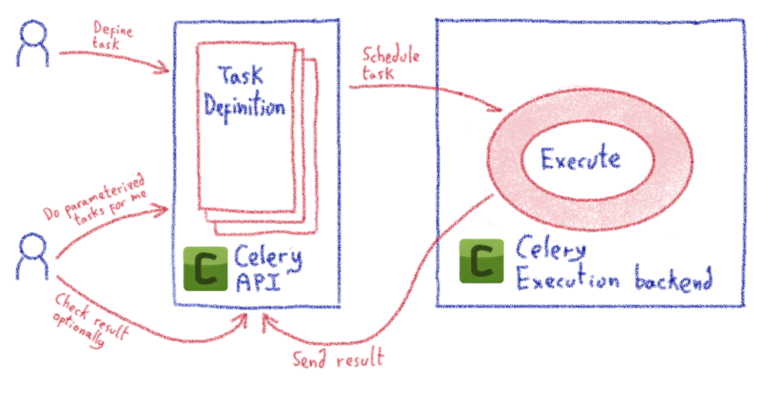
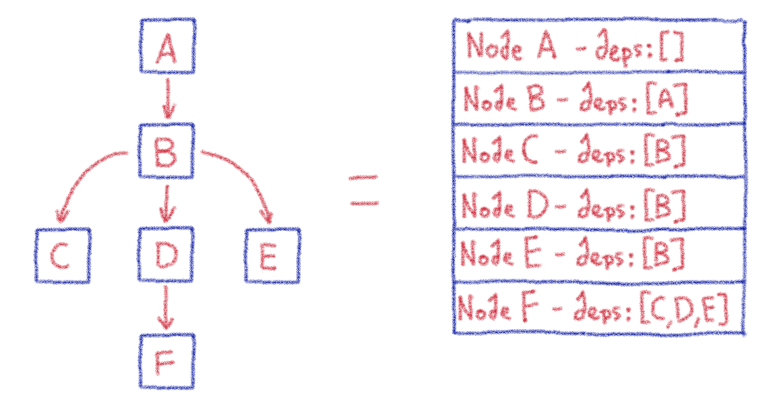
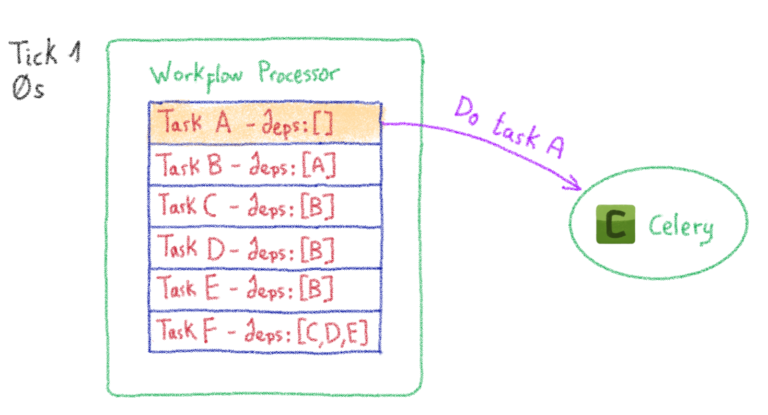
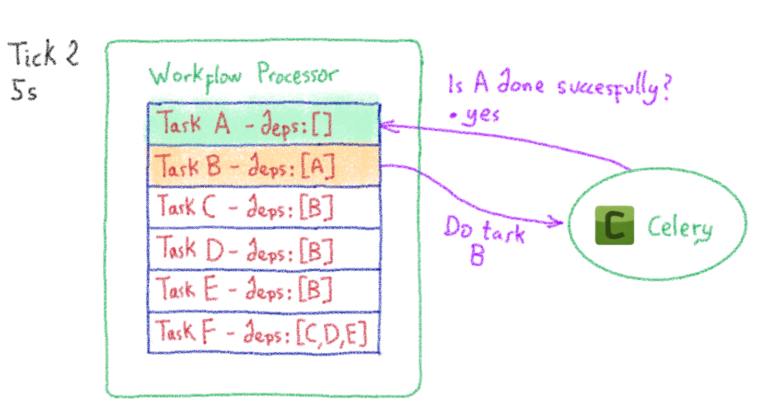
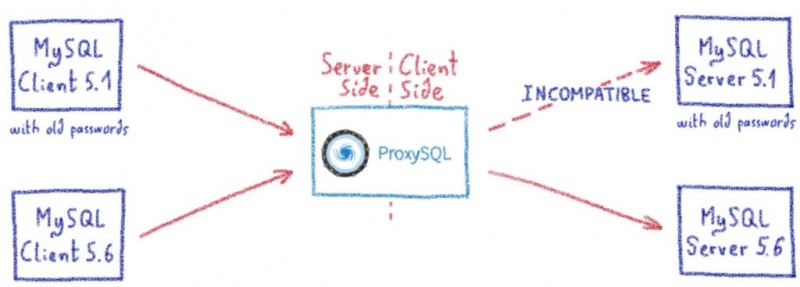
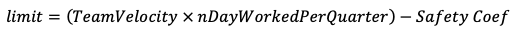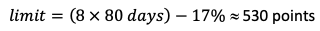Управление Harbour в облачном масштабе: история Harbour Kubernetes Operator
Недавно наша команда контейнерных платформ сделала нашу услугу «Частный управляемый реестр» общедоступной. В этом сообщении блога мы объясним, почему OVHcloud выбрал основу для этой службы на проекте Harbour, построил для него оператор Kubernetes и открыл его исходный код в рамках проекта CNCF goharbor.

После выпуска нашей управляемой службы Kubernetes мы получили много запросов на полностью управляемый частный реестр контейнеров.
Хотя реестр контейнеров для размещения образов может показаться довольно тривиальным для развертывания, наши пользователи упомянули, что решение для реестра производственного уровня является важной частью цепочки поставки программного обеспечения и на самом деле его довольно сложно поддерживать.
Наши клиенты просили решение корпоративного уровня, предлагающее расширенный контроль доступа на основе ролей и безопасность, поскольку опасения по поводу уязвимостей в общедоступных образах возросли, а требования к доверию к контенту стали необходимостью.
Пользователи регулярно хвалили пользовательский интерфейс таких сервисов, как Docker Hub, но в то же время запрашивали сервис с высокой доступностью и поддерживаемый SLA.
Изучив перспективы точной настройки нашего набора функций и модели ценообразования, мы искали лучшие существующие технологии, чтобы поддержать его, и остановились на инкубационном проекте CNCF Harbor (подаренном CNCF компанией VMWare). Помимо того, что Harbour является одним из немногих проектов, достигших инкубационного состояния CNCF, что подтверждает твердую приверженность сообщества, он также стал ключевой частью нескольких коммерческих решений для контейнеризации предприятий. Мы также высоко оценили подход, принятый Харбором: не изобретать колесо заново, а использовать лучшие в своем классе технологии для таких компонентов, как сканирование уязвимостей, доверие к контенту и многие другие. Он использует мощную сеть проектов с открытым исходным кодом CNCF и обеспечивает высокий уровень качества UX.

Пришло время использовать эту технологию 10k-GitHub-stars и адаптировать ее к нашему конкретному случаю: управление десятками тысяч реестров для наших пользователей, каждый из которых имеет определенный объем образов контейнеров и шаблонов использования.
Конечно, высокая доступность (интеграция и развертывание программного обеспечения клиентов зависит от этой услуги), но и надежность данных не обсуждались для нас.
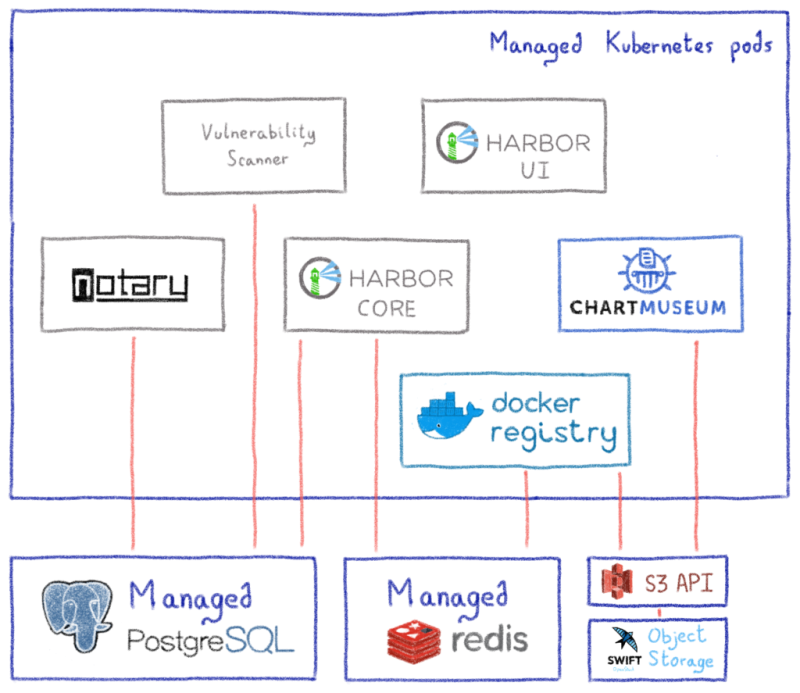
Кроме того, Kubernetes для обеспечения высокой доступности сервисов без сохранения состояния и хранилища объектов (на основе Openstack Swift и совместимость с S3 API ) был очевидным выбором для проверки этих требований.
В течение нескольких недель мы открыли сервис в публичной бета-версии, быстро привлекая сотни активных пользователей. Но с этим всплеском трафика мы, естественно, столкнулись с первыми узкими местами и проблемами производительности.
Мы обратились к группе пользователей и команде Harbour, которые любезно указали нам на возможные решения, и после некоторых небольших, но важных изменений в том, как Harbor обрабатывает соединения с базой данных, наши проблемы были решены. Это укрепило нашу веру в то, что сообщество Harbour твердо и привержено здоровью проекта и требованиям его пользователей.
Поскольку наш сервис процветал, не было реальных инструментов, позволяющих легко приспособить жизненный цикл экземпляров Harbour. Наша приверженность экосистеме Kubernetes сделала концепцию оператора Harbour для Kubernetes интересным подходом.
Мы обсудили с сопровождающими Harbour, и они тепло приветствовали нашу идею разработать его и открыть исходный код в качестве официального оператора Harbour Kubernetes. OVHcloud очень гордится тем, что проект теперь доступен в проекте goharbor GitHub под лицензией Apache 2. Этот проект — еще один пример нашей твердой приверженности открытому исходному коду и нашей готовности внести свой вклад в проекты, которые нам нравятся.
Читатели, знакомые с проектом Harbour, могут задаться вопросом, какое значение этот оператор привносит в текущий каталог развертываний, включая версию Helm Chart, поддерживаемую проектом.
Шаблон проектирования оператора быстро становится популярным и имитирует ориентированный на приложения контроллер, который расширяет Kubernetes для управления более сложными приложениями с отслеживанием состояния. Проще говоря, он предназначен для разных сценариев использования, чем Helm. В то время как диаграмма Helm предлагает универсальный установщик, который также будет развертывать различные зависимости Harbor (база данных, кеш и т. Д.) Из образов Docker с открытым исходным кодом, другие предприятия, операторы услуг и облачные провайдеры, такие как мы, захотят выбрать и -выбрать услугу или технологию, лежащую в основе этих компонентов.
Мы также стремимся расширить возможности текущего оператора v0.5 для управления полным жизненным циклом Harbour, от развертывания до удаления, включая масштабирование, обновления, обновления и управление резервным копированием.
Это поможет производственным пользователям достичь целевого SLO, получить выгоду от управляемых решений или существующих кластеров баз данных, которые они уже обслуживают.
Мы разработали оператор (используя платформу OperatorSDK), чтобы как дополнительные модули Harbor (хранилище Helm Chart, сканер уязвимостей и т. Д.), Ни зависимости (серверная часть хранилища реестра, относительные и нереляционные базы данных и т. Д.) Могли легко соответствовать вашему конкретному варианту использования.
У нас уже есть план действий с сопровождающими Harbour для дальнейшего обогащения оператора, чтобы он мог включать не только фазы развертывания и уничтожения (например, сделать обновления версии Harbour более элегантными). Мы надеемся стать неотъемлемой частью проекта и продолжим инвестировать в Harbour.
С этой целью Жереми Монсинжон и Пьер Перонне также были приглашены в качестве сопровождающих в проекте Harbour с упором на goharbor / оператора.
В дополнение к регулярному участию в нескольких проектах, которые мы используем в OVHcloud, команда контейнерных платформ также работает над другими крупными выпусками с открытым исходным кодом, такими как официальный облачный контроллер OVHcloud для самоуправляемого Kubernetes, который мы планируем выпустить в конце 2020 года.
Скачать Harbour or the Harbour Operator: официальное репозиторий Harbour Github — www.github.com/goharbor
Узнайте больше о гавани: Официальный сайт гавани — goharbor.io/
Необходимость частного реестра S.MART
После выпуска нашей управляемой службы Kubernetes мы получили много запросов на полностью управляемый частный реестр контейнеров.
Хотя реестр контейнеров для размещения образов может показаться довольно тривиальным для развертывания, наши пользователи упомянули, что решение для реестра производственного уровня является важной частью цепочки поставки программного обеспечения и на самом деле его довольно сложно поддерживать.
Наши клиенты просили решение корпоративного уровня, предлагающее расширенный контроль доступа на основе ролей и безопасность, поскольку опасения по поводу уязвимостей в общедоступных образах возросли, а требования к доверию к контенту стали необходимостью.
Пользователи регулярно хвалили пользовательский интерфейс таких сервисов, как Docker Hub, но в то же время запрашивали сервис с высокой доступностью и поддерживаемый SLA.
Идеальное сочетание набора функций с открытым исходным кодом и корпоративного уровня
Изучив перспективы точной настройки нашего набора функций и модели ценообразования, мы искали лучшие существующие технологии, чтобы поддержать его, и остановились на инкубационном проекте CNCF Harbor (подаренном CNCF компанией VMWare). Помимо того, что Harbour является одним из немногих проектов, достигших инкубационного состояния CNCF, что подтверждает твердую приверженность сообщества, он также стал ключевой частью нескольких коммерческих решений для контейнеризации предприятий. Мы также высоко оценили подход, принятый Харбором: не изобретать колесо заново, а использовать лучшие в своем классе технологии для таких компонентов, как сканирование уязвимостей, доверие к контенту и многие другие. Он использует мощную сеть проектов с открытым исходным кодом CNCF и обеспечивает высокий уровень качества UX.
Пришло время использовать эту технологию 10k-GitHub-stars и адаптировать ее к нашему конкретному случаю: управление десятками тысяч реестров для наших пользователей, каждый из которых имеет определенный объем образов контейнеров и шаблонов использования.
Конечно, высокая доступность (интеграция и развертывание программного обеспечения клиентов зависит от этой услуги), но и надежность данных не обсуждались для нас.
Кроме того, Kubernetes для обеспечения высокой доступности сервисов без сохранения состояния и хранилища объектов (на основе Openstack Swift и совместимость с S3 API ) был очевидным выбором для проверки этих требований.
Решение операционных проблем в масштабе облачного провайдера
В течение нескольких недель мы открыли сервис в публичной бета-версии, быстро привлекая сотни активных пользователей. Но с этим всплеском трафика мы, естественно, столкнулись с первыми узкими местами и проблемами производительности.
Мы обратились к группе пользователей и команде Harbour, которые любезно указали нам на возможные решения, и после некоторых небольших, но важных изменений в том, как Harbor обрабатывает соединения с базой данных, наши проблемы были решены. Это укрепило нашу веру в то, что сообщество Harbour твердо и привержено здоровью проекта и требованиям его пользователей.
Поскольку наш сервис процветал, не было реальных инструментов, позволяющих легко приспособить жизненный цикл экземпляров Harbour. Наша приверженность экосистеме Kubernetes сделала концепцию оператора Harbour для Kubernetes интересным подходом.
Мы обсудили с сопровождающими Harbour, и они тепло приветствовали нашу идею разработать его и открыть исходный код в качестве официального оператора Harbour Kubernetes. OVHcloud очень гордится тем, что проект теперь доступен в проекте goharbor GitHub под лицензией Apache 2. Этот проект — еще один пример нашей твердой приверженности открытому исходному коду и нашей готовности внести свой вклад в проекты, которые нам нравятся.
Универсальный оператор, разработанный для любого развертывания в гавани
Читатели, знакомые с проектом Harbour, могут задаться вопросом, какое значение этот оператор привносит в текущий каталог развертываний, включая версию Helm Chart, поддерживаемую проектом.
Шаблон проектирования оператора быстро становится популярным и имитирует ориентированный на приложения контроллер, который расширяет Kubernetes для управления более сложными приложениями с отслеживанием состояния. Проще говоря, он предназначен для разных сценариев использования, чем Helm. В то время как диаграмма Helm предлагает универсальный установщик, который также будет развертывать различные зависимости Harbor (база данных, кеш и т. Д.) Из образов Docker с открытым исходным кодом, другие предприятия, операторы услуг и облачные провайдеры, такие как мы, захотят выбрать и -выбрать услугу или технологию, лежащую в основе этих компонентов.
Мы также стремимся расширить возможности текущего оператора v0.5 для управления полным жизненным циклом Harbour, от развертывания до удаления, включая масштабирование, обновления, обновления и управление резервным копированием.
Это поможет производственным пользователям достичь целевого SLO, получить выгоду от управляемых решений или существующих кластеров баз данных, которые они уже обслуживают.
Мы разработали оператор (используя платформу OperatorSDK), чтобы как дополнительные модули Harbor (хранилище Helm Chart, сканер уязвимостей и т. Д.), Ни зависимости (серверная часть хранилища реестра, относительные и нереляционные базы данных и т. Д.) Могли легко соответствовать вашему конкретному варианту использования.
Вклад в проект Harbor и оператора
У нас уже есть план действий с сопровождающими Harbour для дальнейшего обогащения оператора, чтобы он мог включать не только фазы развертывания и уничтожения (например, сделать обновления версии Harbour более элегантными). Мы надеемся стать неотъемлемой частью проекта и продолжим инвестировать в Harbour.
С этой целью Жереми Монсинжон и Пьер Перонне также были приглашены в качестве сопровождающих в проекте Harbour с упором на goharbor / оператора.
В дополнение к регулярному участию в нескольких проектах, которые мы используем в OVHcloud, команда контейнерных платформ также работает над другими крупными выпусками с открытым исходным кодом, такими как официальный облачный контроллер OVHcloud для самоуправляемого Kubernetes, который мы планируем выпустить в конце 2020 года.
Скачать Harbour or the Harbour Operator: официальное репозиторий Harbour Github — www.github.com/goharbor
Узнайте больше о гавани: Официальный сайт гавани — goharbor.io/