Развертывание платформы FaaS на OVH Managed Kubernetes с использованием OpenFaaS
Несколько недель назад я участвовал в митапе, посвященном Kubernetes, когда один из участников сделал замечание, которое глубоко меня нашло…
Это был не первый раз, когда я задавал этот вопрос…
Поскольку я, прежде всего, веб-разработчик, я определенно понимаю. Kubernetes — замечательный продукт — вы можете устанавливать сложные веб-архитектуры одним щелчком мыши — но как насчет базы данных + модель некоторых функций?
Что ж, вы также можете сделать это с Kubernetes!
В этом прелесть богатой экосистемы Kubernetes: вы можете найти проекты для множества различных вариантов использования, от игровых серверов с Agones до платформ FaaS…
Сказать: «Вы можете сделать это с Kubernetes!» почти новый " Для этого есть приложение!", но это не помогает многим людям, которые ищут решения. Поскольку этот вопрос возникал несколько раз, мы решили подготовить небольшой учебник о том, как развернуть и использовать платформу FaaS на OVH Managed Kubernetes.
Мы начали с тестирования нескольких платформ FaaS на нашем Kubernetes. Нашей целью было найти следующее решение:
Мы протестировали множество платформ, таких как Kubeless, OpenWhisk, OpenFaaS и Fission, и я должен сказать, что все они работали достаточно хорошо. В конце концов, лучший результат с точки зрения наших целей получил OpenFaaS, поэтому мы решили использовать его в качестве справочника для этого сообщения в блоге.

OpenFaaS — это платформа с открытым исходным кодом для создания бессерверных функций с помощью Docker и Kubernetes. Проект уже зрелый, популярный и активный, с более чем 14 тысячами звезд на GitHub, сотнями участников и множеством пользователей (как корпоративных, так и частных).
OpenFaaS очень просто развернуть с помощью диаграммы Helm (включая оператор для CRD, т kubectl get functions. Е. ). Он имеет как интерфейс командной строки, так и пользовательский интерфейс, эффективно управляет автоматическим масштабированием, а его документация действительно исчерпывающая (с каналом Slack для ее обсуждения в качестве приятного бонуса!).
Технически OpenFaaS состоит из нескольких функциональных блоков:
Функции можно писать на многих языках (хотя я в основном использовал для тестирования JavaScript, Go и Python), используя удобные шаблоны или простой файл Dockerfile.
Есть несколько способов установить OpenFaaS в кластере Kubernetes. В этом посте мы рассмотрим самый простой: установка с помощью Helm.
Официальная диаграмма Helm для OpenFaas доступна в репозитории faas-netes.
Диаграмма OpenFaaS Helm недоступна в стандартном stableрепозитории Helm, поэтому вам нужно добавить их репозиторий в вашу установку Helm:
Руководства OpenFaaS рекомендуют создать два пространства имен: одно для основных служб OpenFaaS, а другое — для функций:
Платформа FaaS, открытая для Интернета, кажется плохой идеей. Вот почему мы генерируем секреты, чтобы включить аутентификацию на шлюзе:
Helm диаграмма может быть развернута в трех режимах: LoadBalancer, NodePortи Ingress. Для наших целей самый простой способ — просто использовать наш внешний балансировщик нагрузки, поэтому мы развернем его LoadBalancerс --set serviceType=LoadBalancer опцией
Разверните диаграмму Helm следующим образом:
Как предлагается в сообщении об установке, вы можете проверить, что OpenFaaS запущен, запустив:
Если он работает, вы должны увидеть список доступных deploymentобъектов OpenFaaS:
Самый простой способ взаимодействия с вашей новой платформой OpenFaaS — это установка faas-cliклиента командной строки для OpenFaaS на Linux или Mac (или в терминале WSL linux в Windows):
Теперь вы можете использовать интерфейс командной строки для входа в шлюз. Для интерфейса командной строки потребуется общедоступный URL-адрес OpenFaaS LoadBalancer, который вы можете получить через kubectl:
Экспортируйте URL-адрес в OPENFAAS_URL переменную:
И подключаемся к шлюзу:
Теперь вы подключены к шлюзу и можете отправлять команды на платформу OpenFaaS.
По умолчанию на вашей платформе OpenFaaS не установлено никаких функций, что вы можете проверить с помощью faas-cli listкоманды.
В моем собственном развертывании (URL-адреса и IP-адреса изменены для этого примера) предыдущие операции дали:
Вы можете легко развернуть функции на вашей платформе OpenFaaS с помощью интерфейса командной строки, с помощью этой команды: faas-cli up.
Давайте попробуем несколько примеров функций из репозитория OpenFaaS:
Выполнение faas-cli listкоманды сейчас покажет развернутые функции:
В качестве примера вызовем wordcount(функцию, которая принимает синтаксис команды unix wcи дает нам количество строк, слов и символов входных данных):
Вы можете использовать faas-cli describeкоманду, чтобы получить общедоступный URL-адрес вашей функции, а затем вызвать его напрямую из вашей любимой HTTP-библиотеки (или старой доброй curl):
Самая привлекательная часть платформы FaaS — это возможность развертывать свои собственные функции.
В OpenFaaS вы можете написать эти функции на многих языках, а не только на обычных подозреваемых (JavaScript, Python, Go и т. Д.). Это связано с тем, что в OpenFaaS вы можете развернуть практически любой контейнер как функцию, хотя это означает, что вам нужно упаковать свои функции как контейнеры, чтобы развернуть их.
Это также означает, что для создания ваших собственных функций на вашей рабочей станции должен быть установлен Docker, и вам нужно будет поместить образы в реестр Docker (официальный или частный).
Если вам нужен частный реестр, вы можете установить его в кластере OVH Managed Kubernetes. В этом руководстве мы решили развернуть наш образ в официальном реестре Docker.
В нашем первом примере мы собираемся создать и развернуть функцию приветственного слова в JavaScript, используя NodeJS. Начнем с создания и формирования папки функции:
Интерфейс командной строки загрузит шаблон функции JS из репозитория OpenFaaS, сгенерирует файл описания функции ( hello-js.ymlв данном случае) и папку для исходного кода функции ( hello-js). Для NodeJS вы найдете в этой папке package.json(например, для объявления возможных зависимостей вашей функции) и handler.js(основной код функции).
Отредактируйте, hello-js.yml чтобы задать имя изображения, которое вы хотите загрузить в реестр Docker:
Функция, описанная в handler.jsфайле, действительно проста. Он экспортирует функцию с двумя параметрами: a, contextкуда вы получите данные запроса, и a, callbackкоторый вы вызовете в конце своей функции, и куда вы передадите данные ответа.
Давайте отредактируем его, чтобы отправить обратно наше приветственное сообщение:
Теперь вы можете создать образ Docker и отправить его в общедоступный реестр Docker:
Поздравляю! Вы только что написали и развернули свою первую функцию OpenFaaS.
Вы можете протестировать портал пользовательского интерфейса, указав в браузере URL-адрес шлюза OpenFaaS (тот, который вы указали для $OPENFAAS_URLпеременной) и при появлении запроса введите admin пользователя и пароль, который вы установили для $PASSWORD переменной.
Итак, теперь у вас есть рабочая платформа OpenFaaS в кластере OVH Managed Kubernetes.
Чтобы узнать больше об OpenFaaS и о том, как получить от него максимальную отдачу, обратитесь к официальной документации OpenFaaS. Вы также можете следить за семинарами по OpenFaaS, чтобы получить больше практических советов и советов.
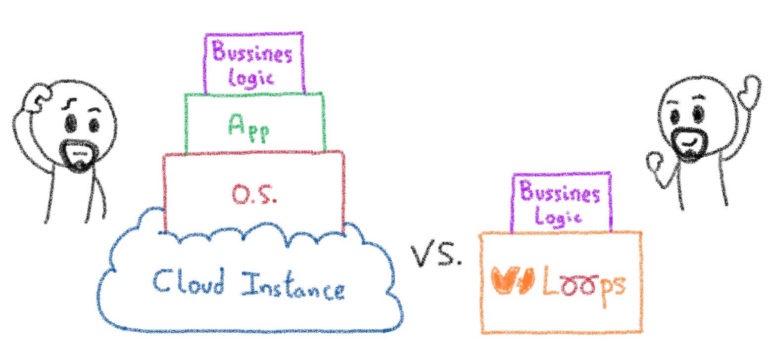
Привет, Горацио, эта штука с Kubernetes довольно крутая, но я бы хотел увидеть платформу «Функции как услуга». Большинство моих приложений можно легко сделать с помощью базы данных и нескольких бессерверных функций!
Это был не первый раз, когда я задавал этот вопрос…
Поскольку я, прежде всего, веб-разработчик, я определенно понимаю. Kubernetes — замечательный продукт — вы можете устанавливать сложные веб-архитектуры одним щелчком мыши — но как насчет базы данных + модель некоторых функций?
Что ж, вы также можете сделать это с Kubernetes!
В этом прелесть богатой экосистемы Kubernetes: вы можете найти проекты для множества различных вариантов использования, от игровых серверов с Agones до платформ FaaS…
Для этого есть таблица Helm!
Сказать: «Вы можете сделать это с Kubernetes!» почти новый " Для этого есть приложение!", но это не помогает многим людям, которые ищут решения. Поскольку этот вопрос возникал несколько раз, мы решили подготовить небольшой учебник о том, как развернуть и использовать платформу FaaS на OVH Managed Kubernetes.
Мы начали с тестирования нескольких платформ FaaS на нашем Kubernetes. Нашей целью было найти следующее решение:
- Простота развертывания (в идеале с простой диаграммой Helm)
- Управляется как с помощью пользовательского интерфейса, так и с помощью интерфейса командной строки, поскольку у разных клиентов разные потребности
- Автоматическое масштабирование как в смысле увеличения, так и уменьшения
- Поддерживается исчерпывающей документацией
Мы протестировали множество платформ, таких как Kubeless, OpenWhisk, OpenFaaS и Fission, и я должен сказать, что все они работали достаточно хорошо. В конце концов, лучший результат с точки зрения наших целей получил OpenFaaS, поэтому мы решили использовать его в качестве справочника для этого сообщения в блоге.
OpenFaaS — платформа FaaS для Kubernetes
OpenFaaS — это платформа с открытым исходным кодом для создания бессерверных функций с помощью Docker и Kubernetes. Проект уже зрелый, популярный и активный, с более чем 14 тысячами звезд на GitHub, сотнями участников и множеством пользователей (как корпоративных, так и частных).
OpenFaaS очень просто развернуть с помощью диаграммы Helm (включая оператор для CRD, т kubectl get functions. Е. ). Он имеет как интерфейс командной строки, так и пользовательский интерфейс, эффективно управляет автоматическим масштабированием, а его документация действительно исчерпывающая (с каналом Slack для ее обсуждения в качестве приятного бонуса!).
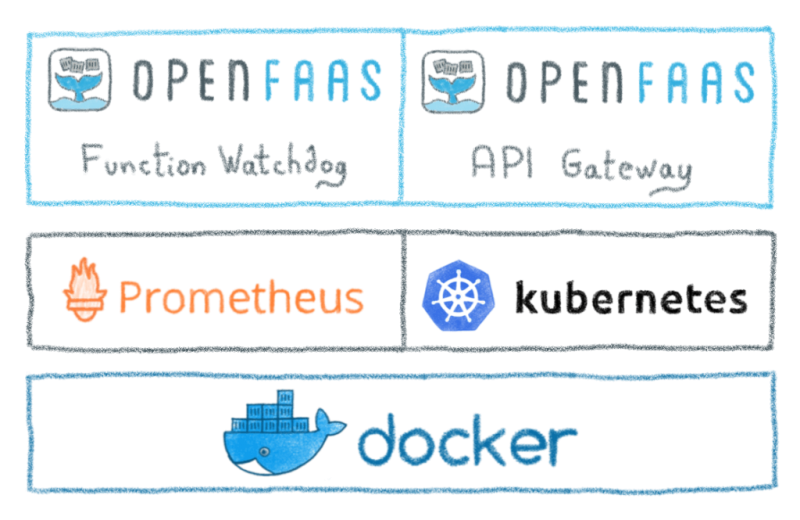
Технически OpenFaaS состоит из нескольких функциональных блоков:
- Функция Watchdog. Крошечный HTTP-сервер golang, который преобразует любой образ Docker в бессерверную функцию
- API шлюз , который обеспечивает внешний маршрут в функции и собирает метрику
- UI портал , который создает и вызывает функцию
- Интерфейс командной строки (по сути, клиент REST для шлюза API ), который может развернуть любой контейнер как функцию
Функции можно писать на многих языках (хотя я в основном использовал для тестирования JavaScript, Go и Python), используя удобные шаблоны или простой файл Dockerfile.
Развертывание OpenFaaS на управляемом OVH Kubernetes
Есть несколько способов установить OpenFaaS в кластере Kubernetes. В этом посте мы рассмотрим самый простой: установка с помощью Helm.
Если вам нужна информация о том, как установить и использовать Helm в кластере OVH Managed Kubernetes, вы можете следовать нашему руководству .
Официальная диаграмма Helm для OpenFaas доступна в репозитории faas-netes.
Добавление диаграммы OpenFaaS Helm
Диаграмма OpenFaaS Helm недоступна в стандартном stableрепозитории Helm, поэтому вам нужно добавить их репозиторий в вашу установку Helm:
helm repo add openfaas https://openfaas.github.io/faas-netes/
helm repo updateСоздание пространств имен
Руководства OpenFaaS рекомендуют создать два пространства имен: одно для основных служб OpenFaaS, а другое — для функций:
kubectl apply -f https://raw.githubusercontent.com/openfaas/faas-netes/master/namespaces.ymlСоздание секретов
Платформа FaaS, открытая для Интернета, кажется плохой идеей. Вот почему мы генерируем секреты, чтобы включить аутентификацию на шлюзе:
# generate a random password
PASSWORD=$(head -c 12 /dev/urandom | shasum| cut -d' ' -f1)
kubectl -n openfaas create secret generic basic-auth \
--from-literal=basic-auth-user=admin \
--from-literal=basic-auth-password="$PASSWORD"Примечание: этот пароль понадобится вам позже в руководстве (например, для доступа к порталу пользовательского интерфейса). Вы можете просмотреть его в любой момент сеанса терминала с помощью echo $PASSWORD.
Развертывание диаграммы Helm
Helm диаграмма может быть развернута в трех режимах: LoadBalancer, NodePortи Ingress. Для наших целей самый простой способ — просто использовать наш внешний балансировщик нагрузки, поэтому мы развернем его LoadBalancerс --set serviceType=LoadBalancer опцией
Если вы хотите лучше понять разницу между этими тремя режимами, вы можете прочитать нашу статью в блоге «Получение внешнего трафика в Kubernetes — ClusterIp, NodePort, LoadBalancer и Ingress» .
Разверните диаграмму Helm следующим образом:
helm upgrade openfaas --install openfaas/openfaas \
--namespace openfaas \
--set basic_auth=true \
--set functionNamespace=openfaas-fn \
--set serviceType=LoadBalancerКак предлагается в сообщении об установке, вы можете проверить, что OpenFaaS запущен, запустив:
kubectl --namespace=openfaas get deployments -l "release=openfaas, app=openfaas"Если он работает, вы должны увидеть список доступных deploymentобъектов OpenFaaS:
$ kubectl --namespace=openfaas get deployments -l "release=openfaas, app=openfaas"
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
alertmanager 1 1 1 1 33s
faas-idler 1 1 1 1 33s
gateway 1 1 1 1 33s
nats 1 1 1 1 33s
prometheus 1 1 1 1 33s
queue-worker 1 1 1 1 33sУстановите интерфейс командной строки FaaS и войдите в API-шлюз
Самый простой способ взаимодействия с вашей новой платформой OpenFaaS — это установка faas-cliклиента командной строки для OpenFaaS на Linux или Mac (или в терминале WSL linux в Windows):
curl -sL https://cli.openfaas.com | shТеперь вы можете использовать интерфейс командной строки для входа в шлюз. Для интерфейса командной строки потребуется общедоступный URL-адрес OpenFaaS LoadBalancer, который вы можете получить через kubectl:
kubectl get svc -n openfaas gateway-external -o wideЭкспортируйте URL-адрес в OPENFAAS_URL переменную:
export OPENFAAS_URL=[THE_URL_OF_YOUR_LOADBALANCER]:[THE_EXTERNAL_PORT]Примечание. Этот URL-адрес понадобится вам позже в руководстве, например, для доступа к порталу пользовательского интерфейса. Вы можете увидеть это в любой момент в терминальной сессии, выполнив echo $OPENFAAS_URL.
И подключаемся к шлюзу:
echo -n $PASSWORD | ./faas-cli login -g $OPENFAAS_URL -u admin --password-stdinТеперь вы подключены к шлюзу и можете отправлять команды на платформу OpenFaaS.
По умолчанию на вашей платформе OpenFaaS не установлено никаких функций, что вы можете проверить с помощью faas-cli listкоманды.
В моем собственном развертывании (URL-адреса и IP-адреса изменены для этого примера) предыдущие операции дали:
$ kubectl get svc -n openfaas gateway-external -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
gateway-external LoadBalancer 10.3.xxx.yyy xxxrt657xx.lb.c1.gra.k8s.ovh.net 8080:30012/TCP 9m10s app=gateway
$ export OPENFAAS_URL=xxxrt657xx.lb.c1.gra.k8s.ovh.net:8080
$ echo -n $PASSWORD | ./faas-cli login -g $OPENFAAS_URL -u admin --password-stdin
Calling the OpenFaaS server to validate the credentials...
WARNING! Communication is not secure, please consider using HTTPS. Letsencrypt.org offers free SSL/TLS certificates.
credentials saved for admin http://xxxrt657xx.lb.c1.gra.k8s.ovh.net:8080
$ ./faas-cli version
___ _____ ____
/ _ \ _ __ ___ _ __ | ___|_ _ __ _/ ___|
| | | | '_ \ / _ \ '_ \| |_ / _` |/ _` \___ \
| |_| | |_) | __/ | | | _| (_| | (_| |___) |
\___/| .__/ \___|_| |_|_| \__,_|\__,_|____/
|_|
CLI:
commit: b42d0703b6136cac7b0d06fa2b212c468b0cff92
version: 0.8.11
Gateway
uri: http://xxxrt657xx.lb.c1.gra.k8s.ovh.net:8080
version: 0.13.0
sha: fa93655d90d1518b04e7cfca7d7548d7d133a34e
commit: Update test for metrics server
Provider
name: faas-netes
orchestration: kubernetes
version: 0.7.5
sha: 4d3671bae8993cf3fde2da9845818a668a009617
$ ./faas-cli list Function Invocations Replicas Развертывание и вызов функций
Вы можете легко развернуть функции на вашей платформе OpenFaaS с помощью интерфейса командной строки, с помощью этой команды: faas-cli up.
Давайте попробуем несколько примеров функций из репозитория OpenFaaS:
./faas-cli deploy -f https://raw.githubusercontent.com/openfaas/faas/master/stack.ymlВыполнение faas-cli listкоманды сейчас покажет развернутые функции:
$ ./faas-cli list
Function Invocations Replicas
base64 0 1
echoit 0 1
hubstats 0 1
markdown 0 1
nodeinfo 0 1
wordcount 0 1 В качестве примера вызовем wordcount(функцию, которая принимает синтаксис команды unix wcи дает нам количество строк, слов и символов входных данных):
echo 'I love when a plan comes together' | ./faas-cli invoke wordcount$ echo 'I love when a plan comes together' | ./faas-cli invoke wordcount
1 7 34Вызов функции без CLI
Вы можете использовать faas-cli describeкоманду, чтобы получить общедоступный URL-адрес вашей функции, а затем вызвать его напрямую из вашей любимой HTTP-библиотеки (или старой доброй curl):
$ ./faas-cli describe wordcount
Name: wordcount
Status: Ready
Replicas: 1
Available replicas: 1
Invocations: 1
Image: functions/alpine:latest
Function process:
URL: http://xxxxx657xx.lb.c1.gra.k8s.ovh.net:8080/function/wordcount
Async URL: http://xxxxx657xx.lb.c1.gra.k8s.ovh.net:8080/async-function/wordcount
Labels: faas_function : wordcount
Annotations: prometheus.io.scrape : false
$ curl -X POST --data-binary "I love when a plan comes together" "http://xxxxx657xx.lb.c1.gra.k8s.ovh.net:8080/function/wordcount"
0 7 33Везде контейнеры ...
Самая привлекательная часть платформы FaaS — это возможность развертывать свои собственные функции.
В OpenFaaS вы можете написать эти функции на многих языках, а не только на обычных подозреваемых (JavaScript, Python, Go и т. Д.). Это связано с тем, что в OpenFaaS вы можете развернуть практически любой контейнер как функцию, хотя это означает, что вам нужно упаковать свои функции как контейнеры, чтобы развернуть их.
Это также означает, что для создания ваших собственных функций на вашей рабочей станции должен быть установлен Docker, и вам нужно будет поместить образы в реестр Docker (официальный или частный).
Если вам нужен частный реестр, вы можете установить его в кластере OVH Managed Kubernetes. В этом руководстве мы решили развернуть наш образ в официальном реестре Docker.
Написание нашей первой функции
В нашем первом примере мы собираемся создать и развернуть функцию приветственного слова в JavaScript, используя NodeJS. Начнем с создания и формирования папки функции:
mkdir hello-js-project
cd hello-js-project
../faas-cli new hello-js --lang nodeИнтерфейс командной строки загрузит шаблон функции JS из репозитория OpenFaaS, сгенерирует файл описания функции ( hello-js.ymlв данном случае) и папку для исходного кода функции ( hello-js). Для NodeJS вы найдете в этой папке package.json(например, для объявления возможных зависимостей вашей функции) и handler.js(основной код функции).
Отредактируйте, hello-js.yml чтобы задать имя изображения, которое вы хотите загрузить в реестр Docker:
version: 1.0
provider:
name: openfaas
gateway: http://6d6rt657vc.lb.c1.gra.k8s.ovh.net:8080
functions:
hello-js:
lang: node
handler: ./hello-js
image: ovhplatform/openfaas-hello-js:latestФункция, описанная в handler.jsфайле, действительно проста. Он экспортирует функцию с двумя параметрами: a, contextкуда вы получите данные запроса, и a, callbackкоторый вы вызовете в конце своей функции, и куда вы передадите данные ответа.
handler.js
"use strict"
module.exports = (context, callback) => {
callback(undefined, {status: "done"});
}Давайте отредактируем его, чтобы отправить обратно наше приветственное сообщение:
"use strict"
module.exports = (context, callback) => {
callback(undefined, {message: 'Hello world'});
}Теперь вы можете создать образ Docker и отправить его в общедоступный реестр Docker:
# Build the image
../faas-cli build -f hello-js.yml
# Login at Docker Registry, needed to push the image
docker login
# Push the image to the registry
../faas-cli push -f hello-js.ymlПоздравляю! Вы только что написали и развернули свою первую функцию OpenFaaS.
Использование портала пользовательского интерфейса OpenFaaS
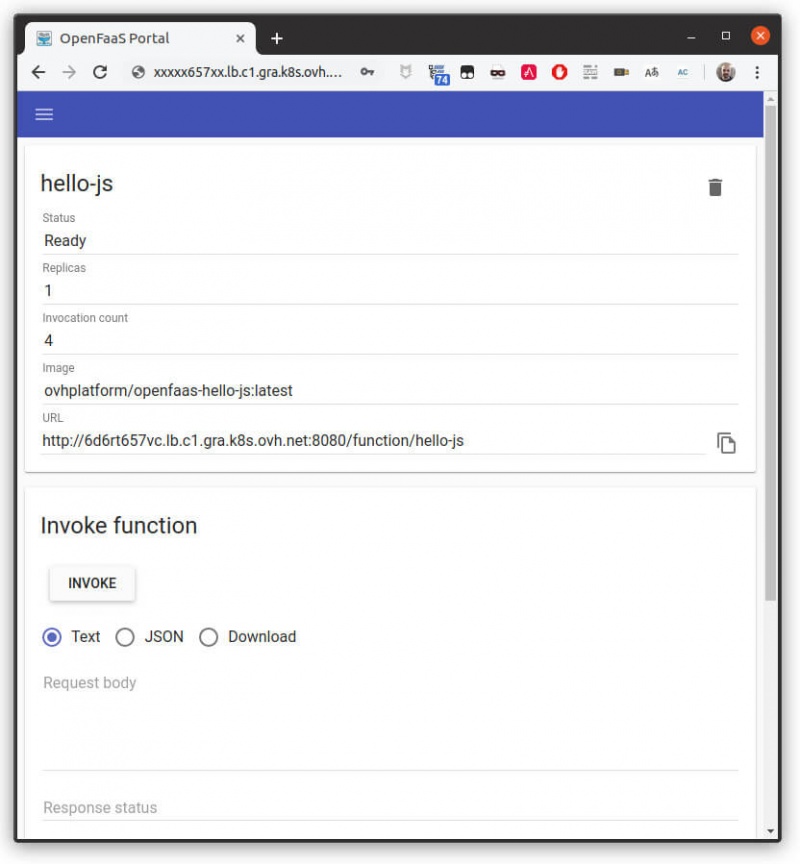
Вы можете протестировать портал пользовательского интерфейса, указав в браузере URL-адрес шлюза OpenFaaS (тот, который вы указали для $OPENFAAS_URLпеременной) и при появлении запроса введите admin пользователя и пароль, который вы установили для $PASSWORD переменной.
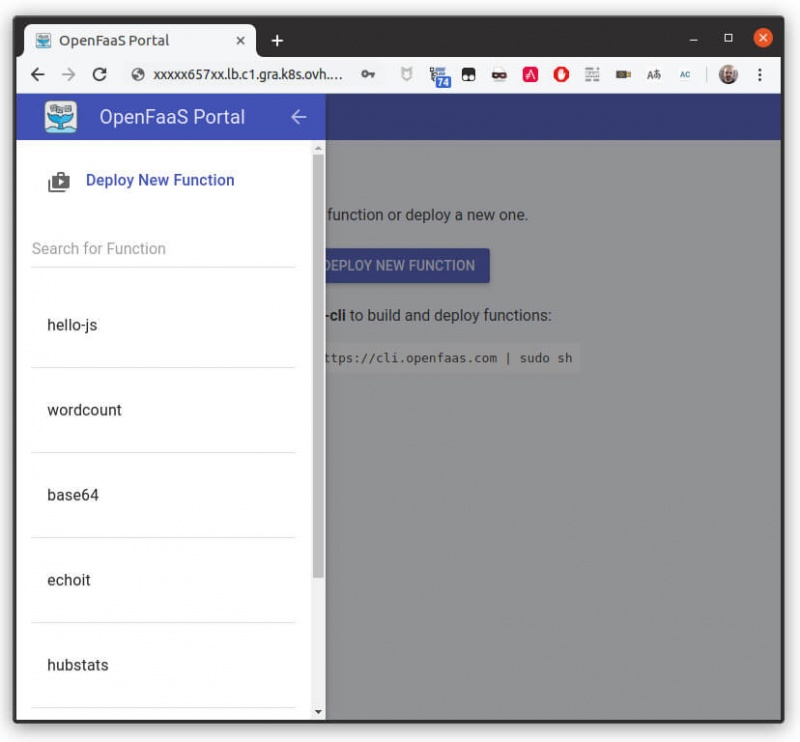
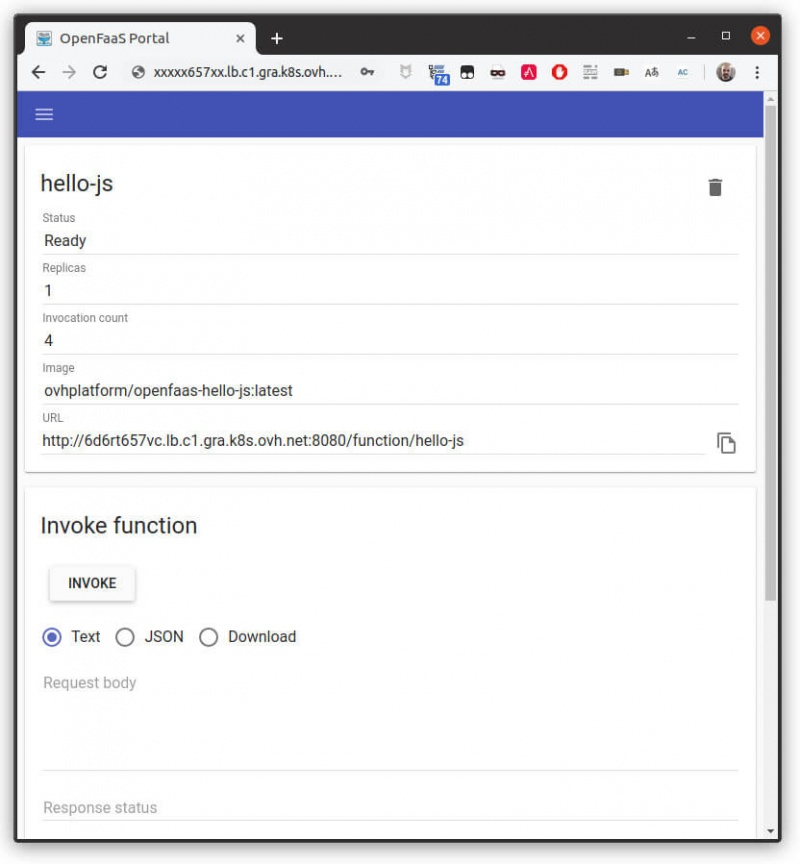
В портале пользовательского интерфейса вы найдете список развернутых функций. Для каждой функции вы можете найти ее описание, вызвать ее и увидеть результат.
Куда мы отправимся отсюда?
Итак, теперь у вас есть рабочая платформа OpenFaaS в кластере OVH Managed Kubernetes.
Чтобы узнать больше об OpenFaaS и о том, как получить от него максимальную отдачу, обратитесь к официальной документации OpenFaaS. Вы также можете следить за семинарами по OpenFaaS, чтобы получить больше практических советов и советов.











{kind=link}