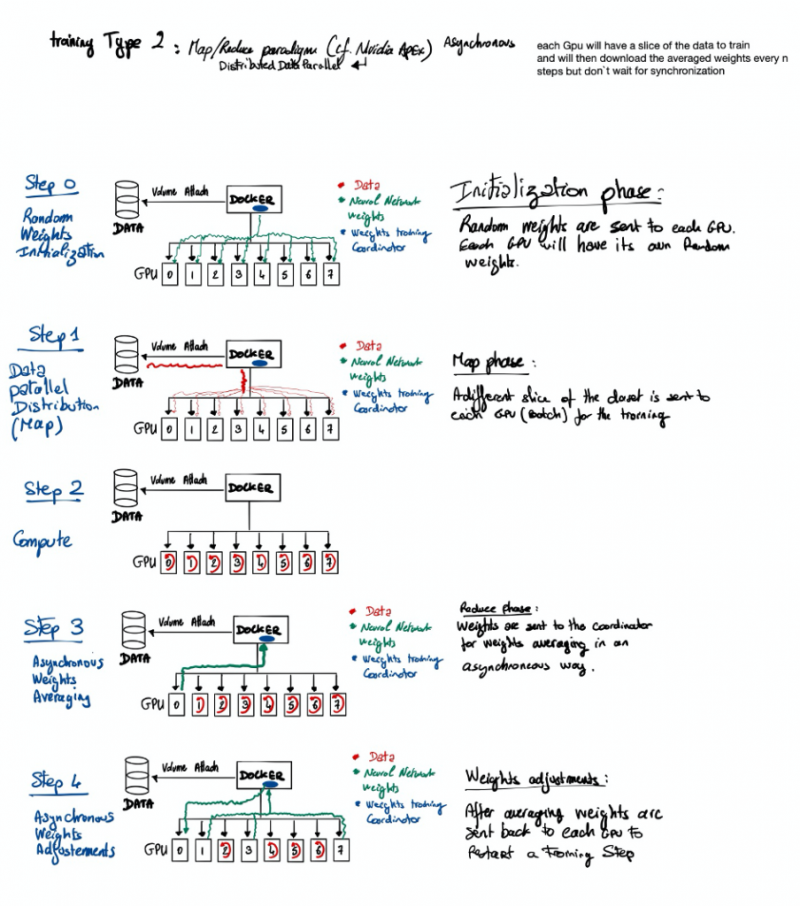
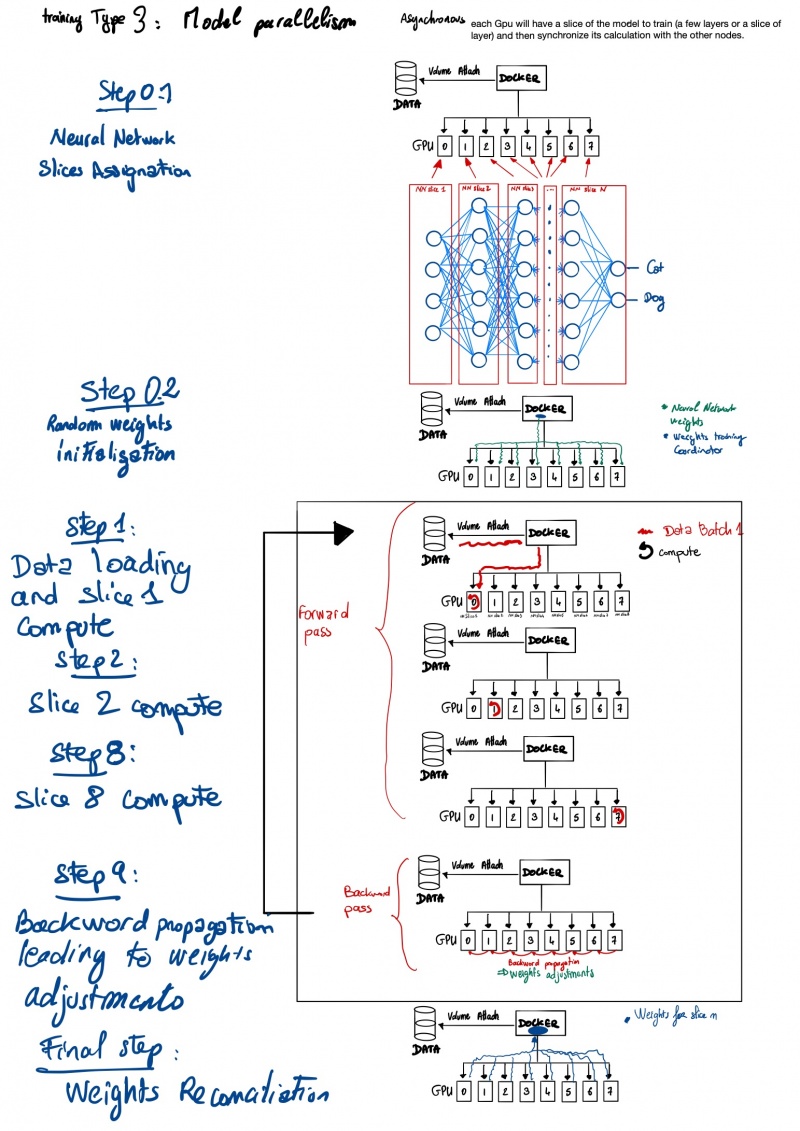
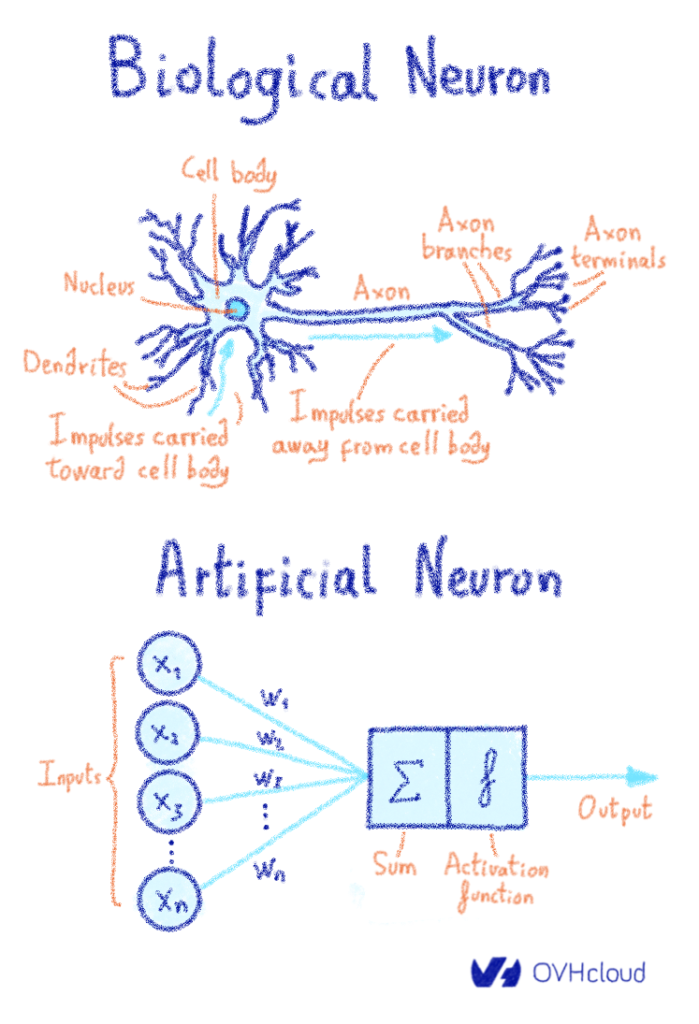
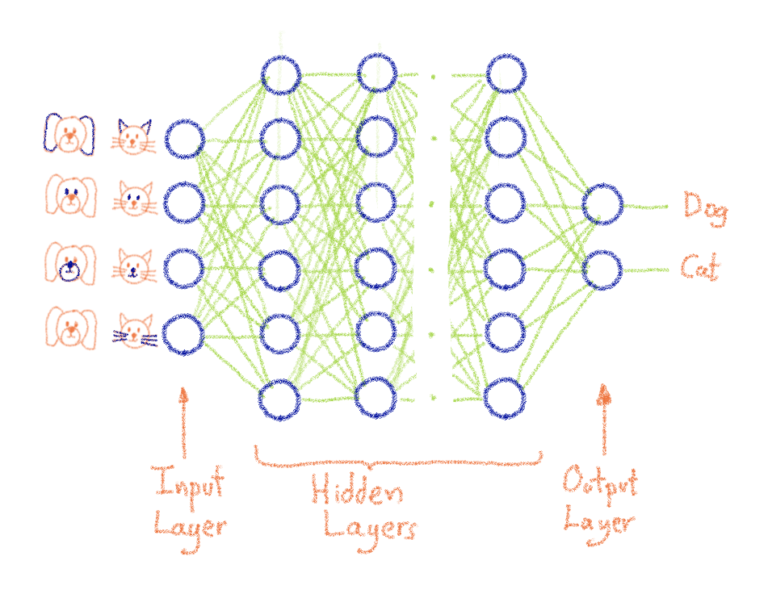
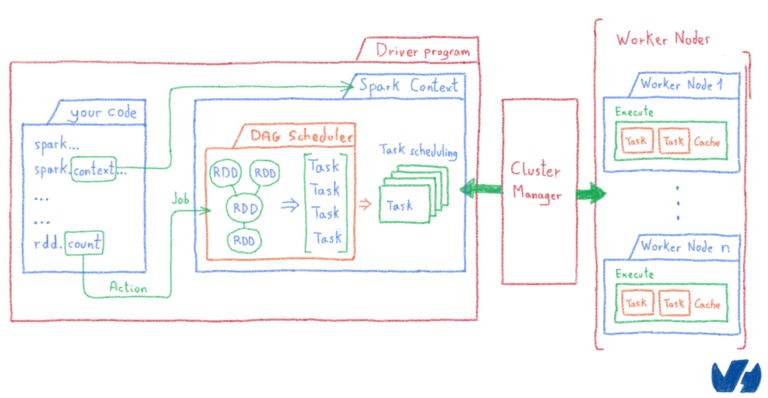
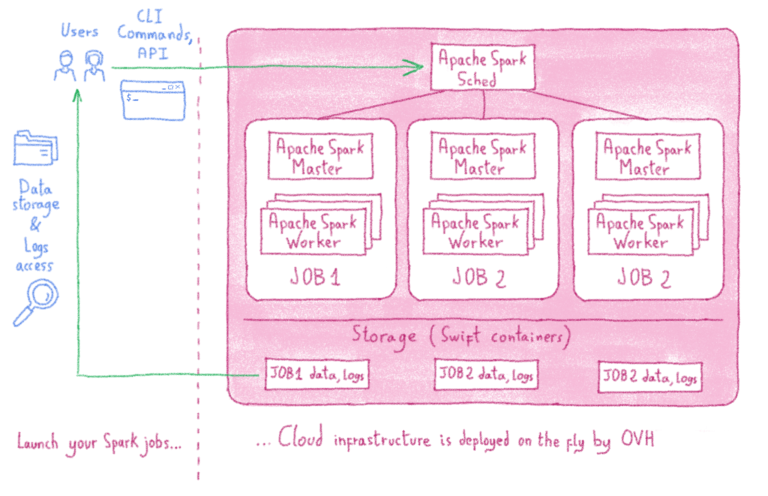
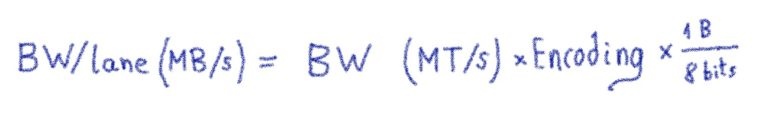Путешествие по чудесной стране машинного обучения или «Могу ли я купить дворец в Париже за 100 000 евро?» (Часть 2)
Спойлер, нет, нельзя.

Несколько месяцев назад я объяснил, как использовать Dataiku — известную интерактивную студию AI — и как использовать данные, предоставленные французским правительством, для построения модели машинного обучения, прогнозирующей рыночную стоимость недвижимости. К сожалению, это с треском провалилось: когда я попробовал это на сделках, совершенных на моей улице, в том же году, когда я купил свою квартиру, модель предсказала, что все они имеют одинаковую рыночную стоимость.
В этом сообщении в блоге я укажу несколько причин, по которым наш эксперимент потерпел неудачу, а затем я попытаюсь обучить новую модель, принимая во внимание то, что мы узнали.
Наша модель потерпела неудачу по нескольким причинам. Из них выделяются три:
Вы можете найти описание структуры данных на специальной веб-странице. Я не буду перечислять все столбцы схемы (их 40), но самый важный из них — первый: id_mutation. Эта информация представляет собой уникальный номер транзакции, а не необычный столбец для поиска.
Однако, если вы посмотрите на сам набор данных, вы увидите, что некоторые транзакции распределены по нескольким строкам. Они соответствуют транзакциям перегруппировки нескольких посылок. В примере с моей собственной сделкой есть две строки: одна для самой квартиры, а другая для отдельного подвала под зданием.
Проблема в том, что на каждой такой строке указана полная цена. С точки зрения моей студии искусственного интеллекта, которая видит только набор линий, которые она интерпретирует как точки данных, похоже, что мой подвал и мои квартиры — это два разных объекта недвижимости, которые стоят одинаково! Ситуация ухудшается для собственности, у которой есть земли и несколько построек, прикрепленных к ним. Как мы можем ожидать, что наш алгоритм обучится должным образом в этих условиях?
Разнообразие данных
В данном случае мы пытаемся спрогнозировать стоимость квартиры в Париже. Однако данные, которые мы предоставили алгоритму, объединяют каждую сделку с недвижимостью, совершенную во Франции за последние несколько лет. Вы можете подумать, что чем больше данных, тем лучше, но это не обязательно.
Рынок недвижимости меняется в зависимости от того, где вы находитесь, и Париж — очень специфический случай для Франции, где цены намного выше, чем в других крупных городах и остальной части Франции. Конечно, это видно по данным, но алгоритм обучения не знает этого заранее, и ему очень сложно научиться оценивать небольшую квартиру в Париже и ферму с акрами земли в Лозере на то же время.

Параметры обучения модели
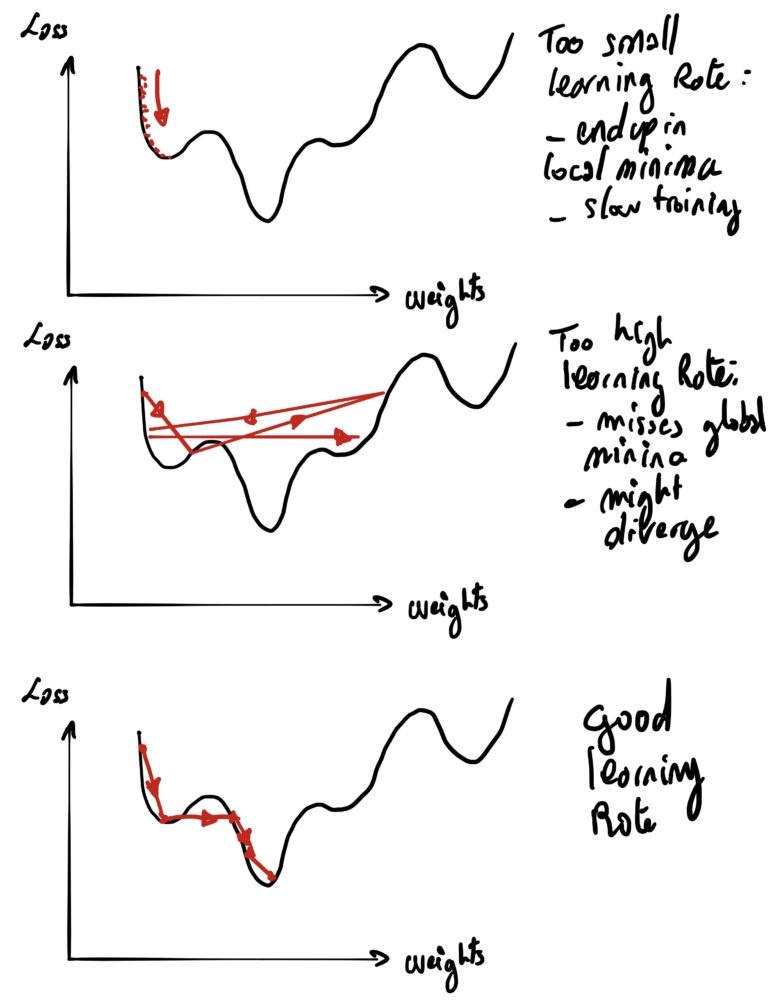
В последнем сообщении в блоге вы увидели, насколько просто использовать Dataiku. Но за это приходится платить: сценарий по умолчанию можно использовать для очень простых случаев использования. Но он не подходит для сложных задач — например, прогнозирования цен на недвижимость. У меня самого нет большого опыта работы с Dataiku. Однако, углубившись в детали, я смог исправить несколько очевидных ошибок:

К счастью, есть способы решить эти проблемы. Dataiku объединяет инструменты для преобразования и фильтрации ваших наборов данных перед запуском ваших алгоритмов. Он также позволяет изменять параметры тренировки. Вместо того, чтобы проводить вас через все шаги, я собираюсь подвести итог тому, что я сделал для каждой из проблем, которые мы определили ранее:
Макет данных
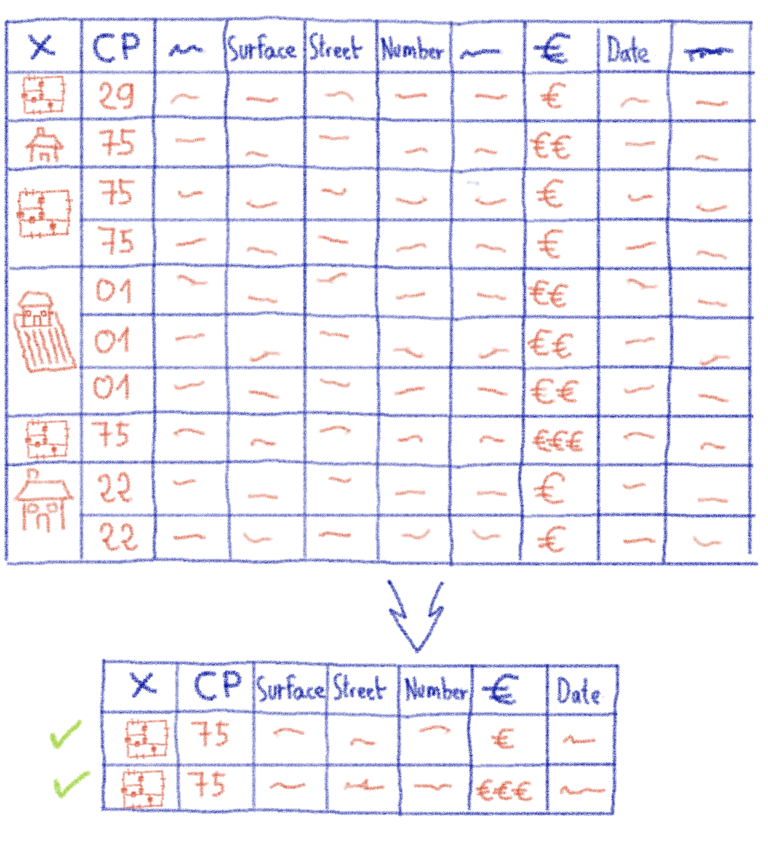
Разнообразие данных

Параметры обучения модели
Параметры обучения модели:
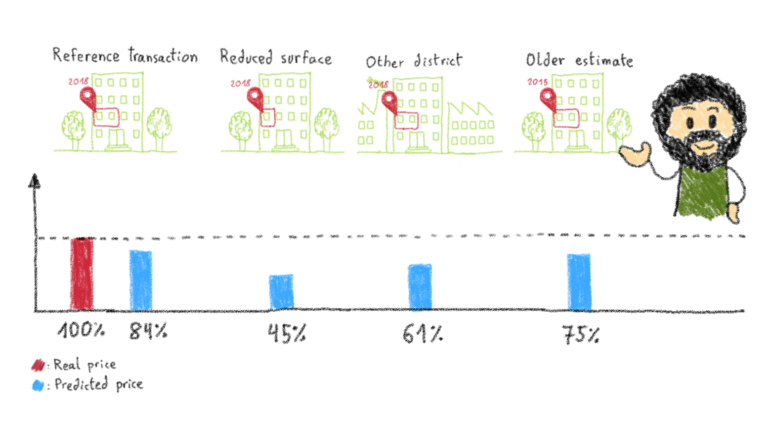
Итак, как мы поживали после всего этого? Что ж, для начала давайте посмотрим на рейтинг R2 наших моделей. В зависимости от тренировки наши лучшие модели имеют оценку R2 от 0,8 до 0,85. Напоминаем, что оценка R2, равная 1, будет означать, что модель идеально предсказывает стоимость каждой точки данных, используемой на этапе оценки обучения. Лучшие модели в наших предыдущих попытках имели оценку R2 от 0,1 до 0,2, так что здесь мы уже явно лучше. Давайте теперь посмотрим на несколько прогнозов этой модели.
Сначала я перепроверил все транзакции со своей улицы. На этот раз прогноз для моей квартиры на ~ 16% ниже цены, которую я заплатил. Но, в отличие от прошлого раза, у каждой квартиры разная оценка, и все эти оценки указаны в правильном порядке. Большинство значений имеют ошибку менее 20% по сравнению с реальной ценой, а худшие оценки имеют ошибку ~ 50%. Очевидно, такая погрешность недопустима при инвестировании в квартиру. Однако по сравнению с предыдущей версией нашей модели, которая давала одинаковую оценку для всех квартир на моей улице, мы добились значительного прогресса.

Итак, теперь, когда у нас, по крайней мере, есть правильный порядок величины, давайте попробуем настроить некоторые значения в нашем входном наборе данных, чтобы увидеть, реагирует ли модель предсказуемо. Для этого я взял точку данных моей собственной транзакции и создал новые точки данных, каждый раз изменяя одну из характеристик исходной точки данных:
С каждой из этих модификаций мы ожидаем, что новые оценки будут ниже первоначальной (рынок недвижимости в Париже находится в постоянной инфляции). Посмотрим на результаты:
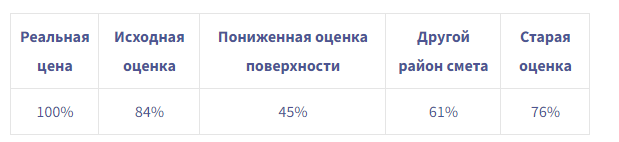
По крайней мере, качественно модель ведет себя должным образом.
На этом этапе мы использовали здравый смысл, чтобы значительно улучшить наши предыдущие результаты и построить модель, которая дает прогнозы в хорошем порядке и ведет себя так, как мы ожидаем, при настройке характеристик точек данных. Однако оставшаяся погрешность делает его непригодным для реального применения. Но почему и что мы могли сделать, чтобы продолжать улучшать нашу модель? На то есть несколько причин:
Сложность данных: я немного противоречу себе. Хотя сложные данные сложнее переварить для алгоритма машинного обучения, необходимо сохранить эту сложность, если она отражает сложность в конечном результате. В этом случае мы могли не только чрезмерно упростить данные, но и сами исходные данные могли не иметь большого количества соответствующей информации.
Мы обучили наш алгоритм общему расположению и поверхности, которые, по общему признанию, являются наиболее важными критериями, но в нашем наборе данных отсутствует очень важная информация, такая как полы, экспозиция, годы строительства, диагностика изоляции, состояние, доступность, вид, общее состояние квартир и т. Д.
Существуют частные наборы данных, созданные нотариальными конторами, которые более полны, чем наш открытый набор данных, но хотя они могут иметь такие характеристики, как пол или год постройки, в них, вероятно, не будет более субъективной информации; например, общее состояние или вид.
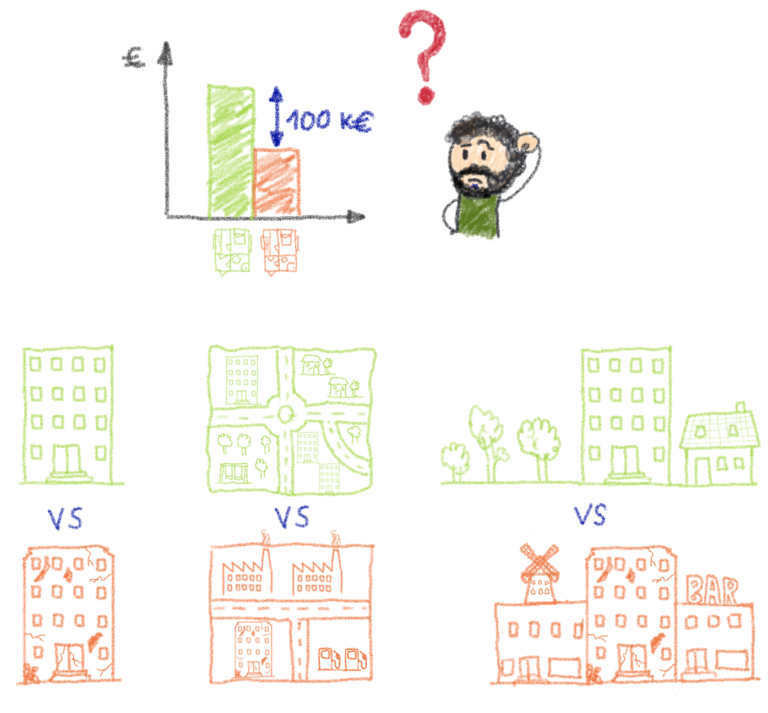
В наборе данных отсутствует очень важная информация о квартирах.
В этом сообщении блога мы обсудили, почему наша предыдущая попытка обучить модель предсказывать цены на квартиры в Париже потерпела неудачу. Данные, которые мы использовали, не были достаточно очищены, и мы использовали параметры обучения Dataiku по умолчанию, а не проверяли их целесообразность.
После этого мы исправили наши ошибки, очистили данные и настроили параметры обучения. Это значительно улучшило результат нашей модели, но недостаточно для реалистичного использования. Есть способы улучшить модель, но в доступных наборах данных не хватает некоторой информации, а самих данных может быть недостаточно для построения надежной модели.
К счастью, цель этой серии никогда не заключалась в том, чтобы точно предсказать цены на квартиры в Париже. Если бы это было возможно, не было бы больше агентств недвижимости. Вместо этого он служит иллюстрацией того, как любой может взять необработанные данные, найти проблему, связанную с данными, и обучить модель решать эту проблему.
Однако набор данных, который мы использовали в этом примере, был довольно небольшим: всего несколько гигабайт. Все происходило на одной виртуальной машине, и нам приходилось делать все вручную, с фиксированным набором данных. Что бы я сделал, если бы хотел обрабатывать петабайты данных? Если бы я хотел обрабатывать непрерывную потоковую передачу данных? Если бы я хотел раскрыть свою модель, чтобы внешние приложения могли ее запрашивать?
Это то, что мы собираемся рассмотреть в следующий раз, в последнем сообщении блога этой серии.
Несколько месяцев назад я объяснил, как использовать Dataiku — известную интерактивную студию AI — и как использовать данные, предоставленные французским правительством, для построения модели машинного обучения, прогнозирующей рыночную стоимость недвижимости. К сожалению, это с треском провалилось: когда я попробовал это на сделках, совершенных на моей улице, в том же году, когда я купил свою квартиру, модель предсказала, что все они имеют одинаковую рыночную стоимость.
В этом сообщении в блоге я укажу несколько причин, по которым наш эксперимент потерпел неудачу, а затем я попытаюсь обучить новую модель, принимая во внимание то, что мы узнали.
Почему наша модель не удалась
Наша модель потерпела неудачу по нескольким причинам. Из них выделяются три:
- Макет формата открытых данных
- Разнообразие данных
- Параметры модели Dataiku по умолчанию
Макет формата открытых данных
Вы можете найти описание структуры данных на специальной веб-странице. Я не буду перечислять все столбцы схемы (их 40), но самый важный из них — первый: id_mutation. Эта информация представляет собой уникальный номер транзакции, а не необычный столбец для поиска.
Однако, если вы посмотрите на сам набор данных, вы увидите, что некоторые транзакции распределены по нескольким строкам. Они соответствуют транзакциям перегруппировки нескольких посылок. В примере с моей собственной сделкой есть две строки: одна для самой квартиры, а другая для отдельного подвала под зданием.
Проблема в том, что на каждой такой строке указана полная цена. С точки зрения моей студии искусственного интеллекта, которая видит только набор линий, которые она интерпретирует как точки данных, похоже, что мой подвал и мои квартиры — это два разных объекта недвижимости, которые стоят одинаково! Ситуация ухудшается для собственности, у которой есть земли и несколько построек, прикрепленных к ним. Как мы можем ожидать, что наш алгоритм обучится должным образом в этих условиях?
Разнообразие данных
В данном случае мы пытаемся спрогнозировать стоимость квартиры в Париже. Однако данные, которые мы предоставили алгоритму, объединяют каждую сделку с недвижимостью, совершенную во Франции за последние несколько лет. Вы можете подумать, что чем больше данных, тем лучше, но это не обязательно.
Рынок недвижимости меняется в зависимости от того, где вы находитесь, и Париж — очень специфический случай для Франции, где цены намного выше, чем в других крупных городах и остальной части Франции. Конечно, это видно по данным, но алгоритм обучения не знает этого заранее, и ему очень сложно научиться оценивать небольшую квартиру в Париже и ферму с акрами земли в Лозере на то же время.
Параметры обучения модели
В последнем сообщении в блоге вы увидели, насколько просто использовать Dataiku. Но за это приходится платить: сценарий по умолчанию можно использовать для очень простых случаев использования. Но он не подходит для сложных задач — например, прогнозирования цен на недвижимость. У меня самого нет большого опыта работы с Dataiku. Однако, углубившись в детали, я смог исправить несколько очевидных ошибок:
- Типы данных: многие столбцы в наборе данных относятся к определенным типам: целые числа, географические координаты, даты и т. Д. Большинство из них правильно определены Dataiku, но некоторые из них — например, географические координаты или даты — нет.
- Анализ данных: если вы помните предыдущий пост, в какой-то момент мы рассматривали разные модели, обученные алгоритмом. У нас не было времени взглянуть на автоматизацию модели. Этот раздел позволяет нам настроить несколько элементов; такие как типы алгоритмов, которые мы запускаем, параметры обучения, выбор набора данных и т. д.
- С таким большим количеством функций, присутствующих в наборе данных, Dataiku попытался уменьшить количество функций, которые он будет анализировать, чтобы упростить алгоритм обучения. Но он сделал плохой выбор. Например, учитывается номер улицы, но не сама улица. Хуже того, он даже не смотрит на дату или площадь участков (но он действительно учитывает поверхность земли, если она есть…), что, безусловно, является самым важным фактором в большинстве городов!
Как все это исправить
К счастью, есть способы решить эти проблемы. Dataiku объединяет инструменты для преобразования и фильтрации ваших наборов данных перед запуском ваших алгоритмов. Он также позволяет изменять параметры тренировки. Вместо того, чтобы проводить вас через все шаги, я собираюсь подвести итог тому, что я сделал для каждой из проблем, которые мы определили ранее:
Макет данных
- Сначала я сгруппировал строки, соответствующие одним и тем же транзакциям. В зависимости от полей я либо суммировал их (например, когда это была жилая площадь), сохранял одно из них (адрес) или объединял их (например, когда это был идентификатор хозяйственной постройки).
- Во-вторых, я удалил несколько ненужных или избыточных полей, добавляющих шум в алгоритм; например, название улицы (уже существуют уникальные для каждого города коды улиц), суффикс номера улицы («Bis» или «Ter», обычно встречающиеся в адресе после номера дома) или другая информация, относящаяся к администрации.
- Наконец, некоторые транзакции содержат не только несколько участков (на нескольких строках), но также несколько подпунктов на участок, каждый со своей собственной поверхностью и номером подпункта. Это подразделение в основном административное, и участки часто представляют собой ранее прилегающие квартиры, которые были объединены. Чтобы упростить данные, я вырезал номера участков и суммировал их соответствующие поверхности, прежде чем перегруппировать линии.
Разнообразие данных
- Во-первых, поскольку мы пытаемся обучить модель для оценки стоимости парижских квартир, я отфильтровал все транзакции, которые не происходили в Париже (а это, как вы можете ожидать, большая часть).
- Во-вторых, я удалил все транзакции, у которых были неполные данные для важных полей (таких как поверхность или адрес).
- Наконец, я удалил выбросы: транзакции, соответствующие объектам недвижимости, которые не соответствуют стандартным квартирам; такие как дома, коммерческая земля, элитные квартиры и т. д.
Параметры обучения модели
Параметры обучения модели:
- Во-первых, я убедился, что в модели учтены все особенности. Примечание: вместо того, чтобы удалять ненужные поля из набора данных, я мог бы просто сказать алгоритму игнорировать соответствующие функции. Однако я предпочитаю повысить удобочитаемость набора данных, чтобы облегчить его изучение. Более того, Dataiku загружает данные в ОЗУ для их обработки, поэтому запуск на чистом наборе данных делает его более эффективным для ОЗУ.
- Во-вторых, я обучил алгоритм различным наборам функций: в некоторых случаях я сохранил район, но не улицу. Поскольку в Париже много разных улиц, это категориальный признак с высокой мощностью (множество различных возможностей, которые невозможно перечислить).
- Наконец, я попробовал разные семейства алгоритмов машинного обучения: Случайный лес — в основном построение дерева решений; XGBoost — повышение градиента; SVM (Support Vector Machine) — обобщение линейных классификаторов; и KNN (K-Nearest-Neighbours) — который пытается классифицировать точки данных, глядя на своих соседей в соответствии с различными показателями.
Это сработало?
Итак, как мы поживали после всего этого? Что ж, для начала давайте посмотрим на рейтинг R2 наших моделей. В зависимости от тренировки наши лучшие модели имеют оценку R2 от 0,8 до 0,85. Напоминаем, что оценка R2, равная 1, будет означать, что модель идеально предсказывает стоимость каждой точки данных, используемой на этапе оценки обучения. Лучшие модели в наших предыдущих попытках имели оценку R2 от 0,1 до 0,2, так что здесь мы уже явно лучше. Давайте теперь посмотрим на несколько прогнозов этой модели.
Сначала я перепроверил все транзакции со своей улицы. На этот раз прогноз для моей квартиры на ~ 16% ниже цены, которую я заплатил. Но, в отличие от прошлого раза, у каждой квартиры разная оценка, и все эти оценки указаны в правильном порядке. Большинство значений имеют ошибку менее 20% по сравнению с реальной ценой, а худшие оценки имеют ошибку ~ 50%. Очевидно, такая погрешность недопустима при инвестировании в квартиру. Однако по сравнению с предыдущей версией нашей модели, которая давала одинаковую оценку для всех квартир на моей улице, мы добились значительного прогресса.
Итак, теперь, когда у нас, по крайней мере, есть правильный порядок величины, давайте попробуем настроить некоторые значения в нашем входном наборе данных, чтобы увидеть, реагирует ли модель предсказуемо. Для этого я взял точку данных моей собственной транзакции и создал новые точки данных, каждый раз изменяя одну из характеристик исходной точки данных:
- поверхность, чтобы уменьшить это
- координаты (название улицы, код улицы, географические координаты и т. д.), чтобы поместить его в более дешевый район
- дата транзакции до 2015 года (за 3 года до реальной даты)
С каждой из этих модификаций мы ожидаем, что новые оценки будут ниже первоначальной (рынок недвижимости в Париже находится в постоянной инфляции). Посмотрим на результаты:
По крайней мере, качественно модель ведет себя должным образом.
Как мы могли добиться большего?
На этом этапе мы использовали здравый смысл, чтобы значительно улучшить наши предыдущие результаты и построить модель, которая дает прогнозы в хорошем порядке и ведет себя так, как мы ожидаем, при настройке характеристик точек данных. Однако оставшаяся погрешность делает его непригодным для реального применения. Но почему и что мы могли сделать, чтобы продолжать улучшать нашу модель? На то есть несколько причин:
Сложность данных: я немного противоречу себе. Хотя сложные данные сложнее переварить для алгоритма машинного обучения, необходимо сохранить эту сложность, если она отражает сложность в конечном результате. В этом случае мы могли не только чрезмерно упростить данные, но и сами исходные данные могли не иметь большого количества соответствующей информации.
Мы обучили наш алгоритм общему расположению и поверхности, которые, по общему признанию, являются наиболее важными критериями, но в нашем наборе данных отсутствует очень важная информация, такая как полы, экспозиция, годы строительства, диагностика изоляции, состояние, доступность, вид, общее состояние квартир и т. Д.
Существуют частные наборы данных, созданные нотариальными конторами, которые более полны, чем наш открытый набор данных, но хотя они могут иметь такие характеристики, как пол или год постройки, в них, вероятно, не будет более субъективной информации; например, общее состояние или вид.
В наборе данных отсутствует очень важная информация о квартирах.
- Объем данных: даже если бы у нас были очень полные данные, нам понадобилось бы их огромное количество. Чем больше функций мы включаем в наше обучение, тем больше данных нам нужно. И для такой сложной задачи ~ 150 тыс. Транзакций в год, которые мы проводим в Париже, вероятно, недостаточно. Решением может быть создание искусственных точек данных: квартир, которых на самом деле не существует, но которые специалисты-люди все равно смогут оценить.
Но здесь есть три проблемы: во-первых, любая предвзятость экспертов неизбежно передается модели. Во-вторых, нам нужно будет создать огромное количество искусственных, но реалистичных точек данных, а затем потребуется помощь нескольких экспертов-людей, чтобы пометить их. Наконец, вышеупомянутые эксперты будут маркировать эти искусственные данные на основе своего текущего опыта. Им будет очень трудно вспомнить рыночные цены, которые были несколько лет назад. Это означает, что для получения однородного набора данных на протяжении многих лет нам придется создавать эти искусственные данные с течением времени и с той же скоростью, что и настоящие транзакции. - Навыки: наконец, работа в области анализа данных — это работа на полную ставку, которая требует опыта и навыков. Настоящий специалист по данным, вероятно, смог бы достичь лучших результатов, чем те, которые я получил, настроив параметры обучения и выбрав наиболее подходящие алгоритмы.
Более того, даже хорошие специалисты по данным должны разбираться в недвижимости и ценообразовании. Очень сложно создавать продвинутые модели машинного обучения, не разбираясь в теме.
Резюме
В этом сообщении блога мы обсудили, почему наша предыдущая попытка обучить модель предсказывать цены на квартиры в Париже потерпела неудачу. Данные, которые мы использовали, не были достаточно очищены, и мы использовали параметры обучения Dataiku по умолчанию, а не проверяли их целесообразность.
После этого мы исправили наши ошибки, очистили данные и настроили параметры обучения. Это значительно улучшило результат нашей модели, но недостаточно для реалистичного использования. Есть способы улучшить модель, но в доступных наборах данных не хватает некоторой информации, а самих данных может быть недостаточно для построения надежной модели.
К счастью, цель этой серии никогда не заключалась в том, чтобы точно предсказать цены на квартиры в Париже. Если бы это было возможно, не было бы больше агентств недвижимости. Вместо этого он служит иллюстрацией того, как любой может взять необработанные данные, найти проблему, связанную с данными, и обучить модель решать эту проблему.
Однако набор данных, который мы использовали в этом примере, был довольно небольшим: всего несколько гигабайт. Все происходило на одной виртуальной машине, и нам приходилось делать все вручную, с фиксированным набором данных. Что бы я сделал, если бы хотел обрабатывать петабайты данных? Если бы я хотел обрабатывать непрерывную потоковую передачу данных? Если бы я хотел раскрыть свою модель, чтобы внешние приложения могли ее запрашивать?
Это то, что мы собираемся рассмотреть в следующий раз, в последнем сообщении блога этой серии.