Если вы читаете этот блог впервые, добро пожаловать в продолжающуюся революцию данных! Сразу после промышленной революции произошло то, что мы называем цифровой революцией, когда миллионы людей и объектов получили доступ к всемирной сети — Интернету — все они создали новый контент, новые данные.
Давайте подумаем о себе… Теперь у нас есть смартфоны, которые делают снимки и отправляют текстовые сообщения, спортивные часы, собирающие данные о нашем здоровье, учетные записи Twitter и Instagram, генерирующие контент, и многие другие варианты использования. В результате объем данных во всех их формах экспоненциально растет во всем мире.
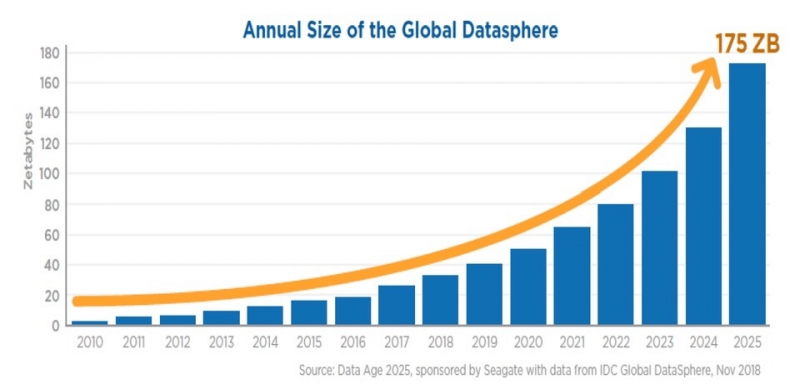
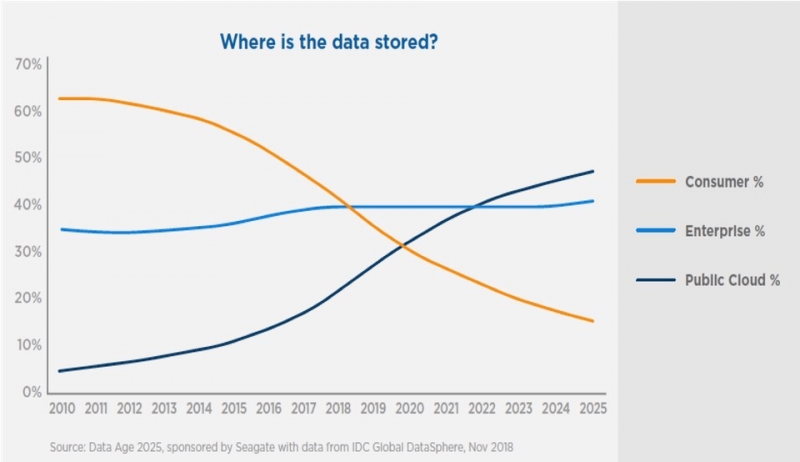
90% всех данных в мире было создано за последние два года. Согласно IDC, объем данных в мире должен вырасти с 33 зеттабайт в 2018 году до 175 зеттабайт в 2025 году. Когда мы делаем базовое деление, это составляет примерно 34 ТБ данных на человека, включая все страны и топологии.
Это открывает множество новых концепций и применений, но, конечно же, и новые проблемы. Как мы храним эти данные? Как обеспечить безопасность и конфиденциальность? И последнее, но не менее важное: как мы можем извлечь пользу из этих данных, если эта новая гигантская сфера данных нуждается в обработке? Другими словами, его нужно использовать для извлечения значений.
Возможные результаты и возможности применения безграничны: улучшение сельскохозяйственного поля путем анализа прогнозов погоды, глубокое понимание клиентов, исследование новых вакцин, изменение определения городской среды путем анализа пробок… Список можно продолжить.
Сначала это кажется простым, но для этого требуются три основных элемента:
- Во-первых, нам нужны данные. Иногда эти источники данных могут быть разнородными (текст, аудио, видео, изображения и т. Д.), И нам может потребоваться «очистить» их, прежде чем они смогут эффективно использоваться.
- Далее нам потребуется вычислительная мощность. Подумайте еще раз о себе: наш мозг может выполнять множество вычислений и операций, но невозможно разделить одну задачу между несколькими мозгами. Попросите друга сделать с вами умножение, и вы убедитесь в этом сами. Но с компьютерами все возможно! Теперь мы можем распараллеливать вычисления на нескольких компьютерах (например, в кластере), что позволяет нам получать желаемые результаты быстрее, чем когда-либо.
- Наконец, нам нужна структура, представляющая собой набор инструментов, которые позволят вам использовать эту базу данных и эффективно вычислять мощность.

Шаг 1. Найдите подходящую структуру
Как вы увидите из названия этого поста, не секрет, что
Apache Spark — наш предпочтительный инструмент в OVH.
Мы выбрали Apache Spark, потому что это распределенная универсальная среда кластерных вычислений с открытым исходным кодом, которая имеет самое большое сообщество разработчиков открытого исходного кода в мире больших данных и работает до 100 раз быстрее, чем предыдущая среда кластерных вычислений. Hadoop MapReduce благодаря приятным функциям, таким как обработка в памяти и отложенная оценка. Apache Spark — это ведущая платформа для крупномасштабного SQL, пакетной обработки, потоковой обработки и машинного обучения с простым в использовании API, а для кодирования в Spark у вас есть возможность использовать разные языки программирования, включая
Java, Scala., Python, R и SQL .
Другие инструменты, такие как Apache Flink и Beam, также выглядят очень многообещающими и будут частью наших будущих услуг.
Различные компоненты Apache Spark:
- Apache Spark Core , который обеспечивает вычисления в памяти и составляет основу других компонентов
- Spark SQL , который обеспечивает абстракцию структурированных и полуструктурированных данных.
- Spark Streaming , который выполняет потоковый анализ с использованием преобразования RDD (Resilient Distributed Datasets).
- MLib (библиотека машинного обучения) , которая представляет собой распределенную платформу машинного обучения над Spark.
- GraphX , который представляет собой среду обработки распределенных графов поверх Spark.
Принцип архитектуры Apache Spark
Прежде чем идти дальше, давайте разберемся, как Apache Spark может работать так быстро, проанализировав его рабочий процесс.
Вот пример кода на Python, где мы будем читать файл и подсчитывать количество строк с буквой «a» и количество строк с буквой «b».
Прежде чем идти дальше, давайте разберемся, как Apache Spark может работать так быстро, проанализировав его рабочий процесс.
Вот пример кода на Python, где мы будем читать файл и подсчитывать количество строк с буквой «a» и количество строк с буквой «b».
Этот код является частью вашего приложения Spark, также известного как ваша программа драйвера.
Каждое действие ( count()в нашем примере) запускает задания. Затем Apache Spark разделит вашу работу на несколько задач, которые можно вычислить отдельно.
Apache Spark хранит данные в RDD (устойчивые распределенные наборы данных), которые представляют собой неизменяемую распределенную коллекцию объектов, а затем делит их на разные логические разделы, чтобы можно было обрабатывать каждую часть параллельно на разных узлах кластера.
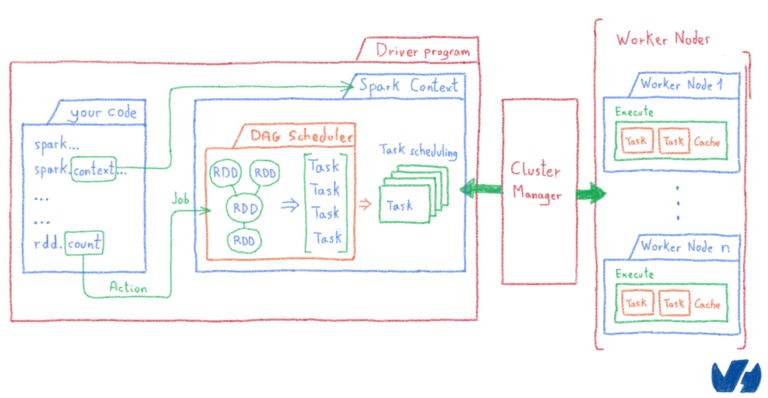 Параллелизм задач
Параллелизм задач и
вычисления в памяти — вот ключ к сверхбыстости. Вы можете углубиться в
официальную документацию .
Шаг 2. Найдите необходимую вычислительную мощность
Теперь у нас есть инструменты, но они нуждаются в вычислительной мощности (мы в основном говорим о ЦП и оперативной памяти) для выполнения таких массовых операций, и они должны быть масштабируемыми.
Поговорим о создании кластера компьютеров. Старомодным способом является покупка физических компьютеров и сетевого оборудования для их соединения, установка ОС и всего необходимого программного обеспечения и пакетов, установка Apache Spark на все узлы, затем настройка автономной системы управления кластером Spark и подключение всех рабочих к системе. главный узел.
Очевидно, это не лучший способ. Это занимает много времени и требует квалифицированных инженеров, чтобы все сделать. Также предположим, что вы выполнили эту сложную работу, а затем закончили обработку больших данных… Что вы собираетесь делать с кластером после этого? Просто оставить там или продать на вторичном рынке? Что, если вы решили выполнить некоторую крупномасштабную обработку и вам нужно добавить больше компьютеров в свой кластер? Вам нужно будет выполнить все программное обеспечение, установку и настройку сети для новых узлов.
Лучшим способом создания кластера является использование поставщика публичного облака. Таким образом, ваши серверы будут развернуты очень быстро, вы будете платить только за то, что потребляете, и сможете удалить кластер после завершения задачи обработки. Вы также сможете получить доступ к своим данным намного проще, чем при использовании локального решения. Не случайно, согласно IDC, к 2025 году половина всех данных в мире будет храниться в публичном облаке [3].
Но основная проблема сохраняется: вам по-прежнему нужно установить все программное обеспечение и пакеты на каждом из серверов в вашем виртуальном кластере, затем настроить сеть и маршрутизаторы, принять меры безопасности и настроить брандмауэр и, наконец, установить и настроить Apache Spark. система управления кластером. Это займет время и будет подвержено ошибкам, и чем дольше это займет, тем больше с вас будет взиматься плата из-за того, что эти серверы развернуты в вашей облачной учетной записи.
Шаг 3. Отдохните и откройте для себя OVH Analytics Data Compute
Как мы только что видели, создание кластера можно выполнить вручную, но это скучная и трудоемкая задача.
В OVH мы решили эту проблему, представив службу кластерных вычислений под названием Analytics Data Compute, которая на лету создаст готовый, полностью установленный и настроенный кластер Apache Spark. Используя эту услугу, вам не нужно тратить время на создание сервера, сети, брандмауэры и настройки безопасности на каждом узле вашего кластера. Вы просто сосредотачиваетесь на своих задачах, и нужный вам вычислительный кластер появится как по волшебству!
На самом деле, в этом нет ничего волшебного… просто автоматизация, созданная OVH для упрощения как нашей, так и вашей жизни. Нам понадобился такой инструмент для внутренних вычислений, и мы превратили его в продукт для вас.
Идея довольно проста: вы запускаете задание Apache Spark как обычно через командную строку или API, и полный кластер Apache Spark будет построен на лету, специально для вашей работы. После завершения обработки мы удаляем кластер, и вам выставляется счет за использованные ресурсы (на данный момент на почасовой основе).
Таким образом, мы можем быстро масштабироваться от одной до тысяч виртуальных машин, позволяя использовать тысячи ядер ЦП и тысячи ГБ оперативной памяти.
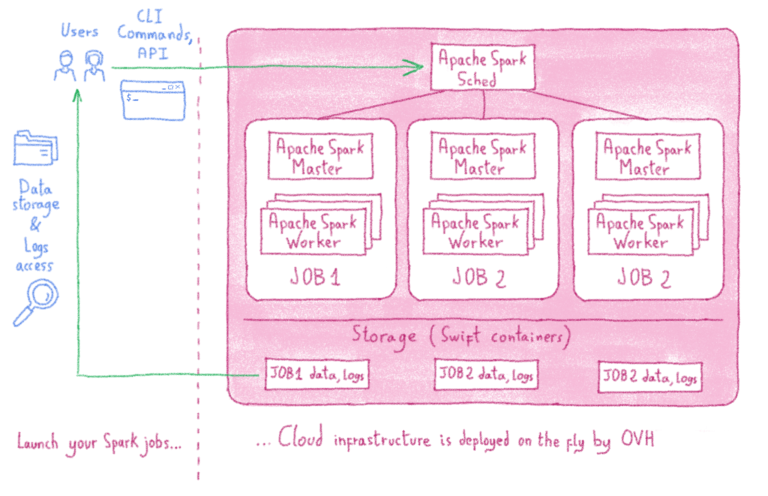
Чтобы использовать Analytics Data Compute, вам необходимо загрузить небольшой пакет клиентского программного обеспечения с открытым исходным кодом из репозитория OVH, который называется ovh-spark-submit.
Этот клиент был создан с целью сохранения официального синтаксиса командной строки Spark-submit Apache Spark. Большинство параметров и синтаксиса одинаковы, хотя в версии OVH есть еще несколько параметров, связанных с управлением инфраструктурой и кластером. Таким образом, вы просто запрашиваете запуск своего кода над своими данными в кластере определенных узлов, и инструмент создаст кластер с указанным количеством узлов, установит все пакеты и программное обеспечение (включая Spark и его систему управления кластером)., а затем настройте сеть и брандмауэр. После создания кластера OVH Analytics Data Compute запустит ваш код Spark, вернет результат пользователю, а затем удалит все, как только это будет сделано. Намного эффективнее!
Приступим… Почувствуй силу!
Хорошая новость заключается в том, что если вы уже знакомы с командной строкой Spark-submit Apache Spark, вам не нужно изучать какие-либо новые инструменты командной строки, поскольку ovh-spark-submit использует почти те же параметры и команды.
Давайте посмотрим на пример, в котором мы вычислим десятичные дроби знаменитого числа Пи, сначала с использованием исходного синтаксиса Apache Spark, а затем с помощью клиента ovh-spark-submit:
./spark-submit \
--class org.apache.spark.examples.SparkPi \
--total-executor-cores 20 \
SparkPI.jar 100
./ovh-spark-submit \
--class org.apache.spark.examples.SparkPi \
--total-executor-cores 20 \
SparkPI.jar 100
Вы можете видеть, что единственная разница — это «ovh-» в начале командной строки, а все остальное такое же. И, запустив ovh-spark-submitкоманду, вы запустите задание на кластере компьютеров с 20 ядрами, а не только на своем локальном компьютере. Этот кластер полностью посвящен этому заданию, так как он будет создан после выполнения команды, а затем удален по завершении.
Другой пример — популярный вариант использования подсчета слов. Предположим, вы хотите подсчитать количество слов в большом текстовом файле, используя кластер из 100 ядер. Большой текстовый файл хранится в хранилище OpenStack Swift (хотя это может быть любая онлайн-система или облачная система хранения). Код Spark для этого вычисления в Java выглядит так:
JavaRDD<String> lines = spark.read().textFile("swift://textfile.abc/novel.txt").javaRDD();
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
List<Tuple2<String, Integer>> output = counts.collect();
Мы также можем выбрать желаемую версию Spark. В этом примере мы выбрали Spark версии 2.4.0, и командная строка для запуска этого задания Spark выглядит так:
./ovh-spark-submit \
--class JavaWordCount \
--total-executor-cores 100 \
--name wordcount1 \
--version 2.4.0 \
SparkWordCount-fat.jar
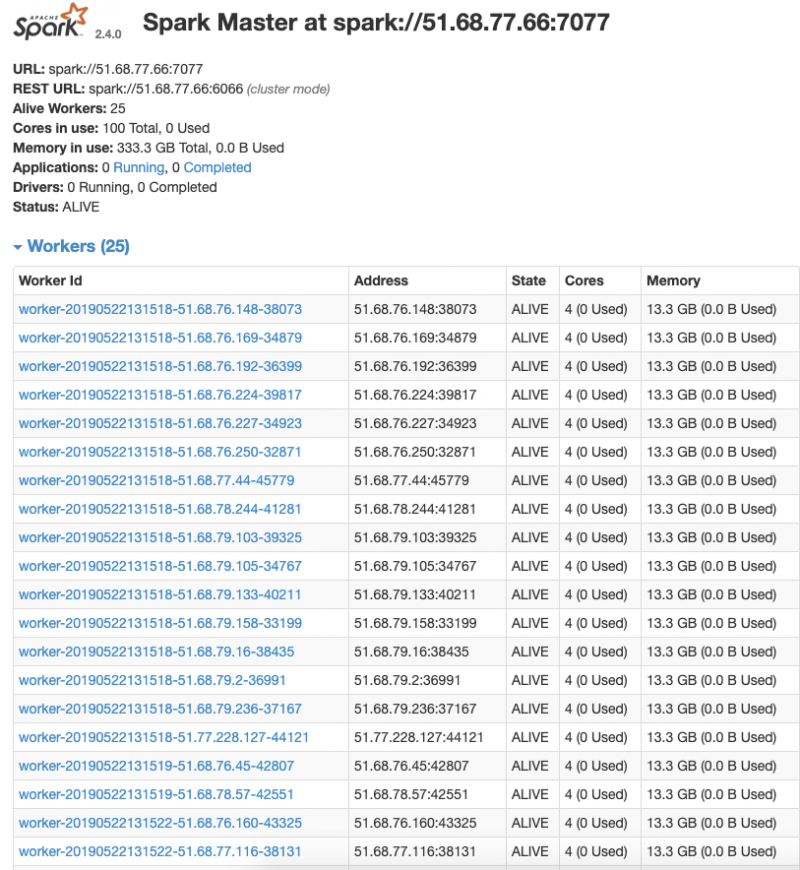
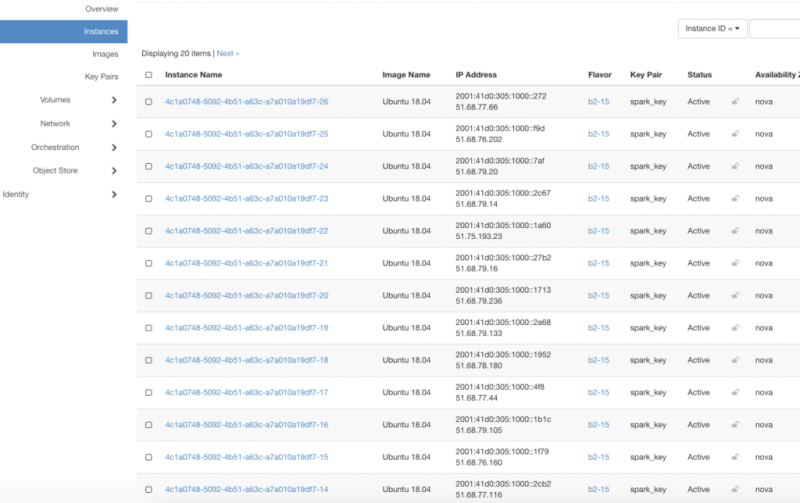
Для создания кластера Spark мы используем узлы с четырьмя виртуальными ядрами и 15 ГБ ОЗУ. Следовательно, при выполнении этой команды будет создан кластер из 26 серверов (один для главного узла и 25 для рабочих), поэтому у нас будет 25 × 4 = 100 виртуальных ядер и 25 × 15 = 375 ГБ ОЗУ.
После запуска командной строки вы увидите процесс создания кластера и установки всего необходимого программного обеспечения.
После создания кластера вы можете взглянуть на него с помощью официальной панели управления Spark и проверить, все ли в вашем кластере запущены и работают:
Кроме того, если вы перейдете на панель управления OpenStack Horizon в своей облачной учетной записи OVH, вы увидите все 26 серверов:
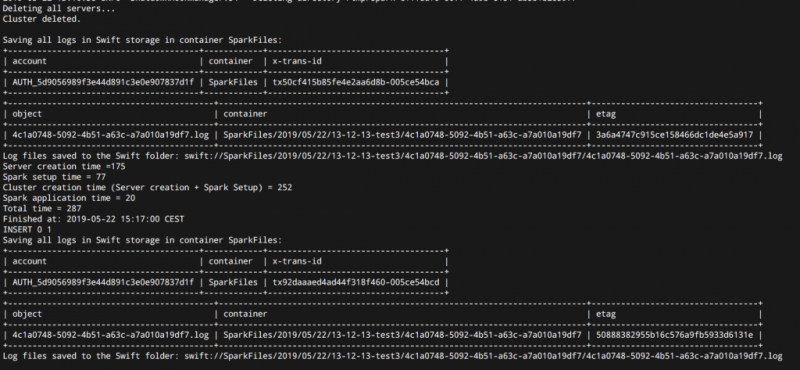
Задание Apache Spark будет выполнено в соответствии с файлом java-кода в jar, который мы отправили в кластер Spark, и результаты будут показаны на экране. Кроме того, результаты и полные файлы журнала будут сохранены как на локальном компьютере, так и в хранилище Swift пользователя.
Когда вы закончите, вы увидите сообщение о том, что кластер удален, а также адреса журналов в хранилище OpenStack Swift и на локальном компьютере. На следующем снимке экрана видно, что создание полностью установленного и настроенного кластера Spark с 26 серверами заняло менее пяти минут.
Еще немного о вычислении данных OVH Analytics
Если вам интересно, вот некоторые дополнительные сведения о вычислении данных Analytics:
- Все построено на публичном облаке OVH, а это значит, что все работает на OpenStack.
- Вы можете выбрать версию Apache Spark, которую хотите запустить, прямо в командной строке. Вы также, конечно, можете запускать несколько кластеров с разными версиями.
- Для каждого запроса будет создан новый выделенный кластер, который будет удален после завершения задания. Это означает, что нет проблем с безопасностью или конфиденциальностью, вызванных наличием нескольких пользователей в одном кластере.
- У вас есть возможность оставить кластер после завершения работы. Если вы добавите параметр keep-infra в командную строку, кластер не будет удален, когда вы закончите. Затем вы можете отправить больше заданий в этот кластер или просмотреть более подробную информацию в журналах.
- Компьютеры кластера создаются в вашем собственном проекте OVH Public Cloud, поэтому вы имеете полный контроль над компьютерами кластера.
- Результаты и журналы вывода будут сохранены в Swift в вашем проекте OVH Public Cloud. Только у вас будет доступ к ним, и у вас также будет полная история всех ваших заданий Spark, сохраненных в папке, с сортировкой по дате и времени выполнения.
- Ввод и вывод данных могут быть любого источника или формата. Когда дело доходит до хранилища, нет привязки к поставщику, поэтому вы не обязаны использовать только облачное хранилище OVH для хранения ваших данных и можете использовать любую онлайн-платформу или платформу облачного хранилища в общедоступном Интернете.
- Вы можете получить доступ к панелям мониторинга Cluster и Spark и веб-интерфейсу через HTTPS.
Сосредоточимся на системах управления кластером
В кластерах Apache Spark на всех узлах кластера есть независимые процессы, называемые «исполнителями», которые координируются программой драйвера. Для распределения ресурсов кластера между приложениями программа драйвера должна подключиться к системе управления кластером, после чего она будет отправлять код приложения и задачи исполнителям.
Когда дело доходит до систем управления кластером, есть несколько вариантов, но, чтобы все было быстро и просто, мы выбрали автономную систему управления кластером Spark. Это дает нашим пользователям свободу выбора любой версии Spark, а также ускоряет установку кластера по сравнению с другими вариантами. Если, например, мы выбрали Kubernetes в качестве нашей системы управления кластером, наши пользователи были бы ограничены Spark версии 2.3 или выше, а установка кластера потребовала бы больше времени. В качестве альтернативы, если бы мы хотели развернуть готовый к использованию кластер Kubernetes (например, OVH Managed Kubernetes), мы бы потеряли масштабируемость, потому что инфраструктура нашего кластера Apache Spark была бы по своей сути ограничена инфраструктурой кластера Kubernetes.. Но с нашим текущим дизайном,
Попробуй сам!
Чтобы начать работу с Analytics Data Compute, вам просто нужно создать облачную учетную запись на
www.ovh.com, затем загрузить программное обеспечение ovh-spark-submit и запустить его, как описано
на странице документации OVH . Кроме того, если вы
примете участие в
небольшом опросе на нашей странице OVH Labs , вы получите ваучер, который позволит вам протестировать Analytics Data Compute из первых рук с 20 евро на бесплатный кредит.
Если у вас есть какие-либо вопросы или вы хотите получить дополнительные объяснения, с нашей командой можно связаться через наш канал Gitter.