Развертывание игровых серверов с Agones на OVH Managed Kubernetes
Одним из ключевых преимуществ использования Kubernetes является огромная экосистема вокруг него. От Rancher к Istio , от Грача до ДЕЛЕНИЯ , от gVisor к KubeDB , экосистема Kubernetes богата, живая и постоянно растет. Мы подходим к тому моменту, когда для большинства потребностей развертывания мы можем сказать, что для этого существует проект с открытым исходным кодом на основе K8s .
Одним из latests дополнений в этой экосистеме является Agones проект с открытым исходным кодом, мультиплеер, посвященный игровой сервер хостинг построен на Kubernetes, разработанный Google в сотрудничестве с Ubisoft . О проекте было объявлено в марте , и он уже наделал много шума…
В OVH Platform Team мы фанаты как онлайн-игр, так и Kubernetes, поэтому мы сказали себе, что нам нужно протестировать Agones. И что может быть лучше для его тестирования, чем развертывание в нашей службе OVH Managed Kubernetes , установка кластера игровых серверов Xonotic и участие в некоторых олдскульных смертельных матчах с коллегами?

И, конечно же, нам нужно было написать об этом, чтобы поделиться опытом…
Agones ( происходящее от греческого слова ag, n, соревнования, проводимые во время публичных фестивалей или, в более общем смысле, «соревнование» или «соревнование в играх») призвано заменить обычные проприетарные решения для развертывания, масштабирования и управления игровыми серверами.
Agones обогащает Kubernetes настраиваемым контроллером и настраиваемым определением ресурса. С их помощью вы можете стандартизировать инструменты и API Kubernetes для создания, масштабирования и управления кластерами игровых серверов.
Что ж, основное внимание Agones уделяется многопользовательским онлайн-играм, таким как FPS и MOBA, динамичным играм, требующим выделенных игровых серверов с малой задержкой, которые синхронизируют состояние игры между игроками и служат источником правды для игровых ситуаций.
Для таких игр требуются относительно недолговечные выделенные игровые серверы, где каждый матч выполняется на экземпляре сервера. Серверы должны иметь состояние (они должны сохранять состояние игры), при этом состояние обычно сохраняется в памяти на время матча.
Задержка — это ключевая проблема, поскольку соревновательные аспекты игр в реальном времени требуют быстрых ответов от сервера. Это означает, что подключение устройства игрока к игровому серверу должно быть максимально прямым, в идеале в обход любого промежуточного сервера, такого как балансировщик нагрузки.
У каждого издателя игр были свои собственные проприетарные решения, но большинство из них следуют аналогичной схеме: со службой подбора игроков, которая группирует игроков в матч, взаимодействует с диспетчером кластера для предоставления выделенного экземпляра игрового сервера и отправки игрокам IP-адрес и порт, чтобы они могли напрямую подключаться к серверу и играть в игру.
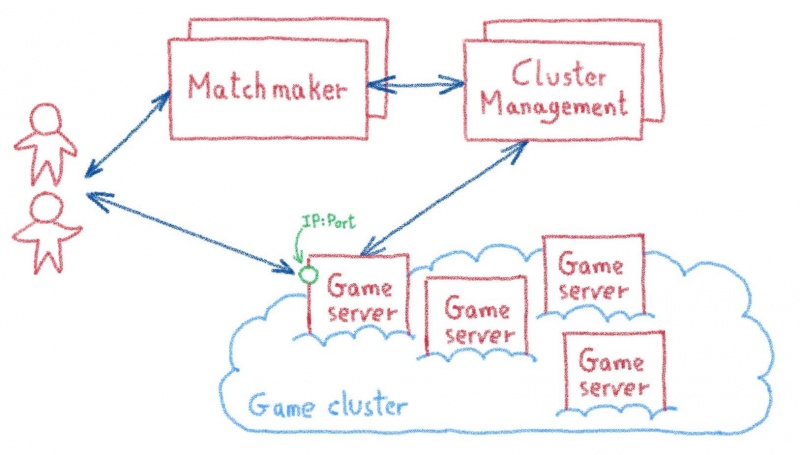
Agones, его настраиваемый контроллер и настраиваемое определение ресурса заменяют сложную инфраструктуру управления кластером на стандартизированные инструменты и API на основе Kubernetes. Сервисы подбора игроков взаимодействуют с этими API для создания новых модулей игровых серверов и передачи их IP-адресов и портов заинтересованным игрокам.
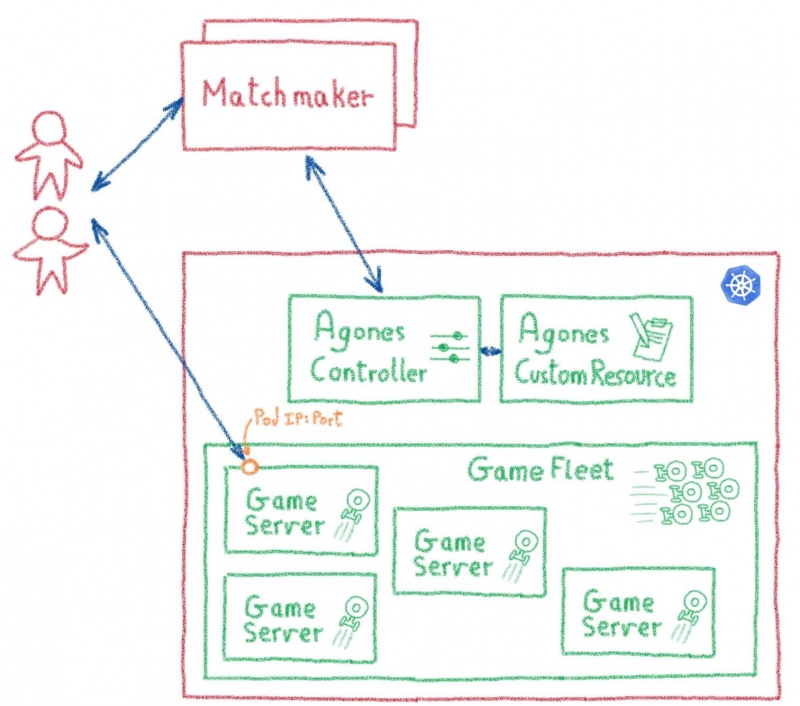
Использование Kubernetes для этих задач также дает приятный дополнительный бонус, например, возможность развернуть полную игровую инфраструктуру в среде разработчика (или даже в мини-кубе ) или легко клонировать ее для развертывания в новом центре обработки данных или облачном регионе, но также предлагая целую платформу для размещения всех дополнительных услуг, необходимых для создания игры: управление учетными записями, списки лидеров, инвентарь…
И, конечно же, простота использования платформ на базе Kubernetes, особенно когда они динамические, разнородные и распределенные, как большинство игровых онлайн-платформ.
Есть несколько способов установить Agones в кластер Kubernetes. Для нашего теста мы выбрали самый простой: установку с помощью Helm.
Первым шагом к установке Agones является настройка учетной записи службы с достаточными разрешениями для создания некоторых специальных типов ресурсов RBAC.
kubectl cre
Теперь у нас есть привязка роли кластера, необходимая для установки.
Теперь продолжим, добавив репозиторий Agones в список репозиториев Helm.
А затем установите стабильную диаграмму Agones:
Только что выполненная установка не подходит для производства, поскольку официальные инструкции по установке рекомендуют запускать Agones и игровые серверы в отдельных выделенных пулах узлов. Но для нужд нашего теста достаточно базовой настройки.
Чтобы убедиться, что Agones работает в нашем кластере Kubernetes, мы можем взглянуть на поды в agones-systemпространстве имен:
Если все в порядке, вы должны увидеть agones-controllerмодуль со статусом " Работает":
Вы также можете увидеть более подробную информацию, используя:
Посмотрев на agones-controllerописание, вы должны увидеть что-то вроде:
Где все Conditionsдолжно иметь статус True.
Мир Agones Hello довольно скучный, простой эхо-сервер UDP, поэтому мы решили пропустить его и перейти непосредственно к чему-то более интересному: игровому серверу Xonotic.
Xonotic — это многопользовательский шутер от первого лица с открытым исходным кодом, и довольно хороший, с множеством интересных игровых режимов, карт, оружия и параметров настройки.
Развернуть игровой сервер Xonotic поверх Agones довольно просто:
Развертывание игрового сервера может занять некоторое время, поэтому нам нужно дождаться его статуса, Readyпрежде чем его использовать. Мы можем получить статус с помощью:
Мы ждем, пока выборка не выдаст Readyстатус на нашем игровом сервере:
Когда игровой сервер готов, мы также получаем адрес и порт, который мы должны использовать для подключения к нашей игре deathmatch (в моем примере 51.83.xxx.yyy:7094).
Итак, теперь, когда у нас есть сервер, давайте протестируем его!
Мы загрузили клиент Xonotic для наших компьютеров (он работает в Windows, Linux и MacOS, поэтому нет оправдания) и запустили его:
Затем заходим в меню многопользовательской игры и вводим адрес и порт нашего игрового сервера:
И мы готовы играть!
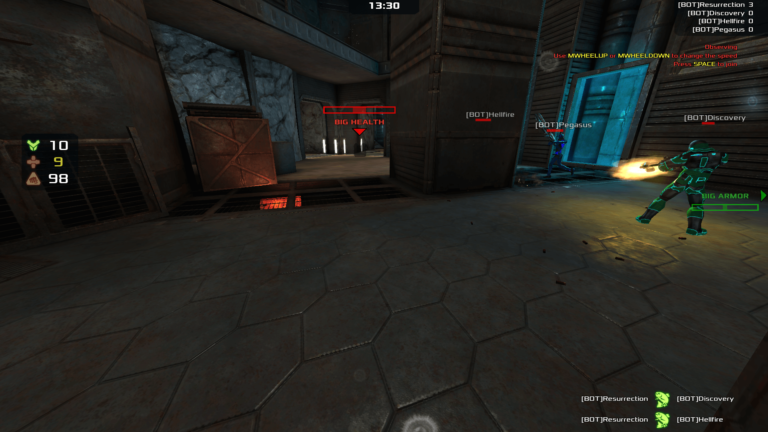
На стороне сервера мы можем следить за тем, как идут дела на нашем игровом сервере, используя kubectl logs. Начнем с поиска модуля, в котором запущена игра:
Мы видим, что наш игровой сервер работает в модуле под названием xonotic:
Затем мы можем использовать kubectl logsего. В модуле есть два контейнера, основной xonoticи вспомогательный Agones, поэтому мы должны указать, что нам нужны журналы xonoticконтейнера:
Следующий шаг в основном доставляет удовольствие: попросить коллег подключиться к серверу и провести настоящий смертельный бой, как в Quake 2 раза.
У нас есть рабочий игровой сервер, но мы едва раскрыли возможности Agones: развертывание флота (набор теплых игровых серверов, которые доступны для распределения), тестирование FleetAutoscaler (для автоматического увеличения и уменьшения флота в ответ на спроса), создавая некую фиктивную службу распределения. В следующих статьях блога мы углубимся в это и исследуем эти возможности.
И в более широком контексте мы продолжим наше исследовательское путешествие на Agones. Проект еще очень молодой, на ранней стадии альфа, но он показывает некоторые впечатляющие перспективы.
Одним из latests дополнений в этой экосистеме является Agones проект с открытым исходным кодом, мультиплеер, посвященный игровой сервер хостинг построен на Kubernetes, разработанный Google в сотрудничестве с Ubisoft . О проекте было объявлено в марте , и он уже наделал много шума…
В OVH Platform Team мы фанаты как онлайн-игр, так и Kubernetes, поэтому мы сказали себе, что нам нужно протестировать Agones. И что может быть лучше для его тестирования, чем развертывание в нашей службе OVH Managed Kubernetes , установка кластера игровых серверов Xonotic и участие в некоторых олдскульных смертельных матчах с коллегами?
И, конечно же, нам нужно было написать об этом, чтобы поделиться опытом…
Почему Агоны?
Agones ( происходящее от греческого слова ag, n, соревнования, проводимые во время публичных фестивалей или, в более общем смысле, «соревнование» или «соревнование в играх») призвано заменить обычные проприетарные решения для развертывания, масштабирования и управления игровыми серверами.
Agones обогащает Kubernetes настраиваемым контроллером и настраиваемым определением ресурса. С их помощью вы можете стандартизировать инструменты и API Kubernetes для создания, масштабирования и управления кластерами игровых серверов.
Постой, о каких игровых серверах ты говоришь?
Что ж, основное внимание Agones уделяется многопользовательским онлайн-играм, таким как FPS и MOBA, динамичным играм, требующим выделенных игровых серверов с малой задержкой, которые синхронизируют состояние игры между игроками и служат источником правды для игровых ситуаций.
Для таких игр требуются относительно недолговечные выделенные игровые серверы, где каждый матч выполняется на экземпляре сервера. Серверы должны иметь состояние (они должны сохранять состояние игры), при этом состояние обычно сохраняется в памяти на время матча.
Задержка — это ключевая проблема, поскольку соревновательные аспекты игр в реальном времени требуют быстрых ответов от сервера. Это означает, что подключение устройства игрока к игровому серверу должно быть максимально прямым, в идеале в обход любого промежуточного сервера, такого как балансировщик нагрузки.
А как подключить игроков к нужному серверу?
У каждого издателя игр были свои собственные проприетарные решения, но большинство из них следуют аналогичной схеме: со службой подбора игроков, которая группирует игроков в матч, взаимодействует с диспетчером кластера для предоставления выделенного экземпляра игрового сервера и отправки игрокам IP-адрес и порт, чтобы они могли напрямую подключаться к серверу и играть в игру.
Agones, его настраиваемый контроллер и настраиваемое определение ресурса заменяют сложную инфраструктуру управления кластером на стандартизированные инструменты и API на основе Kubernetes. Сервисы подбора игроков взаимодействуют с этими API для создания новых модулей игровых серверов и передачи их IP-адресов и портов заинтересованным игрокам.
Вишенка на торте
Использование Kubernetes для этих задач также дает приятный дополнительный бонус, например, возможность развернуть полную игровую инфраструктуру в среде разработчика (или даже в мини-кубе ) или легко клонировать ее для развертывания в новом центре обработки данных или облачном регионе, но также предлагая целую платформу для размещения всех дополнительных услуг, необходимых для создания игры: управление учетными записями, списки лидеров, инвентарь…
И, конечно же, простота использования платформ на базе Kubernetes, особенно когда они динамические, разнородные и распределенные, как большинство игровых онлайн-платформ.
Развертывание Agones в управляемом OVH Kubernetes
Есть несколько способов установить Agones в кластер Kubernetes. Для нашего теста мы выбрали самый простой: установку с помощью Helm.
Включение создания ресурсов RBAC
Первым шагом к установке Agones является настройка учетной записи службы с достаточными разрешениями для создания некоторых специальных типов ресурсов RBAC.
kubectl cre
kubectl create clusterrolebinding cluster-admin-binding \
--clusterrole=cluster-admin --serviceaccount=kube-system:defaultТеперь у нас есть привязка роли кластера, необходимая для установки.
Установка диаграммы Agones
Теперь продолжим, добавив репозиторий Agones в список репозиториев Helm.
helm repo add agones https://agones.dev/chart/stableА затем установите стабильную диаграмму Agones:
helm install --name my-agones --namespace agones-system agones/agonesТолько что выполненная установка не подходит для производства, поскольку официальные инструкции по установке рекомендуют запускать Agones и игровые серверы в отдельных выделенных пулах узлов. Но для нужд нашего теста достаточно базовой настройки.
Подтверждение успешного запуска Agones
Чтобы убедиться, что Agones работает в нашем кластере Kubernetes, мы можем взглянуть на поды в agones-systemпространстве имен:
kubectl get --namespace agones-system podsЕсли все в порядке, вы должны увидеть agones-controllerмодуль со статусом " Работает":
$ kubectl get --namespace agones-system pods
NAME READY STATUS RESTARTS AGE
agones-controller-5f766fc567-xf4vv 1/1 Running 0 5d15h
agones-ping-889c5954d-6kfj4 1/1 Running 0 5d15h
agones-ping-889c5954d-mtp4g 1/1 Running 0 5d15hВы также можете увидеть более подробную информацию, используя:
kubectl describe --namespace agones-system podsПосмотрев на agones-controllerописание, вы должны увидеть что-то вроде:
$ kubectl describe --namespace agones-system pods
Name: agones-controller-5f766fc567-xf4vv
Namespace: agones-system
[...]
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True Где все Conditionsдолжно иметь статус True.
Развертывание игрового сервера
Мир Agones Hello довольно скучный, простой эхо-сервер UDP, поэтому мы решили пропустить его и перейти непосредственно к чему-то более интересному: игровому серверу Xonotic.
Xonotic — это многопользовательский шутер от первого лица с открытым исходным кодом, и довольно хороший, с множеством интересных игровых режимов, карт, оружия и параметров настройки.
Развернуть игровой сервер Xonotic поверх Agones довольно просто:
kubectl create -f https://raw.githubusercontent.com/GoogleCloudPlatform/agones/release-0.9.0/examples/xonotic/gameserver.yamlРазвертывание игрового сервера может занять некоторое время, поэтому нам нужно дождаться его статуса, Readyпрежде чем его использовать. Мы можем получить статус с помощью:
kubectl get gameserverМы ждем, пока выборка не выдаст Readyстатус на нашем игровом сервере:
$ kubectl get gameserver
NAME STATE ADDRESS PORT NODE AGE
xonotic Ready 51.83.xxx.yyy 7094 node-zzz 5dКогда игровой сервер готов, мы также получаем адрес и порт, который мы должны использовать для подключения к нашей игре deathmatch (в моем примере 51.83.xxx.yyy:7094).
Время фрага
Итак, теперь, когда у нас есть сервер, давайте протестируем его!
Мы загрузили клиент Xonotic для наших компьютеров (он работает в Windows, Linux и MacOS, поэтому нет оправдания) и запустили его:
Затем заходим в меню многопользовательской игры и вводим адрес и порт нашего игрового сервера:
И мы готовы играть!
А на стороне сервера?
На стороне сервера мы можем следить за тем, как идут дела на нашем игровом сервере, используя kubectl logs. Начнем с поиска модуля, в котором запущена игра:
kubectl get podsМы видим, что наш игровой сервер работает в модуле под названием xonotic:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
xonotic 2/2 Running 0 5d15hЗатем мы можем использовать kubectl logsего. В модуле есть два контейнера, основной xonoticи вспомогательный Agones, поэтому мы должны указать, что нам нужны журналы xonoticконтейнера:
$ kubectl logs xonotic
Error from server (BadRequest): a container name must be specified for pod xonotic, choose one of: [xonotic agones-gameserver-sidecar]
$ kubectl logs xonotic xonotic
>>> Connecting to Agones with the SDK
>>> Starting health checking
>>> Starting wrapper for Xonotic!
>>> Path to Xonotic server script: /home/xonotic/Xonotic/server_linux.sh
Game is Xonotic using base gamedir data
gamename for server filtering: Xonotic
Xonotic Linux 22:03:50 Mar 31 2017 - release
Current nice level is below the soft limit - cannot use niceness
Skeletal animation uses SSE code path
execing quake.rc
[...]
Authenticated connection to 109.190.xxx.yyy:42475 has been established: client is v6xt9/GlzxBH+xViJCiSf4E/SCn3Kx47aY3EJ+HOmZo=@Xon//Ks, I am /EpGZ8F@~Xon//Ks
LostInBrittany is connecting...
url_fclose: failure in crypto_uri_postbuf
Receiving player stats failed: -1
LostInBrittany connected
LostInBrittany connected
LostInBrittany is now spectating
[BOT]Eureka connected
[BOT]Hellfire connected
[BOT]Lion connected
[BOT]Scorcher connected
unconnected changed name to [BOT]Eureka
unconnected changed name to [BOT]Hellfire
unconnected changed name to [BOT]Lion
unconnected changed name to [BOT]Scorcher
[BOT]Scorcher picked up Strength
[BOT]Scorcher drew first blood!
[BOT]Hellfire was gunned down by [BOT]Scorcher's Shotgun
[BOT]Scorcher slapped [BOT]Lion around a bit with a large Shotgun
[BOT]Scorcher was gunned down by [BOT]Eureka's Shotgun, ending their 2 frag spree
[BOT]Scorcher slapped [BOT]Lion around a bit with a large Shotgun
[BOT]Scorcher was shot to death by [BOT]Eureka's Blaster
[BOT]Hellfire slapped [BOT]Eureka around a bit with a large Shotgun, ending their 2 frag spree
[BOT]Eureka slapped [BOT]Scorcher around a bit with a large Shotgun
[BOT]Eureka was gunned down by [BOT]Hellfire's Shotgun
[BOT]Hellfire was shot to death by [BOT]Lion's Blaster, ending their 2 frag spree
[BOT]Scorcher was cooked by [BOT]Lion
[BOT]Eureka turned into hot slag
[...]Добавить друзей…
Следующий шаг в основном доставляет удовольствие: попросить коллег подключиться к серверу и провести настоящий смертельный бой, как в Quake 2 раза.
И сейчас?
У нас есть рабочий игровой сервер, но мы едва раскрыли возможности Agones: развертывание флота (набор теплых игровых серверов, которые доступны для распределения), тестирование FleetAutoscaler (для автоматического увеличения и уменьшения флота в ответ на спроса), создавая некую фиктивную службу распределения. В следующих статьях блога мы углубимся в это и исследуем эти возможности.
И в более широком контексте мы продолжим наше исследовательское путешествие на Agones. Проект еще очень молодой, на ранней стадии альфа, но он показывает некоторые впечатляющие перспективы.

























{kind=link}