Вклад в Apache HBase: настраиваемая балансировка данных
В сегодняшнем блоге мы собираемся взглянуть на наш вклад в разработку стохастического балансировщика нагрузки Apache HBase, основанный на нашем опыте запуска кластеров HBase для поддержки мониторинга OVHcloud.
Вы когда-нибудь задумывались, как:
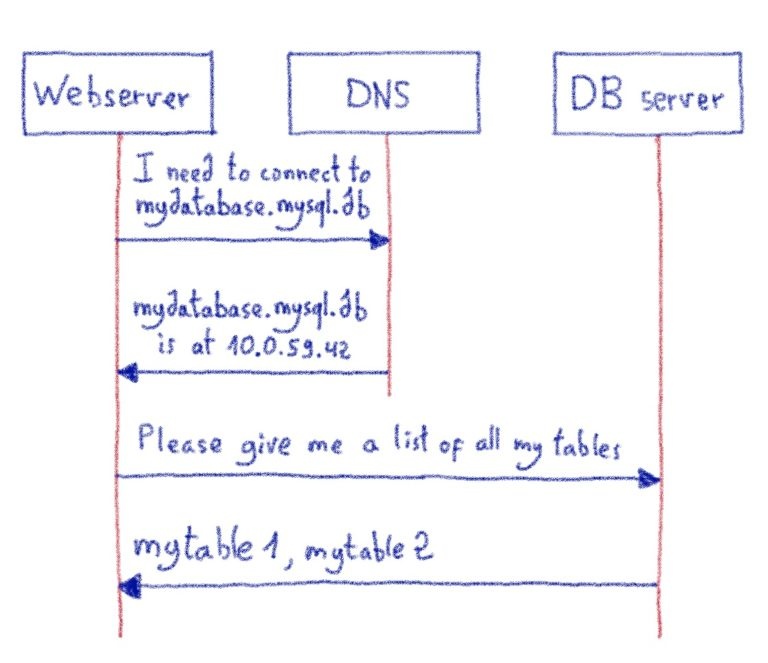
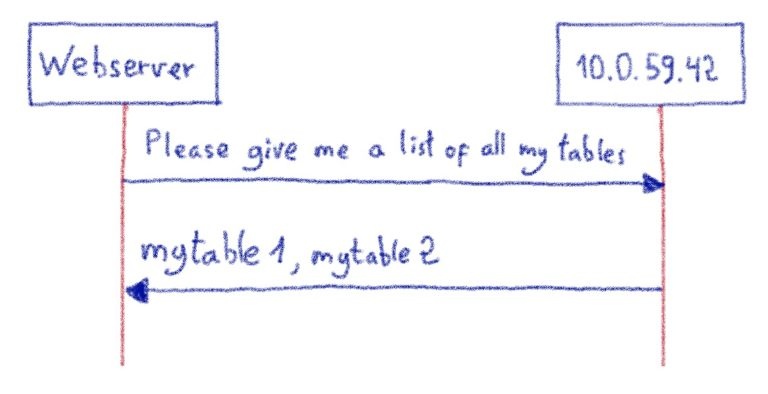
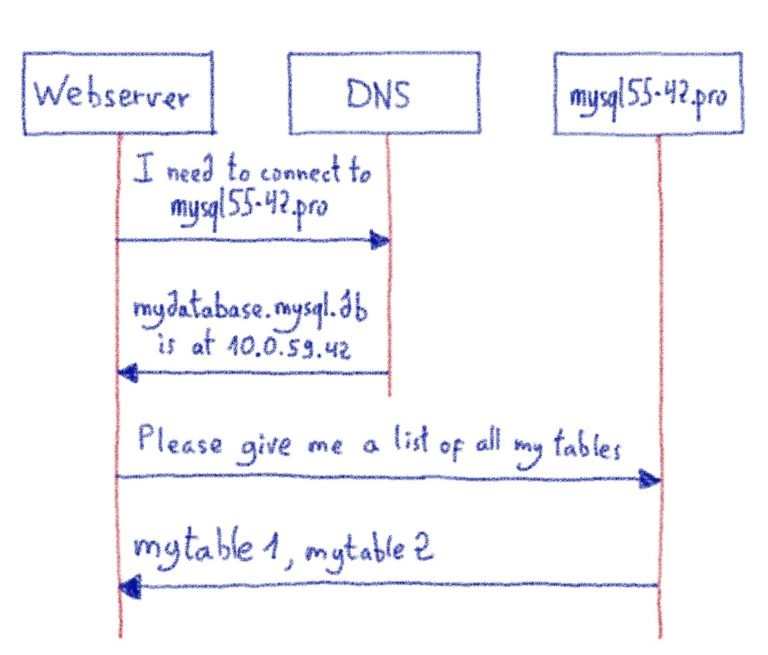
Все внутренние команды постоянно собирают данные телеметрии и мониторинга и отправляют их специальной группе, которая отвечает за обработку всех метрик и журналов, генерируемых инфраструктурой OVHcloud : команде Observability.
Мы перепробовали множество различных баз данных временных рядов и в итоге выбрали Warp10 для обработки наших рабочих нагрузок. Warp10 может быть интегрирован с различными решениями для работы с большими данными, предоставляемыми Apache Foundation. В нашем случае мы используем Apache HBase в качестве хранилища данных долгосрочного хранения для наших показателей.
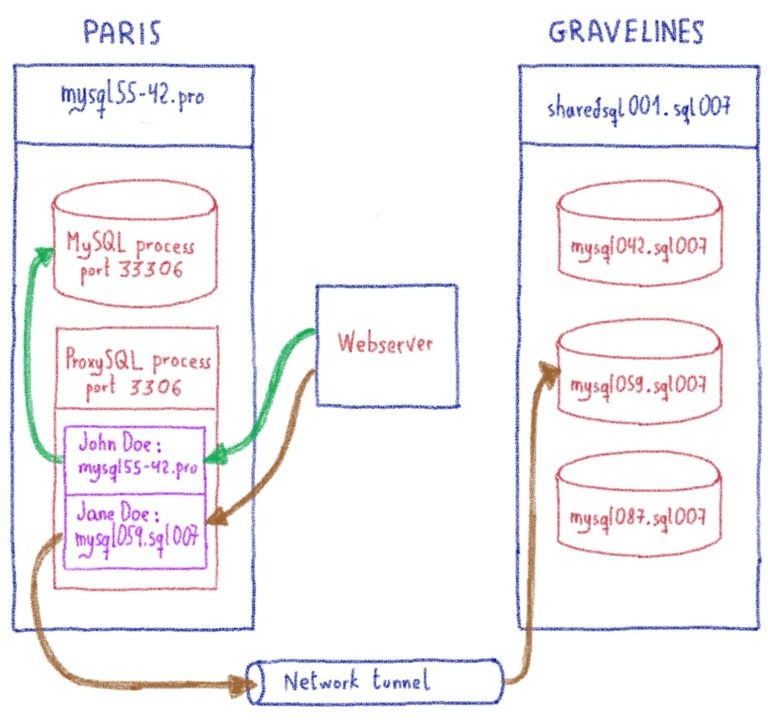
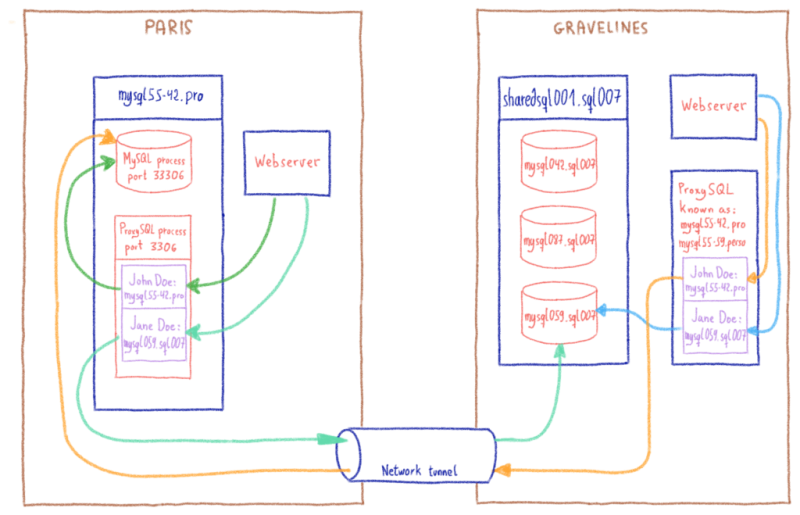
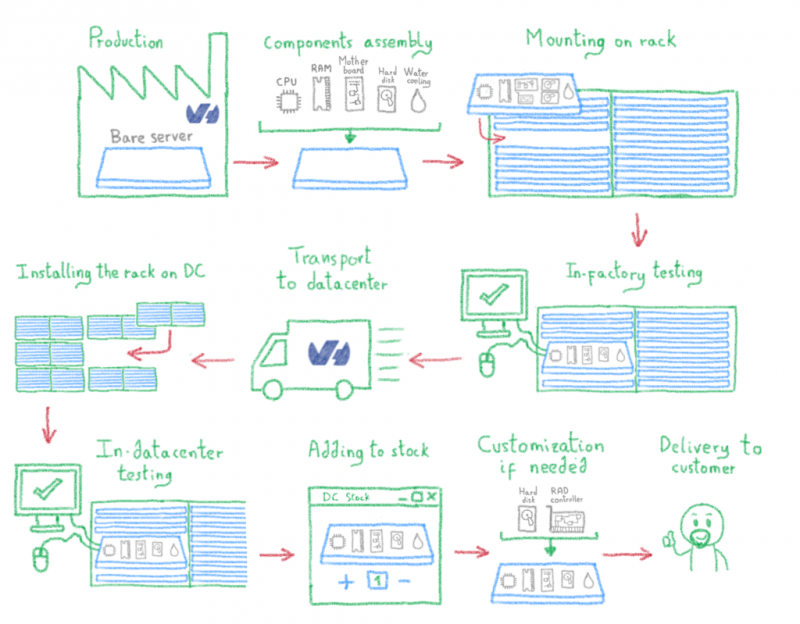
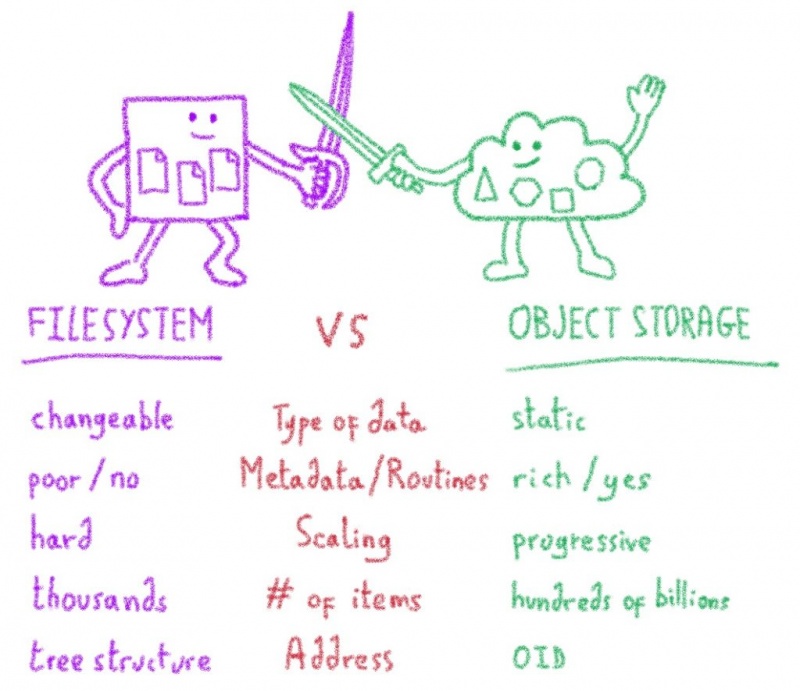
Apache HBase , хранилище данных, построенное на основе Apache Hadoop , предоставляет эластичную распределенную карту с упорядочением по ключам. Таким образом, одна из ключевых особенностей Apache HBase для нас — это возможность сканировать , то есть получать ряд ключей. Благодаря этой функции мы можем оптимизировать тысячи точек данных .
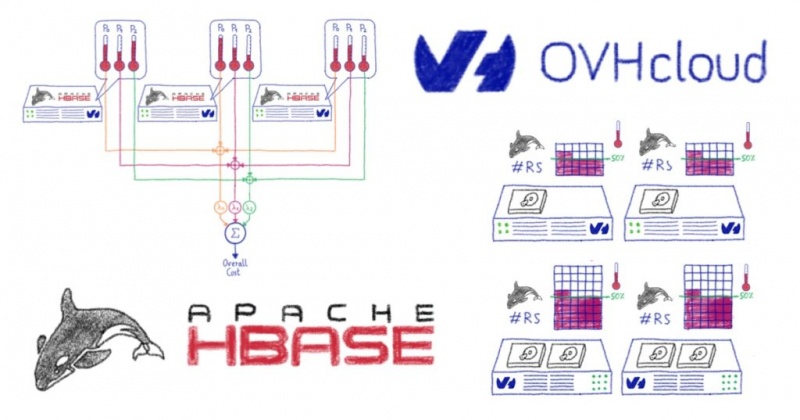
У нас есть собственные выделенные кластеры, самый большой из которых имеет более 270 узлов для распределения наших рабочих нагрузок:
Как вы, вероятно, можете себе представить, хранение 300 ТБ данных на 270 узлах сопряжено с некоторыми проблемами, связанными с перераспределением, поскольку каждый бит является горячими данными и должен быть доступен в любое время. Давайте нырнем!
Прежде чем погрузиться в балансировщик, давайте посмотрим, как он работает. В Apache HBase данные разделяются на сегменты, вызываемые Regionsи распределяемые по ним RegionServers. Количество регионов будет увеличиваться по мере поступления данных, и в результате регионы будут разделены. Вот тут-то и пригодится Balancer. Он будет перемещать регионы, чтобы избежать появления горячих точек, RegionServerи эффективно распределяет нагрузку.
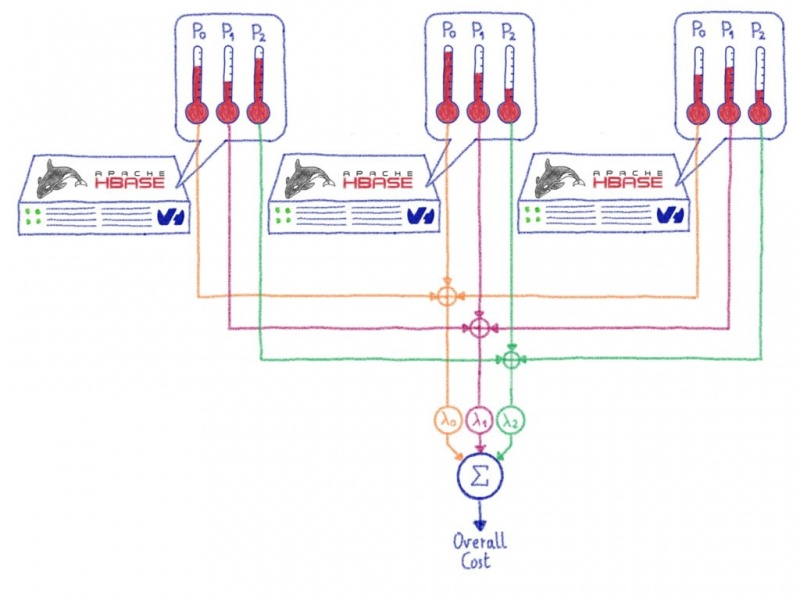
Фактическая реализация, называемая StochasticBalancer, использует подход, основанный на затратах:
Мы выяснили это для нашего конкретного варианта использования , который включает:
… Количество регионов на RegionServer было для нас настоящим пределом
Даже если стратегия балансировки кажется простой, мы действительно считаем, что возможность запускать кластер Apache HBase на разнородном оборудовании жизненно важна , особенно в облачных средах, потому что вы, возможно, не сможете снова купить те же спецификации сервера в будущем. В нашем предыдущем примере наш кластер вырос с 80 до 250 машин за четыре года. За это время мы купили новые ссылки на выделенные серверы и даже протестировали некоторые специальные внутренние ссылки.
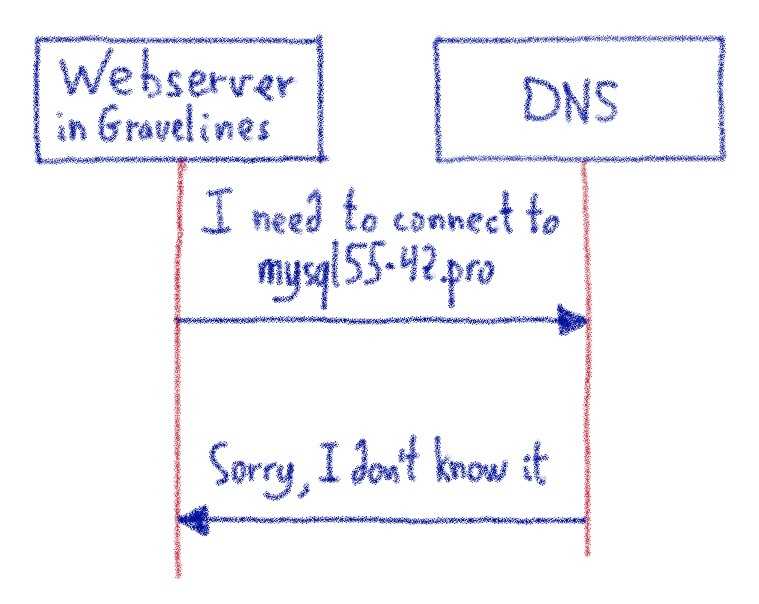
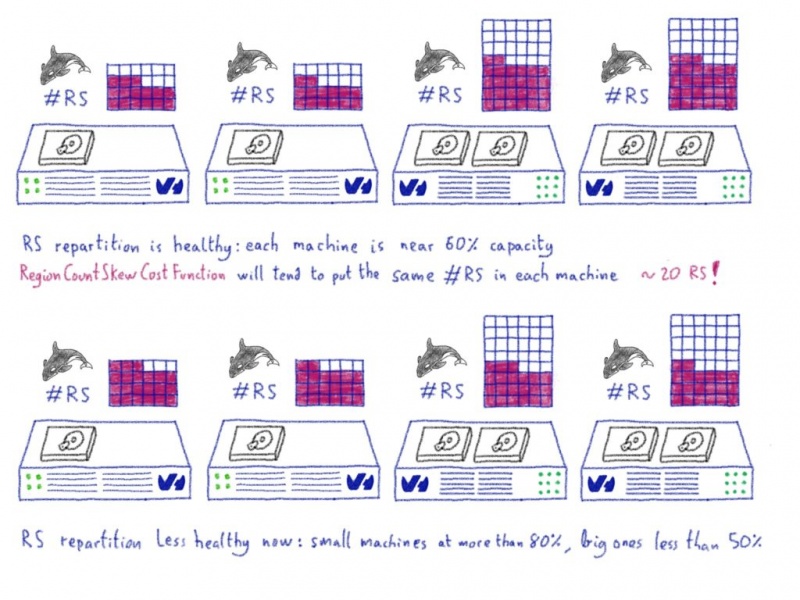
В итоге мы получили разные группы оборудования: некоторые серверы могут обрабатывать только 180 регионов, тогда как самые большие могут обрабатывать более 900 . Из-за этого несоответствия нам пришлось отключить балансировщик нагрузки, чтобы избежать использования RegionCountSkewCostFunction , которая попыталась бы перенести все RegionServers в одно и то же количество регионов.
Два года назад мы разработали некоторые внутренние инструменты, которые отвечают за балансировку нагрузки по регионам в RegionServers. Этот инструмент действительно хорошо работал в нашем случае, упрощая повседневную работу нашего кластера.
Открытый исходный код лежит в основе OVHcloud , и это означает, что мы создаем наши инструменты на основе программного обеспечения с открытым исходным кодом, но также мы вносим свой вклад и возвращаем его сообществу. Когда мы поговорили, мы увидели, что не только нас беспокоит проблема гетерогенного кластера. Мы решили переписать наш инструментарий, чтобы сделать его более общим, и внести его непосредственно в проект HBase .
Первый вклад был довольно простым, список функций стоимости был постоянным. Мы добавили возможность загрузки пользовательских функций стоимости.
Второй вклад касался добавления дополнительной функции costFunction для балансировки регионов в соответствии с правилом емкости.
Балансировщик загрузит файл, содержащий строки правил. Правило состоит из регулярного выражения для имени хоста и ограничения. Например, мы могли бы иметь:
RegionServers с именами хостов, соответствующими первым правилам, будут иметь ограничение 200 , а остальные 50 . Если совпадений нет, устанавливается значение по умолчанию.
Благодаря этому правилу у нас есть две ключевые части информации:
Они
Возьмем пример… Представьте, что у нас есть 20 RS:
Итак, исходя из следующих правил
… Мы видим, что вторая группа перегружена, тогда как в первой группе много места.
Мы знаем, что можем обрабатывать максимум 2500 регионов (200 × 10 + 50 × 10), и в настоящее время у нас есть 1200 регионов (60 × 20). Таким образом, система
Благодаря участникам Apache HBase наши исправления теперь объединены в основную ветку. Как только сопровождающие Apache HBase опубликуют новый выпуск, мы развернем и будем использовать его в любом масштабе. Это позволит больше автоматизировать с нашей стороны и упростит операции для группы наблюдения.
Участие было потрясающим путешествием. Что мне больше всего нравится в открытом исходном коде, так это возможность внести свой вклад и создать более надежное программное обеспечение. У нас было мнение о том, как следует решать ту или иную проблему, но обсуждения с сообществом помогли нам уточнить ее . Мы поговорили с инженерами из других компаний, которые, как и мы , испытывали трудности с развертыванием облака Apache HBase , и благодаря этим обменам наш вклад становился все более и более актуальным.
Контекст
Вы когда-нибудь задумывались, как:
- мы генерируем графики для вашего сервера OVHcloud или пакета веб-хостинга?
- наши внутренние команды контролируют свои собственные серверы и приложения?
Все внутренние команды постоянно собирают данные телеметрии и мониторинга и отправляют их специальной группе, которая отвечает за обработку всех метрик и журналов, генерируемых инфраструктурой OVHcloud : команде Observability.
Мы перепробовали множество различных баз данных временных рядов и в итоге выбрали Warp10 для обработки наших рабочих нагрузок. Warp10 может быть интегрирован с различными решениями для работы с большими данными, предоставляемыми Apache Foundation. В нашем случае мы используем Apache HBase в качестве хранилища данных долгосрочного хранения для наших показателей.
Apache HBase , хранилище данных, построенное на основе Apache Hadoop , предоставляет эластичную распределенную карту с упорядочением по ключам. Таким образом, одна из ключевых особенностей Apache HBase для нас — это возможность сканировать , то есть получать ряд ключей. Благодаря этой функции мы можем оптимизировать тысячи точек данных .
У нас есть собственные выделенные кластеры, самый большой из которых имеет более 270 узлов для распределения наших рабочих нагрузок:
- от 1,6 до 2 миллионов операций записи в секунду, 24/7
- от 4 до 6 миллионов чтений в секунду
- около 300 ТБ телеметрии, хранящейся в Apache HBase
Как вы, вероятно, можете себе представить, хранение 300 ТБ данных на 270 узлах сопряжено с некоторыми проблемами, связанными с перераспределением, поскольку каждый бит является горячими данными и должен быть доступен в любое время. Давайте нырнем!
Как работает балансировка в Apache HBase?
Прежде чем погрузиться в балансировщик, давайте посмотрим, как он работает. В Apache HBase данные разделяются на сегменты, вызываемые Regionsи распределяемые по ним RegionServers. Количество регионов будет увеличиваться по мере поступления данных, и в результате регионы будут разделены. Вот тут-то и пригодится Balancer. Он будет перемещать регионы, чтобы избежать появления горячих точек, RegionServerи эффективно распределяет нагрузку.
Фактическая реализация, называемая StochasticBalancer, использует подход, основанный на затратах:
- Сначала он вычисляет общую стоимость кластера, проходя через цикл
. Каждая функция стоимости возвращает число от 0 до 1 включительно , где 0 — это решение с наименьшей стоимостью и лучшим решением, а 1 — с максимально возможной стоимостью и наихудшим решением. Apache Hbase поставляется с несколькими функциями стоимости, которые измеряют такие вещи, как загрузка региона, загрузка таблицы, локальность данных, количество регионов на сервер RegionServer… Вычисленные затраты масштабируются с помощью соответствующих коэффициентов, определенных в конфигурации .cost functions - Теперь, когда начальная стоимость вычислена, мы можем попробовать
наш кластер. Для этого Balancer создает случайный случайMutate
, который может быть чем-то вроде замены двух регионов или перемещения одного региона на другой RegionServer . Действие применяется виртуально , после чего рассчитывается новая стоимость . Если новая стоимость ниже нашей предыдущей, действие сохраняется. В противном случае он пропускается. Эта операция повторяетсяnextAction
, поэтому файлthousands of times
.Stochastic - В конце список допустимых действий применяется к фактическому кластеру.
Что у нас не работало?
Мы выяснили это для нашего конкретного варианта использования , который включает:
- Один стол
- Выделенные Apache HBase и Apache Hadoop, адаптированные к нашим требованиям
- Хорошее распределение ключей
… Количество регионов на RegionServer было для нас настоящим пределом
Даже если стратегия балансировки кажется простой, мы действительно считаем, что возможность запускать кластер Apache HBase на разнородном оборудовании жизненно важна , особенно в облачных средах, потому что вы, возможно, не сможете снова купить те же спецификации сервера в будущем. В нашем предыдущем примере наш кластер вырос с 80 до 250 машин за четыре года. За это время мы купили новые ссылки на выделенные серверы и даже протестировали некоторые специальные внутренние ссылки.
В итоге мы получили разные группы оборудования: некоторые серверы могут обрабатывать только 180 регионов, тогда как самые большие могут обрабатывать более 900 . Из-за этого несоответствия нам пришлось отключить балансировщик нагрузки, чтобы избежать использования RegionCountSkewCostFunction , которая попыталась бы перенести все RegionServers в одно и то же количество регионов.
Два года назад мы разработали некоторые внутренние инструменты, которые отвечают за балансировку нагрузки по регионам в RegionServers. Этот инструмент действительно хорошо работал в нашем случае, упрощая повседневную работу нашего кластера.
Открытый исходный код лежит в основе OVHcloud , и это означает, что мы создаем наши инструменты на основе программного обеспечения с открытым исходным кодом, но также мы вносим свой вклад и возвращаем его сообществу. Когда мы поговорили, мы увидели, что не только нас беспокоит проблема гетерогенного кластера. Мы решили переписать наш инструментарий, чтобы сделать его более общим, и внести его непосредственно в проект HBase .
Наш вклад
Первый вклад был довольно простым, список функций стоимости был постоянным. Мы добавили возможность загрузки пользовательских функций стоимости.
Второй вклад касался добавления дополнительной функции costFunction для балансировки регионов в соответствии с правилом емкости.
Как это работает?
Балансировщик загрузит файл, содержащий строки правил. Правило состоит из регулярного выражения для имени хоста и ограничения. Например, мы могли бы иметь:
rs[0-9] 200
rs1[0-9] 50RegionServers с именами хостов, соответствующими первым правилам, будут иметь ограничение 200 , а остальные 50 . Если совпадений нет, устанавливается значение по умолчанию.
Благодаря этому правилу у нас есть две ключевые части информации:
- максимальное число областей для этого кластера
- то правила для каждого сервера
Они
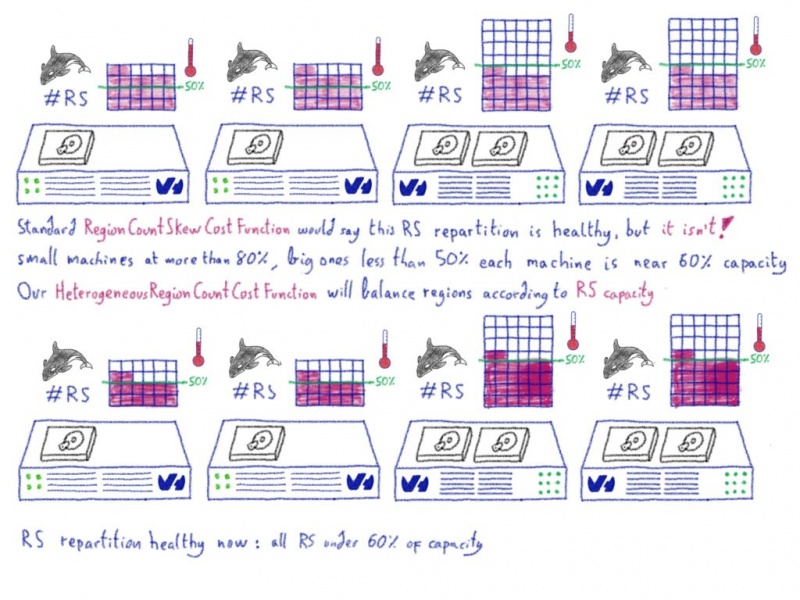
HeterogeneousRegionCountCostFunction Возьмем пример… Представьте, что у нас есть 20 RS:
- 10 RS, названный
вrs0
, нагруженные 60 регионов каждый, каждый из которых может рукоятку 200 регионов.rs9 - 10 RS, названные
вrs10
, нагруженные 60 регионов каждый, каждый из которых может обрабатывать 50 областей.rs19
Итак, исходя из следующих правил
rs[0-9] 200
rs1[0-9] 50… Мы видим, что вторая группа перегружена, тогда как в первой группе много места.
Мы знаем, что можем обрабатывать максимум 2500 регионов (200 × 10 + 50 × 10), и в настоящее время у нас есть 1200 регионов (60 × 20). Таким образом, система
HeterogeneousRegionCountCostFunctionКуда дальше?
Благодаря участникам Apache HBase наши исправления теперь объединены в основную ветку. Как только сопровождающие Apache HBase опубликуют новый выпуск, мы развернем и будем использовать его в любом масштабе. Это позволит больше автоматизировать с нашей стороны и упростит операции для группы наблюдения.
Участие было потрясающим путешествием. Что мне больше всего нравится в открытом исходном коде, так это возможность внести свой вклад и создать более надежное программное обеспечение. У нас было мнение о том, как следует решать ту или иную проблему, но обсуждения с сообществом помогли нам уточнить ее . Мы поговорили с инженерами из других компаний, которые, как и мы , испытывали трудности с развертыванием облака Apache HBase , и благодаря этим обменам наш вклад становился все более и более актуальным.