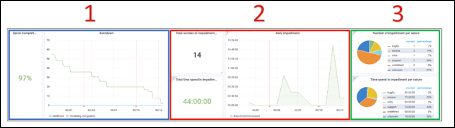
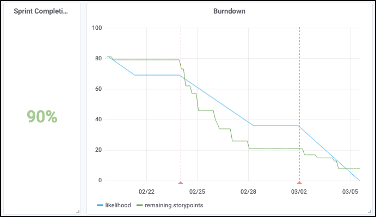
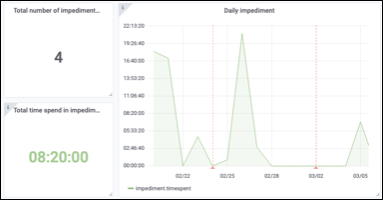
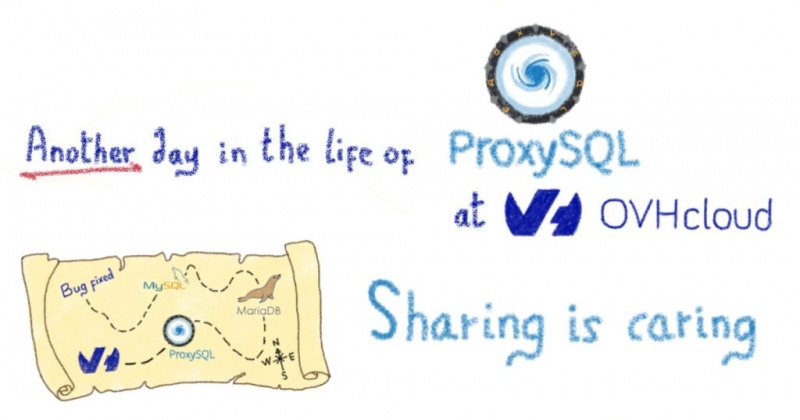
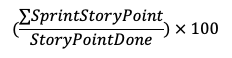Что означает обучение нейронных сетей?
В предыдущем сообщении блога мы обсудили общие концепции глубокого обучения. В этом сообщении блога мы углубимся в основные концепции обучения (глубокой) нейронной сети.
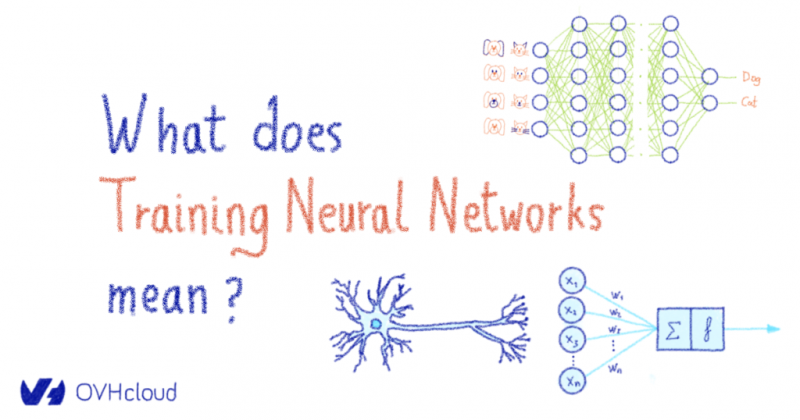
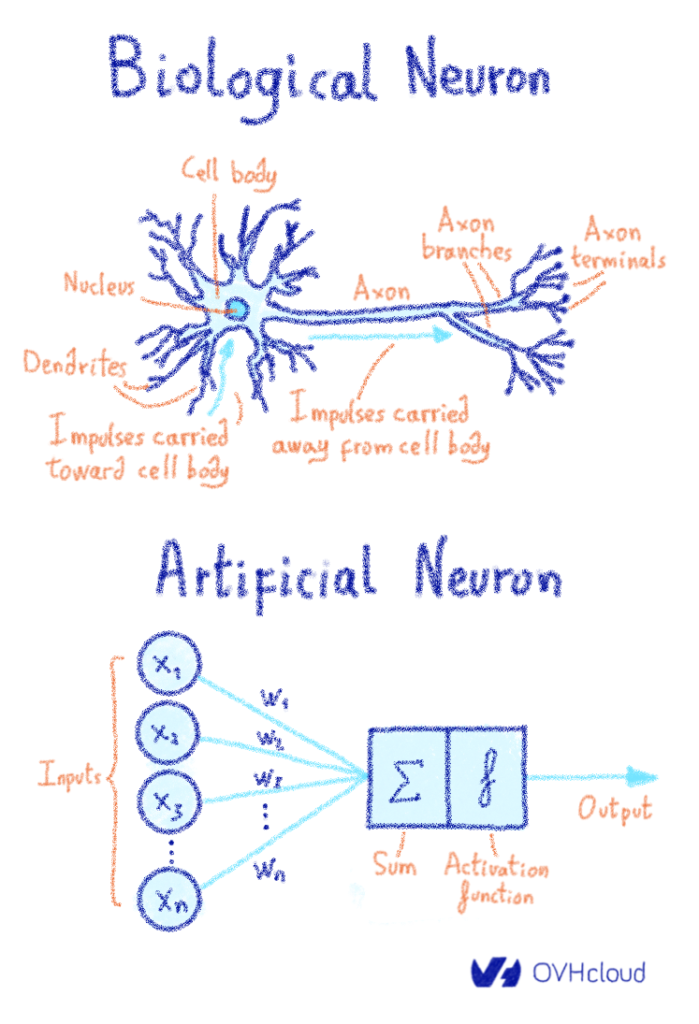
Как вы должны знать, биологический нейрон состоит из нескольких дендритов , ядра и аксона (если бы вы уделяли этому внимание на уроках биологии). Когда стимул посылается в мозг, он передается через синапс, расположенный на конце дендрита.
Когда стимул поступает в мозг, он передается в нейрон через синаптические рецепторы, которые регулируют силу сигнала, отправляемого в ядро . Это сообщение транспортируются по дендритам к ядру , чтобы затем быть обработаны в сочетании с другими сигналами , исходящих от других рецепторов на других дендритах. Т HUS сочетание всех этих сигналов происходит в ядре. После обработки всех этих сигналов ядро будет излучать выходной сигнал через свой единственный аксон . Затем аксон будет передавать этот сигнал нескольким другим нижестоящим нейронам через своиокончания аксонов . Таким образом нейронный анализ проталкивается в последующие слои нейронов. Когда вы сталкиваетесь со сложностью и эффективностью этой системы, вы можете только представить себе тысячелетия биологической эволюции, которые привели нас сюда.
С другой стороны, искусственные нейронные сети построены по принципу биомимикрии. Внешние стимулы (данные), мощность сигнала которых регулируется весами нейронов (помните синапс ?), Циркулируют в нейрон (место, где будет выполняться математический расчет) через дендриты. Результат расчета, называемый выходом, является затем повторно передается (через аксон) нескольким другим нейронам, затем объединяются последующие слои и так далее.
Следовательно, это явная параллель между биологическими нейронами и искусственными нейронными сетями, как показано на рисунке ниже.
Для создания хорошей искусственной нейронной сети (ИНС) вам понадобятся следующие ингредиенты.
Ингредиенты:
Искусственные нейроны (узел обработки), состоящие из:
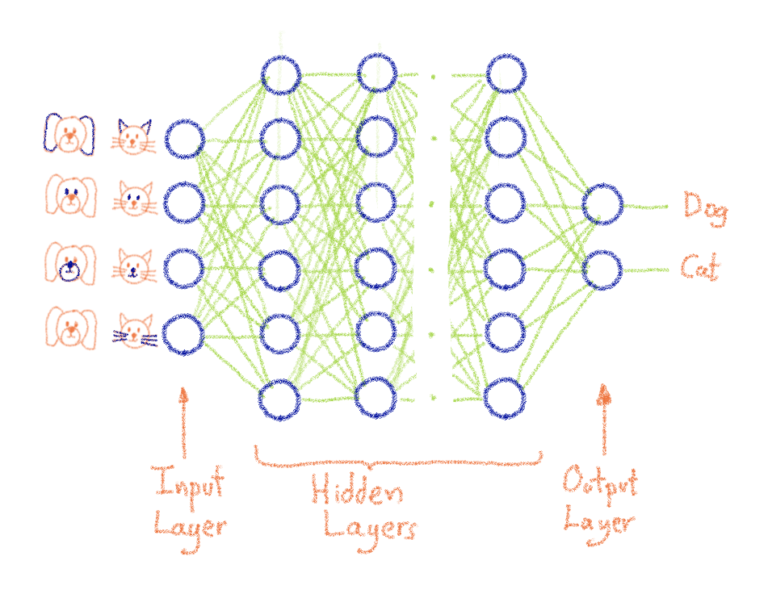
Все нейроны данного слоя генерируют выходные данные , но они не имеют одинаковый вес для следующего слоя нейронов . Это означает, что если нейрон на слое наблюдает заданный образец, это может иметь меньшее значение для общей картины и будет частично или полностью отключен. Это то, что мы называем взвешиванием : большой вес означает, что ввод важен, и, конечно, маленький вес означает, что мы должны его игнорировать . Каждая нейронная связь между нейронами будет иметь соответствующий вес .
И в этом волшебство адаптируемости нейронной сети : веса будут корректироваться во время обучения, чтобы соответствовать поставленным нами целям (признать, что собака — это собака, а кошка — это кошка). Проще говоря: обучение нейронной сети означает нахождение подходящих весов нейронных связей благодаря петле обратной связи, называемой градиентным обратным распространением… и все, ребята.
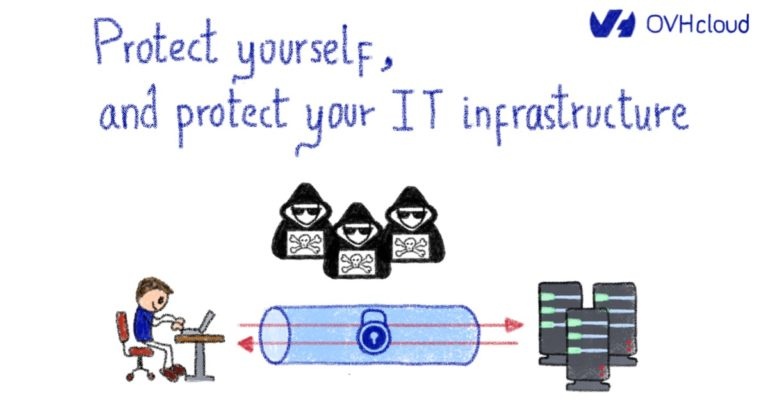
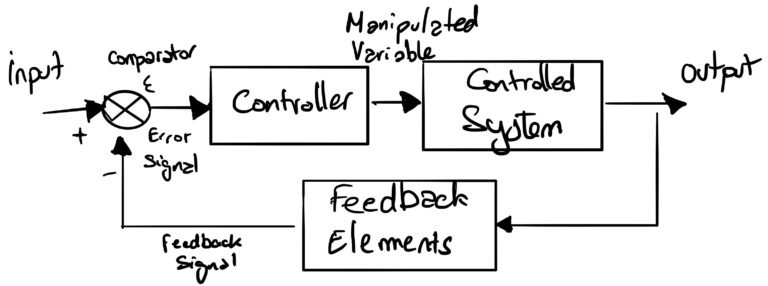
Инженерная область теории управления определяет принципы, аналогичные механизму, используемому для обучения нейронных сетей.
В системах управления уставка — это целевое значение для системы. Заданное значение ( вход ) определена и затем обрабатывается контроллером, который регулирует величину заданного значения в соответствии с контуром обратной связи ( регулируемую переменную ). После того, как заданное значение было регулировать ее затем направляется в контролируемой системе , которая будет производить выходной сигнал. Этот выход контролируется с помощью соответствующей метрики, которая затем сравнивается (компаратор) с исходным входом через контур обратной связи . Это позволяет контроллеру определять уровень регулировки (управляемая переменная) исходной уставки.
Возьмем, к примеру, сопротивление (управляемую систему) в радиаторе. Представьте, что вы решили установить комнатную температуру на 20 ° C (заданное значение) . Радиатор запускается, подает сопротивление с определенной интенсивностью, определяемой контроллером . Затем датчик (термометр) измеряет температуру окружающей среды ( элементы обратной связи ), которая затем сравнивается (компаратор) с заданным значением (желаемой температурой) и регулирует (контроллер) электрическую напряженность, передаваемую на сопротивление. Регулировка новой интенсивности осуществляется через шаг постепенной регулировки.
Обучение нейронной сети аналогично обучению излучателя, поскольку управляемая система является моделью обнаружения кошки или собаки.
Цель больше не в том, чтобы иметь минимальную разницу между заданной температурой и фактической температурой, а в том, чтобы минимизировать ошибку (потерю) между классификацией входящих данных (кошка есть кошка) и классификацией нейронной сети.
Для достижения этого система должна будет посмотреть на вход ( заданное значение ) и вычислить выход ( управляемая система ) на основе параметров, определенных в алгоритме. Этот этап называется прямым проходом.
После расчета выходных данных система повторно распространит ошибку оценки, используя градиентное ретро-распространение ( элементы обратной связи ). Хотя разница температур между заданным значением и показателем термометра была преобразована в электрическую интенсивность для излучателя, здесь система будет регулировать веса различных входов в каждый нейрон с заданным шагом (скорость обучения) .
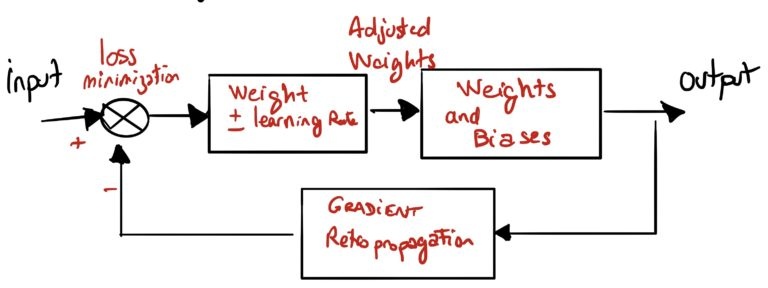
При обучении системы обратное распространение приведет к тому, что система уменьшит количество ошибок, которые она допускает, чтобы наилучшим образом соответствовать поставленным вами целям (обнаружение, что собака есть собака…).
Выбор скорости обучения, с которой вы будете регулировать свои веса (то, что в теории управления называется этапом корректировки ).
Как и в теории управления, система управления может столкнуться с несколькими проблемами, если она неправильно спроектирована:
Вот и все, теперь вы готовы прочитать нашу будущую запись в блоге, посвященную распределенному обучению в контексте глубокого обучения.
Откуда взялось «Neural»?
Как вы должны знать, биологический нейрон состоит из нескольких дендритов , ядра и аксона (если бы вы уделяли этому внимание на уроках биологии). Когда стимул посылается в мозг, он передается через синапс, расположенный на конце дендрита.
Когда стимул поступает в мозг, он передается в нейрон через синаптические рецепторы, которые регулируют силу сигнала, отправляемого в ядро . Это сообщение транспортируются по дендритам к ядру , чтобы затем быть обработаны в сочетании с другими сигналами , исходящих от других рецепторов на других дендритах. Т HUS сочетание всех этих сигналов происходит в ядре. После обработки всех этих сигналов ядро будет излучать выходной сигнал через свой единственный аксон . Затем аксон будет передавать этот сигнал нескольким другим нижестоящим нейронам через своиокончания аксонов . Таким образом нейронный анализ проталкивается в последующие слои нейронов. Когда вы сталкиваетесь со сложностью и эффективностью этой системы, вы можете только представить себе тысячелетия биологической эволюции, которые привели нас сюда.
С другой стороны, искусственные нейронные сети построены по принципу биомимикрии. Внешние стимулы (данные), мощность сигнала которых регулируется весами нейронов (помните синапс ?), Циркулируют в нейрон (место, где будет выполняться математический расчет) через дендриты. Результат расчета, называемый выходом, является затем повторно передается (через аксон) нескольким другим нейронам, затем объединяются последующие слои и так далее.
Следовательно, это явная параллель между биологическими нейронами и искусственными нейронными сетями, как показано на рисунке ниже.
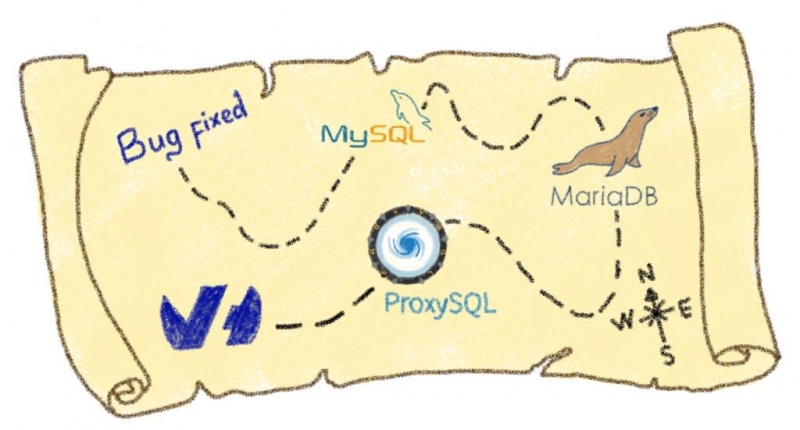
Рецепт искусственной нейронной сети
Для создания хорошей искусственной нейронной сети (ИНС) вам понадобятся следующие ингредиенты.
Ингредиенты:
Искусственные нейроны (узел обработки), состоящие из:
- (много) входных нейронов, соединений (дендритов)
- вычисления блок (ядро) состоит из:
- линейная функция (ах + Ь)
- функция активации (эквивалентно синапс )
- выход (аксон)
Подготовка к получению ИНС для обучения классификации изображений:
- Определитесь с количеством классов вывода (имеется в виду количество классов изображений — например, два для кошки против собаки)
- Нарисуйте столько вычислительных единиц, сколько выходных классов (поздравляю, что вы только что создали выходной слой ИНС)
- Добавьте столько скрытых слоев, сколько необходимо в рамках определенной архитектуры (например, vgg16 или любой другой популярной архитектуры ). Совет. Скрытые слои — это просто набор соседних вычислительных единиц , они не связаны друг с другом.
- Сложите эти скрытые слои на выходной слой с помощью нейронных соединений.
- Важно понимать, что входной уровень — это, по сути, уровень приема данных.
- Добавьте уровень ввода, который адаптирован для приема ваших данных (или вы адаптируете формат данных к заранее определенной архитектуре)
- Соберите множество искусственных нейронов таким образом, чтобы выход (аксон) нейрона на данном слое был (одним) входом другого нейрона на последующем слое . Как следствие, входной слой связан со скрытыми слоями, которые затем связаны с выходным слоем (как показано на рисунке ниже) с помощью нейронных соединений (также показанных на рисунке ниже).
- Приятного аппетита
Что означает обучение искусственной нейронной сети?
Все нейроны данного слоя генерируют выходные данные , но они не имеют одинаковый вес для следующего слоя нейронов . Это означает, что если нейрон на слое наблюдает заданный образец, это может иметь меньшее значение для общей картины и будет частично или полностью отключен. Это то, что мы называем взвешиванием : большой вес означает, что ввод важен, и, конечно, маленький вес означает, что мы должны его игнорировать . Каждая нейронная связь между нейронами будет иметь соответствующий вес .
И в этом волшебство адаптируемости нейронной сети : веса будут корректироваться во время обучения, чтобы соответствовать поставленным нами целям (признать, что собака — это собака, а кошка — это кошка). Проще говоря: обучение нейронной сети означает нахождение подходящих весов нейронных связей благодаря петле обратной связи, называемой градиентным обратным распространением… и все, ребята.
Параллельно теории управления и глубокому обучению
Инженерная область теории управления определяет принципы, аналогичные механизму, используемому для обучения нейронных сетей.
Общие понятия теории управления
В системах управления уставка — это целевое значение для системы. Заданное значение ( вход ) определена и затем обрабатывается контроллером, который регулирует величину заданного значения в соответствии с контуром обратной связи ( регулируемую переменную ). После того, как заданное значение было регулировать ее затем направляется в контролируемой системе , которая будет производить выходной сигнал. Этот выход контролируется с помощью соответствующей метрики, которая затем сравнивается (компаратор) с исходным входом через контур обратной связи . Это позволяет контроллеру определять уровень регулировки (управляемая переменная) исходной уставки.
Теория управления применительно к радиатору
Возьмем, к примеру, сопротивление (управляемую систему) в радиаторе. Представьте, что вы решили установить комнатную температуру на 20 ° C (заданное значение) . Радиатор запускается, подает сопротивление с определенной интенсивностью, определяемой контроллером . Затем датчик (термометр) измеряет температуру окружающей среды ( элементы обратной связи ), которая затем сравнивается (компаратор) с заданным значением (желаемой температурой) и регулирует (контроллер) электрическую напряженность, передаваемую на сопротивление. Регулировка новой интенсивности осуществляется через шаг постепенной регулировки.
Теория управления применительно к обучению нейронной сети
Обучение нейронной сети аналогично обучению излучателя, поскольку управляемая система является моделью обнаружения кошки или собаки.
Цель больше не в том, чтобы иметь минимальную разницу между заданной температурой и фактической температурой, а в том, чтобы минимизировать ошибку (потерю) между классификацией входящих данных (кошка есть кошка) и классификацией нейронной сети.
Для достижения этого система должна будет посмотреть на вход ( заданное значение ) и вычислить выход ( управляемая система ) на основе параметров, определенных в алгоритме. Этот этап называется прямым проходом.
После расчета выходных данных система повторно распространит ошибку оценки, используя градиентное ретро-распространение ( элементы обратной связи ). Хотя разница температур между заданным значением и показателем термометра была преобразована в электрическую интенсивность для излучателя, здесь система будет регулировать веса различных входов в каждый нейрон с заданным шагом (скорость обучения) .
Одна вещь, которую следует учитывать: проблема долины
При обучении системы обратное распространение приведет к тому, что система уменьшит количество ошибок, которые она допускает, чтобы наилучшим образом соответствовать поставленным вами целям (обнаружение, что собака есть собака…).
Выбор скорости обучения, с которой вы будете регулировать свои веса (то, что в теории управления называется этапом корректировки ).
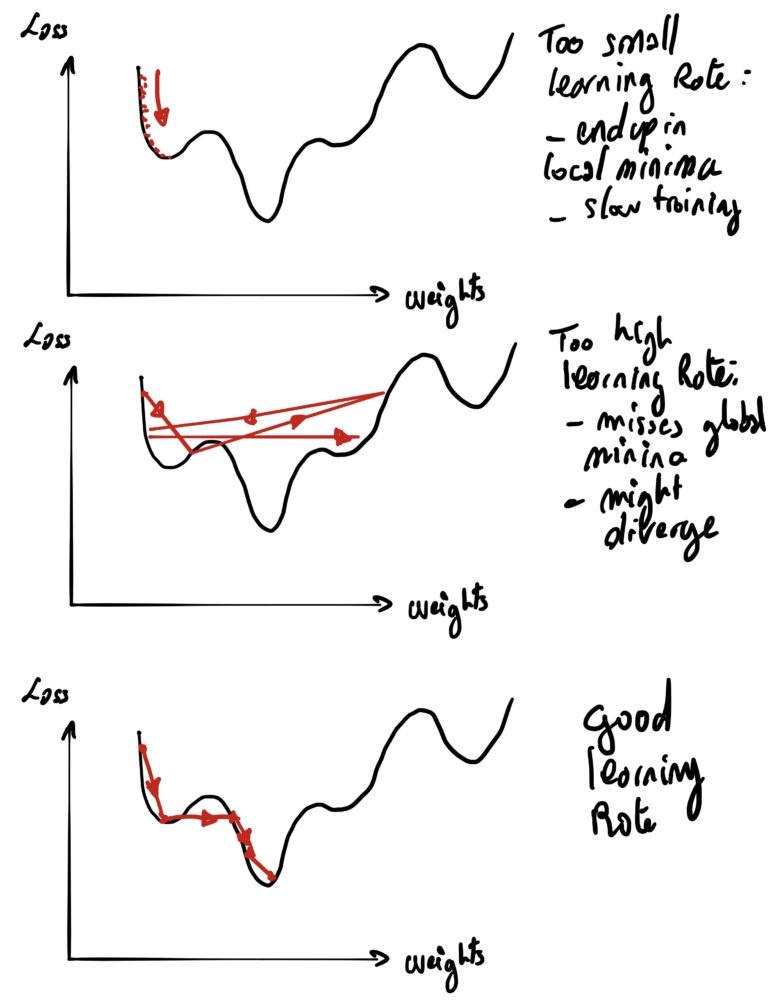
Как и в теории управления, система управления может столкнуться с несколькими проблемами, если она неправильно спроектирована:
- Если шаг коррекции (скорость обучения) слишком мал, это приведет к очень медленной сходимости (то есть потребуется очень много времени, чтобы разогреть вашу комнату до 20 ° C…).
- Слишком низкая скорость обучения также может привести к тому, что вы застрянете в локальных минимумах
- Если шаг коррекции (скорость обучения) слишком высок, это приведет к тому, что система никогда не сойдется (биение вокруг куста) или хуже (то есть радиатор будет колебаться между слишком горячим или слишком холодным)
- Система могла войти в резонансное состояние ( дивергенцию ).
В конце концов, для обучения искусственной нейронной сети (ИНС) требуется всего несколько шагов:
- Сначала для ИНС потребуется инициализация случайного веса.
- Разделить набор данных на партии (размер партии)
- Отправляйте партии 1 на 1 в GPU
- Рассчитайте прямой проход (каким будет результат с текущими весами)
- Сравните рассчитанный выход с ожидаемым выходом (убытком)
- Отрегулируйте веса (используя приращение или уменьшение скорости обучения ) в соответствии с обратным проходом (обратное распространение градиента) .
- Вернуться на квадрат 2
Дальнейшего уведомления
Вот и все, теперь вы готовы прочитать нашу будущую запись в блоге, посвященную распределенному обучению в контексте глубокого обучения.