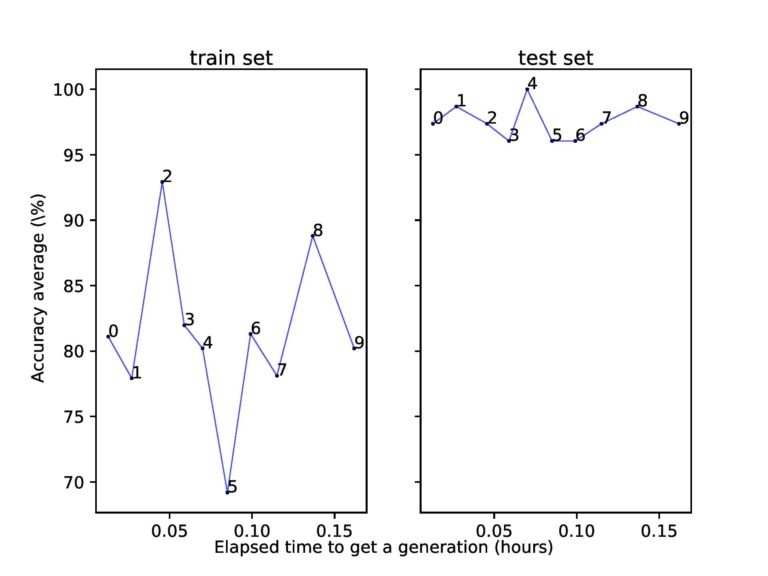
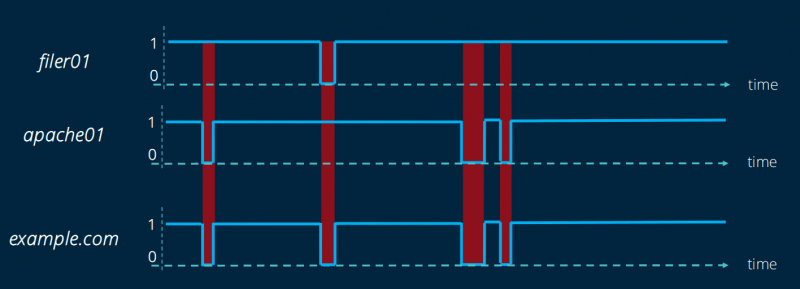
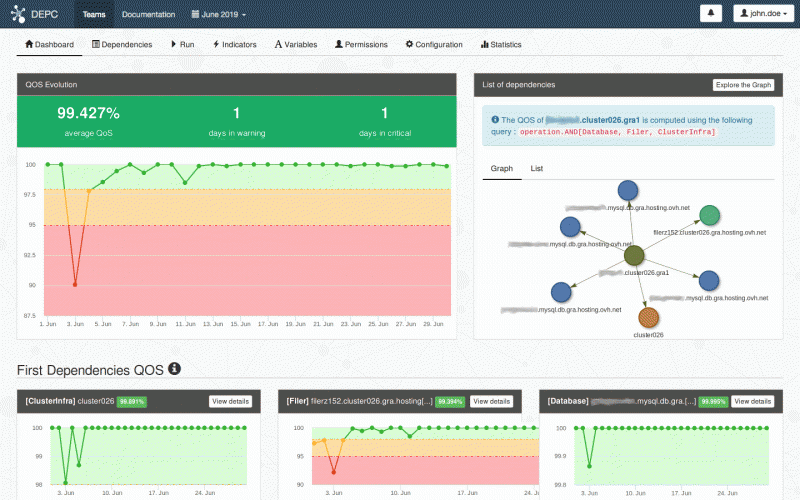
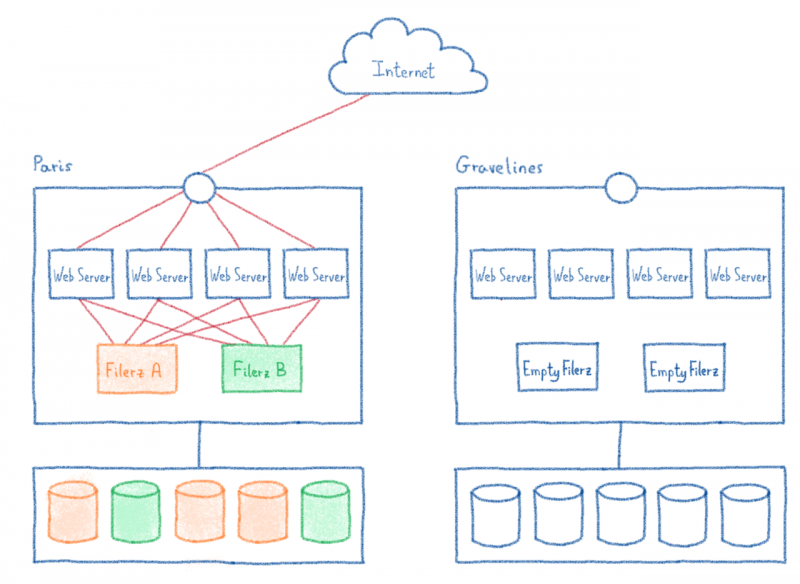
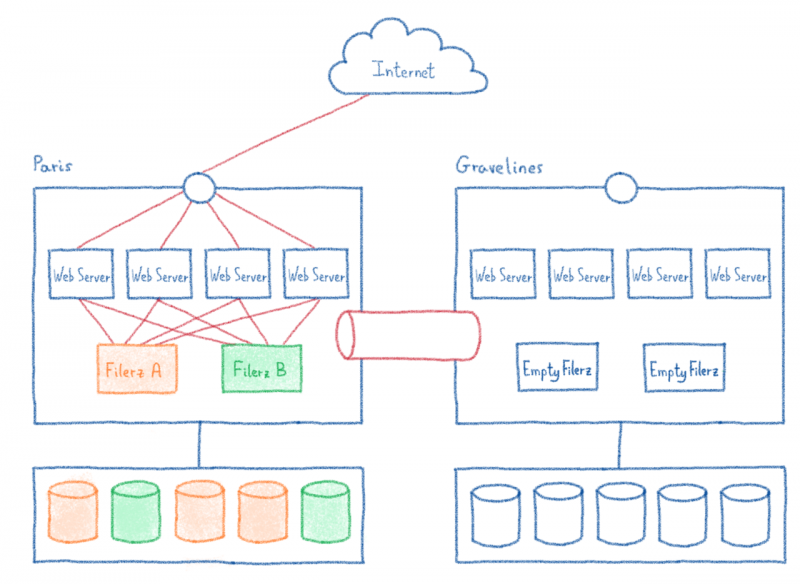
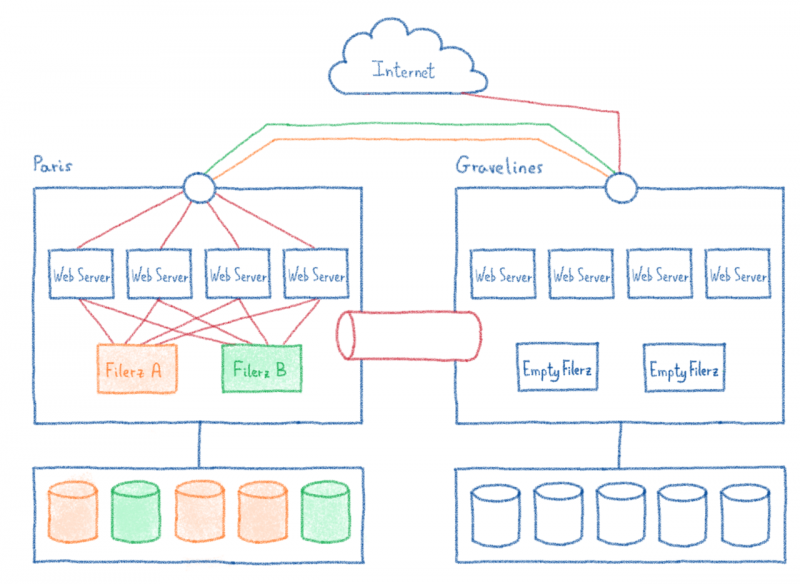
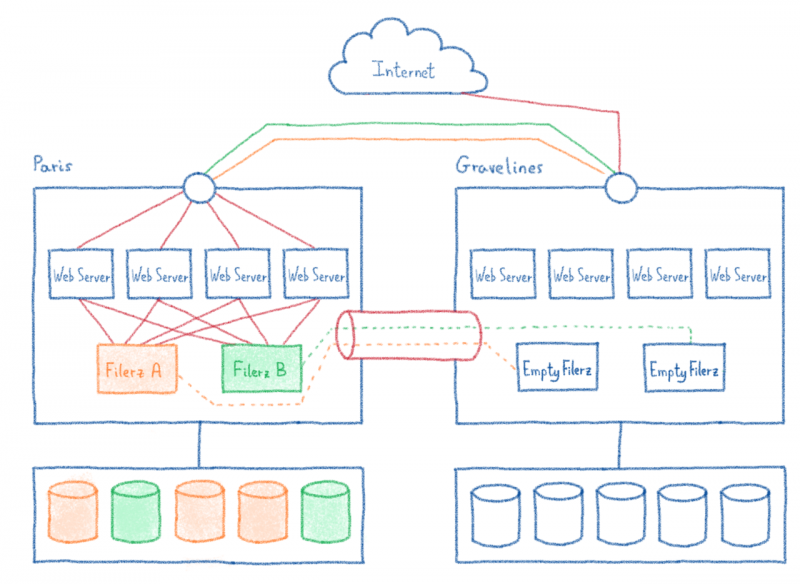
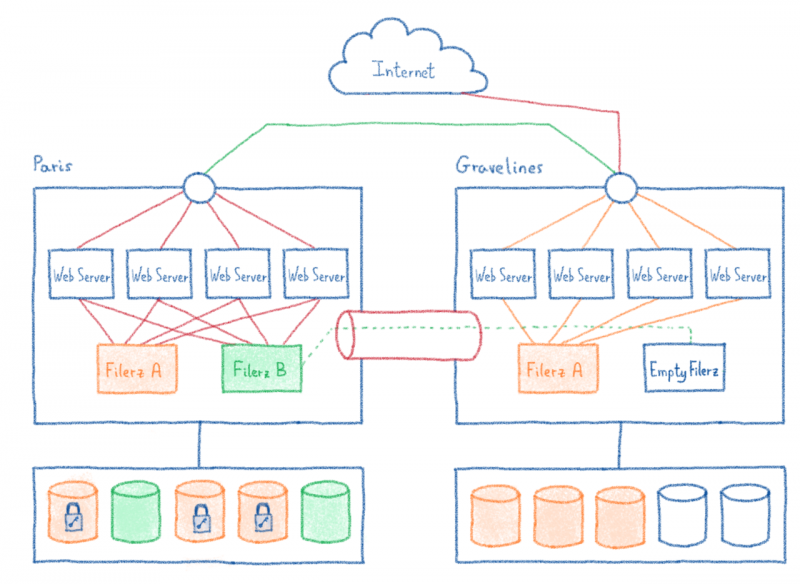
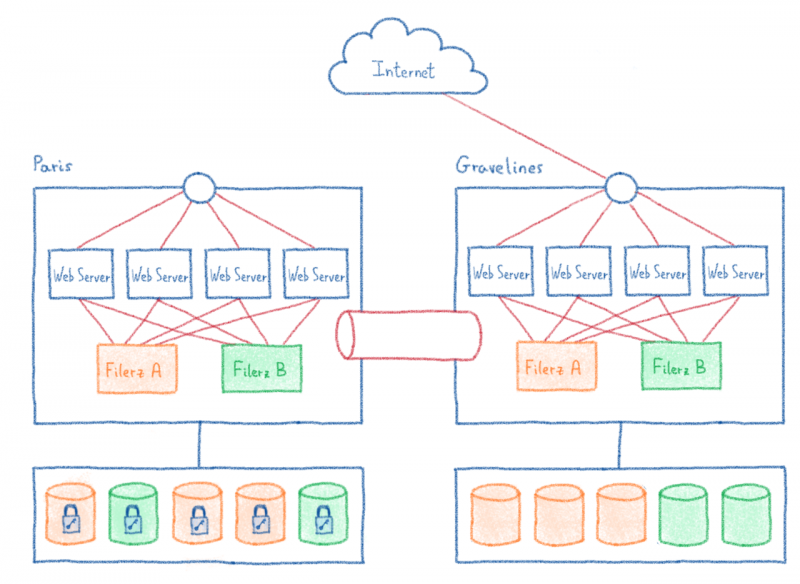
Оглядываясь назад на саммит OVHCloud 2019
На свой 7-й саммит OVHcloud собрал все свое сообщество на ежегодную встречу в Порт-де-Версаль, Париж. На вступительной речи, представленной основателем и председателем OVHcloud Октавом Клаба и генеральным директором Мишелем Поленом, за мероприятием следили почти 10 000 человек, посетив выставку Paris Expo или воспользовавшись видеопотоком по всему миру.
Компания стремится предложить европейскую альтернативу облачному рынку, и ее 20-летие знаменует собой новую веху в ее росте. Это возможность напомнить всем о позиционировании компании и объявить о принятии названия OVHcloud.
OVHcloud демонстрирует свою способность к международному росту, поддержке и инновациям. Он полностью сосредоточен на облаке и намерен внести свой вклад в развивающуюся экосистему надежных решений в Европе.

В своих четырех вселенных OVHcloud следует своим направлениям развития и инноваций, чтобы предлагать своим клиентам решения и продукты, адаптированные к их потребностям и использованию ресурсов.
В своих четырех вселенных OVHcloud следует своим направлениям развития и инноваций, чтобы предлагать своим клиентам решения и продукты, адаптированные к их потребностям и использованию ресурсов.
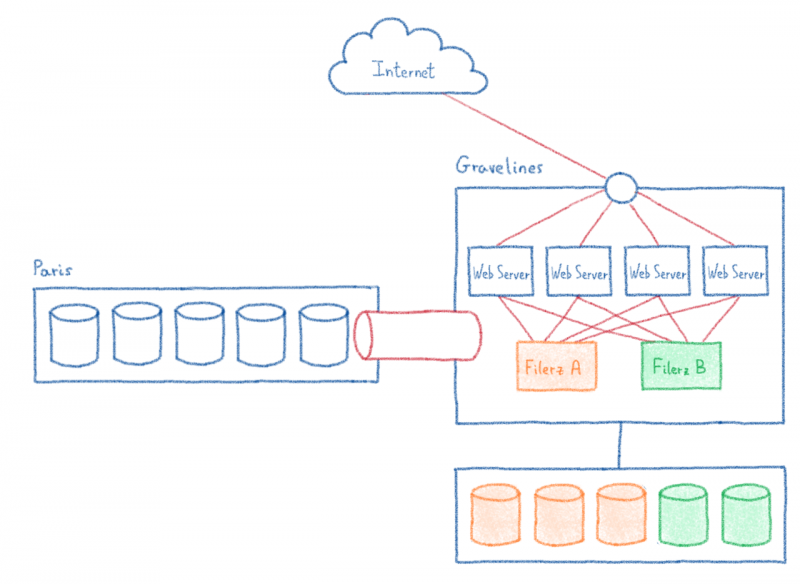
С помощью корпоративных продуктов и решений лица, принимающие решения в области ИТ, имеют возможность защитить свои проекты цифрового перехода на основе прозрачного, обратимого, прогнозирующего и мульти-локального облака. В этом году портфель Bare Metal будет пополнен кластерами выделенных серверов на основе частной сети с гарантированной производительностью через стандартные API-интерфейсы для лучшей автоматизации. Компания будет в ближайшее время обновить свою линейку премиум настраиваемым выделенных серверов HG с последнего поколения Intel® Cascade Lake ™ и 2 - го поколения AMD EPYC ™ процессоров, чтобы предложить пользователям еще больше производительности и надежности. Наконец, группа реализует свою глобальную стратегию сертификации и проходит процесс квалификации SecNumCloud .
С линейкой продуктов Public Cloud разработчики могут начать свою деятельность мгновенно, с гибкостью ресурсов по запросу, которые позволяют им легко и быстро регулировать использование ресурсов в соответствии со своими потребностями. Компания также остается верна своим обязательствам, используя открытые и совместимые стандарты: теперь доступно публичное облачное хранилище с поддержкой S3 API, и скоро будет завершено согласование общедоступного облака с инструментами RefStack.
Услуги общедоступного облака также расширяются во всем мире: платформа аналитических данных (ADP) теперь позволяет развертывать предварительно настроенные кластеры больших данных менее чем за час в регионах общедоступного облака в Европе, Канаде и Азиатско-Тихоокеанском регионе. Наконец, OVHcloud недавно запустила ряд частных баз данных на основе PostgreSQL, которые полностью управляются и адаптированы к производственным потребностям, чтобы пользователи могли сосредоточиться на своей основной деятельности.
Системные администраторы могут использовать серверные решения для построения своей инфраструктуры по лучшей цене и производительности, доступным на рынке. В этом году OVHcloud полностью изменил дизайн выделенных серверов, стремясь упростить его и сделать более универсальным. Чтобы удовлетворить требования средних предприятий, государственных учреждений и университетов к масштабируемости и производительности, OVHcloud недавно выпустила новую линейку выделенных серверов для инфраструктуры . Вы можете использовать их для построения серверных архитектур в кластерах и управления большими базами данных. Все серверы в линейке Infrastructure оснащены новейшей технологией OVHcloud Link Aggregation (OLA )., который позволяет пользователям объединять сетевые интерфейсы каждого сервера для повышения его доступности, одновременно изолируя его от общедоступной сети и возможных угроз. Некоторые серверы в линейке Infrastructure также предоставляют расширенные функции безопасности с помощью технологии Intel® Software Guard Extensions (SGX), которая полностью изолирует код, который выполняется, и данные, которые обрабатываются.
OVHCloud также запустит в начале 2020 года свое совершенно новое предложение виртуального частного сервера. Просто и легко масштабируется, от STARTER до ELITE. Он поставляется с такими опциями, как автоматическое резервное копирование и 99,9% SLA.
Рыночные решения позволяют физическим лицам и малым предприятиям расти в цифровом формате. Облачные веб- решения предназначены для разработчиков и агентств. Они будут разработаны в этом году с новыми конфигурациями для более широкого круга задач. В результате пользователи получат дополнительные ресурсы для своих сайтов и веб-приложений.
Наконец, как чистый игрок в инфраструктуре как услуги (IaaS), OVHcloud полагается на обширную сеть партнеров, обладающих всеми навыками, необходимыми для развертывания и обслуживания услуг для своих клиентов. Чтобы инвестировать в это, компания переработала партнерскую программу OVHcloud, чтобы лучше поддерживать цифровые преобразования компаний. Это также еще один способ, которым компания фокусируется на своей интернационализации. Программа открыта и соответствует ДНК OVHcloud, и в ее первые участники уже входят такие компании, как Thales, Capgemini и Deloitte.
Компания стремится предложить европейскую альтернативу облачному рынку, и ее 20-летие знаменует собой новую веху в ее росте. Это возможность напомнить всем о позиционировании компании и объявить о принятии названия OVHcloud.
OVHcloud демонстрирует свою способность к международному росту, поддержке и инновациям. Он полностью сосредоточен на облаке и намерен внести свой вклад в развивающуюся экосистему надежных решений в Европе.
Постоянные инновации для облака SMARTer
В своих четырех вселенных OVHcloud следует своим направлениям развития и инноваций, чтобы предлагать своим клиентам решения и продукты, адаптированные к их потребностям и использованию ресурсов.
Поддержка лиц, принимающих решения в сфере ИТ, в переходе на цифровые технологии с помощью Enterprise
В своих четырех вселенных OVHcloud следует своим направлениям развития и инноваций, чтобы предлагать своим клиентам решения и продукты, адаптированные к их потребностям и использованию ресурсов.
Поддержка лиц, принимающих решения в сфере ИТ, в переходе на цифровые технологии с помощью Enterprise
С помощью корпоративных продуктов и решений лица, принимающие решения в области ИТ, имеют возможность защитить свои проекты цифрового перехода на основе прозрачного, обратимого, прогнозирующего и мульти-локального облака. В этом году портфель Bare Metal будет пополнен кластерами выделенных серверов на основе частной сети с гарантированной производительностью через стандартные API-интерфейсы для лучшей автоматизации. Компания будет в ближайшее время обновить свою линейку премиум настраиваемым выделенных серверов HG с последнего поколения Intel® Cascade Lake ™ и 2 - го поколения AMD EPYC ™ процессоров, чтобы предложить пользователям еще больше производительности и надежности. Наконец, группа реализует свою глобальную стратегию сертификации и проходит процесс квалификации SecNumCloud .
Предоставление открытой стандартной среды для DevOps, которым необходимо разрабатывать масштабируемые облачные приложения с публичным облаком
С линейкой продуктов Public Cloud разработчики могут начать свою деятельность мгновенно, с гибкостью ресурсов по запросу, которые позволяют им легко и быстро регулировать использование ресурсов в соответствии со своими потребностями. Компания также остается верна своим обязательствам, используя открытые и совместимые стандарты: теперь доступно публичное облачное хранилище с поддержкой S3 API, и скоро будет завершено согласование общедоступного облака с инструментами RefStack.
Услуги общедоступного облака также расширяются во всем мире: платформа аналитических данных (ADP) теперь позволяет развертывать предварительно настроенные кластеры больших данных менее чем за час в регионах общедоступного облака в Европе, Канаде и Азиатско-Тихоокеанском регионе. Наконец, OVHcloud недавно запустила ряд частных баз данных на основе PostgreSQL, которые полностью управляются и адаптированы к производственным потребностям, чтобы пользователи могли сосредоточиться на своей основной деятельности.
Удовлетворение потребностей энтузиастов инфраструктуры, оборудования и сетей, желающих создать облачную платформу с серверными решениями
Системные администраторы могут использовать серверные решения для построения своей инфраструктуры по лучшей цене и производительности, доступным на рынке. В этом году OVHcloud полностью изменил дизайн выделенных серверов, стремясь упростить его и сделать более универсальным. Чтобы удовлетворить требования средних предприятий, государственных учреждений и университетов к масштабируемости и производительности, OVHcloud недавно выпустила новую линейку выделенных серверов для инфраструктуры . Вы можете использовать их для построения серверных архитектур в кластерах и управления большими базами данных. Все серверы в линейке Infrastructure оснащены новейшей технологией OVHcloud Link Aggregation (OLA )., который позволяет пользователям объединять сетевые интерфейсы каждого сервера для повышения его доступности, одновременно изолируя его от общедоступной сети и возможных угроз. Некоторые серверы в линейке Infrastructure также предоставляют расширенные функции безопасности с помощью технологии Intel® Software Guard Extensions (SGX), которая полностью изолирует код, который выполняется, и данные, которые обрабатываются.
OVHCloud также запустит в начале 2020 года свое совершенно новое предложение виртуального частного сервера. Просто и легко масштабируется, от STARTER до ELITE. Он поставляется с такими опциями, как автоматическое резервное копирование и 99,9% SLA.
Расширение присутствия владельцев бизнеса в Интернете и делового общения с помощью решений Market
Рыночные решения позволяют физическим лицам и малым предприятиям расти в цифровом формате. Облачные веб- решения предназначены для разработчиков и агентств. Они будут разработаны в этом году с новыми конфигурациями для более широкого круга задач. В результате пользователи получат дополнительные ресурсы для своих сайтов и веб-приложений.
Наконец, как чистый игрок в инфраструктуре как услуги (IaaS), OVHcloud полагается на обширную сеть партнеров, обладающих всеми навыками, необходимыми для развертывания и обслуживания услуг для своих клиентов. Чтобы инвестировать в это, компания переработала партнерскую программу OVHcloud, чтобы лучше поддерживать цифровые преобразования компаний. Это также еще один способ, которым компания фокусируется на своей интернационализации. Программа открыта и соответствует ДНК OVHcloud, и в ее первые участники уже входят такие компании, как Thales, Capgemini и Deloitte.